 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThink before Go: Hierarchical Reasoning for Image-goal Navigation
Apr 19, 2026Image-goal navigation steers an agent to a target location specified by an image in unseen environments. Existing methods primarily handle this task by learning an end-to-end navigation policy, which compares the similarities of target and observation images and directly predicts the actions. However, when the target is distant or lies in another room, such methods fail to extract informative visual cues, leading the agent to wander around. Motivated by the human cognitive principle that deliberate, high-level reasoning guides fast, reactive execution in complex tasks, we propose Hierarchical Reasoning Navigation (HRNav), a framework that decomposes image-goal navigation into high-level planning and low-level execution. In high-level planning, a vision-language model is trained on a self-collected dataset to generate a short-horizon plan, such as whether the agent should walk through the door or down the hallway. This downgrades the difficulty of the long-horizon task, making it more amenable to the execution part. In low-level execution, an online reinforcement learning policy is utilized to decide actions conditioned on the short-horizon plan. We also devise a novel Wandering Suppression Penalty (WSP) to further reduce the wandering problem. Together, these components form a hierarchical framework for Image-Goal Navigation. Extensive experiments in both simulation and real-world environments demonstrate the superiority of our method.
DVGT-2: Vision-Geometry-Action Model for Autonomous Driving at Scale
Apr 01, 2026End-to-end autonomous driving has evolved from the conventional paradigm based on sparse perception into vision-language-action (VLA) models, which focus on learning language descriptions as an auxiliary task to facilitate planning. In this paper, we propose an alternative Vision-Geometry-Action (VGA) paradigm that advocates dense 3D geometry as the critical cue for autonomous driving. As vehicles operate in a 3D world, we think dense 3D geometry provides the most comprehensive information for decision-making. However, most existing geometry reconstruction methods (e.g., DVGT) rely on computationally expensive batch processing of multi-frame inputs and cannot be applied to online planning. To address this, we introduce a streaming Driving Visual Geometry Transformer (DVGT-2), which processes inputs in an online manner and jointly outputs dense geometry and trajectory planning for the current frame. We employ temporal causal attention and cache historical features to support on-the-fly inference. To further enhance efficiency, we propose a sliding-window streaming strategy and use historical caches within a certain interval to avoid repetitive computations. Despite the faster speed, DVGT-2 achieves superior geometry reconstruction performance on various datasets. The same trained DVGT-2 can be directly applied to planning across diverse camera configurations without fine-tuning, including closed-loop NAVSIM and open-loop nuScenes benchmarks.
LaST-VLA: Thinking in Latent Spatio-Temporal Space for Vision-Language-Action in Autonomous Driving
Mar 02, 2026While Vision-Language-Action (VLA) models have revolutionized autonomous driving by unifying perception and planning, their reliance on explicit textual Chain-of-Thought (CoT) leads to semantic-perceptual decoupling and perceptual-symbolic conflicts. Recent shifts toward latent reasoning attempt to bypass these bottlenecks by thinking in continuous hidden space. However, without explicit intermediate constraints, standard latent CoT often operates as a physics-agnostic representation. To address this, we propose the Latent Spatio-Temporal VLA (LaST-VLA), a framework shifting the reasoning paradigm from discrete symbolic processing into a physically grounded Latent Spatio-Temporal CoT. By implementing a dual-feature alignment mechanism, we distill geometric constraints from 3D foundation models and dynamic foresight from world models directly into the latent space. Coupled with a progressive SFT training strategy that transitions from feature alignment to trajectory generation, and refined via Reinforcement Learning with Group Relative Policy Optimization (GRPO) to ensure safety and rule compliance. \method~setting a new record on NAVSIM v1 (91.3 PDMS) and NAVSIM v2 (87.1 EPDMS), while excelling in spatial-temporal reasoning on SURDS and NuDynamics benchmarks.
VILTA: A VLM-in-the-Loop Adversary for Enhancing Driving Policy Robustness
Jan 19, 2026The safe deployment of autonomous driving (AD) systems is fundamentally hindered by the long-tail problem, where rare yet critical driving scenarios are severely underrepresented in real-world data. Existing solutions including safety-critical scenario generation and closed-loop learning often rely on rule-based heuristics, resampling methods and generative models learned from offline datasets, limiting their ability to produce diverse and novel challenges. While recent works leverage Vision Language Models (VLMs) to produce scene descriptions that guide a separate, downstream model in generating hazardous trajectories for agents, such two-stage framework constrains the generative potential of VLMs, as the diversity of the final trajectories is ultimately limited by the generalization ceiling of the downstream algorithm. To overcome these limitations, we introduce VILTA (VLM-In-the-Loop Trajectory Adversary), a novel framework that integrates a VLM into the closed-loop training of AD agents. Unlike prior works, VILTA actively participates in the training loop by comprehending the dynamic driving environment and strategically generating challenging scenarios through direct, fine-grained editing of surrounding agents' future trajectories. This direct-editing approach fully leverages the VLM's powerful generalization capabilities to create a diverse curriculum of plausible yet challenging scenarios that extend beyond the scope of traditional methods. We demonstrate that our approach substantially enhances the safety and robustness of the resulting AD policy, particularly in its ability to navigate critical long-tail events.
DVGT: Driving Visual Geometry Transformer
Dec 18, 2025



Perceiving and reconstructing 3D scene geometry from visual inputs is crucial for autonomous driving. However, there still lacks a driving-targeted dense geometry perception model that can adapt to different scenarios and camera configurations. To bridge this gap, we propose a Driving Visual Geometry Transformer (DVGT), which reconstructs a global dense 3D point map from a sequence of unposed multi-view visual inputs. We first extract visual features for each image using a DINO backbone, and employ alternating intra-view local attention, cross-view spatial attention, and cross-frame temporal attention to infer geometric relations across images. We then use multiple heads to decode a global point map in the ego coordinate of the first frame and the ego poses for each frame. Unlike conventional methods that rely on precise camera parameters, DVGT is free of explicit 3D geometric priors, enabling flexible processing of arbitrary camera configurations. DVGT directly predicts metric-scaled geometry from image sequences, eliminating the need for post-alignment with external sensors. Trained on a large mixture of driving datasets including nuScenes, OpenScene, Waymo, KITTI, and DDAD, DVGT significantly outperforms existing models on various scenarios. Code is available at https://github.com/wzzheng/DVGT.
Linearly Solving Robust Rotation Estimation
Jun 13, 2025Rotation estimation plays a fundamental role in computer vision and robot tasks, and extremely robust rotation estimation is significantly useful for safety-critical applications. Typically, estimating a rotation is considered a non-linear and non-convex optimization problem that requires careful design. However, in this paper, we provide some new perspectives that solving a rotation estimation problem can be reformulated as solving a linear model fitting problem without dropping any constraints and without introducing any singularities. In addition, we explore the dual structure of a rotation motion, revealing that it can be represented as a great circle on a quaternion sphere surface. Accordingly, we propose an easily understandable voting-based method to solve rotation estimation. The proposed method exhibits exceptional robustness to noise and outliers and can be computed in parallel with graphics processing units (GPUs) effortlessly. Particularly, leveraging the power of GPUs, the proposed method can obtain a satisfactory rotation solution for large-scale($10^6$) and severely corrupted (99$\%$ outlier ratio) rotation estimation problems under 0.5 seconds. Furthermore, to validate our theoretical framework and demonstrate the superiority of our proposed method, we conduct controlled experiments and real-world dataset experiments. These experiments provide compelling evidence supporting the effectiveness and robustness of our approach in solving rotation estimation problems.
Accelerating Outlier-robust Rotation Estimation by Stereographic Projection
Feb 10, 2025Rotation estimation plays a fundamental role in many computer vision and robot tasks. However, efficiently estimating rotation in large inputs containing numerous outliers (i.e., mismatches) and noise is a recognized challenge. Many robust rotation estimation methods have been designed to address this challenge. Unfortunately, existing methods are often inapplicable due to their long computation time and the risk of local optima. In this paper, we propose an efficient and robust rotation estimation method. Specifically, our method first investigates geometric constraints involving only the rotation axis. Then, it uses stereographic projection and spatial voting techniques to identify the rotation axis and angle. Furthermore, our method efficiently obtains the optimal rotation estimation and can estimate multiple rotations simultaneously. To verify the feasibility of our method, we conduct comparative experiments using both synthetic and real-world data. The results show that, with GPU assistance, our method can solve large-scale ($10^6$ points) and severely corrupted (90\% outlier rate) rotation estimation problems within 0.07 seconds, with an angular error of only 0.01 degrees, which is superior to existing methods in terms of accuracy and efficiency.
TiGDistill-BEV: Multi-view BEV 3D Object Detection via Target Inner-Geometry Learning Distillation
Dec 30, 2024



Accurate multi-view 3D object detection is essential for applications such as autonomous driving. Researchers have consistently aimed to leverage LiDAR's precise spatial information to enhance camera-based detectors through methods like depth supervision and bird-eye-view (BEV) feature distillation. However, existing approaches often face challenges due to the inherent differences between LiDAR and camera data representations. In this paper, we introduce the TiGDistill-BEV, a novel approach that effectively bridges this gap by leveraging the strengths of both sensors. Our method distills knowledge from diverse modalities(e.g., LiDAR) as the teacher model to a camera-based student detector, utilizing the Target Inner-Geometry learning scheme to enhance camera-based BEV detectors through both depth and BEV features by leveraging diverse modalities. Specially, we propose two key modules: an inner-depth supervision module to learn the low-level relative depth relations within objects which equips detectors with a deeper understanding of object-level spatial structures, and an inner-feature BEV distillation module to transfer high-level semantics of different key points within foreground targets. To further alleviate the domain gap, we incorporate both inter-channel and inter-keypoint distillation to model feature similarity. Extensive experiments on the nuScenes benchmark demonstrate that TiGDistill-BEV significantly boosts camera-based only detectors achieving a state-of-the-art with 62.8% NDS and surpassing previous methods by a significant margin. The codes is available at: https://github.com/Public-BOTs/TiGDistill-BEV.git.
Space-time Reinforcement Network for Video Object Segmentation
May 07, 2024Recently, video object segmentation (VOS) networks typically use memory-based methods: for each query frame, the mask is predicted by space-time matching to memory frames. Despite these methods having superior performance, they suffer from two issues: 1) Challenging data can destroy the space-time coherence between adjacent video frames. 2) Pixel-level matching will lead to undesired mismatching caused by the noises or distractors. To address the aforementioned issues, we first propose to generate an auxiliary frame between adjacent frames, serving as an implicit short-temporal reference for the query one. Next, we learn a prototype for each video object and prototype-level matching can be implemented between the query and memory. The experiment demonstrated that our network outperforms the state-of-the-art method on the DAVIS 2017, achieving a J&F score of 86.4%, and attains a competitive result 85.0% on YouTube VOS 2018. In addition, our network exhibits a high inference speed of 32+ FPS.
PU-EVA: An Edge Vector based Approximation Solution for Flexible-scale Point Cloud Upsampling
Apr 22, 2022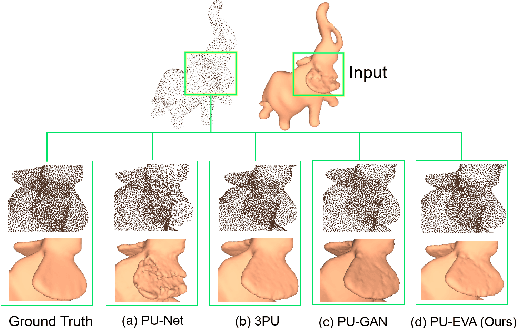
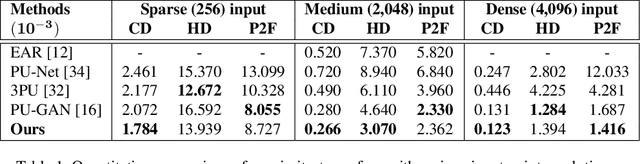
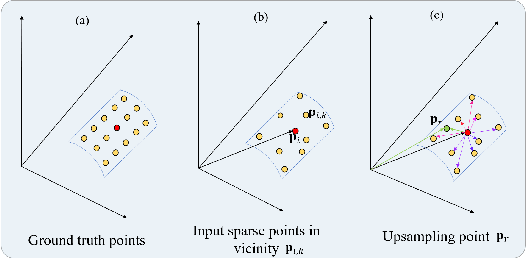
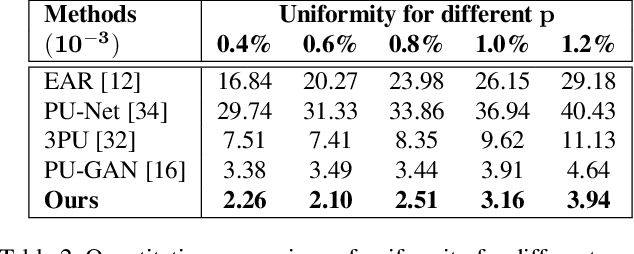
High-quality point clouds have practical significance for point-based rendering, semantic understanding, and surface reconstruction. Upsampling sparse, noisy and nonuniform point clouds for a denser and more regular approximation of target objects is a desirable but challenging task. Most existing methods duplicate point features for upsampling, constraining the upsampling scales at a fixed rate. In this work, the flexible upsampling rates are achieved via edge vector based affine combinations, and a novel design of Edge Vector based Approximation for Flexible-scale Point clouds Upsampling (PU-EVA) is proposed. The edge vector based approximation encodes the neighboring connectivity via affine combinations based on edge vectors, and restricts the approximation error within the second-order term of Taylor's Expansion. The EVA upsampling decouples the upsampling scales with network architecture, achieving the flexible upsampling rates in one-time training. Qualitative and quantitative evaluations demonstrate that the proposed PU-EVA outperforms the state-of-the-art in terms of proximity-to-surface, distribution uniformity, and geometric details preservation.