 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Scalable Multi-GPU Framework for Encrypted Large-Model Inference
Dec 12, 2025Encrypted AI using fully homomorphic encryption (FHE) provides strong privacy guarantees; but its slow performance has limited practical deployment. Recent works proposed ASICs to accelerate FHE, but require expensive advanced manufacturing processes that constrain their accessibility. GPUs are a far more accessible platform, but achieving ASIC-level performance using GPUs has remained elusive. Furthermore, state-of-the-art approaches primarily focus on small models that fit comfortably within a single device. Supporting large models such as LLMs in FHE introduces a dramatic increase in computational complexity that requires optimized GPU kernels, along with managing terabyte-scale memory footprints that far exceed the capacity of a single GPU. This paper presents Cerium, a multi-GPU framework for FHE inference on large models. Cerium integrates a domain-specific language, an optimizing compiler, and a runtime system to automatically generate high-performance GPU kernels, manage terabyte-scale memory footprints, and parallelize computation across multiple GPUs. It introduces new IR constructs, compiler passes, sparse polynomial representations, memory-efficient data layouts, and communication-aware parallelization techniques that together enable encrypted inference for models ranging from small CNNs to Llama3-8B. We build Cerium on NVIDIA GPUs and demonstrate significant performance gains. For small models, Cerium outperforms expert-written hand-optimized GPU libraries by up to 2.25 times. Cerium achieves performance competitive with state-of-the-art FHE ASICs, outright matching prior FHE ASIC CraterLake. It is the first GPU system to execute bootstrapping in under 10 milliseconds, achieving 7.5 milliseconds, and is the first to demonstrate encrypted inference for BERT-Base and Llama3-8B in 8 seconds and 134 seconds, respectively.
Communication Bounds for the Distributed Experts Problem
Jan 06, 2025In this work, we study the experts problem in the distributed setting where an expert's cost needs to be aggregated across multiple servers. Our study considers various communication models such as the message-passing model and the broadcast model, along with multiple aggregation functions, such as summing and taking the $\ell_p$ norm of an expert's cost across servers. We propose the first communication-efficient protocols that achieve near-optimal regret in these settings, even against a strong adversary who can choose the inputs adaptively. Additionally, we give a conditional lower bound showing that the communication of our protocols is nearly optimal. Finally, we implement our protocols and demonstrate empirical savings on the HPO-B benchmarks.
HR Human: Modeling Human Avatars with Triangular Mesh and High-Resolution Textures from Videos
May 18, 2024Recently, implicit neural representation has been widely used to generate animatable human avatars. However, the materials and geometry of those representations are coupled in the neural network and hard to edit, which hinders their application in traditional graphics engines. We present a framework for acquiring human avatars that are attached with high-resolution physically-based material textures and triangular mesh from monocular video. Our method introduces a novel information fusion strategy to combine the information from the monocular video and synthesize virtual multi-view images to tackle the sparsity of the input view. We reconstruct humans as deformable neural implicit surfaces and extract triangle mesh in a well-behaved pose as the initial mesh of the next stage. In addition, we introduce an approach to correct the bias for the boundary and size of the coarse mesh extracted. Finally, we adapt prior knowledge of the latent diffusion model at super-resolution in multi-view to distill the decomposed texture. Experiments show that our approach outperforms previous representations in terms of high fidelity, and this explicit result supports deployment on common renderers.
Attacking LLM Watermarks by Exploiting Their Strengths
Feb 25, 2024



Advances in generative models have made it possible for AI-generated text, code, and images to mirror human-generated content in many applications. Watermarking, a technique that aims to embed information in the output of a model to verify its source, is useful for mitigating misuse of such AI-generated content. However, existing watermarking schemes remain surprisingly susceptible to attack. In particular, we show that desirable properties shared by existing LLM watermarking systems such as quality preservation, robustness, and public detection APIs can in turn make these systems vulnerable to various attacks. We rigorously study potential attacks in terms of common watermark design choices, and propose best practices and defenses for mitigation -- establishing a set of practical guidelines for embedding and detection of LLM watermarks.
Helen: Maliciously Secure Coopetitive Learning for Linear Models
Sep 03, 2019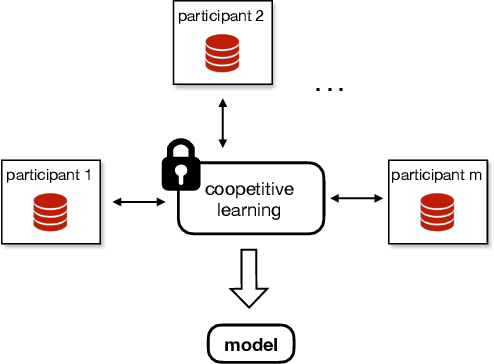

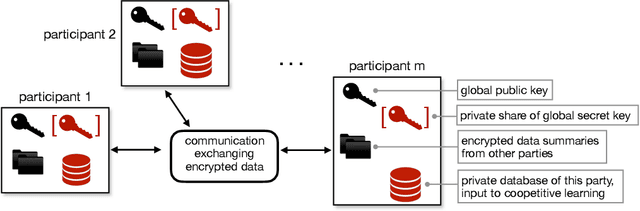

Many organizations wish to collaboratively train machine learning models on their combined datasets for a common benefit (e.g., better medical research, or fraud detection). However, they often cannot share their plaintext datasets due to privacy concerns and/or business competition. In this paper, we design and build Helen, a system that allows multiple parties to train a linear model without revealing their data, a setting we call coopetitive learning. Compared to prior secure training systems, Helen protects against a much stronger adversary who is malicious and can compromise m-1 out of m parties. Our evaluation shows that Helen can achieve up to five orders of magnitude of performance improvement when compared to training using an existing state-of-the-art secure multi-party computation framework.