 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLACUNA: A Testbed for Evaluating Localization Precision for LLM Unlearning
Jul 02, 2026LLMs memorize sensitive training data, including personally identifiable information (PII), creating a pressing need for reliable post hoc removal methods. Unlearning has emerged as a promising solution, with state-of-the-art(SOTA) methods often following a localize-first, unlearn-second paradigm that targets specific model parameters. However, existing benchmarks evaluate unlearning solely at the output level, leaving open the question of whether unlearning truly erases knowledge from a model's parameters or merely obfuscates it, a concern reinforced by the success of resurfacing attacks. To bridge this gap, we introduce LACUNA: the first unlearning testbed with ground-truth parameter-level localization. LACUNA injects PII of synthetic individuals into predefined parameters of 1B and 7B OLMo-based models via masked continual pretraining, enabling direct evaluation of whether unlearning targets the weights responsible for knowledge storage. We use LACUNA to benchmark current SOTA unlearning methods and find that, despite strong output-level performance, existing methods are highly imprecise and susceptible to resurfacing attacks. We further show that when localization is successful, even a simple gradient-based unlearning method achieves strong erasure and robustness to resurfacing attacks, highlighting the importance of precise unlearning. We release LACUNA to complement behavioral evaluations and drive further advances in robust, localization-based unlearning.
Do Generalisation Results Generalise?
Dec 08, 2025



A large language model's (LLM's) out-of-distribution (OOD) generalisation ability is crucial to its deployment. Previous work assessing LLMs' generalisation performance, however, typically focuses on a single out-of-distribution dataset. This approach may fail to precisely evaluate the capabilities of the model, as the data shifts encountered once a model is deployed are much more diverse. In this work, we investigate whether OOD generalisation results generalise. More specifically, we evaluate a model's performance across multiple OOD testsets throughout a finetuning run; we then evaluate the partial correlation of performances across these testsets, regressing out in-domain performance. This allows us to assess how correlated are generalisation performances once in-domain performance is controlled for. Analysing OLMo2 and OPT, we observe no overarching trend in generalisation results: the existence of a positive or negative correlation between any two OOD testsets depends strongly on the specific choice of model analysed.
Enhancing One-run Privacy Auditing with Quantile Regression-Based Membership Inference
Jun 18, 2025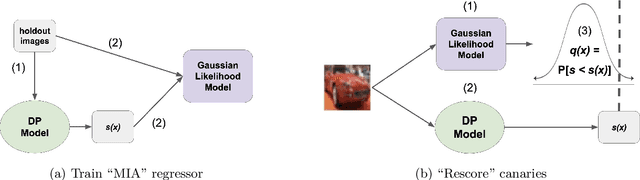
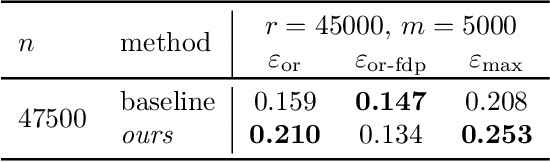
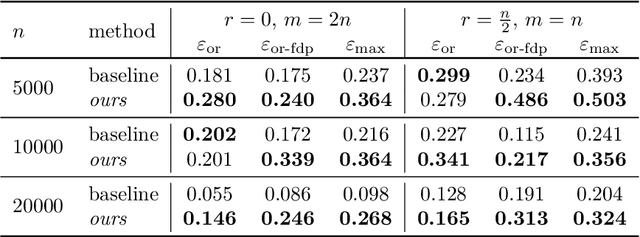
Differential privacy (DP) auditing aims to provide empirical lower bounds on the privacy guarantees of DP mechanisms like DP-SGD. While some existing techniques require many training runs that are prohibitively costly, recent work introduces one-run auditing approaches that effectively audit DP-SGD in white-box settings while still being computationally efficient. However, in the more practical black-box setting where gradients cannot be manipulated during training and only the last model iterate is observed, prior work shows that there is still a large gap between the empirical lower bounds and theoretical upper bounds. Consequently, in this work, we study how incorporating approaches for stronger membership inference attacks (MIA) can improve one-run auditing in the black-box setting. Evaluating on image classification models trained on CIFAR-10 with DP-SGD, we demonstrate that our proposed approach, which utilizes quantile regression for MIA, achieves tighter bounds while crucially maintaining the computational efficiency of one-run methods.