 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Learning-based Occluded Person Re-identification: A Survey
Jul 29, 2022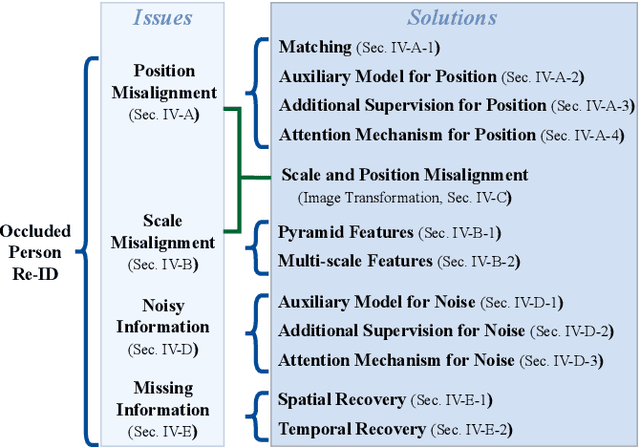
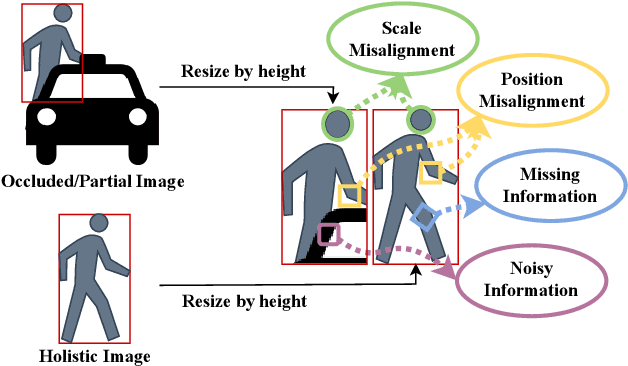

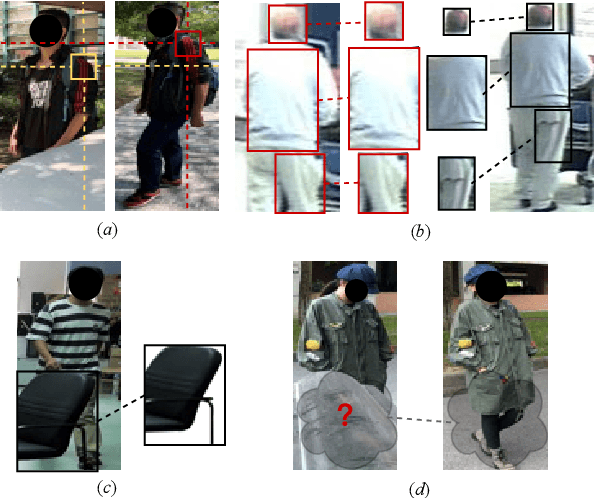
Occluded person re-identification (Re-ID) aims at addressing the occlusion problem when retrieving the person of interest across multiple cameras. With the promotion of deep learning technology and the increasing demand for intelligent video surveillance, the frequent occlusion in real-world applications has made occluded person Re-ID draw considerable interest from researchers. A large number of occluded person Re-ID methods have been proposed while there are few surveys that focus on occlusion. To fill this gap and help boost future research, this paper provides a systematic survey of occluded person Re-ID. Through an in-depth analysis of the occlusion in person Re-ID, most existing methods are found to only consider part of the problems brought by occlusion. Therefore, we review occlusion-related person Re-ID methods from the perspective of issues and solutions. We summarize four issues caused by occlusion in person Re-ID, i.e., position misalignment, scale misalignment, noisy information, and missing information. The occlusion-related methods addressing different issues are then categorized and introduced accordingly. After that, we summarize and compare the performance of recent occluded person Re-ID methods on four popular datasets: Partial-ReID, Partial-iLIDS, Occluded-ReID, and Occluded-DukeMTMC. Finally, we provide insights on promising future research directions.
A Robust Ensemble Model for Patasitic Egg Detection and Classification
Jul 04, 2022
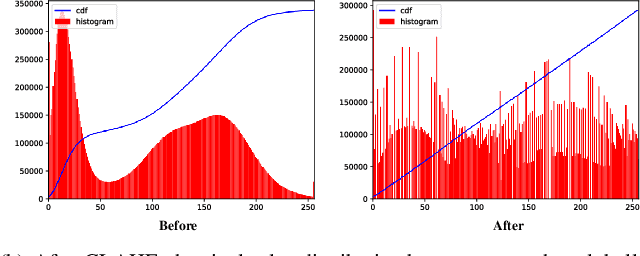
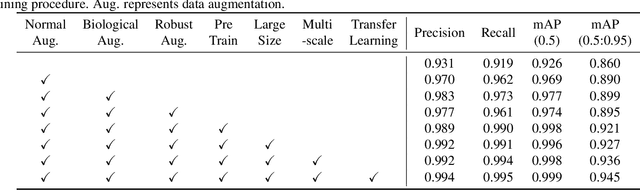
Intestinal parasitic infections, as a leading causes of morbidity worldwide, still lacks time-saving, high-sensitivity and user-friendly examination method. The development of deep learning technique reveals its broad application potential in biological image. In this paper, we apply several object detectors such as YOLOv5 and variant cascadeRCNNs to automatically discriminate parasitic eggs in microscope images. Through specially-designed optimization including raw data augmentation, model ensemble, transfer learning and test time augmentation, our model achieves excellent performance on challenge dataset. In addition, our model trained with added noise gains a high robustness against polluted input, which further broaden its applicability in practice.
mmFormer: Multimodal Medical Transformer for Incomplete Multimodal Learning of Brain Tumor Segmentation
Jun 06, 2022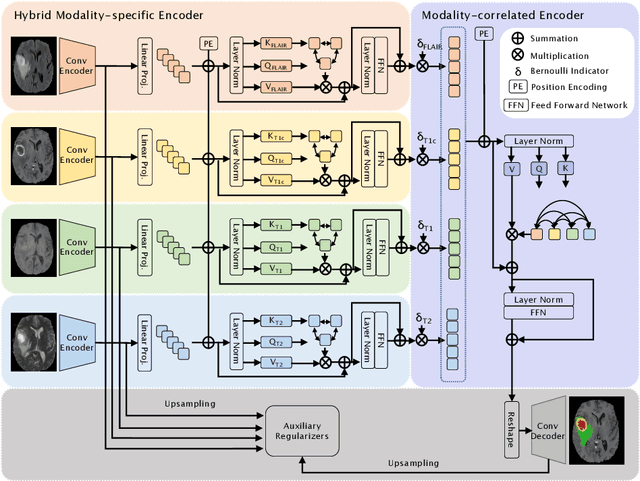
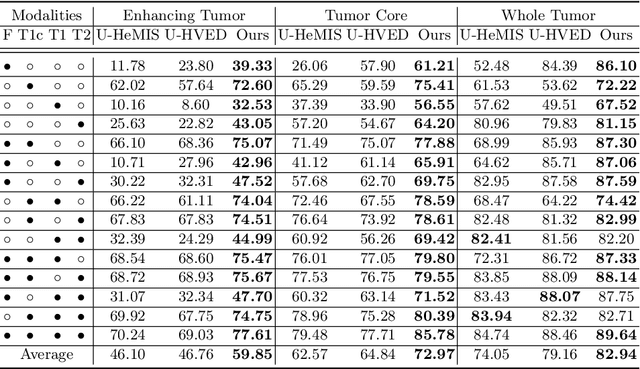

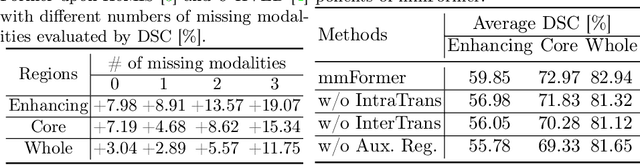
Accurate brain tumor segmentation from Magnetic Resonance Imaging (MRI) is desirable to joint learning of multimodal images. However, in clinical practice, it is not always possible to acquire a complete set of MRIs, and the problem of missing modalities causes severe performance degradation in existing multimodal segmentation methods. In this work, we present the first attempt to exploit the Transformer for multimodal brain tumor segmentation that is robust to any combinatorial subset of available modalities. Concretely, we propose a novel multimodal Medical Transformer (mmFormer) for incomplete multimodal learning with three main components: the hybrid modality-specific encoders that bridge a convolutional encoder and an intra-modal Transformer for both local and global context modeling within each modality; an inter-modal Transformer to build and align the long-range correlations across modalities for modality-invariant features with global semantics corresponding to tumor region; a decoder that performs a progressive up-sampling and fusion with the modality-invariant features to generate robust segmentation. Besides, auxiliary regularizers are introduced in both encoder and decoder to further enhance the model's robustness to incomplete modalities. We conduct extensive experiments on the public BraTS $2018$ dataset for brain tumor segmentation. The results demonstrate that the proposed mmFormer outperforms the state-of-the-art methods for incomplete multimodal brain tumor segmentation on almost all subsets of incomplete modalities, especially by an average 19.07% improvement of Dice on tumor segmentation with only one available modality. The code is available at https://github.com/YaoZhang93/mmFormer.
Decoupled Pyramid Correlation Network for Liver Tumor Segmentation from CT images
May 26, 2022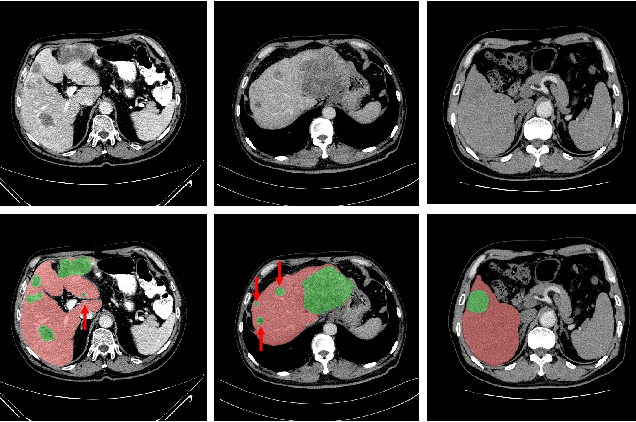
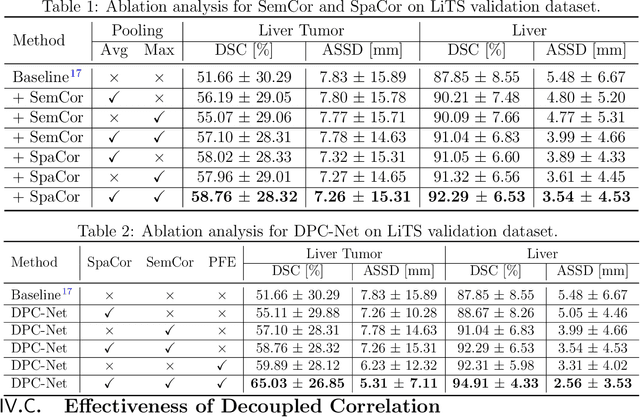
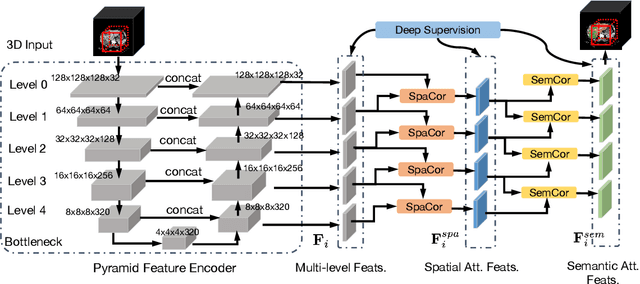
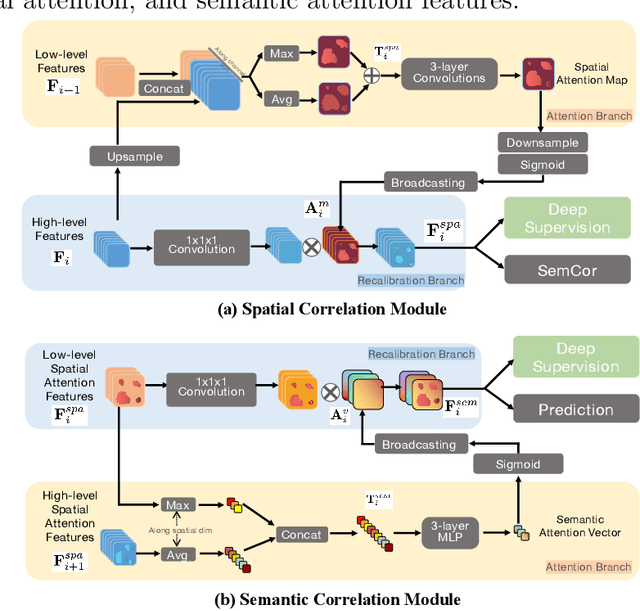
Purpose: Automated liver tumor segmentation from Computed Tomography (CT) images is a necessary prerequisite in the interventions of hepatic abnormalities and surgery planning. However, accurate liver tumor segmentation remains challenging due to the large variability of tumor sizes and inhomogeneous texture. Recent advances based on Fully Convolutional Network (FCN) for medical image segmentation drew on the success of learning discriminative pyramid features. In this paper, we propose a Decoupled Pyramid Correlation Network (DPC-Net) that exploits attention mechanisms to fully leverage both low- and high-level features embedded in FCN to segment liver tumor. Methods: We first design a powerful Pyramid Feature Encoder (PFE) to extract multi-level features from input images. Then we decouple the characteristics of features concerning spatial dimension (i.e., height, width, depth) and semantic dimension (i.e., channel). On top of that, we present two types of attention modules, Spatial Correlation (SpaCor) and Semantic Correlation (SemCor) modules, to recursively measure the correlation of multi-level features. The former selectively emphasizes global semantic information in low-level features with the guidance of high-level ones. The latter adaptively enhance spatial details in high-level features with the guidance of low-level ones. Results: We evaluate the DPC-Net on MICCAI 2017 LiTS Liver Tumor Segmentation (LiTS) challenge dataset. Dice Similarity Coefficient (DSC) and Average Symmetric Surface Distance (ASSD) are employed for evaluation. The proposed method obtains a DSC of 76.4% and an ASSD of 0.838 mm for liver tumor segmentation, outperforming the state-of-the-art methods. It also achieves a competitive results with a DSC of 96.0% and an ASSD of 1.636 mm for liver segmentation.
Designing the Topology of Graph Neural Networks: A Novel Feature Fusion Perspective
Dec 29, 2021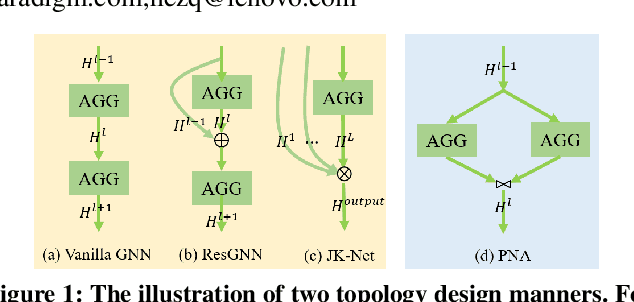

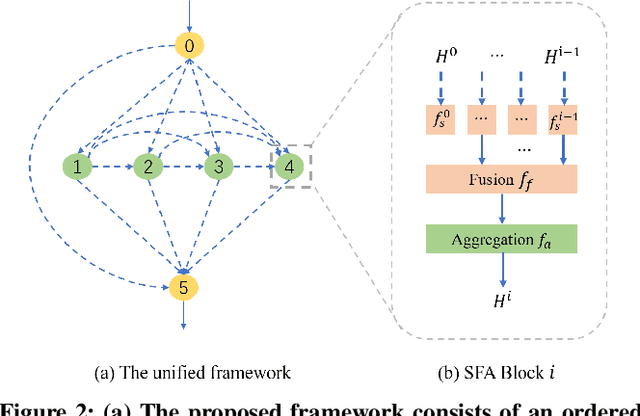
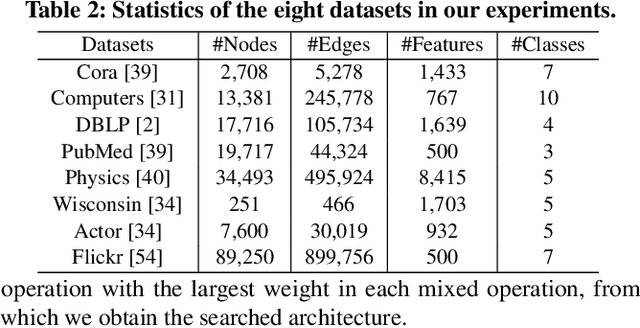
In recent years, Graph Neural Networks (GNNs) have shown superior performance on diverse real-world applications. To improve the model capacity, besides designing aggregation operations, GNN topology design is also very important. In general, there are two mainstream GNN topology design manners. The first one is to stack aggregation operations to obtain the higher-level features but easily got performance drop as the network goes deeper. Secondly, the multiple aggregation operations are utilized in each layer which provides adequate and independent feature extraction stage on local neighbors while are costly to obtain the higher-level information. To enjoy the benefits while alleviating the corresponding deficiencies of these two manners, we learn to design the topology of GNNs in a novel feature fusion perspective which is dubbed F$^2$GNN. To be specific, we provide a feature fusion perspective in designing GNN topology and propose a novel framework to unify the existing topology designs with feature selection and fusion strategies. Then we develop a neural architecture search method on top of the unified framework which contains a set of selection and fusion operations in the search space and an improved differentiable search algorithm. The performance gains on eight real-world datasets demonstrate the effectiveness of F$^2$GNN. We further conduct experiments to show that F$^2$GNN can improve the model capacity while alleviating the deficiencies of existing GNN topology design manners, especially alleviating the over-smoothing problem, by utilizing different levels of features adaptively.
Learn Layer-wise Connections in Graph Neural Networks
Dec 27, 2021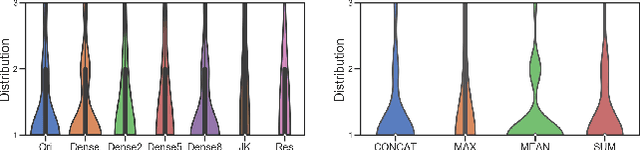

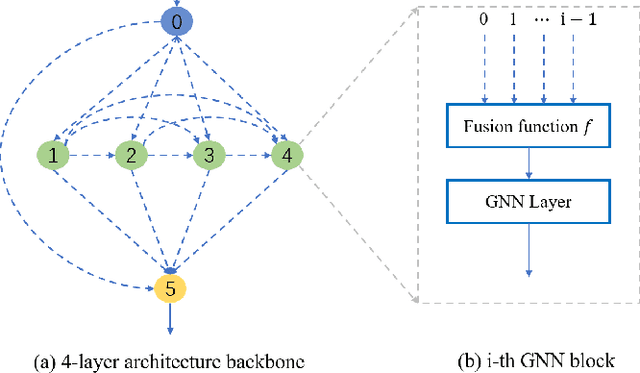
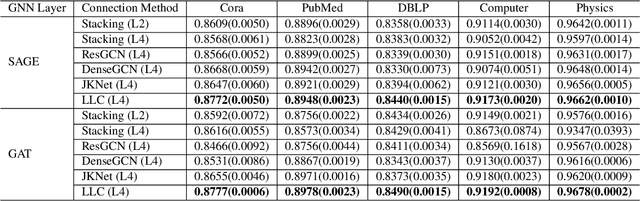
In recent years, Graph Neural Networks (GNNs) have shown superior performance on diverse applications on real-world datasets. To improve the model capacity and alleviate the over-smoothing problem, several methods proposed to incorporate the intermediate layers by layer-wise connections. However, due to the highly diverse graph types, the performance of existing methods vary on diverse graphs, leading to a need for data-specific layer-wise connection methods. To address this problem, we propose a novel framework LLC (Learn Layer-wise Connections) based on neural architecture search (NAS) to learn adaptive connections among intermediate layers in GNNs. LLC contains one novel search space which consists of 3 types of blocks and learnable connections, and one differentiable search algorithm to enable the efficient search process. Extensive experiments on five real-world datasets are conducted, and the results show that the searched layer-wise connections can not only improve the performance but also alleviate the over-smoothing problem.
A Survey of Visual Transformers
Nov 13, 2021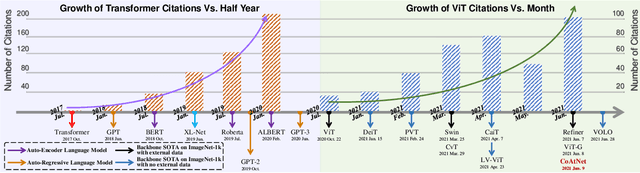
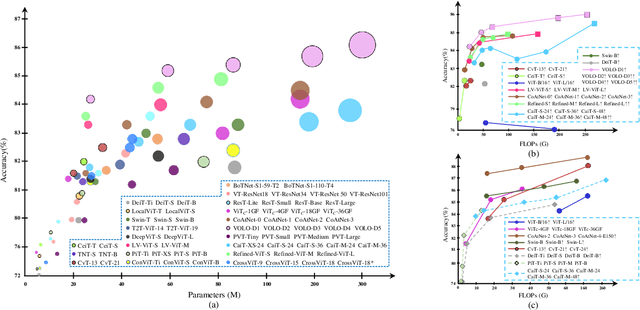
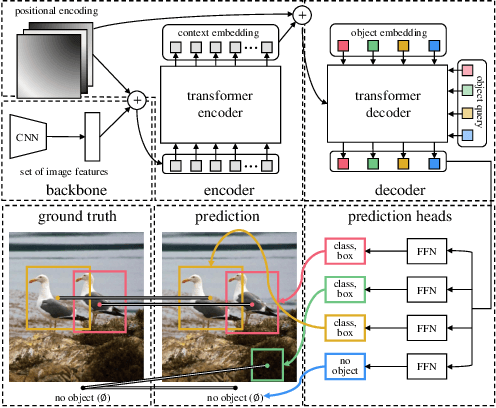
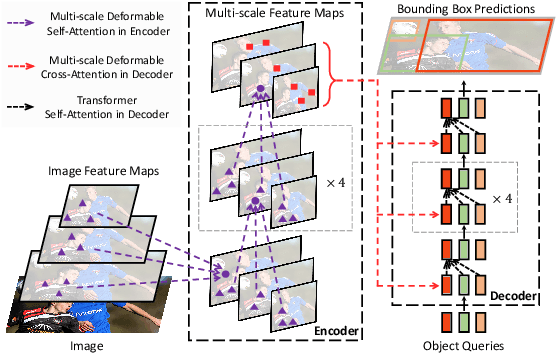
Transformer, an attention-based encoder-decoder architecture, has revolutionized the field of natural language processing. Inspired by this significant achievement, some pioneering works have recently been done on adapting Transformerliked architectures to Computer Vision (CV) fields, which have demonstrated their effectiveness on various CV tasks. Relying on competitive modeling capability, visual Transformers have achieved impressive performance on multiple benchmarks such as ImageNet, COCO, and ADE20k as compared with modern Convolution Neural Networks (CNN). In this paper, we have provided a comprehensive review of over one hundred different visual Transformers for three fundamental CV tasks (classification, detection, and segmentation), where a taxonomy is proposed to organize these methods according to their motivations, structures, and usage scenarios. Because of the differences in training settings and oriented tasks, we have also evaluated these methods on different configurations for easy and intuitive comparison instead of only various benchmarks. Furthermore, we have revealed a series of essential but unexploited aspects that may empower Transformer to stand out from numerous architectures, e.g., slack high-level semantic embeddings to bridge the gap between visual and sequential Transformers. Finally, three promising future research directions are suggested for further investment.
Learning Rich Features for Gait Recognition by Integrating Skeletons and Silhouettes
Oct 26, 2021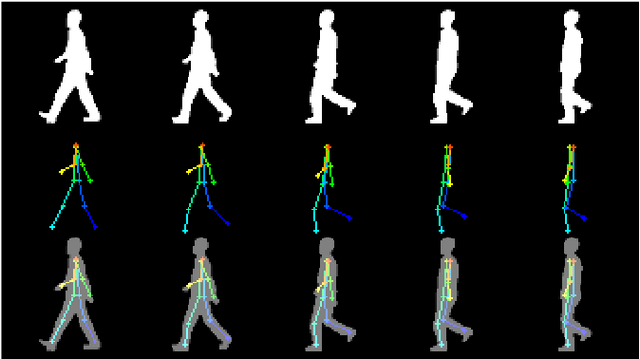
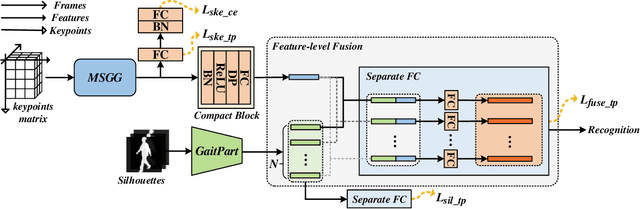
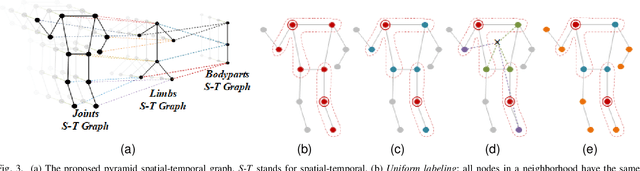
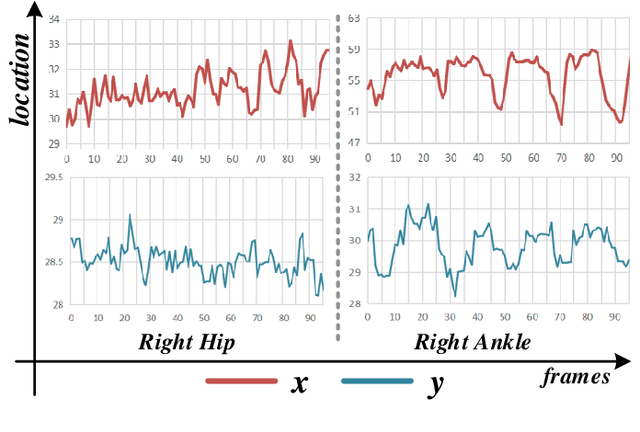
Gait recognition captures gait patterns from the walking sequence of an individual for identification. Most existing gait recognition methods learn features from silhouettes or skeletons for the robustness to clothing, carrying, and other exterior factors. The combination of the two data modalities, however, is not fully exploited. This paper proposes a simple yet effective bimodal fusion (BiFusion) network, which mines the complementary clues of skeletons and silhouettes, to learn rich features for gait identification. Particularly, the inherent hierarchical semantics of body joints in a skeleton is leveraged to design a novel Multi-scale Gait Graph (MSGG) network for the feature extraction of skeletons. Extensive experiments on CASIA-B and OUMVLP demonstrate both the superiority of the proposed MSGG network in modeling skeletons and the effectiveness of the bimodal fusion for gait recognition. Under the most challenging condition of walking in different clothes on CASIA-B, our method achieves the rank-1 accuracy of 92.1%.
Pooling Architecture Search for Graph Classification
Aug 24, 2021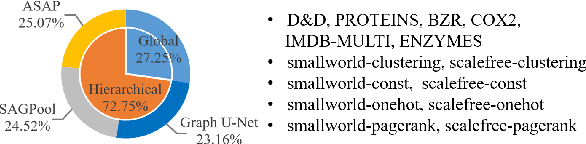
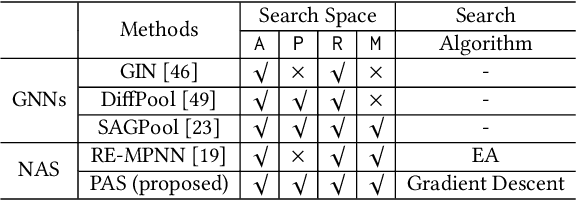
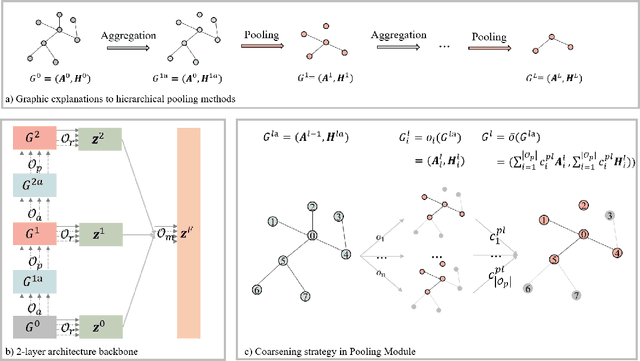
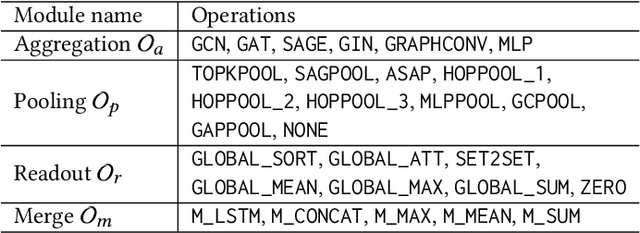
Graph classification is an important problem with applications across many domains, like chemistry and bioinformatics, for which graph neural networks (GNNs) have been state-of-the-art (SOTA) methods. GNNs are designed to learn node-level representation based on neighborhood aggregation schemes, and to obtain graph-level representation, pooling methods are applied after the aggregation operation in existing GNN models to generate coarse-grained graphs. However,due to highly diverse applications of graph classification, and the performance of existing pooling methods vary on different graphs. In other words, it is a challenging problem to design a universal pooling architecture to perform well in most cases, leading to a demand for data-specific pooling methods in real-world applications. To address this problem, we propose to use neural architecture search (NAS) to search for adaptive pooling architectures for graph classification. Firstly we designed a unified framework consisting of four modules: Aggregation, Pooling, Readout, and Merge, which can cover existing human-designed pooling methods for graph classification. Based on this framework, a novel search space is designed by incorporating popular operations in human-designed architectures. Then to enable efficient search, a coarsening strategy is proposed to continuously relax the search space, thus a differentiable search method can be adopted. Extensive experiments on six real-world datasets from three domains are conducted, and the results demonstrate the effectiveness and efficiency of the proposed framework.
TumorCP: A Simple but Effective Object-Level Data Augmentation for Tumor Segmentation
Jul 21, 2021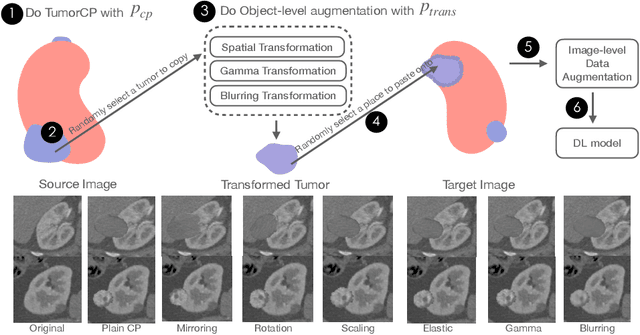
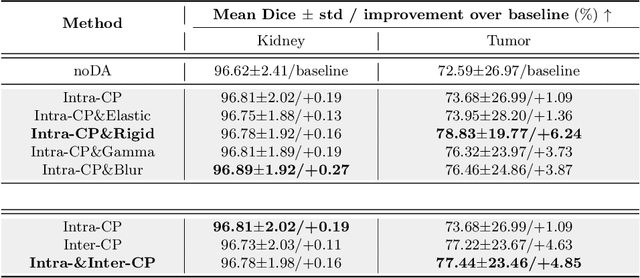


Deep learning models are notoriously data-hungry. Thus, there is an urging need for data-efficient techniques in medical image analysis, where well-annotated data are costly and time consuming to collect. Motivated by the recently revived "Copy-Paste" augmentation, we propose TumorCP, a simple but effective object-level data augmentation method tailored for tumor segmentation. TumorCP is online and stochastic, providing unlimited augmentation possibilities for tumors' subjects, locations, appearances, as well as morphologies. Experiments on kidney tumor segmentation task demonstrate that TumorCP surpasses the strong baseline by a remarkable margin of 7.12% on tumor Dice. Moreover, together with image-level data augmentation, it beats the current state-of-the-art by 2.32% on tumor Dice. Comprehensive ablation studies are performed to validate the effectiveness of TumorCP. Meanwhile, we show that TumorCP can lead to striking improvements in extremely low-data regimes. Evaluated with only 10% labeled data, TumorCP significantly boosts tumor Dice by 21.87%. To the best of our knowledge, this is the very first work exploring and extending the "Copy-Paste" design in medical imaging domain. Code is available at: https://github.com/YaoZhang93/TumorCP.