 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTimeThink: Reasoning with Time for Video LLMs
Jul 06, 2026Video reasoning requires models to identify and verify temporally localized evidence within long video sequences. Recent Video Large Language Models (Video-LLMs) have shown promising reasoning abilities when aligned with reinforcement learning, yet existing approaches typically rely on outcome-based rewards that supervise only the final prediction. Such supervision provides limited guidance on how models should discover the relevant temporal evidence during intermediate reasoning. In this work, we propose TimeThink, a reinforcement learning framework that explicitly guides temporal evidence discovery in Video-LLMs. Our key idea is to treat temporal clue steps as the fundamental optimization primitive of video reasoning, where each reasoning step references a candidate time interval in the video. We introduce a step-wise temporal process reward that provides localized credit assignment for these clues and a joint process--outcome optimization objective that balances reasoning fidelity with task correctness. To enable scalable training, we construct TimeThink-RFT-20K, a dataset with automatically derived temporal evidence segments. Extensive experiments across video reasoning, temporal grounding, and general video understanding benchmarks show that TimeThink consistently improves both temporal localization and reasoning performance, achieving state-of-the-art results among open-source video RL models.
Clearer Sight, Fewer Lies: Oriented Pickup Preference Optimization for Multimodal Hallucination Mitigation
Jun 30, 2026Multimodal Large Language Models (MLLMs) are prone to hallucination as their generation preferences are insufficiently calibrated to visual evidence, causing them to fall back on linguistic priors, rather than faithful grounding. In this work, we start from an empirical observation: when query-relevant visual evidence is explicitly strengthened using the model's own attention, generation becomes more accurate, suggesting that many failures do not arise solely from missing perception, but from an insufficient tendency to trust the evidence the model has already attended to. Motivated by this finding, we propose Oriented Pickup Preference Optimization (\texttt{OPPO}), an evidence-aware alignment objective that learns preferences over the strength of visual evidence, rather than only response quality. Concretely, \texttt{OPPO} contrasts the same faithful response under stronger, anchored, weaker-evidence views, turning naive visual preference into ordered visual-evidence alignment. We further combine this objective with fine-grained span-level and token-level regularization to stabilize the training. Besides, we provide a theoretical analysis showing that ordered evidence margins induce a positive lower bound on local visual sensitivity. Extensive evaluations across hallucination and general-purpose benchmarks demonstrate that \texttt{OPPO} consistently outperforms baseline methods.
Consistency as Inductive Bias: Learning Cross-View Invariance for Robust Multimodal Reasoning
Jun 29, 2026Inductive biases steer learning toward generalizable solutions by encoding task structure. In this work, we identify a crucial missing bias in MLLMs: cross-view consistency, \textit{i.e.}, semantically invariant views of the same instance should lead to the same answer. Standard reinforcement learning with verifiable rewards (RLVR) objectives do not impose this constraint, but instead assign pointwise rewards to each visual input. Even with data augmentation (DA), transformed views are typically rewarded independently, providing little signal once within-view rewards saturate. We propose \textbf{ConsistRoll}, a simple but effective method that injects cross-view consistency into RLVR training by reusing the group-sampling mechanism of GRPO. Specifically, ConsistRoll places original and semantically invariant transformed views in the same generation group, and assigns a joint reward only when paired completions are both correct and consistent. In this way, ConsistRoll turns consistency into an online credit-assignment signal, \textbf{without extra generation overhead and annotations}. Theoretically, we show that cross-view consistency is a valid inductive bias, and ConsistRoll introduces a cross-view correction term absent from DA, penalizing view dependence and alleviating advantage collapse. Comprehensive benchmarks across math, general-purpose, hallucination domains confirm that ConsistRoll achieves robust improvements in multimodal reasoning.
Stabilizing On-Policy Distillation for MLLM Reasoning with Global Normalization
Jun 08, 2026On-policy distillation (OPD) has recently emerged as an important post-training paradigm. By using a stronger teacher model to provide dense, fine-grained supervision for sampled trajectories, OPD offers a clear advantage over reinforcement learning with verifiable rewards (RLVR), which typically depends on sparse binary or outcome-based environmental feedback. However, naive token-level distillation can suffer from gradient instability, due to magnitude misalignment in outlier states. To address this issue, we propose Globally Normalized Distillation Policy Optimization (GNDPO), a practical method that stabilizes optimization by transforming raw KL scores into batch-level relative advantages. This normalization effectively mitigates gradient explosions while retaining the benefits of token-level guidance. Experimental results show that GNDPO substantially improves training robustness and downstream performance across multimodal reasoning tasks. The code is released at https://github.com/OPPO-Mente-Lab/GNDPO.
Learning from Fine-Grained Visual Discrepancies: Mitigating Multimodal Hallucinations via In-Context Visual Contrastive Optimization
May 29, 2026Multimodal hallucination remains a persistent challenge for Vision-Language Models (VLMs). Standard textual Direct Preference Optimization (DPO) often fails to mitigate it due to a lack of explicit visual supervision. While existing works introduce visual preference DPO by contrasting original images against negative ones, they suffer from a theoretically inconsistent objective caused by partition function mismatches and rely on coarse-grained negatives that could enable shortcut learning. In this work, we propose In-Context Visual Contrastive Optimization (IC-VCO). By placing contrastive images within a shared multi-image context, IC-VCO ensures a mathematically rigorous objective. We further introduce Visual Contrast Distillation (VCDist), an auxiliary reliability-gated regularizer that encourages consistency between multi-image contrastive training and single-image inference. Finally, we propose a contrastive sample editing strategy that generates hard negatives via precise semantic perturbations. Experiments on five benchmarks demonstrate IC-VCO's best overall performance and the effectiveness of our sample editing strategy. Code and data are available at https://github.com/OPPO-Mente-Lab/IC-VCO.
PixelPrune: Pixel-Level Adaptive Visual Token Reduction via Predictive Coding
Apr 01, 2026Document understanding and GUI interaction are among the highest-value applications of Vision-Language Models (VLMs), yet they impose exceptionally heavy computational burden: fine-grained text and small UI elements demand high-resolution inputs that produce tens of thousands of visual tokens. We observe that this cost is largely wasteful -- across document and GUI benchmarks, only 22--71\% of image patches are pixel-unique, the rest being exact duplicates of another patch in the same image. We propose \textbf{PixelPrune}, which exploits this pixel-level redundancy through predictive-coding-based compression, pruning redundant patches \emph{before} the Vision Transformer (ViT) encoder. Because it operates in pixel space prior to any neural computation, PixelPrune accelerates both the ViT encoder and the downstream LLM, covering the full inference pipeline. The method is training-free, requires no learnable parameters, and supports pixel-lossless compression ($τ{=}0$) as well as controlled lossy compression ($τ{>}0$). Experiments across three model scales and document and GUI benchmarks show that PixelPrune maintains competitive task accuracy while delivering up to 4.2$\times$ inference speedup and 1.9$\times$ training acceleration. Code is available at https://github.com/OPPO-Mente-Lab/PixelPrune.
Learn over Past, Evolve for Future: Forecasting Temporal Trends for Fake News Detection
Jun 26, 2023Fake news detection has been a critical task for maintaining the health of the online news ecosystem. However, very few existing works consider the temporal shift issue caused by the rapidly-evolving nature of news data in practice, resulting in significant performance degradation when training on past data and testing on future data. In this paper, we observe that the appearances of news events on the same topic may display discernible patterns over time, and posit that such patterns can assist in selecting training instances that could make the model adapt better to future data. Specifically, we design an effective framework FTT (Forecasting Temporal Trends), which could forecast the temporal distribution patterns of news data and then guide the detector to fast adapt to future distribution. Experiments on the real-world temporally split dataset demonstrate the superiority of our proposed framework. The code is available at https://github.com/ICTMCG/FTT-ACL23.
Image Credibility Analysis with Effective Domain Transferred Deep Networks
Nov 16, 2016

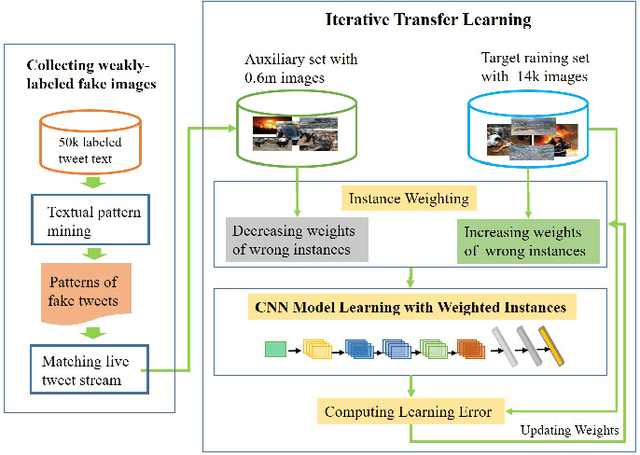

Numerous fake images spread on social media today and can severely jeopardize the credibility of online content to public. In this paper, we employ deep networks to learn distinct fake image related features. In contrast to authentic images, fake images tend to be eye-catching and visually striking. Compared with traditional visual recognition tasks, it is extremely challenging to understand these psychologically triggered visual patterns in fake images. Traditional general image classification datasets, such as ImageNet set, are designed for feature learning at the object level but are not suitable for learning the hyper-features that would be required by image credibility analysis. In order to overcome the scarcity of training samples of fake images, we first construct a large-scale auxiliary dataset indirectly related to this task. This auxiliary dataset contains 0.6 million weakly-labeled fake and real images collected automatically from social media. Through an AdaBoost-like transfer learning algorithm, we train a CNN model with a few instances in the target training set and 0.6 million images in the collected auxiliary set. This learning algorithm is able to leverage knowledge from the auxiliary set and gradually transfer it to the target task. Experiments on a real-world testing set show that our proposed domain transferred CNN model outperforms several competing baselines. It obtains superiror results over transfer learning methods based on the general ImageNet set. Moreover, case studies show that our proposed method reveals some interesting patterns for distinguishing fake and authentic images.