 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTimeThink: Reasoning with Time for Video LLMs
Jul 06, 2026Video reasoning requires models to identify and verify temporally localized evidence within long video sequences. Recent Video Large Language Models (Video-LLMs) have shown promising reasoning abilities when aligned with reinforcement learning, yet existing approaches typically rely on outcome-based rewards that supervise only the final prediction. Such supervision provides limited guidance on how models should discover the relevant temporal evidence during intermediate reasoning. In this work, we propose TimeThink, a reinforcement learning framework that explicitly guides temporal evidence discovery in Video-LLMs. Our key idea is to treat temporal clue steps as the fundamental optimization primitive of video reasoning, where each reasoning step references a candidate time interval in the video. We introduce a step-wise temporal process reward that provides localized credit assignment for these clues and a joint process--outcome optimization objective that balances reasoning fidelity with task correctness. To enable scalable training, we construct TimeThink-RFT-20K, a dataset with automatically derived temporal evidence segments. Extensive experiments across video reasoning, temporal grounding, and general video understanding benchmarks show that TimeThink consistently improves both temporal localization and reasoning performance, achieving state-of-the-art results among open-source video RL models.
Stabilizing On-Policy Distillation for MLLM Reasoning with Global Normalization
Jun 08, 2026On-policy distillation (OPD) has recently emerged as an important post-training paradigm. By using a stronger teacher model to provide dense, fine-grained supervision for sampled trajectories, OPD offers a clear advantage over reinforcement learning with verifiable rewards (RLVR), which typically depends on sparse binary or outcome-based environmental feedback. However, naive token-level distillation can suffer from gradient instability, due to magnitude misalignment in outlier states. To address this issue, we propose Globally Normalized Distillation Policy Optimization (GNDPO), a practical method that stabilizes optimization by transforming raw KL scores into batch-level relative advantages. This normalization effectively mitigates gradient explosions while retaining the benefits of token-level guidance. Experimental results show that GNDPO substantially improves training robustness and downstream performance across multimodal reasoning tasks. The code is released at https://github.com/OPPO-Mente-Lab/GNDPO.
SciVQR: A Multidisciplinary Multimodal Benchmark for Advanced Scientific Reasoning Evaluation
May 11, 2026Scientific reasoning is a key aspect of human intelligence, requiring the integration of multimodal inputs, domain expertise, and multi-step inference across various subjects. Existing benchmarks for multimodal large language models (MLLMs) often fail to capture the complexity and traceability of reasoning processes necessary for rigorous evaluation. To fill this gap, we introduce SciVQR, a multimodal benchmark covering 54 subfields in mathematics, physics, chemistry, geography, astronomy, and biology. SciVQR includes domain-specific visuals, such as equations, charts, and diagrams, and challenges models to combine visual comprehension with reasoning. The tasks range from basic factual recall to complex, multi-step inferences, with 46% including expert-authored solutions. SciVQR not only evaluates final answers but also examines the reasoning process, providing insights into how models reach their conclusions. Our evaluation of leading MLLMs, including both proprietary and open-source models, reveals significant limitations in handling complex multimodal reasoning tasks, underscoring the need for improved multi-step reasoning and better integration of interdisciplinary knowledge in advancing MLLMs toward true scientific intelligence. The dataset and evaluation code are publicly available at https://github.com/CASIA-IVA-Lab/SciVQR.
M$^3$-VQA: A Benchmark for Multimodal, Multi-Entity, Multi-Hop Visual Question Answering
Apr 28, 2026We present M$^3$-VQA, a novel knowledge-based Visual Question Answering (VQA) benchmark, to enhance the evaluation of multimodal large language models (MLLMs) in fine-grained multimodal entity understanding and complex multi-hop reasoning. Unlike existing VQA datasets that focus on coarse-grained categories and simple reasoning over single entities, M$^3$-VQA introduces diverse multi-entity questions involving multiple distinct entities from both visual and textual sources. It requires models to perform both sequential and parallel multi-hop reasoning across multiple documents, supported by traceable, detailed evidence and a curated multimodal knowledge base. We evaluate 16 leading MLLMs under three settings: without external knowledge, with gold evidence, and with retrieval-augmented input. The poor results reveal significant challenges for MLLMs in knowledge acquisition and reasoning. Models perform poorly without external information but improve markedly when provided with precise evidence. Furthermore, reasoning-aware agentic retrieval surpasses heuristic methods, highlighting the importance of structured reasoning for complex multimodal understanding. M$^3$-VQA presents a more challenging evaluation for advancing the multimodal reasoning capabilities of MLLMs. Our code and dataset are available at https://github.com/CASIA-IVA-Lab/M3VQA.
Boter: Bootstrapping Knowledge Selection and Question Answering for Knowledge-based VQA
Apr 22, 2024



Knowledge-based Visual Question Answering (VQA) requires models to incorporate external knowledge to respond to questions about visual content. Previous methods mostly follow the "retrieve and generate" paradigm. Initially, they utilize a pre-trained retriever to fetch relevant knowledge documents, subsequently employing them to generate answers. While these methods have demonstrated commendable performance in the task, they possess limitations: (1) they employ an independent retriever to acquire knowledge solely based on the similarity between the query and knowledge embeddings, without assessing whether the knowledge document is truly conducive to helping answer the question; (2) they convert the image into text and then conduct retrieval and answering in natural language space, which may not ensure comprehensive acquisition of all image information. To address these limitations, we propose Boter, a novel framework designed to bootstrap knowledge selection and question answering by leveraging the robust multimodal perception capabilities of the Multimodal Large Language Model (MLLM). The framework consists of two modules: Selector and Answerer, where both are initialized by the MLLM and parameter-efficiently finetuned in a simple cycle: find key knowledge in the retrieved knowledge documents using the Selector, and then use them to finetune the Answerer to predict answers; obtain the pseudo-labels of key knowledge documents based on the predictions of the Answerer and weak supervision labels, and then finetune the Selector to select key knowledge; repeat. Our framework significantly enhances the performance of the baseline on the challenging open-domain Knowledge-based VQA benchmark, OK-VQA, achieving a state-of-the-art accuracy of 62.83%.
Knowledge Condensation and Reasoning for Knowledge-based VQA
Mar 15, 2024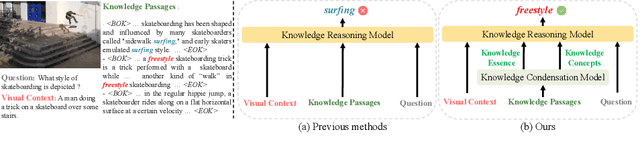
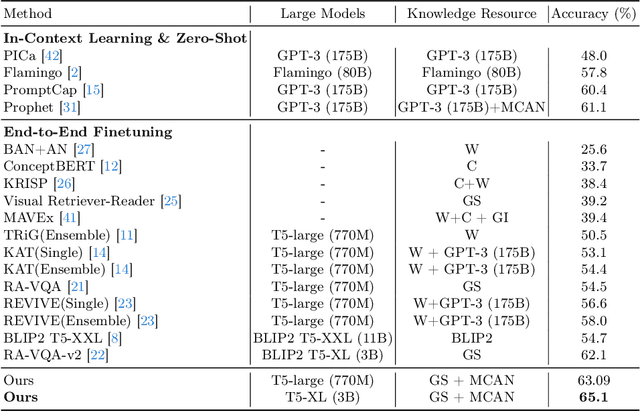
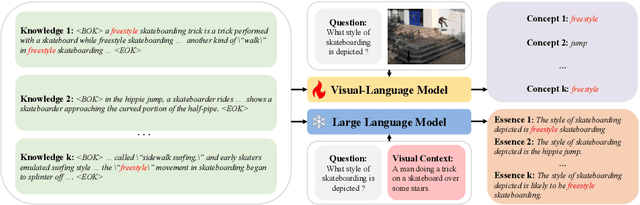

Knowledge-based visual question answering (KB-VQA) is a challenging task, which requires the model to leverage external knowledge for comprehending and answering questions grounded in visual content. Recent studies retrieve the knowledge passages from external knowledge bases and then use them to answer questions. However, these retrieved knowledge passages often contain irrelevant or noisy information, which limits the performance of the model. To address the challenge, we propose two synergistic models: Knowledge Condensation model and Knowledge Reasoning model. We condense the retrieved knowledge passages from two perspectives. First, we leverage the multimodal perception and reasoning ability of the visual-language models to distill concise knowledge concepts from retrieved lengthy passages, ensuring relevance to both the visual content and the question. Second, we leverage the text comprehension ability of the large language models to summarize and condense the passages into the knowledge essence which helps answer the question. These two types of condensed knowledge are then seamlessly integrated into our Knowledge Reasoning model, which judiciously navigates through the amalgamated information to arrive at the conclusive answer. Extensive experiments validate the superiority of the proposed method. Compared to previous methods, our method achieves state-of-the-art performance on knowledge-based VQA datasets (65.1% on OK-VQA and 60.1% on A-OKVQA) without resorting to the knowledge produced by GPT-3 (175B).