 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMirage Persistent Kernel: A Compiler and Runtime for Mega-Kernelizing Tensor Programs
Dec 22, 2025We introduce Mirage Persistent Kernel (MPK), the first compiler and runtime system that automatically transforms multi-GPU model inference into a single high-performance megakernel. MPK introduces an SM-level graph representation that captures data dependencies at the granularity of individual streaming multiprocessors (SMs), enabling cross-operator software pipelining, fine-grained kernel overlap, and other previously infeasible GPU optimizations. The MPK compiler lowers tensor programs into highly optimized SM-level task graphs and generates optimized CUDA implementations for all tasks, while the MPK in-kernel parallel runtime executes these tasks within a single mega-kernel using decentralized scheduling across SMs. Together, these components provide end-to-end kernel fusion with minimal developer effort, while preserving the flexibility of existing programming models. Our evaluation shows that MPK significantly outperforms existing kernel-per-operator LLM serving systems by reducing end-to-end inference latency by up to 1.7x, pushing LLM inference performance close to hardware limits. MPK is publicly available at https://github.com/mirage-project/mirage.
Less Is More: Training-Free Sparse Attention with Global Locality for Efficient Reasoning
Aug 09, 2025Large reasoning models achieve strong performance through test-time scaling but incur substantial computational overhead, particularly from excessive token generation when processing short input prompts. While sparse attention mechanisms can reduce latency and memory usage, existing approaches suffer from significant accuracy degradation due to accumulated errors during long-generation reasoning. These methods generally require either high token retention rates or expensive retraining. We introduce LessIsMore, a training-free sparse attention mechanism for reasoning tasks, which leverages global attention patterns rather than relying on traditional head-specific local optimizations. LessIsMore aggregates token selections from local attention heads with recent contextual information, enabling unified cross-head token ranking for future decoding layers. This unified selection improves generalization and efficiency by avoiding the need to maintain separate token subsets per head. Evaluation across diverse reasoning tasks and benchmarks shows that LessIsMore preserves -- and in some cases improves -- accuracy while achieving a $1.1\times$ average decoding speed-up compared to full attention. Moreover, LessIsMore attends to $2\times$ fewer tokens without accuracy loss, achieving a $1.13\times$ end-to-end speed-up compared to existing sparse attention methods.
Nexus: Taming Throughput-Latency Tradeoff in LLM Serving via Efficient GPU Sharing
Jul 09, 2025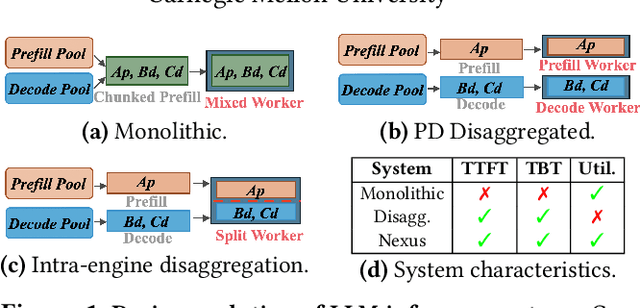
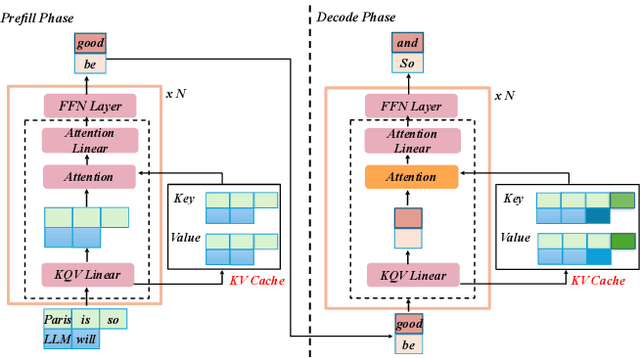
Current prefill-decode (PD) disaggregation is typically deployed at the level of entire serving engines, assigning separate GPUs to handle prefill and decode phases. While effective at reducing latency, this approach demands more hardware. To improve GPU utilization, Chunked Prefill mixes prefill and decode requests within the same batch, but introduces phase interference between prefill and decode. While existing PD disaggregation solutions separate the phases across GPUs, we ask: can the same decoupling be achieved within a single serving engine? The key challenge lies in managing the conflicting resource requirements of prefill and decode when they share the same hardware. In this paper, we first show that chunked prefill requests cause interference with decode requests due to their distinct requirements for GPU resources. Second, we find that GPU resources exhibit diminishing returns. Beyond a saturation point, increasing GPU allocation yields negligible latency improvements. This insight enables us to split a single GPU's resources and dynamically allocate them to prefill and decode on the fly, effectively disaggregating the two phases within the same GPU. Across a range of models and workloads, our system Nexus achieves up to 2.2x higher throughput, 20x lower TTFT, and 2.5x lower TBT than vLLM. It also outperforms SGLang with up to 2x higher throughput, 2x lower TTFT, and 1.7x lower TBT, and achieves 1.4x higher throughput than vLLM-disaggregation using only half the number of GPUs.
DDO: Dual-Decision Optimization via Multi-Agent Collaboration for LLM-Based Medical Consultation
May 24, 2025



Large Language Models (LLMs) demonstrate strong generalization and reasoning abilities, making them well-suited for complex decision-making tasks such as medical consultation (MC). However, existing LLM-based methods often fail to capture the dual nature of MC, which entails two distinct sub-tasks: symptom inquiry, a sequential decision-making process, and disease diagnosis, a classification problem. This mismatch often results in ineffective symptom inquiry and unreliable disease diagnosis. To address this, we propose \textbf{DDO}, a novel LLM-based framework that performs \textbf{D}ual-\textbf{D}ecision \textbf{O}ptimization by decoupling and independently optimizing the the two sub-tasks through a collaborative multi-agent workflow. Experiments on three real-world MC datasets show that DDO consistently outperforms existing LLM-based approaches and achieves competitive performance with state-of-the-art generation-based methods, demonstrating its effectiveness in the MC task.
SpecReason: Fast and Accurate Inference-Time Compute via Speculative Reasoning
Apr 10, 2025



Recent advances in inference-time compute have significantly improved performance on complex tasks by generating long chains of thought (CoTs) using Large Reasoning Models (LRMs). However, this improved accuracy comes at the cost of high inference latency due to the length of generated reasoning sequences and the autoregressive nature of decoding. Our key insight in tackling these overheads is that LRM inference, and the reasoning that it embeds, is highly tolerant of approximations: complex tasks are typically broken down into simpler steps, each of which brings utility based on the semantic insight it provides for downstream steps rather than the exact tokens it generates. Accordingly, we introduce SpecReason, a system that automatically accelerates LRM inference by using a lightweight model to (speculatively) carry out simpler intermediate reasoning steps and reserving the costly base model only to assess (and potentially correct) the speculated outputs. Importantly, SpecReason's focus on exploiting the semantic flexibility of thinking tokens in preserving final-answer accuracy is complementary to prior speculation techniques, most notably speculative decoding, which demands token-level equivalence at each step. Across a variety of reasoning benchmarks, SpecReason achieves 1.5-2.5$\times$ speedup over vanilla LRM inference while improving accuracy by 1.0-9.9\%. Compared to speculative decoding without SpecReason, their combination yields an additional 19.4-44.2\% latency reduction. We open-source SpecReason at https://github.com/ruipeterpan/specreason.
AdaServe: SLO-Customized LLM Serving with Fine-Grained Speculative Decoding
Jan 21, 2025This paper introduces AdaServe, the first LLM serving system to support SLO customization through fine-grained speculative decoding. AdaServe leverages the logits of a draft model to predict the speculative accuracy of tokens and employs a theoretically optimal algorithm to construct token trees for verification. To accommodate diverse SLO requirements without compromising throughput, AdaServe employs a speculation-and-selection scheme that first constructs candidate token trees for each request and then dynamically selects tokens to meet individual SLO constraints while optimizing throughput. Comprehensive evaluations demonstrate that AdaServe achieves up to 73% higher SLO attainment and 74% higher goodput compared to state-of-the-art systems. These results underscore AdaServe's potential to enhance the efficiency and adaptability of LLM deployments across varied application scenarios.
Communication Bounds for the Distributed Experts Problem
Jan 06, 2025In this work, we study the experts problem in the distributed setting where an expert's cost needs to be aggregated across multiple servers. Our study considers various communication models such as the message-passing model and the broadcast model, along with multiple aggregation functions, such as summing and taking the $\ell_p$ norm of an expert's cost across servers. We propose the first communication-efficient protocols that achieve near-optimal regret in these settings, even against a strong adversary who can choose the inputs adaptively. Additionally, we give a conditional lower bound showing that the communication of our protocols is nearly optimal. Finally, we implement our protocols and demonstrate empirical savings on the HPO-B benchmarks.
SuffixDecoding: A Model-Free Approach to Speeding Up Large Language Model Inference
Nov 07, 2024



We present SuffixDecoding, a novel model-free approach to accelerating large language model (LLM) inference through speculative decoding. Unlike existing methods that rely on draft models or specialized decoding heads, SuffixDecoding leverages suffix trees built from previously generated outputs to efficiently predict candidate token sequences. Our approach enables flexible tree-structured speculation without the overhead of maintaining and orchestrating additional models. SuffixDecoding builds and dynamically updates suffix trees to capture patterns in the generated text, using them to construct speculation trees through a principled scoring mechanism based on empirical token frequencies. SuffixDecoding requires only CPU memory which is plentiful and underutilized on typical LLM serving nodes. We demonstrate that SuffixDecoding achieves competitive speedups compared to model-based approaches across diverse workloads including open-domain chat, code generation, and text-to-SQL tasks. For open-ended chat and code generation tasks, SuffixDecoding achieves up to $1.4\times$ higher output throughput than SpecInfer and up to $1.1\times$ lower time-per-token (TPOT) latency. For a proprietary multi-LLM text-to-SQL application, SuffixDecoding achieves up to $2.9\times$ higher output throughput and $3\times$ lower latency than speculative decoding. Our evaluation shows that SuffixDecoding maintains high acceptance rates even with small reference corpora of 256 examples, while continuing to improve performance as more historical outputs are incorporated.
MagicPIG: LSH Sampling for Efficient LLM Generation
Oct 21, 2024



Large language models (LLMs) with long context windows have gained significant attention. However, the KV cache, stored to avoid re-computation, becomes a bottleneck. Various dynamic sparse or TopK-based attention approximation methods have been proposed to leverage the common insight that attention is sparse. In this paper, we first show that TopK attention itself suffers from quality degradation in certain downstream tasks because attention is not always as sparse as expected. Rather than selecting the keys and values with the highest attention scores, sampling with theoretical guarantees can provide a better estimation for attention output. To make the sampling-based approximation practical in LLM generation, we propose MagicPIG, a heterogeneous system based on Locality Sensitive Hashing (LSH). MagicPIG significantly reduces the workload of attention computation while preserving high accuracy for diverse tasks. MagicPIG stores the LSH hash tables and runs the attention computation on the CPU, which allows it to serve longer contexts and larger batch sizes with high approximation accuracy. MagicPIG can improve decoding throughput by $1.9\sim3.9\times$ across various GPU hardware and achieve 110ms decoding latency on a single RTX 4090 for Llama-3.1-8B-Instruct model with a context of 96k tokens. The code is available at \url{https://github.com/Infini-AI-Lab/MagicPIG}.
TidalDecode: Fast and Accurate LLM Decoding with Position Persistent Sparse Attention
Oct 07, 2024Large language models (LLMs) have driven significant advancements across diverse NLP tasks, with long-context models gaining prominence for handling extended inputs. However, the expanding key-value (KV) cache size required by Transformer architectures intensifies the memory constraints, particularly during the decoding phase, creating a significant bottleneck. Existing sparse attention mechanisms designed to address this bottleneck have two limitations: (1) they often fail to reliably identify the most relevant tokens for attention, and (2) they overlook the spatial coherence of token selection across consecutive Transformer layers, which can lead to performance degradation and substantial overhead in token selection. This paper introduces TidalDecode, a simple yet effective algorithm and system for fast and accurate LLM decoding through position persistent sparse attention. TidalDecode leverages the spatial coherence of tokens selected by existing sparse attention methods and introduces a few token selection layers that perform full attention to identify the tokens with the highest attention scores, while all other layers perform sparse attention with the pre-selected tokens. This design enables TidalDecode to substantially reduce the overhead of token selection for sparse attention without sacrificing the quality of the generated results. Evaluation on a diverse set of LLMs and tasks shows that TidalDecode closely matches the generative performance of full attention methods while reducing the LLM decoding latency by up to 2.1x.