 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlleviating Representational Shift for Continual Fine-tuning
Apr 22, 2022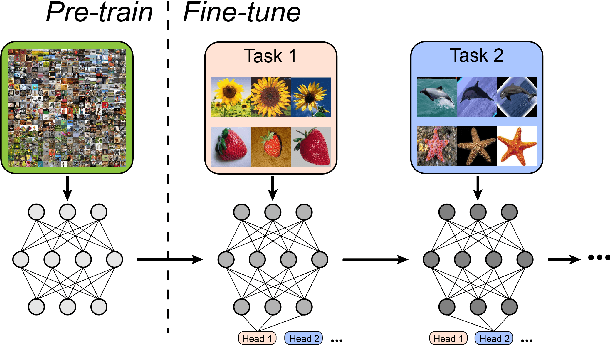
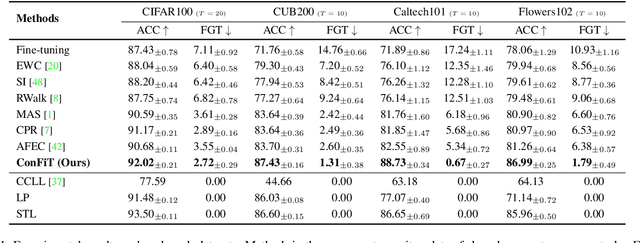
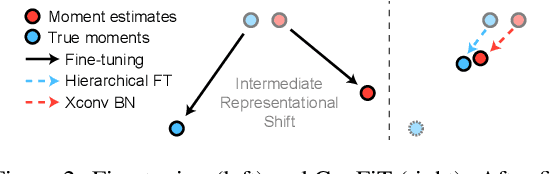
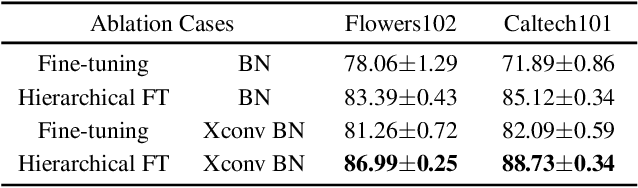
We study a practical setting of continual learning: fine-tuning on a pre-trained model continually. Previous work has found that, when training on new tasks, the features (penultimate layer representations) of previous data will change, called representational shift. Besides the shift of features, we reveal that the intermediate layers' representational shift (IRS) also matters since it disrupts batch normalization, which is another crucial cause of catastrophic forgetting. Motivated by this, we propose ConFiT, a fine-tuning method incorporating two components, cross-convolution batch normalization (Xconv BN) and hierarchical fine-tuning. Xconv BN maintains pre-convolution running means instead of post-convolution, and recovers post-convolution ones before testing, which corrects the inaccurate estimates of means under IRS. Hierarchical fine-tuning leverages a multi-stage strategy to fine-tune the pre-trained network, preventing massive changes in Conv layers and thus alleviating IRS. Experimental results on four datasets show that our method remarkably outperforms several state-of-the-art methods with lower storage overhead.
Rethinking Minimal Sufficient Representation in Contrastive Learning
Apr 02, 2022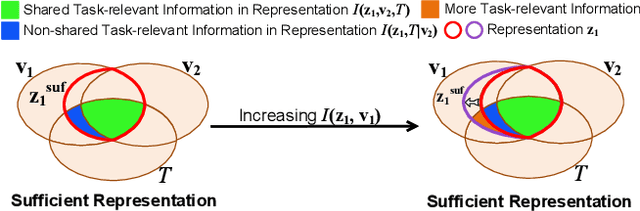

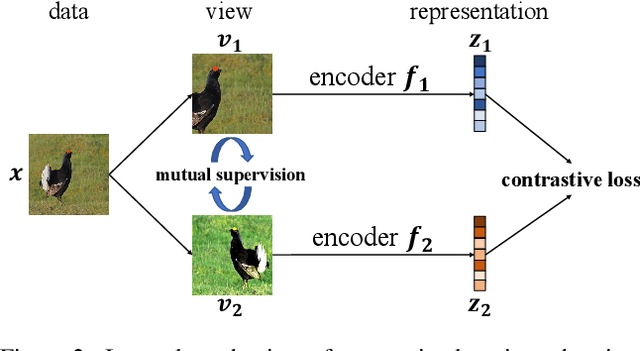
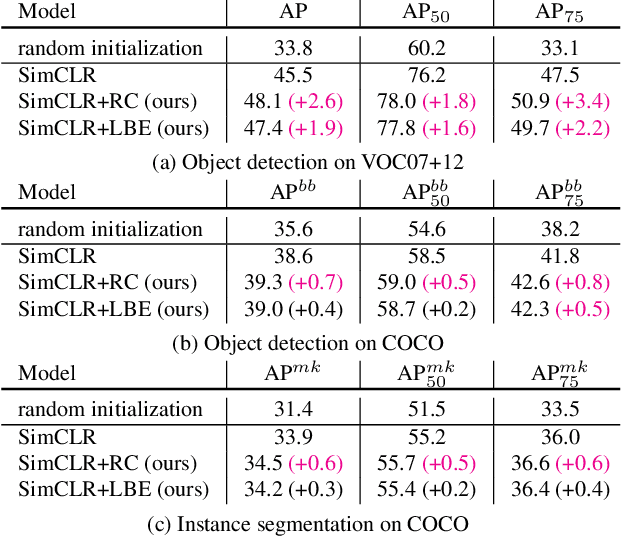
Contrastive learning between different views of the data achieves outstanding success in the field of self-supervised representation learning and the learned representations are useful in broad downstream tasks. Since all supervision information for one view comes from the other view, contrastive learning approximately obtains the minimal sufficient representation which contains the shared information and eliminates the non-shared information between views. Considering the diversity of the downstream tasks, it cannot be guaranteed that all task-relevant information is shared between views. Therefore, we assume the non-shared task-relevant information cannot be ignored and theoretically prove that the minimal sufficient representation in contrastive learning is not sufficient for the downstream tasks, which causes performance degradation. This reveals a new problem that the contrastive learning models have the risk of over-fitting to the shared information between views. To alleviate this problem, we propose to increase the mutual information between the representation and input as regularization to approximately introduce more task-relevant information, since we cannot utilize any downstream task information during training. Extensive experiments verify the rationality of our analysis and the effectiveness of our method. It significantly improves the performance of several classic contrastive learning models in downstream tasks. Our code is available at https://github.com/Haoqing-Wang/InfoCL.
G$^3$SR: Global Graph Guided Session-based Recommendation
Mar 12, 2022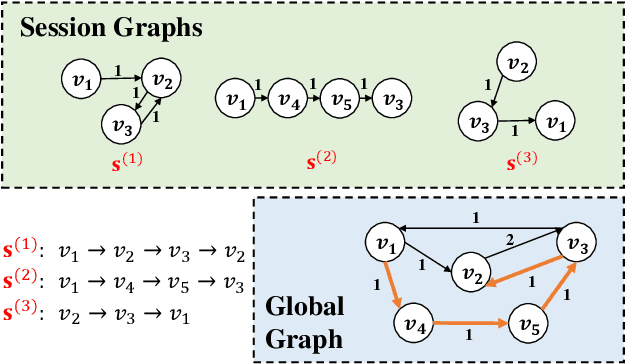
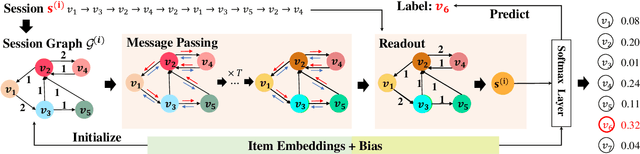
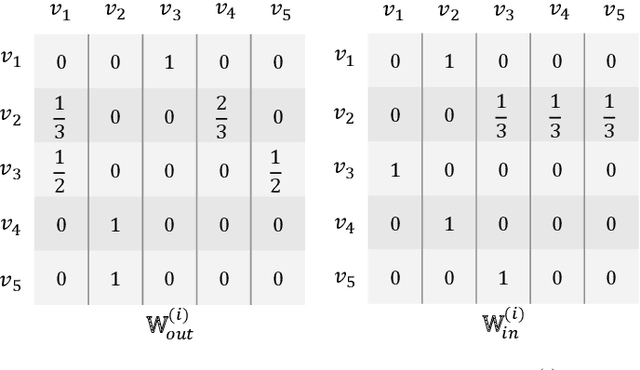
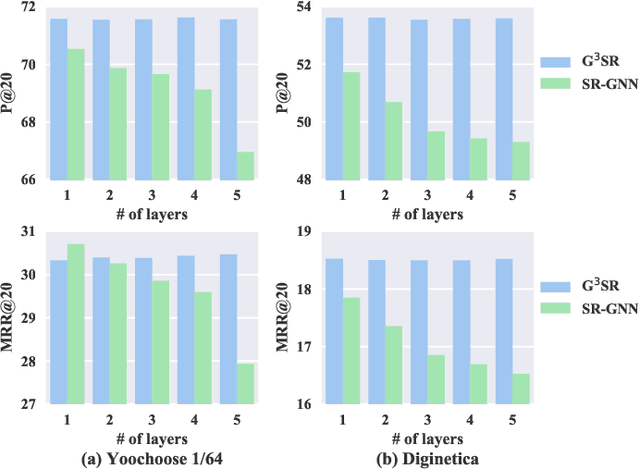
Session-based recommendation tries to make use of anonymous session data to deliver high-quality recommendation under the condition that user-profiles and the complete historical behavioral data of a target user are unavailable. Previous works consider each session individually and try to capture user interests within a session. Despite their encouraging results, these models can only perceive intra-session items and cannot draw upon the massive historical relational information. To solve this problem, we propose a novel method named G$^3$SR (Global Graph Guided Session-based Recommendation). G$^3$SR decomposes the session-based recommendation workflow into two steps. First, a global graph is built upon all session data, from which the global item representations are learned in an unsupervised manner. Then, these representations are refined on session graphs under the graph networks, and a readout function is used to generate session representations for each session. Extensive experiments on two real-world benchmark datasets show remarkable and consistent improvements of the G$^3$SR method over the state-of-the-art methods, especially for cold items.
Cross-Domain Few-Shot Classification via Adversarial Task Augmentation
May 02, 2021
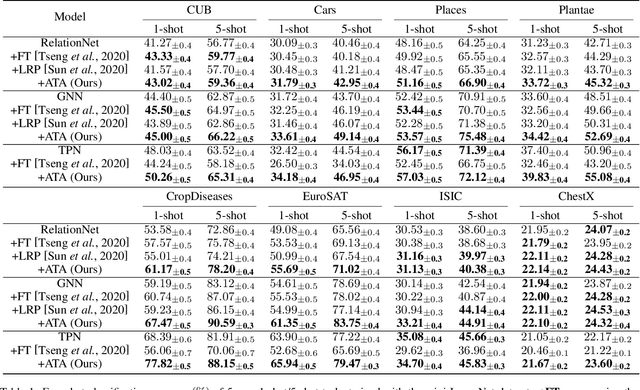
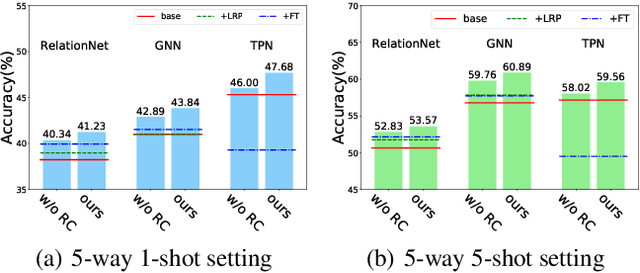
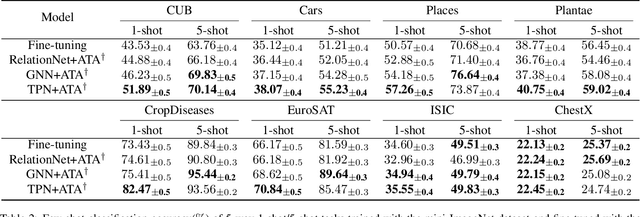
Few-shot classification aims to recognize unseen classes with few labeled samples from each class. Many meta-learning models for few-shot classification elaborately design various task-shared inductive bias (meta-knowledge) to solve such tasks, and achieve impressive performance. However, when there exists the domain shift between the training tasks and the test tasks, the obtained inductive bias fails to generalize across domains, which degrades the performance of the meta-learning models. In this work, we aim to improve the robustness of the inductive bias through task augmentation. Concretely, we consider the worst-case problem around the source task distribution, and propose the adversarial task augmentation method which can generate the inductive bias-adaptive 'challenging' tasks. Our method can be used as a simple plug-and-play module for various meta-learning models, and improve their cross-domain generalization capability. We conduct extensive experiments under the cross-domain setting, using nine few-shot classification datasets: mini-ImageNet, CUB, Cars, Places, Plantae, CropDiseases, EuroSAT, ISIC and ChestX. Experimental results show that our method can effectively improve the few-shot classification performance of the meta-learning models under domain shift, and outperforms the existing works. Our code is available at https://github.com/Haoqing-Wang/CDFSL-ATA.
BCFNet: A Balanced Collaborative Filtering Network with Attention Mechanism
Mar 10, 2021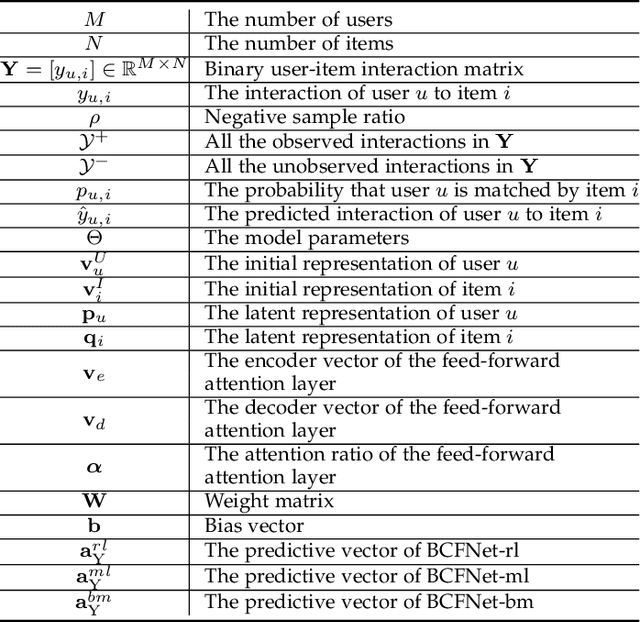
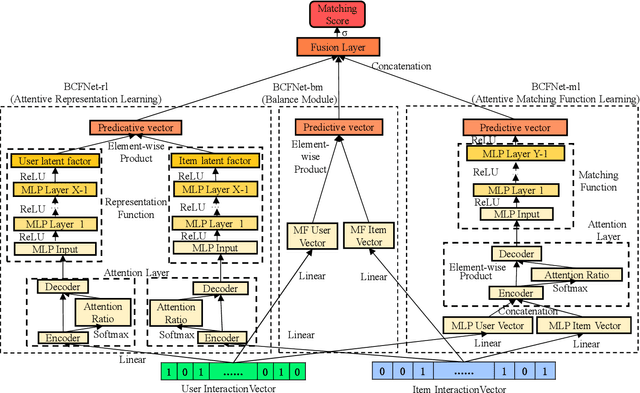
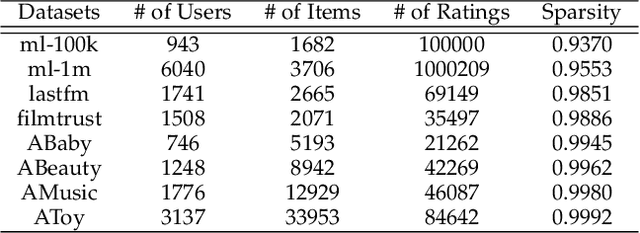
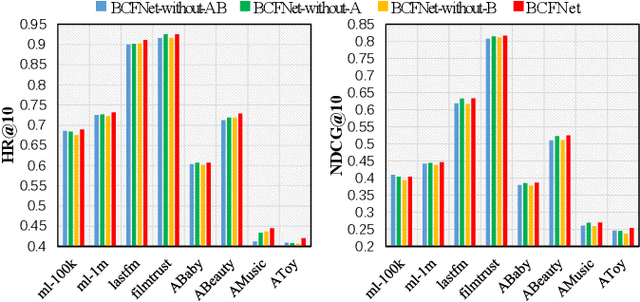
Collaborative Filtering (CF) based recommendation methods have been widely studied, which can be generally categorized into two types, i.e., representation learning-based CF methods and matching function learning-based CF methods. Representation learning tries to learn a common low dimensional space for the representations of users and items. In this case, a user and item match better if they have higher similarity in that common space. Matching function learning tries to directly learn the complex matching function that maps user-item pairs to matching scores. Although both methods are well developed, they suffer from two fundamental flaws, i.e., the representation learning resorts to applying a dot product which has limited expressiveness on the latent features of users and items, while the matching function learning has weakness in capturing low-rank relations. To overcome such flaws, we propose a novel recommendation model named Balanced Collaborative Filtering Network (BCFNet), which has the strengths of the two types of methods. In addition, an attention mechanism is designed to better capture the hidden information within implicit feedback and strengthen the learning ability of the neural network. Furthermore, a balance module is designed to alleviate the over-fitting issue in DNNs. Extensive experiments on eight real-world datasets demonstrate the effectiveness of the proposed model.
Few-shot Learning with LSSVM Base Learner and Transductive Modules
Sep 12, 2020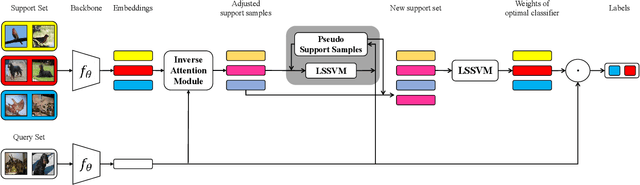
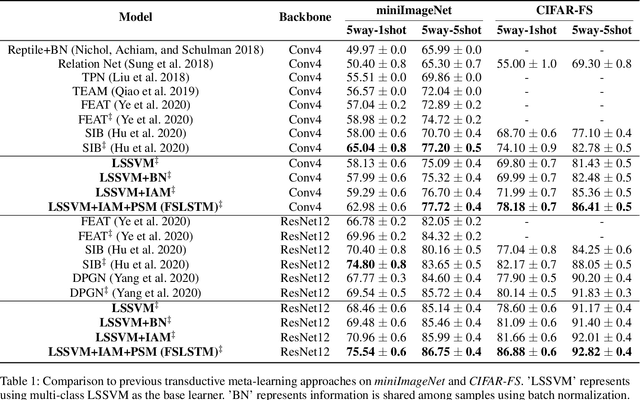
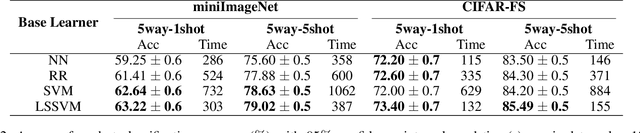
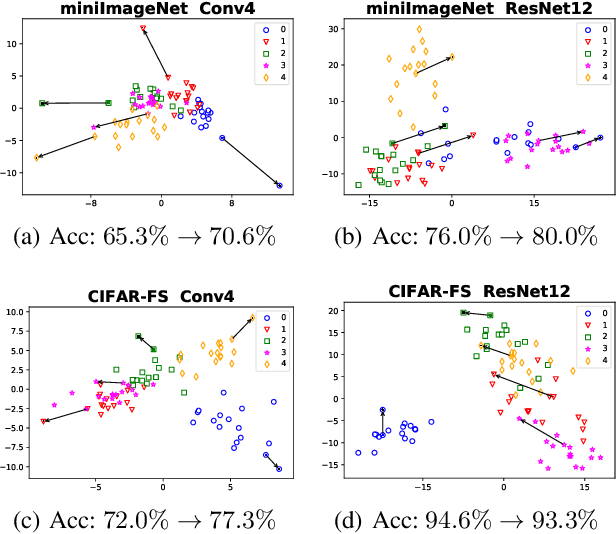
The performance of meta-learning approaches for few-shot learning generally depends on three aspects: features suitable for comparison, the classifier ( base learner ) suitable for low-data scenarios, and valuable information from the samples to classify. In this work, we make improvements for the last two aspects: 1) although there are many effective base learners, there is a trade-off between generalization performance and computational overhead, so we introduce multi-class least squares support vector machine as our base learner which obtains better generation than existing ones with less computational overhead; 2) further, in order to utilize the information from the query samples, we propose two simple and effective transductive modules which modify the support set using the query samples, i.e., adjusting the support samples basing on the attention mechanism and adding the prototypes of the query set with pseudo labels to the support set as the pseudo support samples. These two modules significantly improve the few-shot classification accuracy, especially for the difficult 1-shot setting. Our model, denoted as FSLSTM (Few-Shot learning with LSsvm base learner and Transductive Modules), achieves state-of-the-art performance on miniImageNet and CIFAR-FS few-shot learning benchmarks.
Self-Supervised Learning Aided Class-Incremental Lifelong Learning
Jun 19, 2020
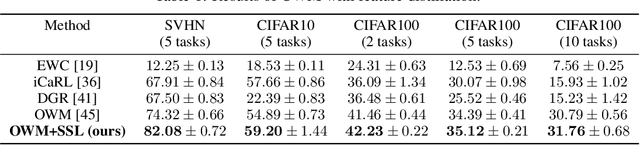
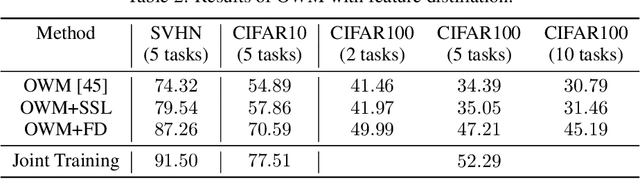
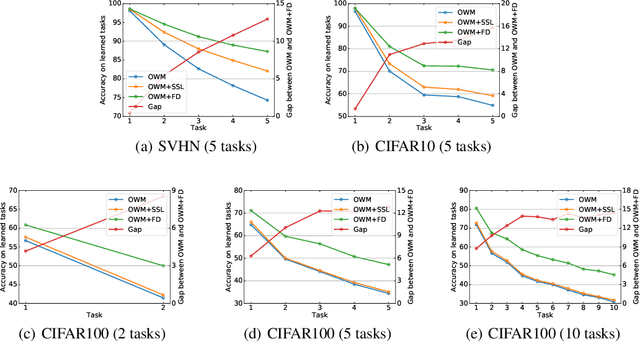
Lifelong or continual learning remains to be a challenge for artificial neural network, as it is required to be both stable for preservation of old knowledge and plastic for acquisition of new knowledge. It is common to see previous experience get overwritten, which leads to the well-known issue of catastrophic forgetting, especially in the scenario of class-incremental learning (Class-IL). Recently, many lifelong learning methods have been proposed to avoid catastrophic forgetting. However, models which learn without replay of the input data, would encounter another problem which has been ignored, and we refer to it as prior information loss (PIL). In training procedure of Class-IL, as the model has no knowledge about following tasks, it would only extract features necessary for tasks learned so far, whose information is insufficient for joint classification. In this paper, our empirical results on several image datasets show that PIL limits the performance of current state-of-the-art method for Class-IL, the orthogonal weights modification (OWM) algorithm. Furthermore, we propose to combine self-supervised learning, which can provide effective representations without requiring labels, with Class-IL to partly get around this problem. Experiments show superiority of proposed method to OWM, as well as other strong baselines.
Generative Feature Replay with Orthogonal Weight Modification for Continual Learning
May 07, 2020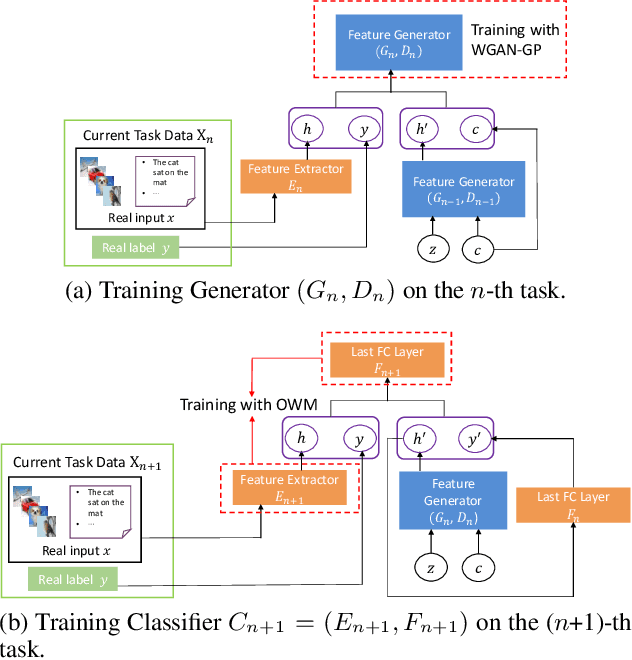


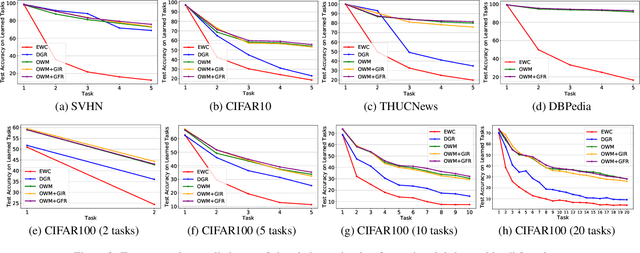
The ability of intelligent agents to learn and remember multiple tasks sequentially is crucial to achieving artificial general intelligence. Many continual learning (CL) methods have been proposed to overcome catastrophic forgetting. Catastrophic forgetting notoriously impedes the sequential learning of neural networks as the data of previous tasks are unavailable. In this paper we focus on class incremental learning, a challenging CL scenario, in which classes of each task are disjoint and task identity is unknown during test. For this scenario, generative replay is an effective strategy which generates and replays pseudo data for previous tasks to alleviate catastrophic forgetting. However, it is not trivial to learn a generative model continually for relatively complex data. Based on recently proposed orthogonal weight modification (OWM) algorithm which can keep previously learned input-output mappings invariant approximately when learning new tasks, we propose to directly generate and replay feature. Empirical results on image and text datasets show our method can improve OWM consistently by a significant margin while conventional generative replay always results in a negative effect. Our method also beats a state-of-the-art generative replay method and is competitive with a strong baseline based on real data storage.
Fast Structured Decoding for Sequence Models
Oct 25, 2019
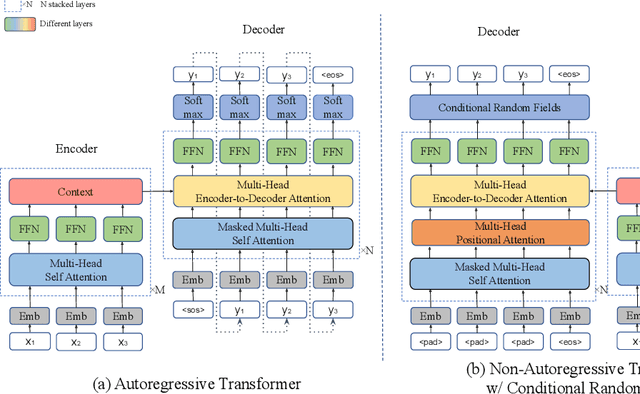
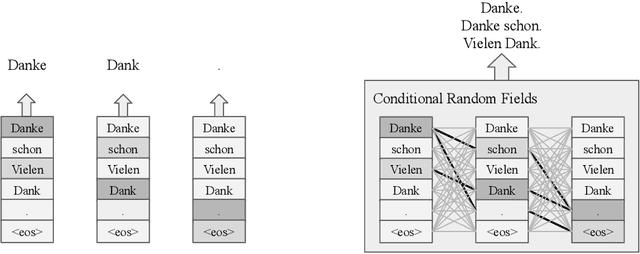
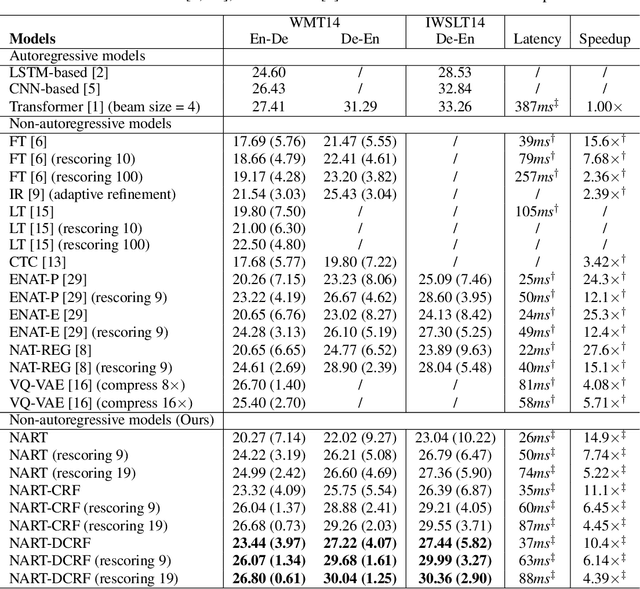
Autoregressive sequence models achieve state-of-the-art performance in domains like machine translation. However, due to the autoregressive factorization nature, these models suffer from heavy latency during inference. Recently, non-autoregressive sequence models were proposed to speed up the inference time. However, these models assume that the decoding process of each token is conditionally independent of others. Such a generation process sometimes makes the output sentence inconsistent, and thus the learned non-autoregressive models could only achieve inferior accuracy compared to their autoregressive counterparts. To improve then decoding consistency and reduce the inference cost at the same time, we propose to incorporate a structured inference module into the non-autoregressive models. Specifically, we design an efficient approximation for Conditional Random Fields (CRF) for non-autoregressive sequence models, and further propose a dynamic transition technique to model positional contexts in the CRF. Experiments in machine translation show that while increasing little latency (8~14ms), our model could achieve significantly better translation performance than previous non-autoregressive models on different translation datasets. In particular, for the WMT14 En-De dataset, our model obtains a BLEU score of 26.80, which largely outperforms the previous non-autoregressive baselines and is only 0.61 lower in BLEU than purely autoregressive models.
Dynamically Pruned Message Passing Networks for Large-Scale Knowledge Graph Reasoning
Sep 27, 2019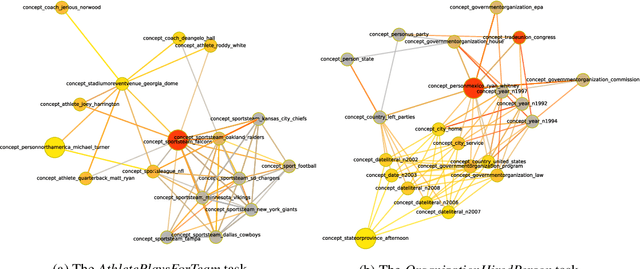
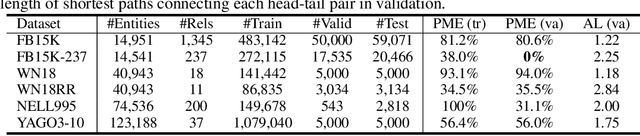
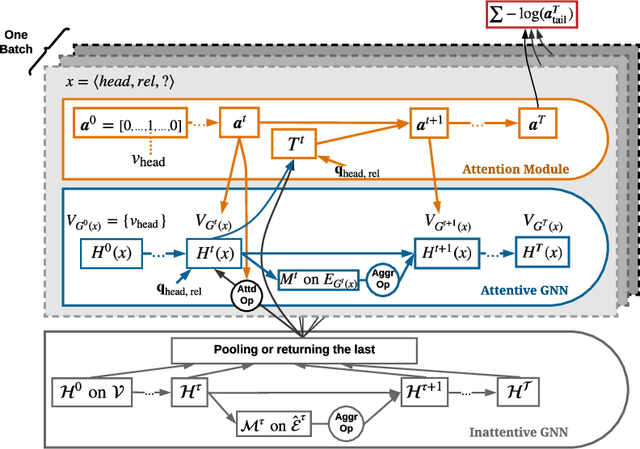
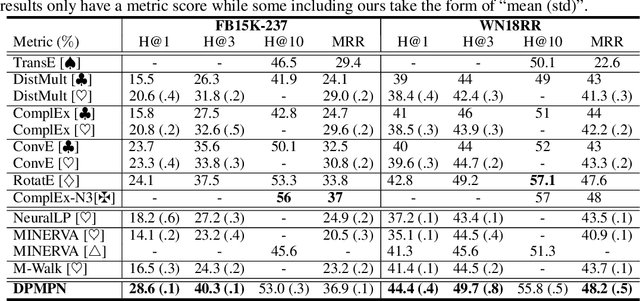
We propose Dynamically Pruned Message Passing Networks (DPMPN) for large-scale knowledge graph reasoning. In contrast to existing models, embedding-based or path-based, we learn an input-dependent subgraph to explicitly model a sequential reasoning process. Each subgraph is dynamically constructed, expanding itself selectively under a flow-style attention mechanism. In this way, we can not only construct graphical explanations to interpret prediction, but also prune message passing in Graph Neural Networks (GNNs) to scale with the size of graphs. We take the inspiration from the consciousness prior proposed by Bengio to design a two-GNN framework to encode global input-invariant graph-structured representation and learn local input-dependent one coordinated by an attention module. Experiments show the reasoning capability in our model that is providing a clear graphical explanation as well as predicting results accurately, outperforming most state-of-the-art methods in knowledge base completion tasks.