 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Attention in Machine Reading Comprehension
Aug 26, 2021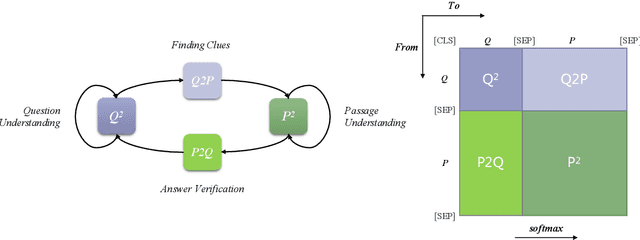
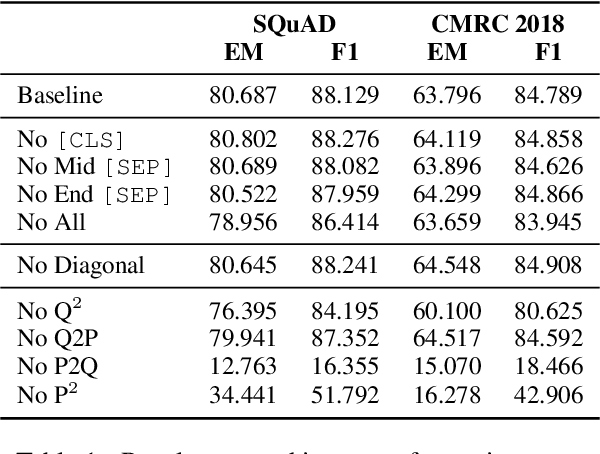
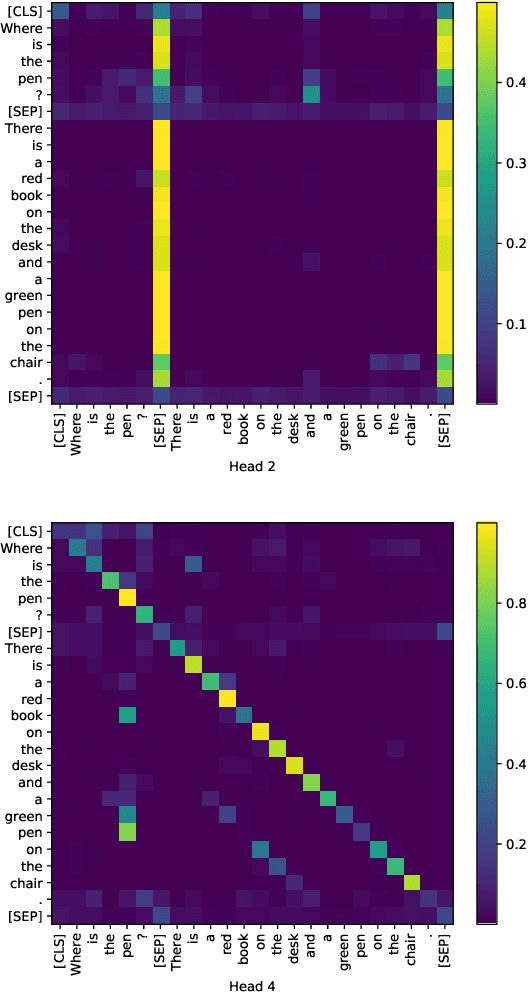
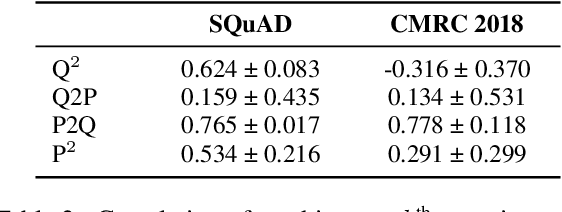
Achieving human-level performance on some of Machine Reading Comprehension (MRC) datasets is no longer challenging with the help of powerful Pre-trained Language Models (PLMs). However, the internal mechanism of these artifacts still remains unclear, placing an obstacle for further understanding these models. This paper focuses on conducting a series of analytical experiments to examine the relations between the multi-head self-attention and the final performance, trying to analyze the potential explainability in PLM-based MRC models. We perform quantitative analyses on SQuAD (English) and CMRC 2018 (Chinese), two span-extraction MRC datasets, on top of BERT, ALBERT, and ELECTRA in various aspects. We discover that {\em passage-to-question} and {\em passage understanding} attentions are the most important ones, showing strong correlations to the final performance than other parts. Through visualizations and case studies, we also observe several general findings on the attention maps, which could be helpful to understand how these models solve the questions.
Multi-Modal Chorus Recognition for Improving Song Search
Jun 27, 2021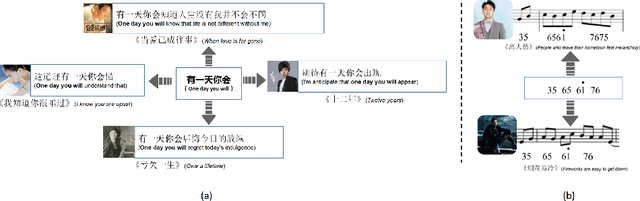
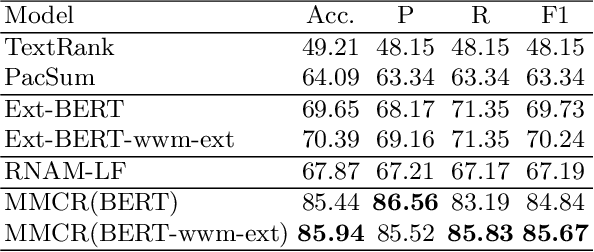
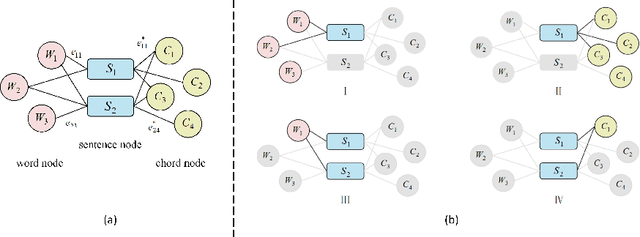
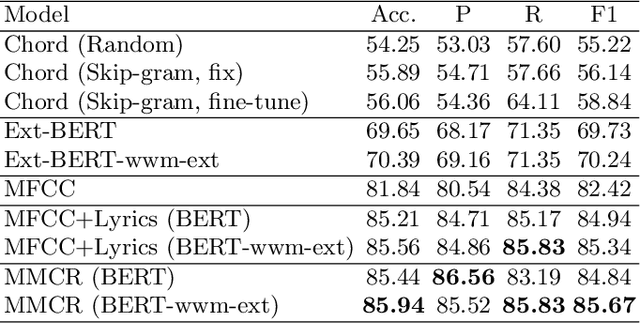
We discuss a novel task, Chorus Recognition, which could potentially benefit downstream tasks such as song search and music summarization. Different from the existing tasks such as music summarization or lyrics summarization relying on single-modal information, this paper models chorus recognition as a multi-modal one by utilizing both the lyrics and the tune information of songs. We propose a multi-modal Chorus Recognition model that considers diverse features. Besides, we also create and publish the first Chorus Recognition dataset containing 627 songs for public use. Our empirical study performed on the dataset demonstrates that our approach outperforms several baselines in chorus recognition. In addition, our approach also helps to improve the accuracy of its downstream task - song search by more than 10.6%.
CIL: Contrastive Instance Learning Framework for Distantly Supervised Relation Extraction
Jun 21, 2021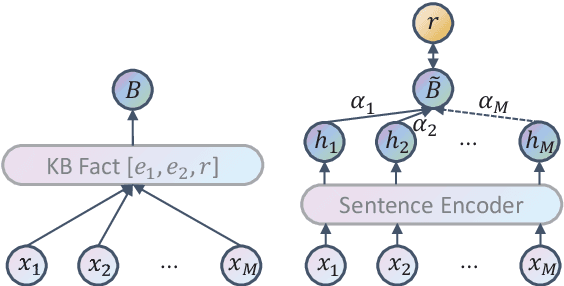
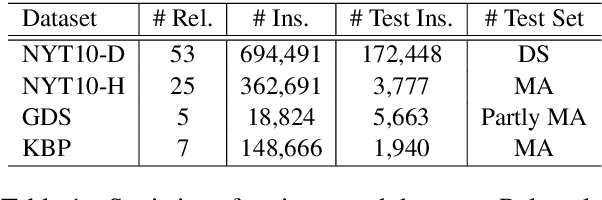
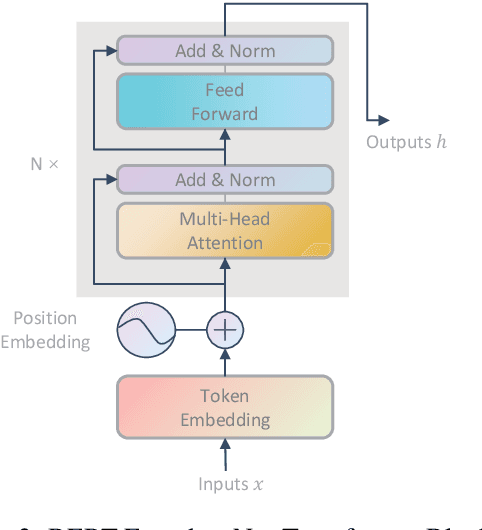
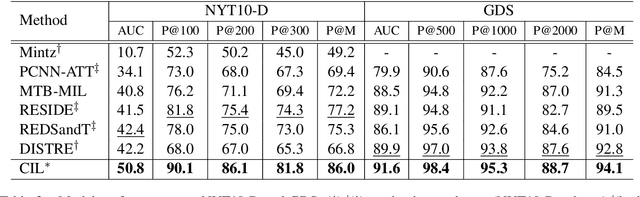
The journey of reducing noise from distant supervision (DS) generated training data has been started since the DS was first introduced into the relation extraction (RE) task. For the past decade, researchers apply the multi-instance learning (MIL) framework to find the most reliable feature from a bag of sentences. Although the pattern of MIL bags can greatly reduce DS noise, it fails to represent many other useful sentence features in the datasets. In many cases, these sentence features can only be acquired by extra sentence-level human annotation with heavy costs. Therefore, the performance of distantly supervised RE models is bounded. In this paper, we go beyond typical MIL framework and propose a novel contrastive instance learning (CIL) framework. Specifically, we regard the initial MIL as the relational triple encoder and constraint positive pairs against negative pairs for each instance. Experiments demonstrate the effectiveness of our proposed framework, with significant improvements over the previous methods on NYT10, GDS and KBP.
Empower Distantly Supervised Relation Extraction with Collaborative Adversarial Training
Jun 21, 2021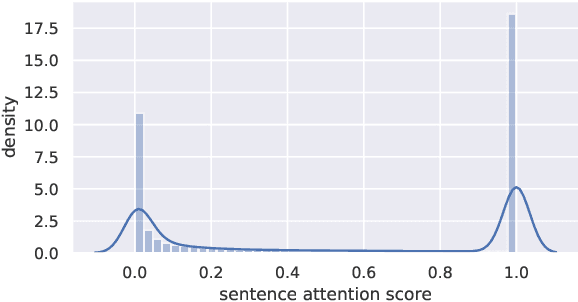
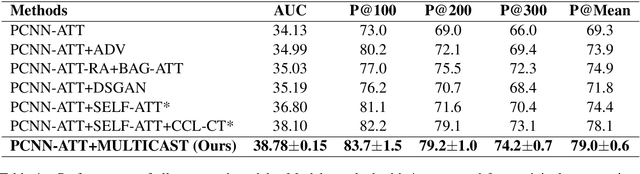
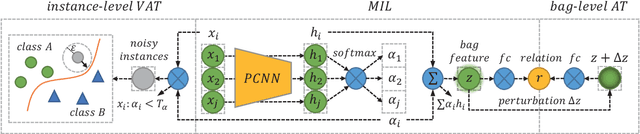
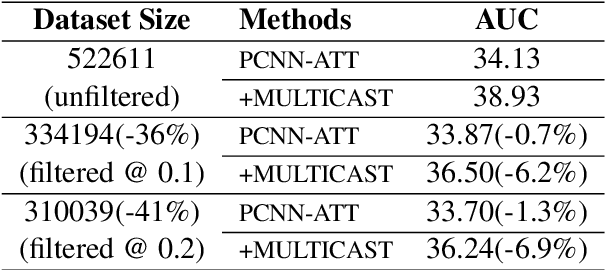
With recent advances in distantly supervised (DS) relation extraction (RE), considerable attention is attracted to leverage multi-instance learning (MIL) to distill high-quality supervision from the noisy DS. Here, we go beyond label noise and identify the key bottleneck of DS-MIL to be its low data utilization: as high-quality supervision being refined by MIL, MIL abandons a large amount of training instances, which leads to a low data utilization and hinders model training from having abundant supervision. In this paper, we propose collaborative adversarial training to improve the data utilization, which coordinates virtual adversarial training (VAT) and adversarial training (AT) at different levels. Specifically, since VAT is label-free, we employ the instance-level VAT to recycle instances abandoned by MIL. Besides, we deploy AT at the bag-level to unleash the full potential of the high-quality supervision got by MIL. Our proposed method brings consistent improvements (~ 5 absolute AUC score) to the previous state of the art, which verifies the importance of the data utilization issue and the effectiveness of our method.
Partner Matters! An Empirical Study on Fusing Personas for Personalized Response Selection in Retrieval-Based Chatbots
May 21, 2021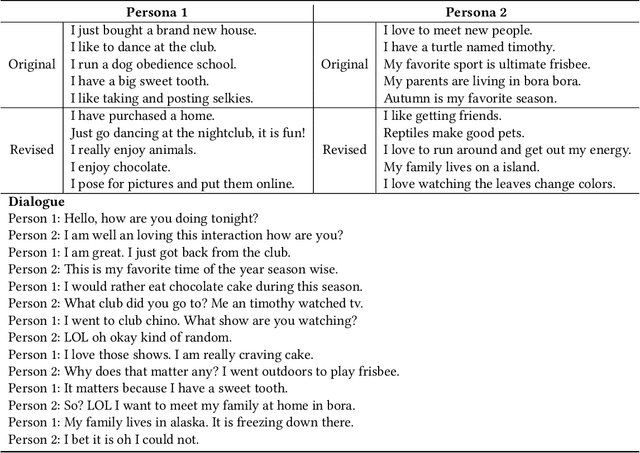
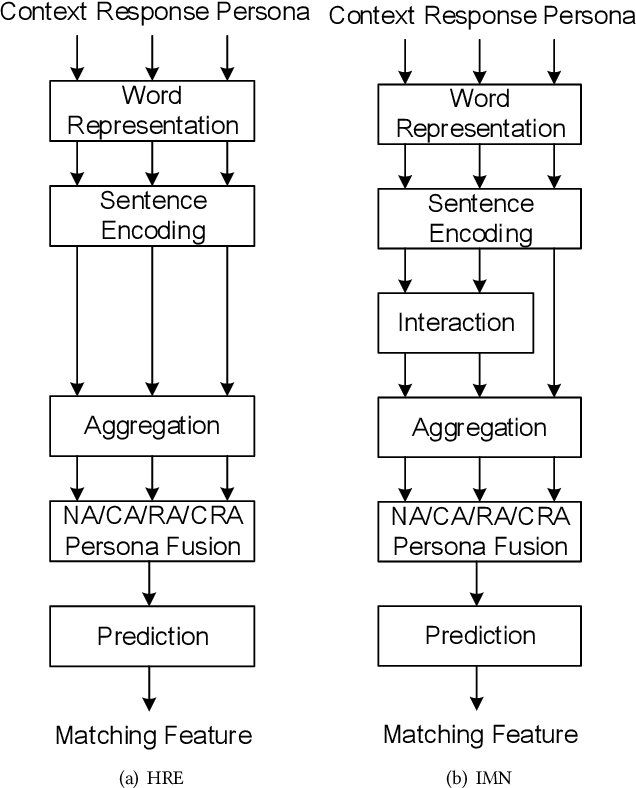
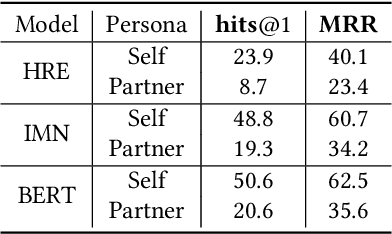
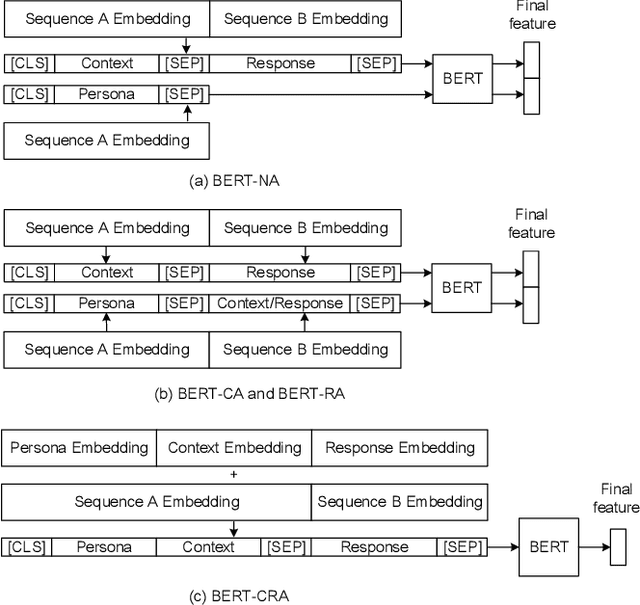
Persona can function as the prior knowledge for maintaining the consistency of dialogue systems. Most of previous studies adopted the self persona in dialogue whose response was about to be selected from a set of candidates or directly generated, but few have noticed the role of partner in dialogue. This paper makes an attempt to thoroughly explore the impact of utilizing personas that describe either self or partner speakers on the task of response selection in retrieval-based chatbots. Four persona fusion strategies are designed, which assume personas interact with contexts or responses in different ways. These strategies are implemented into three representative models for response selection, which are based on the Hierarchical Recurrent Encoder (HRE), Interactive Matching Network (IMN) and Bidirectional Encoder Representations from Transformers (BERT) respectively. Empirical studies on the Persona-Chat dataset show that the partner personas neglected in previous studies can improve the accuracy of response selection in the IMN- and BERT-based models. Besides, our BERT-based model implemented with the context-response-aware persona fusion strategy outperforms previous methods by margins larger than 2.7% on original personas and 4.6% on revised personas in terms of hits@1 (top-1 accuracy), achieving a new state-of-the-art performance on the Persona-Chat dataset.
ExpMRC: Explainability Evaluation for Machine Reading Comprehension
May 10, 2021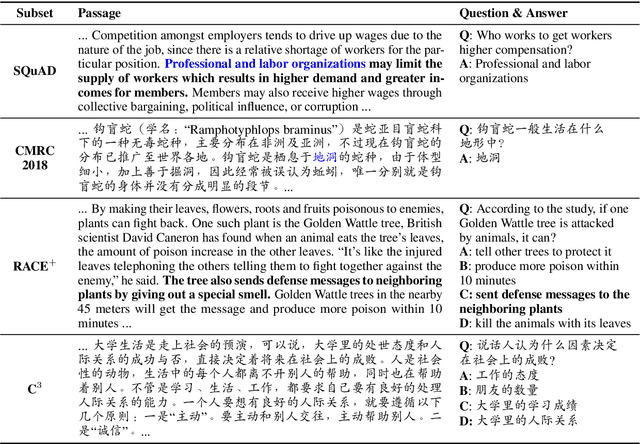
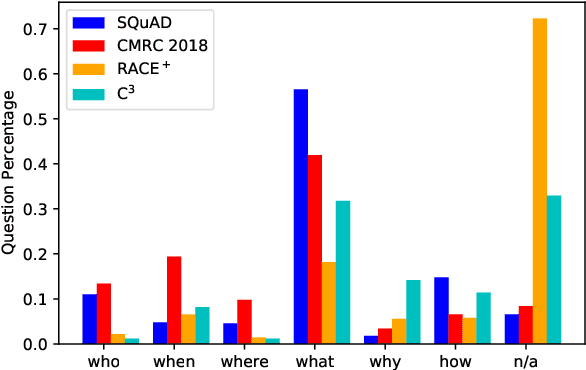
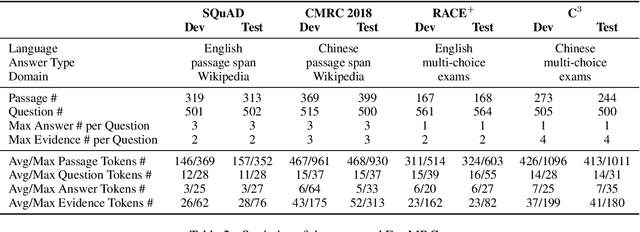
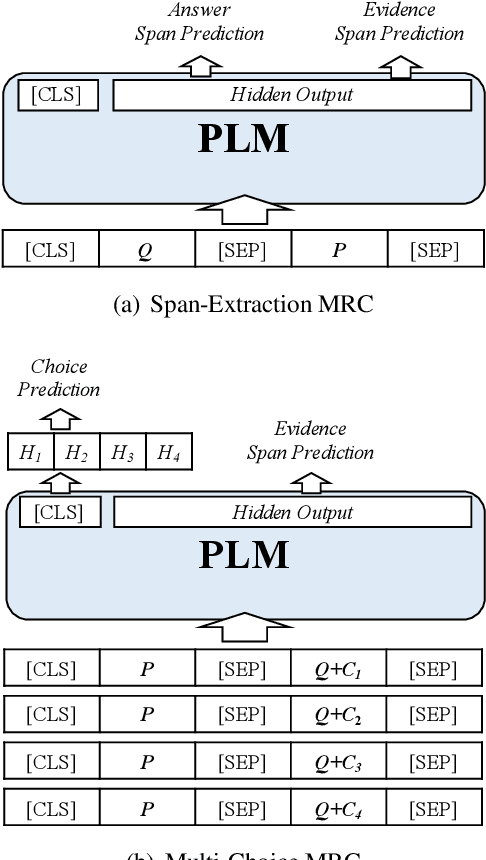
Achieving human-level performance on some of Machine Reading Comprehension (MRC) datasets is no longer challenging with the help of powerful Pre-trained Language Models (PLMs). However, it is necessary to provide both answer prediction and its explanation to further improve the MRC system's reliability, especially for real-life applications. In this paper, we propose a new benchmark called ExpMRC for evaluating the explainability of the MRC systems. ExpMRC contains four subsets, including SQuAD, CMRC 2018, RACE$^+$, and C$^3$ with additional annotations of the answer's evidence. The MRC systems are required to give not only the correct answer but also its explanation. We use state-of-the-art pre-trained language models to build baseline systems and adopt various unsupervised approaches to extract evidence without a human-annotated training set. The experimental results show that these models are still far from human performance, suggesting that the ExpMRC is challenging. Resources will be available through https://github.com/ymcui/expmrc
Program Enhanced Fact Verification with Verbalization and Graph Attention Network
Oct 14, 2020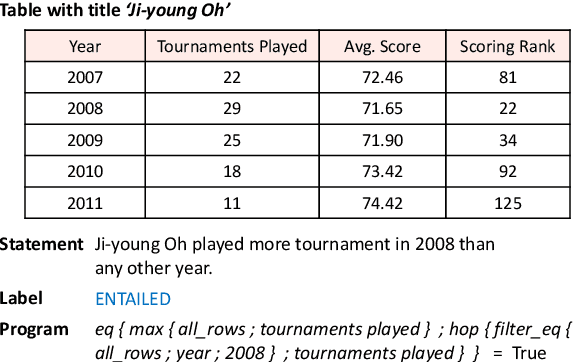

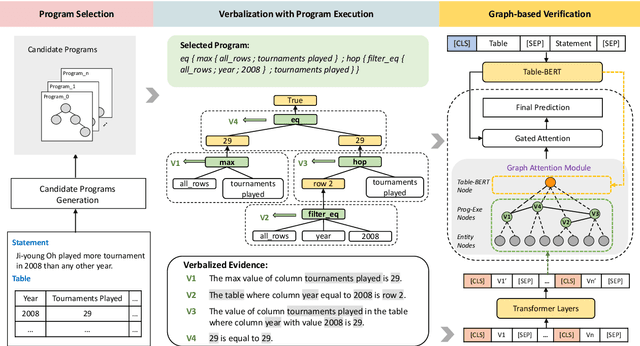
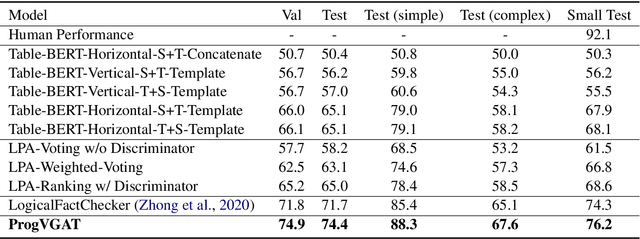
Performing fact verification based on structured data is important for many real-life applications and is a challenging research problem, particularly when it involves both symbolic operations and informal inference based on language understanding. In this paper, we present a Program-enhanced Verbalization and Graph Attention Network (ProgVGAT) to integrate programs and execution into textual inference models. Specifically, a verbalization with program execution model is proposed to accumulate evidences that are embedded in operations over the tables. Built on that, we construct the graph attention verification networks, which are designed to fuse different sources of evidences from verbalized program execution, program structures, and the original statements and tables, to make the final verification decision. To support the above framework, we propose a program selection module optimized with a new training strategy based on margin loss, to produce more accurate programs, which is shown to be effective in enhancing the final verification results. Experimental results show that the proposed framework achieves the new state-of-the-art performance, a 74.4% accuracy, on the benchmark dataset TABFACT.
FewJoint: A Few-shot Learning Benchmark for Joint Language Understanding
Sep 17, 2020



Few-learn learning (FSL) is one of the key future steps in machine learning and has raised a lot of attention. However, in contrast to the rapid development in other domains, such as Computer Vision, the progress of FSL in Nature Language Processing (NLP) is much slower. One of the key reasons for this is the lacking of public benchmarks. NLP FSL researches always report new results on their own constructed few-shot datasets, which is pretty inefficient in results comparison and thus impedes cumulative progress. In this paper, we present FewJoint, a novel Few-Shot Learning benchmark for NLP. Different from most NLP FSL research that only focus on simple N-classification problems, our benchmark introduces few-shot joint dialogue language understanding, which additionally covers the structure prediction and multi-task reliance problems. This allows our benchmark to reflect the real-word NLP complexity beyond simple N-classification. Our benchmark is used in the few-shot learning contest of SMP2020-ECDT task-1. We also provide a compatible FSL platform to ease experiment set-up.
Learning Dynamic Context Augmentation for Global Entity Linking
Sep 04, 2019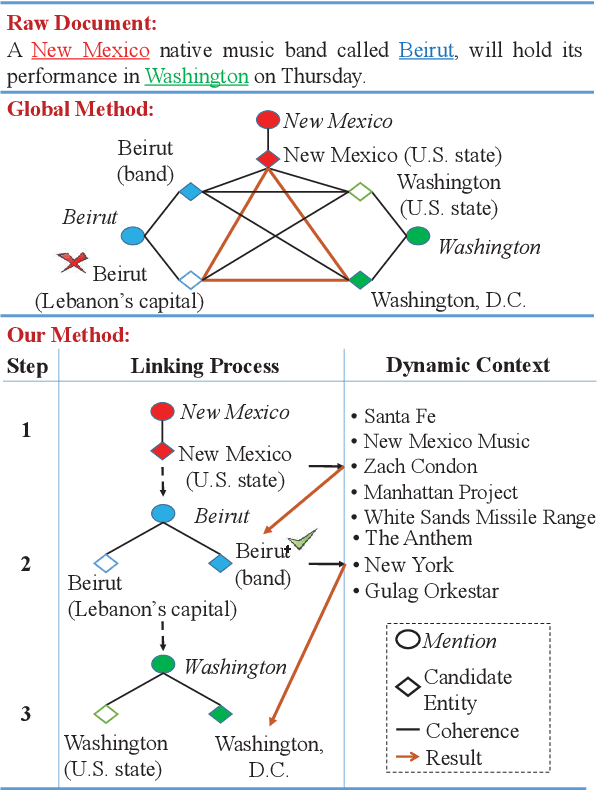
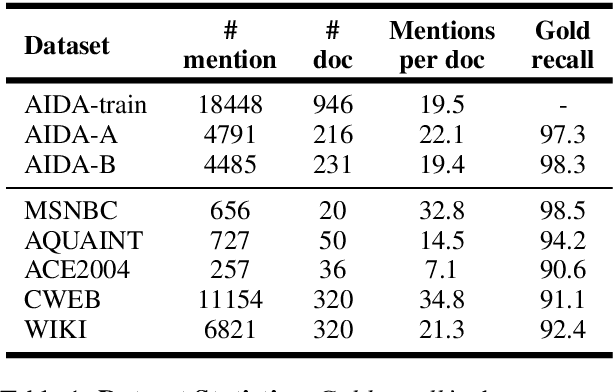
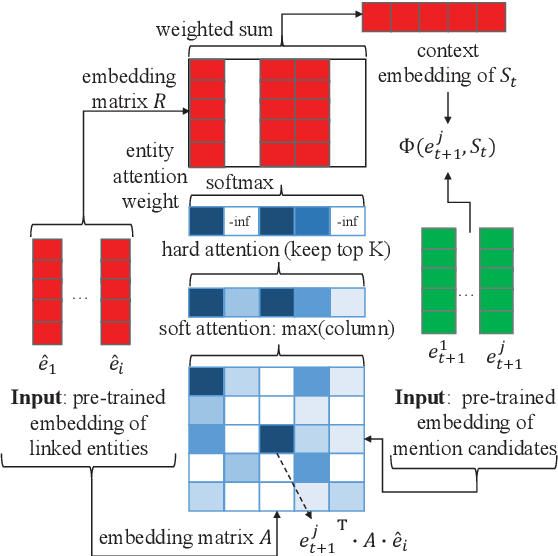
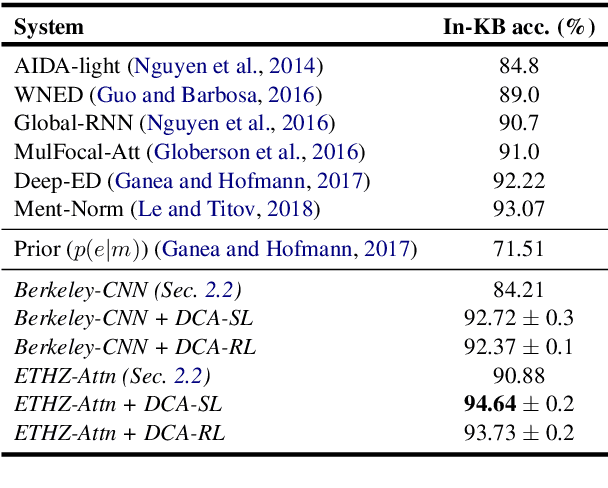
Despite of the recent success of collective entity linking (EL) methods, these "global" inference methods may yield sub-optimal results when the "all-mention coherence" assumption breaks, and often suffer from high computational cost at the inference stage, due to the complex search space. In this paper, we propose a simple yet effective solution, called Dynamic Context Augmentation (DCA), for collective EL, which requires only one pass through the mentions in a document. DCA sequentially accumulates context information to make efficient, collective inference, and can cope with different local EL models as a plug-and-enhance module. We explore both supervised and reinforcement learning strategies for learning the DCA model. Extensive experiments show the effectiveness of our model with different learning settings, base models, decision orders and attention mechanisms.
KCAT: A Knowledge-Constraint Typing Annotation Tool
Jun 13, 2019
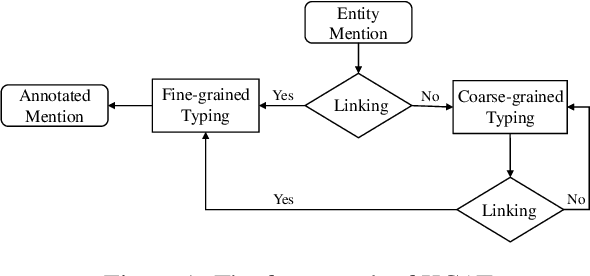
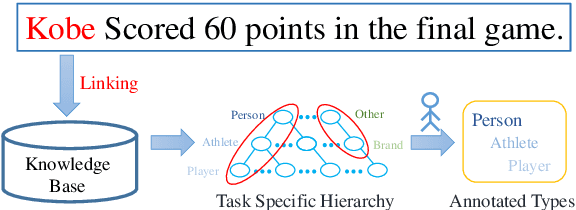
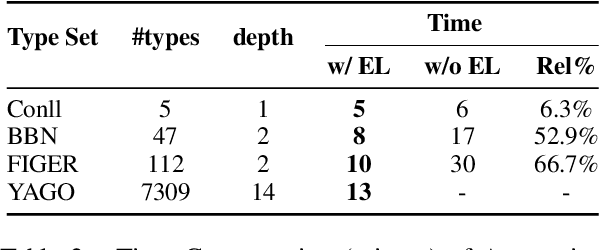
Fine-grained Entity Typing is a tough task which suffers from noise samples extracted from distant supervision. Thousands of manually annotated samples can achieve greater performance than millions of samples generated by the previous distant supervision method. Whereas, it's hard for human beings to differentiate and memorize thousands of types, thus making large-scale human labeling hardly possible. In this paper, we introduce a Knowledge-Constraint Typing Annotation Tool (KCAT), which is efficient for fine-grained entity typing annotation. KCAT reduces the size of candidate types to an acceptable range for human beings through entity linking and provides a Multi-step Typing scheme to revise the entity linking result. Moreover, KCAT provides an efficient Annotator Client to accelerate the annotation process and a comprehensive Manager Module to analyse crowdsourcing annotations. Experiment shows that KCAT can significantly improve annotation efficiency, the time consumption increases slowly as the size of type set expands.