 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDemocratic or Authoritarian? Probing a New Dimension of Political Biases in Large Language Models
Jun 15, 2025As Large Language Models (LLMs) become increasingly integrated into everyday life and information ecosystems, concerns about their implicit biases continue to persist. While prior work has primarily examined socio-demographic and left--right political dimensions, little attention has been paid to how LLMs align with broader geopolitical value systems, particularly the democracy--authoritarianism spectrum. In this paper, we propose a novel methodology to assess such alignment, combining (1) the F-scale, a psychometric tool for measuring authoritarian tendencies, (2) FavScore, a newly introduced metric for evaluating model favorability toward world leaders, and (3) role-model probing to assess which figures are cited as general role-models by LLMs. We find that LLMs generally favor democratic values and leaders, but exhibit increases favorability toward authoritarian figures when prompted in Mandarin. Further, models are found to often cite authoritarian figures as role models, even outside explicit political contexts. These results shed light on ways LLMs may reflect and potentially reinforce global political ideologies, highlighting the importance of evaluating bias beyond conventional socio-political axes. Our code is available at: https://github.com/irenestrauss/Democratic-Authoritarian-Bias-LLMs
Improving Large Language Model Safety with Contrastive Representation Learning
Jun 13, 2025Large Language Models (LLMs) are powerful tools with profound societal impacts, yet their ability to generate responses to diverse and uncontrolled inputs leaves them vulnerable to adversarial attacks. While existing defenses often struggle to generalize across varying attack types, recent advancements in representation engineering offer promising alternatives. In this work, we propose a defense framework that formulates model defense as a contrastive representation learning (CRL) problem. Our method finetunes a model using a triplet-based loss combined with adversarial hard negative mining to encourage separation between benign and harmful representations. Our experimental results across multiple models demonstrate that our approach outperforms prior representation engineering-based defenses, improving robustness against both input-level and embedding-space attacks without compromising standard performance. Our code is available at https://github.com/samuelsimko/crl-llm-defense
Can Theoretical Physics Research Benefit from Language Agents?
Jun 06, 2025Large Language Models (LLMs) are rapidly advancing across diverse domains, yet their application in theoretical physics research is not yet mature. This position paper argues that LLM agents can potentially help accelerate theoretical, computational, and applied physics when properly integrated with domain knowledge and toolbox. We analyze current LLM capabilities for physics -- from mathematical reasoning to code generation -- identifying critical gaps in physical intuition, constraint satisfaction, and reliable reasoning. We envision future physics-specialized LLMs that could handle multimodal data, propose testable hypotheses, and design experiments. Realizing this vision requires addressing fundamental challenges: ensuring physical consistency, and developing robust verification methods. We call for collaborative efforts between physics and AI communities to help advance scientific discovery in physics.
Revisiting Multi-Agent Debate as Test-Time Scaling: A Systematic Study of Conditional Effectiveness
May 29, 2025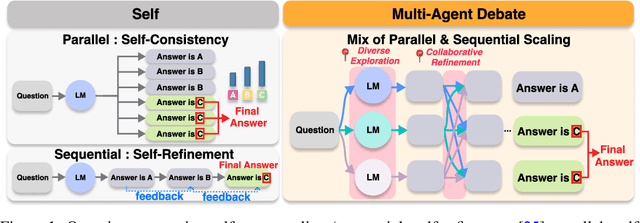
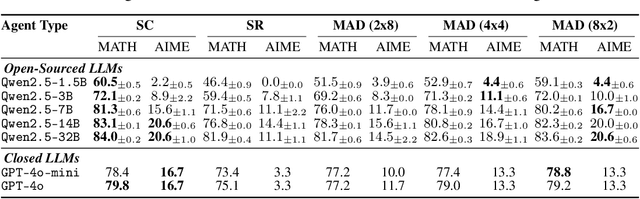
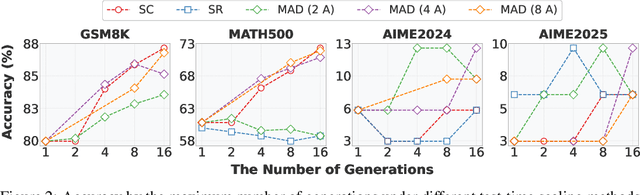
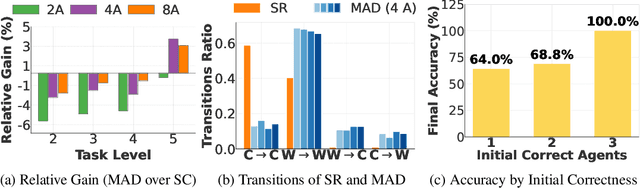
The remarkable growth in large language model (LLM) capabilities has spurred exploration into multi-agent systems, with debate frameworks emerging as a promising avenue for enhanced problem-solving. These multi-agent debate (MAD) approaches, where agents collaboratively present, critique, and refine arguments, potentially offer improved reasoning, robustness, and diverse perspectives over monolithic models. Despite prior studies leveraging MAD, a systematic understanding of its effectiveness compared to self-agent methods, particularly under varying conditions, remains elusive. This paper seeks to fill this gap by conceptualizing MAD as a test-time computational scaling technique, distinguished by collaborative refinement and diverse exploration capabilities. We conduct a comprehensive empirical investigation comparing MAD with strong self-agent test-time scaling baselines on mathematical reasoning and safety-related tasks. Our study systematically examines the influence of task difficulty, model scale, and agent diversity on MAD's performance. Key findings reveal that, for mathematical reasoning, MAD offers limited advantages over self-agent scaling but becomes more effective with increased problem difficulty and decreased model capability, while agent diversity shows little benefit. Conversely, for safety tasks, MAD's collaborative refinement can increase vulnerability, but incorporating diverse agent configurations facilitates a gradual reduction in attack success through the collaborative refinement process. We believe our findings provide critical guidance for the future development of more effective and strategically deployed MAD systems.
NLP for Social Good: A Survey of Challenges, Opportunities, and Responsible Deployment
May 28, 2025



Recent advancements in large language models (LLMs) have unlocked unprecedented possibilities across a range of applications. However, as a community, we believe that the field of Natural Language Processing (NLP) has a growing need to approach deployment with greater intentionality and responsibility. In alignment with the broader vision of AI for Social Good (Toma\v{s}ev et al., 2020), this paper examines the role of NLP in addressing pressing societal challenges. Through a cross-disciplinary analysis of social goals and emerging risks, we highlight promising research directions and outline challenges that must be addressed to ensure responsible and equitable progress in NLP4SG research.
Are Language Models Consequentialist or Deontological Moral Reasoners?
May 27, 2025As AI systems increasingly navigate applications in healthcare, law, and governance, understanding how they handle ethically complex scenarios becomes critical. Previous work has mainly examined the moral judgments in large language models (LLMs), rather than their underlying moral reasoning process. In contrast, we focus on a large-scale analysis of the moral reasoning traces provided by LLMs. Furthermore, unlike prior work that attempted to draw inferences from only a handful of moral dilemmas, our study leverages over 600 distinct trolley problems as probes for revealing the reasoning patterns that emerge within different LLMs. We introduce and test a taxonomy of moral rationales to systematically classify reasoning traces according to two main normative ethical theories: consequentialism and deontology. Our analysis reveals that LLM chains-of-thought tend to favor deontological principles based on moral obligations, while post-hoc explanations shift notably toward consequentialist rationales that emphasize utility. Our framework provides a foundation for understanding how LLMs process and articulate ethical considerations, an important step toward safe and interpretable deployment of LLMs in high-stakes decision-making environments. Our code is available at https://github.com/keenansamway/moral-lens .
When Ethics and Payoffs Diverge: LLM Agents in Morally Charged Social Dilemmas
May 25, 2025Recent advances in large language models (LLMs) have enabled their use in complex agentic roles, involving decision-making with humans or other agents, making ethical alignment a key AI safety concern. While prior work has examined both LLMs' moral judgment and strategic behavior in social dilemmas, there is limited understanding of how they act when moral imperatives directly conflict with rewards or incentives. To investigate this, we introduce Moral Behavior in Social Dilemma Simulation (MoralSim) and evaluate how LLMs behave in the prisoner's dilemma and public goods game with morally charged contexts. In MoralSim, we test a range of frontier models across both game structures and three distinct moral framings, enabling a systematic examination of how LLMs navigate social dilemmas in which ethical norms conflict with payoff-maximizing strategies. Our results show substantial variation across models in both their general tendency to act morally and the consistency of their behavior across game types, the specific moral framing, and situational factors such as opponent behavior and survival risks. Crucially, no model exhibits consistently moral behavior in MoralSim, highlighting the need for caution when deploying LLMs in agentic roles where the agent's "self-interest" may conflict with ethical expectations. Our code is available at https://github.com/sbackmann/moralsim.
Accidental Misalignment: Fine-Tuning Language Models Induces Unexpected Vulnerability
May 22, 2025



As large language models gain popularity, their vulnerability to adversarial attacks remains a primary concern. While fine-tuning models on domain-specific datasets is often employed to improve model performance, it can introduce vulnerabilities within the underlying model. In this work, we investigate Accidental Misalignment, unexpected vulnerabilities arising from characteristics of fine-tuning data. We begin by identifying potential correlation factors such as linguistic features, semantic similarity, and toxicity within our experimental datasets. We then evaluate the adversarial performance of these fine-tuned models and assess how dataset factors correlate with attack success rates. Lastly, we explore potential causal links, offering new insights into adversarial defense strategies and highlighting the crucial role of dataset design in preserving model alignment. Our code is available at https://github.com/psyonp/accidental_misalignment.
Causality for Natural Language Processing
Apr 20, 2025Causal reasoning is a cornerstone of human intelligence and a critical capability for artificial systems aiming to achieve advanced understanding and decision-making. This thesis delves into various dimensions of causal reasoning and understanding in large language models (LLMs). It encompasses a series of studies that explore the causal inference skills of LLMs, the mechanisms behind their performance, and the implications of causal and anticausal learning for natural language processing (NLP) tasks. Additionally, it investigates the application of causal reasoning in text-based computational social science, specifically focusing on political decision-making and the evaluation of scientific impact through citations. Through novel datasets, benchmark tasks, and methodological frameworks, this work identifies key challenges and opportunities to improve the causal capabilities of LLMs, providing a comprehensive foundation for future research in this evolving field.
The Reasoning-Memorization Interplay in Language Models Is Mediated by a Single Direction
Mar 29, 2025



Large language models (LLMs) excel on a variety of reasoning benchmarks, but previous studies suggest they sometimes struggle to generalize to unseen questions, potentially due to over-reliance on memorized training examples. However, the precise conditions under which LLMs switch between reasoning and memorization during text generation remain unclear. In this work, we provide a mechanistic understanding of LLMs' reasoning-memorization dynamics by identifying a set of linear features in the model's residual stream that govern the balance between genuine reasoning and memory recall. These features not only distinguish reasoning tasks from memory-intensive ones but can also be manipulated to causally influence model performance on reasoning tasks. Additionally, we show that intervening in these reasoning features helps the model more accurately activate the most relevant problem-solving capabilities during answer generation. Our findings offer new insights into the underlying mechanisms of reasoning and memory in LLMs and pave the way for the development of more robust and interpretable generative AI systems.