 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantically Structured Image Compression via Irregular Group-Based Decoupling
May 04, 2023



Image compression techniques typically focus on compressing rectangular images for human consumption, however, resulting in transmitting redundant content for downstream applications. To overcome this limitation, some previous works propose to semantically structure the bitstream, which can meet specific application requirements by selective transmission and reconstruction. Nevertheless, they divide the input image into multiple rectangular regions according to semantics and ignore avoiding information interaction among them, causing waste of bitrate and distorted reconstruction of region boundaries. In this paper, we propose to decouple an image into multiple groups with irregular shapes based on a customized group mask and compress them independently. Our group mask describes the image at a finer granularity, enabling significant bitrate saving by reducing the transmission of redundant content. Moreover, to ensure the fidelity of selective reconstruction, this paper proposes the concept of group-independent transform that maintain the independence among distinct groups. And we instantiate it by the proposed Group-Independent Swin-Block (GI Swin-Block). Experimental results demonstrate that our framework structures the bitstream with negligible cost, and exhibits superior performance on both visual quality and intelligent task supporting.
Prompt-ICM: A Unified Framework towards Image Coding for Machines with Task-driven Prompts
May 04, 2023Image coding for machines (ICM) aims to compress images to support downstream AI analysis instead of human perception. For ICM, developing a unified codec to reduce information redundancy while empowering the compressed features to support various vision tasks is very important, which inevitably faces two core challenges: 1) How should the compression strategy be adjusted based on the downstream tasks? 2) How to well adapt the compressed features to different downstream tasks? Inspired by recent advances in transferring large-scale pre-trained models to downstream tasks via prompting, in this work, we explore a new ICM framework, termed Prompt-ICM. To address both challenges by carefully learning task-driven prompts to coordinate well the compression process and downstream analysis. Specifically, our method is composed of two core designs: a) compression prompts, which are implemented as importance maps predicted by an information selector, and used to achieve different content-weighted bit allocations during compression according to different downstream tasks; b) task-adaptive prompts, which are instantiated as a few learnable parameters specifically for tuning compressed features for the specific intelligent task. Extensive experiments demonstrate that with a single feature codec and a few extra parameters, our proposed framework could efficiently support different kinds of intelligent tasks with much higher coding efficiency.
Inpaint Anything: Segment Anything Meets Image Inpainting
Apr 13, 2023


Modern image inpainting systems, despite the significant progress, often struggle with mask selection and holes filling. Based on Segment-Anything Model (SAM), we make the first attempt to the mask-free image inpainting and propose a new paradigm of ``clicking and filling'', which is named as Inpaint Anything (IA). The core idea behind IA is to combine the strengths of different models in order to build a very powerful and user-friendly pipeline for solving inpainting-related problems. IA supports three main features: (i) Remove Anything: users could click on an object and IA will remove it and smooth the ``hole'' with the context; (ii) Fill Anything: after certain objects removal, users could provide text-based prompts to IA, and then it will fill the hole with the corresponding generative content via driving AIGC models like Stable Diffusion; (iii) Replace Anything: with IA, users have another option to retain the click-selected object and replace the remaining background with the newly generated scenes. We are also very willing to help everyone share and promote new projects based on our Inpaint Anything (IA). Our codes are available at https://github.com/geekyutao/Inpaint-Anything.
Learning Distortion Invariant Representation for Image Restoration from A Causality Perspective
Mar 31, 2023In recent years, we have witnessed the great advancement of Deep neural networks (DNNs) in image restoration. However, a critical limitation is that they cannot generalize well to real-world degradations with different degrees or types. In this paper, we are the first to propose a novel training strategy for image restoration from the causality perspective, to improve the generalization ability of DNNs for unknown degradations. Our method, termed Distortion Invariant representation Learning (DIL), treats each distortion type and degree as one specific confounder, and learns the distortion-invariant representation by eliminating the harmful confounding effect of each degradation. We derive our DIL with the back-door criterion in causality by modeling the interventions of different distortions from the optimization perspective. Particularly, we introduce counterfactual distortion augmentation to simulate the virtual distortion types and degrees as the confounders. Then, we instantiate the intervention of each distortion with a virtual model updating based on corresponding distorted images, and eliminate them from the meta-learning perspective. Extensive experiments demonstrate the effectiveness of our DIL on the generalization capability for unseen distortion types and degrees. Our code will be available at https://github.com/lixinustc/Causal-IR-DIL.
Versatile Neural Processes for Learning Implicit Neural Representations
Jan 21, 2023



Representing a signal as a continuous function parameterized by neural network (a.k.a. Implicit Neural Representations, INRs) has attracted increasing attention in recent years. Neural Processes (NPs), which model the distributions over functions conditioned on partial observations (context set), provide a practical solution for fast inference of continuous functions. However, existing NP architectures suffer from inferior modeling capability for complex signals. In this paper, we propose an efficient NP framework dubbed Versatile Neural Processes (VNP), which largely increases the capability of approximating functions. Specifically, we introduce a bottleneck encoder that produces fewer and informative context tokens, relieving the high computational cost while providing high modeling capability. At the decoder side, we hierarchically learn multiple global latent variables that jointly model the global structure and the uncertainty of a function, enabling our model to capture the distribution of complex signals. We demonstrate the effectiveness of the proposed VNP on a variety of tasks involving 1D, 2D and 3D signals. Particularly, our method shows promise in learning accurate INRs w.r.t. a 3D scene without further finetuning.
Semantic-aware Message Broadcasting for Efficient Unsupervised Domain Adaptation
Dec 06, 2022



Vision transformer has demonstrated great potential in abundant vision tasks. However, it also inevitably suffers from poor generalization capability when the distribution shift occurs in testing (i.e., out-of-distribution data). To mitigate this issue, we propose a novel method, Semantic-aware Message Broadcasting (SAMB), which enables more informative and flexible feature alignment for unsupervised domain adaptation (UDA). Particularly, we study the attention module in the vision transformer and notice that the alignment space using one global class token lacks enough flexibility, where it interacts information with all image tokens in the same manner but ignores the rich semantics of different regions. In this paper, we aim to improve the richness of the alignment features by enabling semantic-aware adaptive message broadcasting. Particularly, we introduce a group of learned group tokens as nodes to aggregate the global information from all image tokens, but encourage different group tokens to adaptively focus on the message broadcasting to different semantic regions. In this way, our message broadcasting encourages the group tokens to learn more informative and diverse information for effective domain alignment. Moreover, we systematically study the effects of adversarial-based feature alignment (ADA) and pseudo-label based self-training (PST) on UDA. We find that one simple two-stage training strategy with the cooperation of ADA and PST can further improve the adaptation capability of the vision transformer. Extensive experiments on DomainNet, OfficeHome, and VisDA-2017 demonstrate the effectiveness of our methods for UDA.
Task Residual for Tuning Vision-Language Models
Nov 18, 2022Large-scale vision-language models (VLMs) pre-trained on billion-level data have learned general visual representations and broad visual concepts. In principle, the well-learned knowledge structure of the VLMs should be inherited appropriately when being transferred to downstream tasks with limited data. However, most existing efficient transfer learning (ETL) approaches for VLMs either damage or are excessively biased towards the prior knowledge, e.g., prompt tuning (PT) discards the pre-trained text-based classifier and builds a new one while adapter-style tuning (AT) fully relies on the pre-trained features. To address this, we propose a new efficient tuning approach for VLMs named Task Residual Tuning (TaskRes), which performs directly on the text-based classifier and explicitly decouples the prior knowledge of the pre-trained models and new knowledge regarding a target task. Specifically, TaskRes keeps the original classifier weights from the VLMs frozen and obtains a new classifier for the target task by tuning a set of prior-independent parameters as a residual to the original one, which enables reliable prior knowledge preservation and flexible task-specific knowledge exploration. The proposed TaskRes is simple yet effective, which significantly outperforms previous ETL methods (e.g., PT and AT) on 11 benchmark datasets while requiring minimal effort for the implementation. Our code will be available at https://github.com/geekyutao/TaskRes.
MiNL: Micro-images based Neural Representation for Light Fields
Sep 17, 2022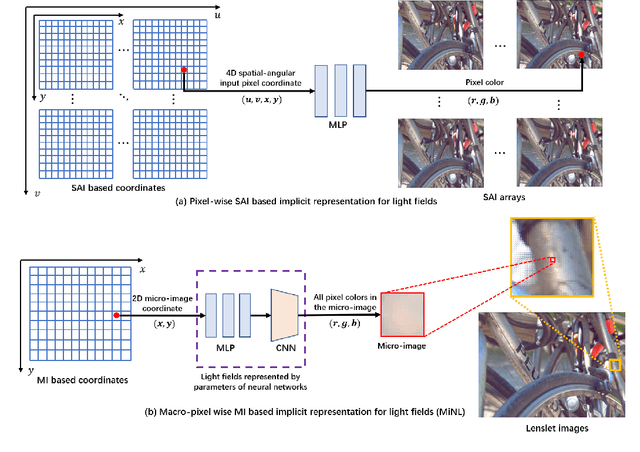
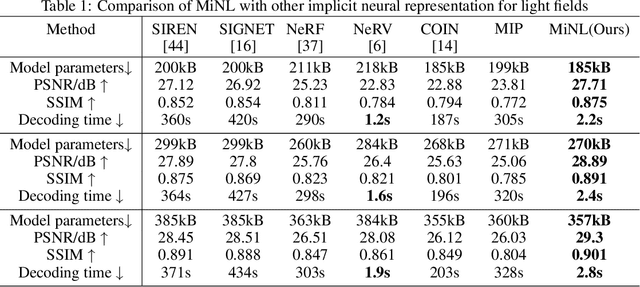
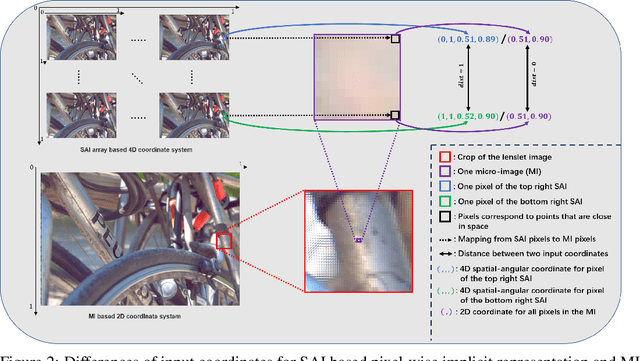
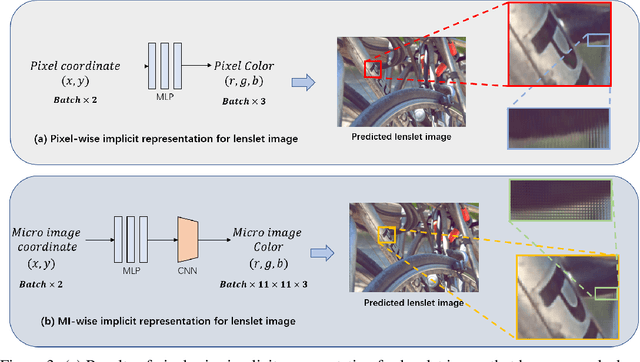
Traditional representations for light fields can be separated into two types: explicit representation and implicit representation. Unlike explicit representation that represents light fields as Sub-Aperture Images (SAIs) based arrays or Micro-Images (MIs) based lenslet images, implicit representation treats light fields as neural networks, which is inherently a continuous representation in contrast to discrete explicit representation. However, at present almost all the implicit representations for light fields utilize SAIs to train an MLP to learn a pixel-wise mapping from 4D spatial-angular coordinate to pixel colors, which is neither compact nor of low complexity. Instead, in this paper we propose MiNL, a novel MI-wise implicit neural representation for light fields that train an MLP + CNN to learn a mapping from 2D MI coordinates to MI colors. Given the micro-image's coordinate, MiNL outputs the corresponding micro-image's RGB values. Light field encoding in MiNL is just training a neural network to regress the micro-images and the decoding process is a simple feedforward operation. Compared with common pixel-wise implicit representation, MiNL is more compact and efficient that has faster decoding speed (\textbf{$\times$80$\sim$180} speed-up) as well as better visual quality (\textbf{1$\sim$4dB} PSNR improvement on average).
Learned Lossless JPEG Transcoding via Joint Lossy and Residual Compression
Aug 24, 2022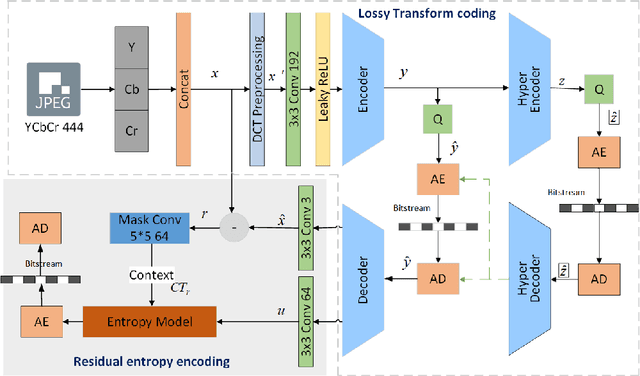
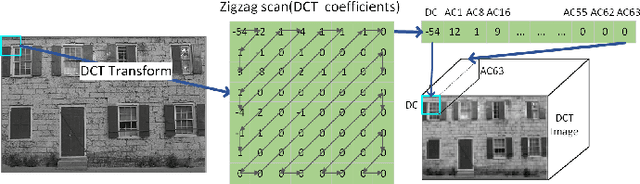
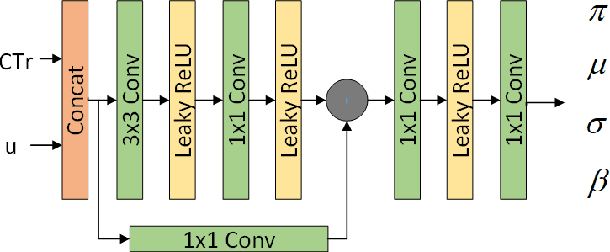
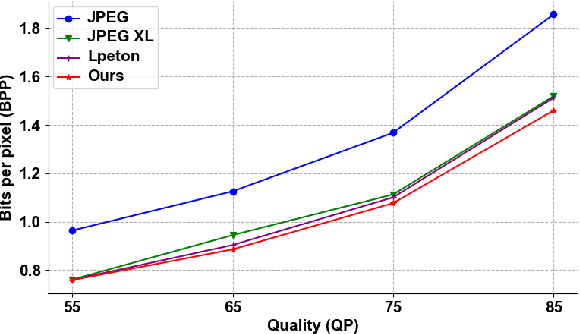
As a commonly-used image compression format, JPEG has been broadly applied in the transmission and storage of images. To further reduce the compression cost while maintaining the quality of JPEG images, lossless transcoding technology has been proposed to recompress the compressed JPEG image in the DCT domain. Previous works, on the other hand, typically reduce the redundancy of DCT coefficients and optimize the probability prediction of entropy coding in a hand-crafted manner that lacks generalization ability and flexibility. To tackle the above challenge, we propose the learned lossless JPEG transcoding framework via Joint Lossy and Residual Compression. Instead of directly optimizing the entropy estimation, we focus on the redundancy that exists in the DCT coefficients. To the best of our knowledge, we are the first to utilize the learned end-to-end lossy transform coding to reduce the redundancy of DCT coefficients in a compact representational domain. We also introduce residual compression for lossless transcoding, which adaptively learns the distribution of residual DCT coefficients before compressing them using context-based entropy coding. Our proposed transcoding architecture shows significant superiority in the compression of JPEG images thanks to the collaboration of learned lossy transform coding and residual entropy coding. Extensive experiments on multiple datasets have demonstrated that our proposed framework can achieve about 21.49% bits saving in average based on JPEG compression, which outperforms the typical lossless transcoding framework JPEG-XL by 3.51%.
Hierarchical Reinforcement Learning Based Video Semantic Coding for Segmentation
Aug 24, 2022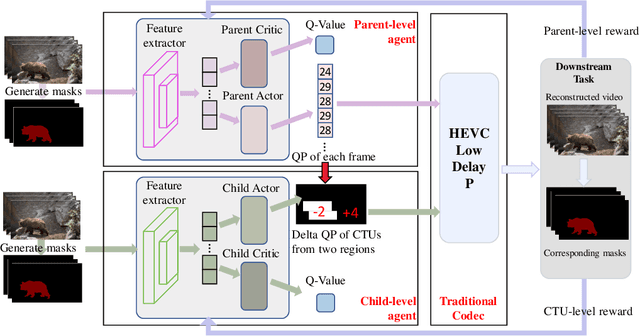
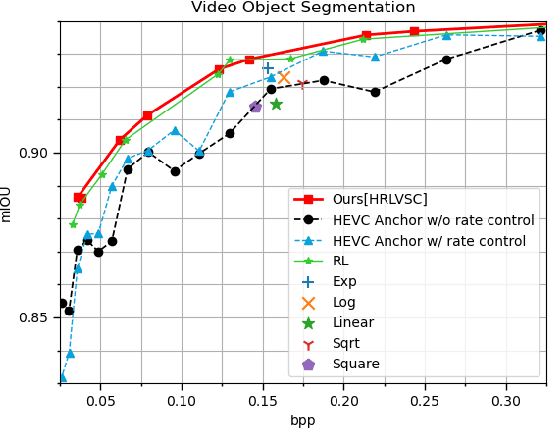
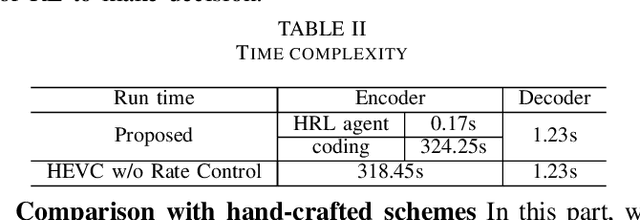
The rapid development of intelligent tasks, e.g., segmentation, detection, classification, etc, has brought an urgent need for semantic compression, which aims to reduce the compression cost while maintaining the original semantic information. However, it is impractical to directly integrate the semantic metric into the traditional codecs since they cannot be optimized in an end-to-end manner. To solve this problem, some pioneering works have applied reinforcement learning to implement image-wise semantic compression. Nevertheless, video semantic compression has not been explored since its complex reference architectures and compression modes. In this paper, we take a step forward to video semantic compression and propose the Hierarchical Reinforcement Learning based task-driven Video Semantic Coding, named as HRLVSC. Specifically, to simplify the complex mode decision of video semantic coding, we divided the action space into frame-level and CTU-level spaces in a hierarchical manner, and then explore the best mode selection for them progressively with the cooperation of frame-level and CTU-level agents. Moreover, since the modes of video semantic coding will exponentially increase with the number of frames in a Group of Pictures (GOP), we carefully investigate the effects of different mode selections for video semantic coding and design a simple but effective mode simplification strategy for it. We have validated our HRLVSC on the video segmentation task with HEVC reference software HM16.19. Extensive experimental results demonstrated that our HRLVSC can achieve over 39% BD-rate saving for video semantic coding under the Low Delay P configuration.