 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVision-based Uneven BEV Representation Learning with Polar Rasterization and Surface Estimation
Jul 05, 2022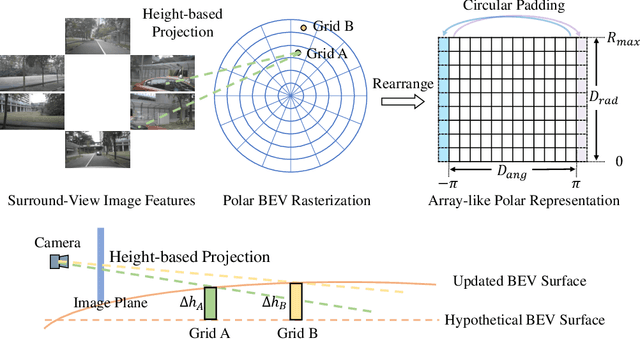
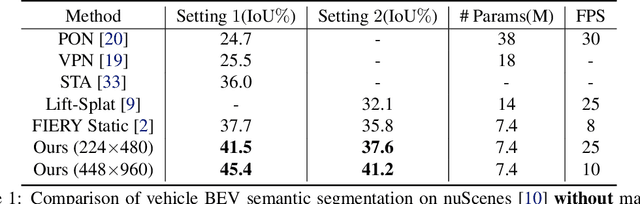
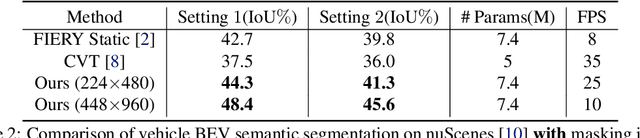

In this work, we propose PolarBEV for vision-based uneven BEV representation learning. To adapt to the foreshortening effect of camera imaging, we rasterize the BEV space both angularly and radially, and introduce polar embedding decomposition to model the associations among polar grids. Polar grids are rearranged to an array-like regular representation for efficient processing. Besides, to determine the 2D-to-3D correspondence, we iteratively update the BEV surface based on a hypothetical plane, and adopt height-based feature transformation. PolarBEV keeps real-time inference speed on a single 2080Ti GPU, and outperforms other methods for both BEV semantic segmentation and BEV instance segmentation. Thorough ablations are presented to validate the design. The code will be released at \url{https://github.com/SuperZ-Liu/PolarBEV}.
Equity in Resident Crowdsourcing: Measuring Under-reporting without Ground Truth Data
Apr 19, 2022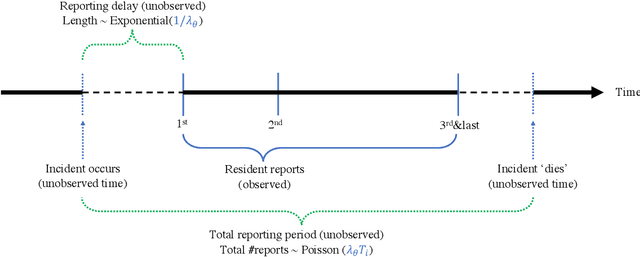

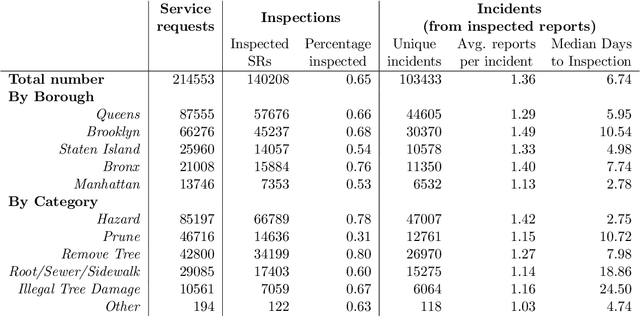
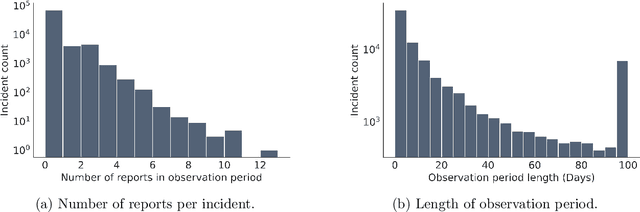
Modern city governance relies heavily on crowdsourcing (or "co-production") to identify problems such as downed trees and power-lines. A major concern in these systems is that residents do not report problems at the same rates, leading to an inequitable allocation of government resources. However, measuring such under-reporting is a difficult statistical task, as, almost by definition, we do not observe incidents that are not reported. Thus, distinguishing between low reporting rates and low ground-truth incident rates is challenging. We develop a method to identify (heterogeneous) reporting rates, without using external (proxy) ground truth data. Our insight is that rates on $\textit{duplicate}$ reports about the same incident can be leveraged, to turn the question into a standard Poisson rate estimation task -- even though the full incident reporting interval is also unobserved. We apply our method to over 100,000 resident reports made to the New York City Department of Parks and Recreation, finding that there are substantial spatial and socio-economic disparities in reporting rates, even after controlling for incident characteristics.
Adjacent Context Coordination Network for Salient Object Detection in Optical Remote Sensing Images
Mar 25, 2022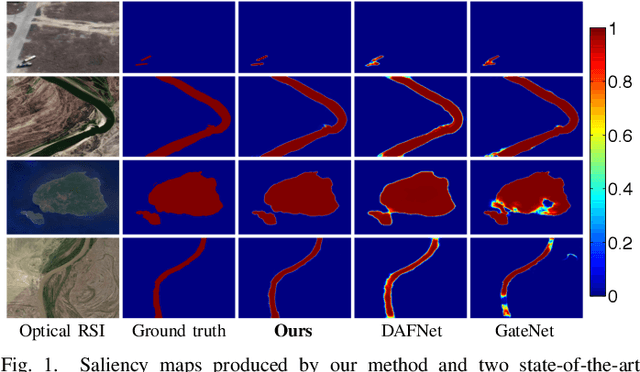
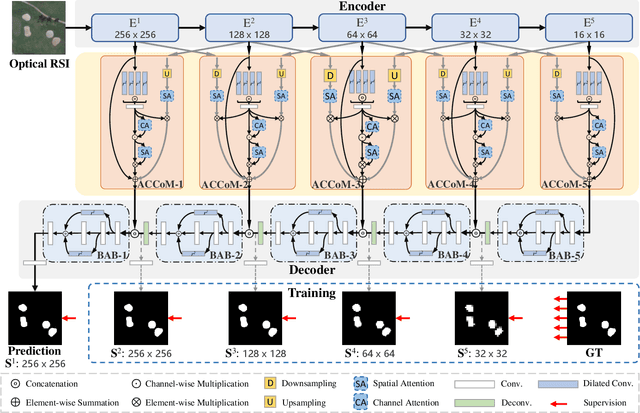

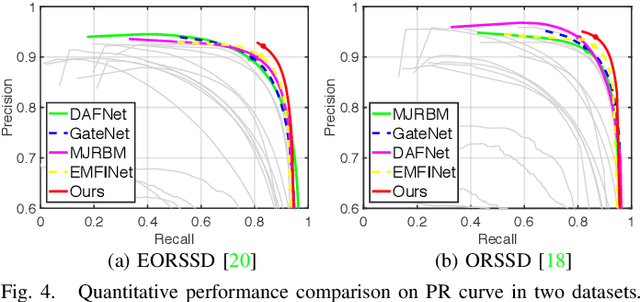
Salient object detection (SOD) in optical remote sensing images (RSIs), or RSI-SOD, is an emerging topic in understanding optical RSIs. However, due to the difference between optical RSIs and natural scene images (NSIs), directly applying NSI-SOD methods to optical RSIs fails to achieve satisfactory results. In this paper, we propose a novel Adjacent Context Coordination Network (ACCoNet) to explore the coordination of adjacent features in an encoder-decoder architecture for RSI-SOD. Specifically, ACCoNet consists of three parts: an encoder, Adjacent Context Coordination Modules (ACCoMs), and a decoder. As the key component of ACCoNet, ACCoM activates the salient regions of output features of the encoder and transmits them to the decoder. ACCoM contains a local branch and two adjacent branches to coordinate the multi-level features simultaneously. The local branch highlights the salient regions in an adaptive way, while the adjacent branches introduce global information of adjacent levels to enhance salient regions. Additionally, to extend the capabilities of the classic decoder block (i.e., several cascaded convolutional layers), we extend it with two bifurcations and propose a Bifurcation-Aggregation Block to capture the contextual information in the decoder. Extensive experiments on two benchmark datasets demonstrate that the proposed ACCoNet outperforms 22 state-of-the-art methods under nine evaluation metrics, and runs up to 81 fps on a single NVIDIA Titan X GPU. The code and results of our method are available at https://github.com/MathLee/ACCoNet.
Spherical Convolution empowered FoV Prediction in 360-degree Video Multicast with Limited FoV Feedback
Jan 29, 2022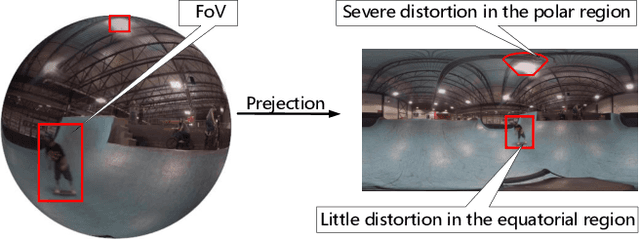

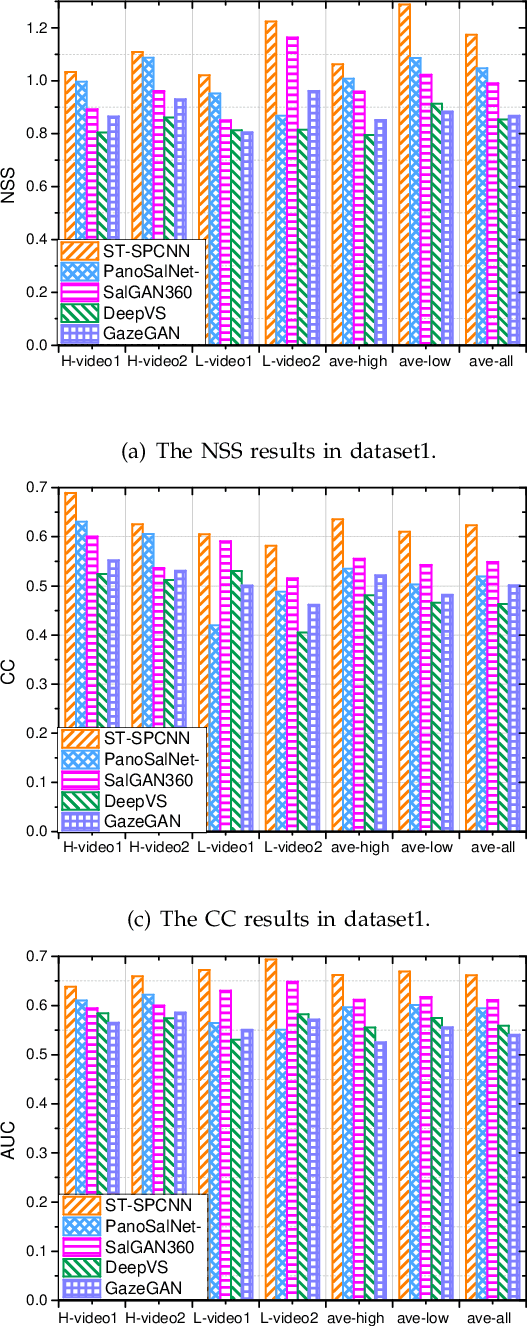
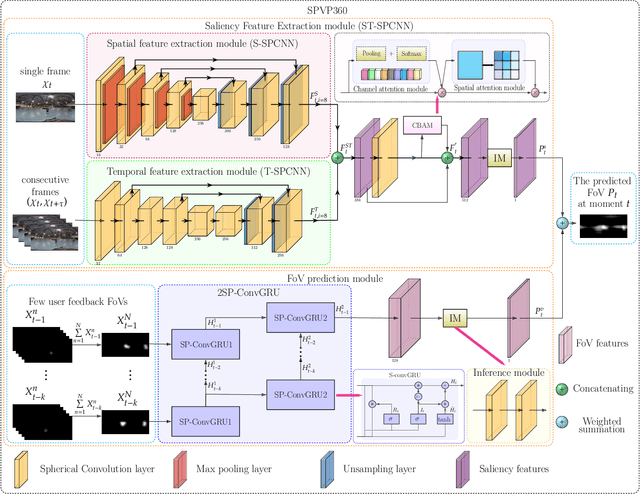
Field of view (FoV) prediction is critical in 360-degree video multicast, which is a key component of the emerging Virtual Reality (VR) and Augmented Reality (AR) applications. Most of the current prediction methods combining saliency detection and FoV information neither take into account that the distortion of projected 360-degree videos can invalidate the weight sharing of traditional convolutional networks, nor do they adequately consider the difficulty of obtaining complete multi-user FoV information, which degrades the prediction performance. This paper proposes a spherical convolution-empowered FoV prediction method, which is a multi-source prediction framework combining salient features extracted from 360-degree video with limited FoV feedback information. A spherical convolution neural network (CNN) is used instead of a traditional two-dimensional CNN to eliminate the problem of weight sharing failure caused by video projection distortion. Specifically, salient spatial-temporal features are extracted through a spherical convolution-based saliency detection model, after which the limited feedback FoV information is represented as a time-series model based on a spherical convolution-empowered gated recurrent unit network. Finally, the extracted salient video features are combined to predict future user FoVs. The experimental results show that the performance of the proposed method is better than other prediction methods.
Lightweight Salient Object Detection in Optical Remote Sensing Images via Feature Correlation
Jan 20, 2022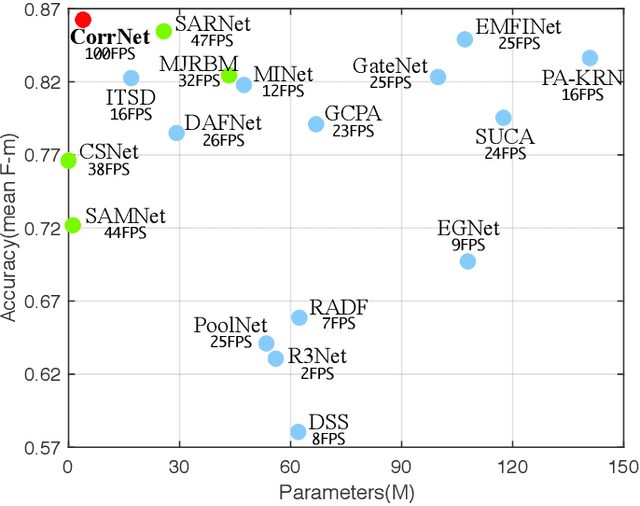
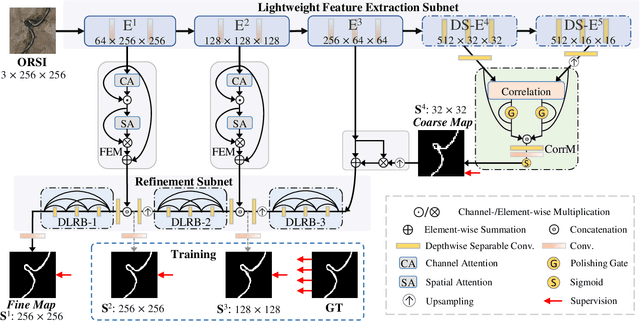
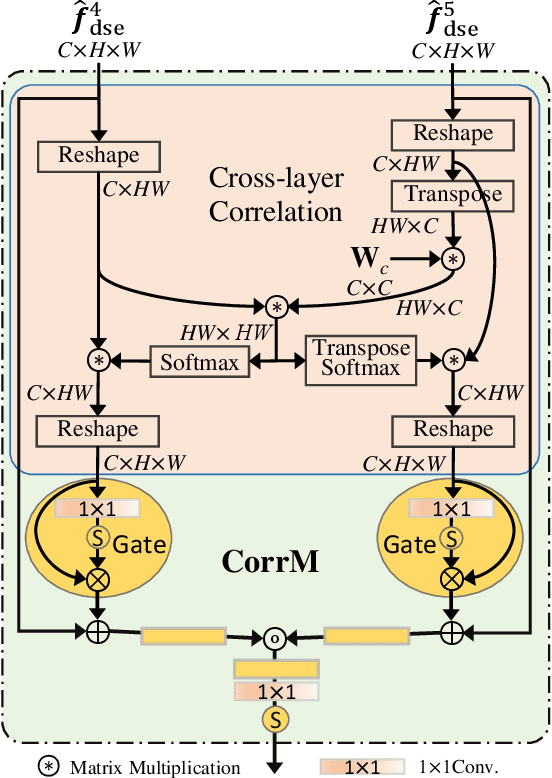
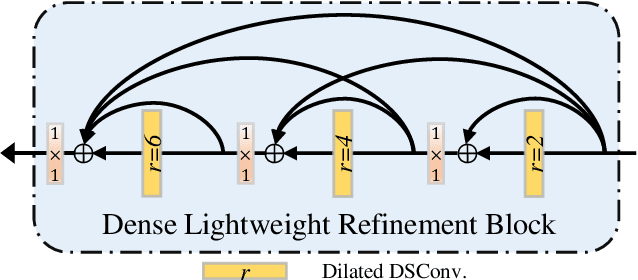
Salient object detection in optical remote sensing images (ORSI-SOD) has been widely explored for understanding ORSIs. However, previous methods focus mainly on improving the detection accuracy while neglecting the cost in memory and computation, which may hinder their real-world applications. In this paper, we propose a novel lightweight ORSI-SOD solution, named CorrNet, to address these issues. In CorrNet, we first lighten the backbone (VGG-16) and build a lightweight subnet for feature extraction. Then, following the coarse-to-fine strategy, we generate an initial coarse saliency map from high-level semantic features in a Correlation Module (CorrM). The coarse saliency map serves as the location guidance for low-level features. In CorrM, we mine the object location information between high-level semantic features through the cross-layer correlation operation. Finally, based on low-level detailed features, we refine the coarse saliency map in the refinement subnet equipped with Dense Lightweight Refinement Blocks, and produce the final fine saliency map. By reducing the parameters and computations of each component, CorrNet ends up having only 4.09M parameters and running with 21.09G FLOPs. Experimental results on two public datasets demonstrate that our lightweight CorrNet achieves competitive or even better performance compared with 26 state-of-the-art methods (including 16 large CNN-based methods and 2 lightweight methods), and meanwhile enjoys the clear memory and run time efficiency. The code and results of our method are available at https://github.com/MathLee/CorrNet.
Deep Reinforcement Learning for Optimal Power Flow with Renewables Using Spatial-Temporal Graph Information
Dec 22, 2021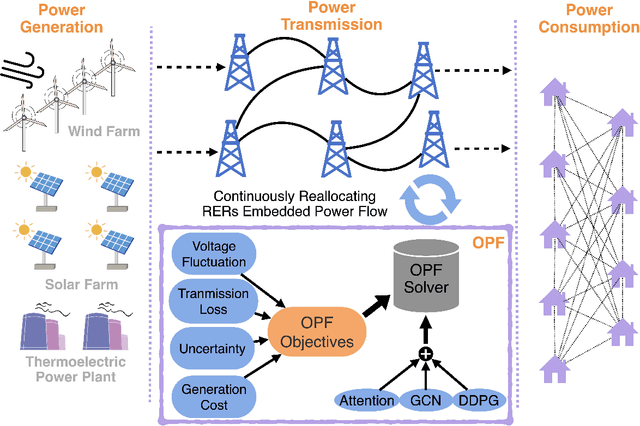
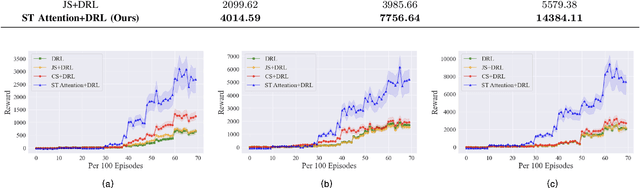
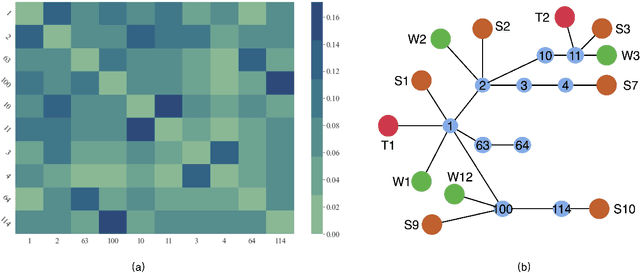
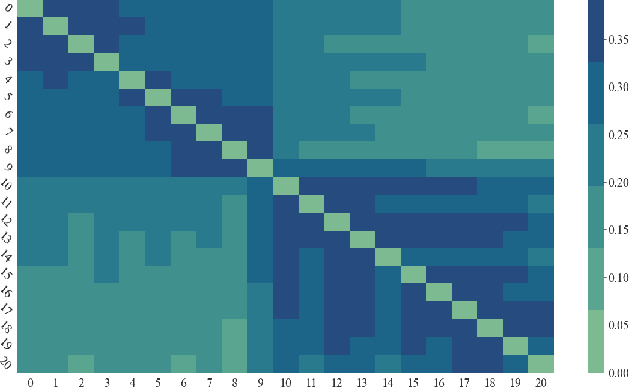
Renewable energy resources (RERs) have been increasingly integrated into modern power systems, especially in large-scale distribution networks (DNs). In this paper, we propose a deep reinforcement learning (DRL)-based approach to dynamically search for the optimal operation point, i.e., optimal power flow (OPF), in DNs with a high uptake of RERs. Considering uncertainties and voltage fluctuation issues caused by RERs, we formulate OPF into a multi-objective optimization (MOO) problem. To solve the MOO problem, we develop a novel DRL algorithm leveraging the graphical information of the distribution network. Specifically, we employ the state-of-the-art DRL algorithm, i.e., deep deterministic policy gradient (DDPG), to learn an optimal strategy for OPF. Since power flow reallocation in the DN is a consecutive process, where nodes are self-correlated and interrelated in temporal and spatial views, to make full use of DNs' graphical information, we develop a multi-grained attention-based spatial-temporal graph convolution network (MG-ASTGCN) for spatial-temporal graph information extraction, preparing for its sequential DDPG. We validate our proposed DRL-based approach in modified IEEE 33, 69, and 118-bus radial distribution systems (RDSs) and show that our DRL-based approach outperforms other benchmark algorithms. Our experimental results also reveal that MG-ASTGCN can significantly accelerate the DDPG training process and improve DDPG's capability in reallocating power flow for OPF. The proposed DRL-based approach also promotes DNs' stability in the presence of node faults, especially for large-scale DNs.
Multi-Content Complementation Network for Salient Object Detection in Optical Remote Sensing Images
Dec 02, 2021
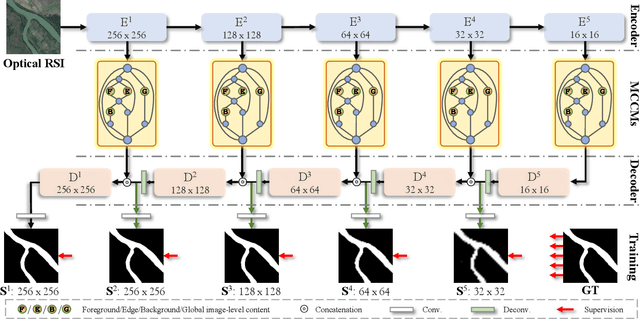
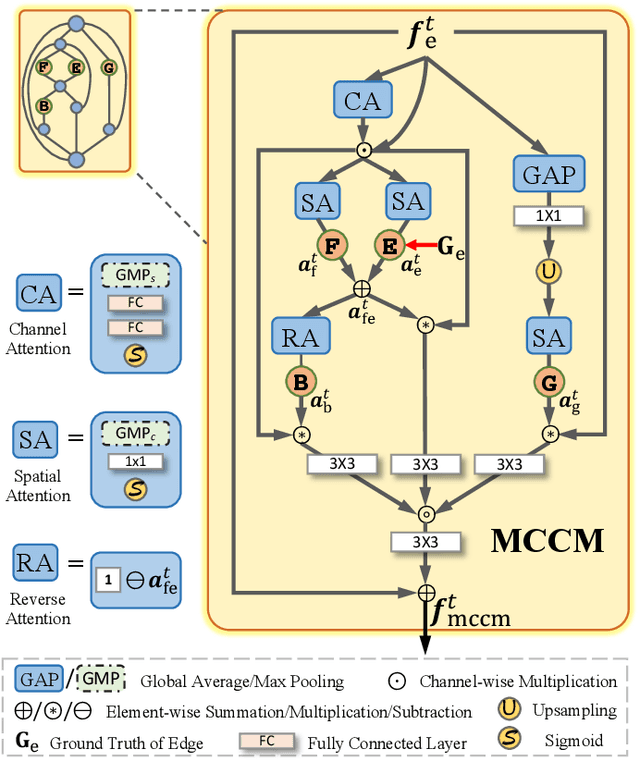
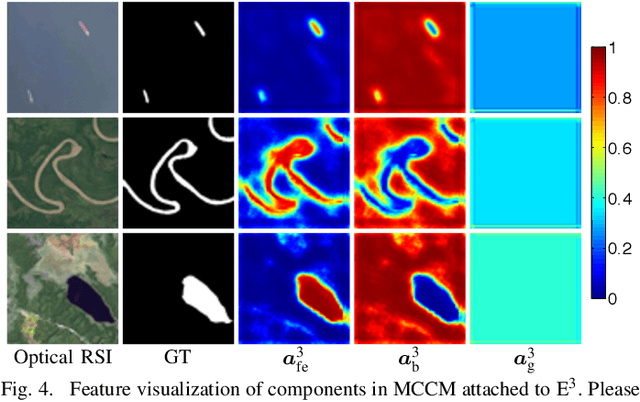
In the computer vision community, great progresses have been achieved in salient object detection from natural scene images (NSI-SOD); by contrast, salient object detection in optical remote sensing images (RSI-SOD) remains to be a challenging emerging topic. The unique characteristics of optical RSIs, such as scales, illuminations and imaging orientations, bring significant differences between NSI-SOD and RSI-SOD. In this paper, we propose a novel Multi-Content Complementation Network (MCCNet) to explore the complementarity of multiple content for RSI-SOD. Specifically, MCCNet is based on the general encoder-decoder architecture, and contains a novel key component named Multi-Content Complementation Module (MCCM), which bridges the encoder and the decoder. In MCCM, we consider multiple types of features that are critical to RSI-SOD, including foreground features, edge features, background features, and global image-level features, and exploit the content complementarity between them to highlight salient regions over various scales in RSI features through the attention mechanism. Besides, we comprehensively introduce pixel-level, map-level and metric-aware losses in the training phase. Extensive experiments on two popular datasets demonstrate that the proposed MCCNet outperforms 23 state-of-the-art methods, including both NSI-SOD and RSI-SOD methods. The code and results of our method are available at https://github.com/MathLee/MCCNet.
A QoE Model in Point Cloud Video Streaming
Nov 09, 2021

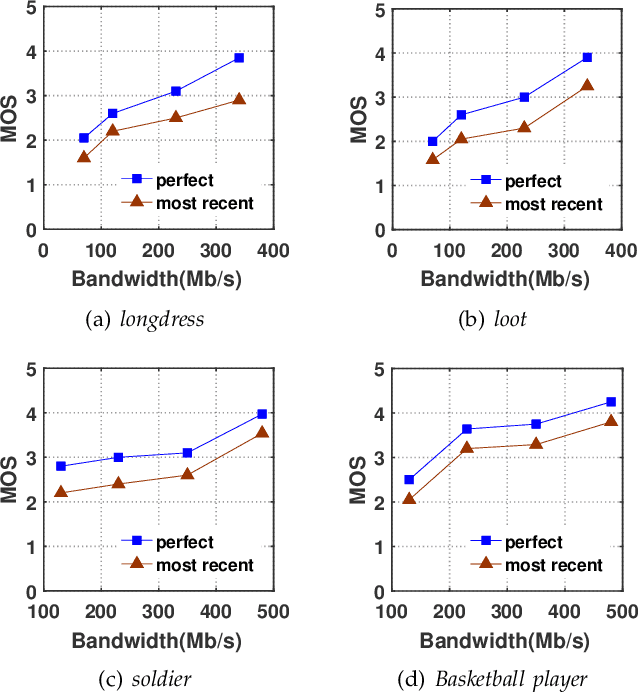

Point cloud video has been widely used by augmented reality (AR) and virtual reality (VR) applications as it allows users to have an immersive experience of six degrees of freedom (6DoFs). Yet there is still a lack of research on quality of experience (QoE) model of point cloud video streaming, which cannot provide optimization metric for streaming systems. Besides, position and color information contained in each pixel of point cloud video, and viewport distance effect caused by 6DoFs viewing procedure make the traditional objective quality evaluation metric cannot be directly used in point cloud video streaming system. In this paper we first analyze the subjective and objective factors related to QoE model. Then an experimental system to simulate point cloud video streaming is setup and detailed subjective quality evaluation experiments are carried out. Based on collected mean opinion score (MOS) data, we propose a QoE model for point cloud video streaming. We also verify the model by actual subjective scoring, and the results show that the proposed QoE model can accurately reflect users' visual perception. We also make the experimental database public to promote the QoE research of point cloud video streaming.
Spatio-Temporal Self-Attention Network for Video Saliency Prediction
Aug 24, 2021
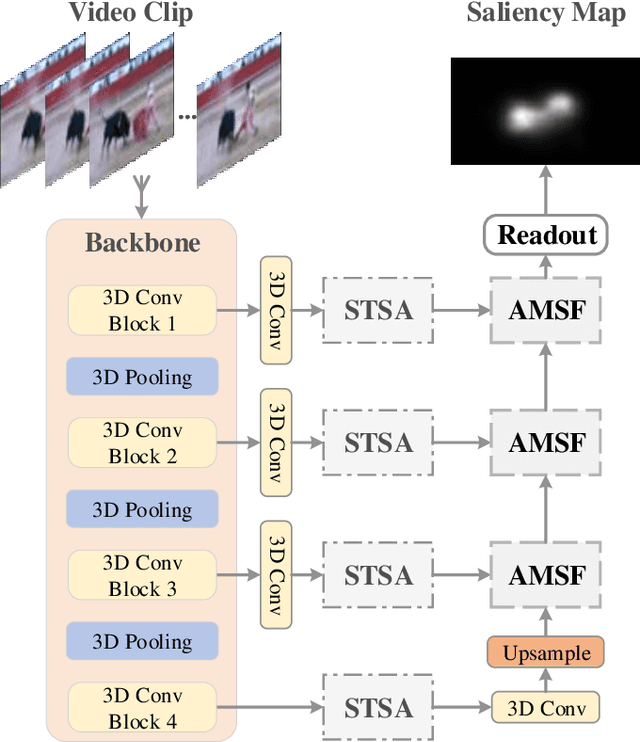
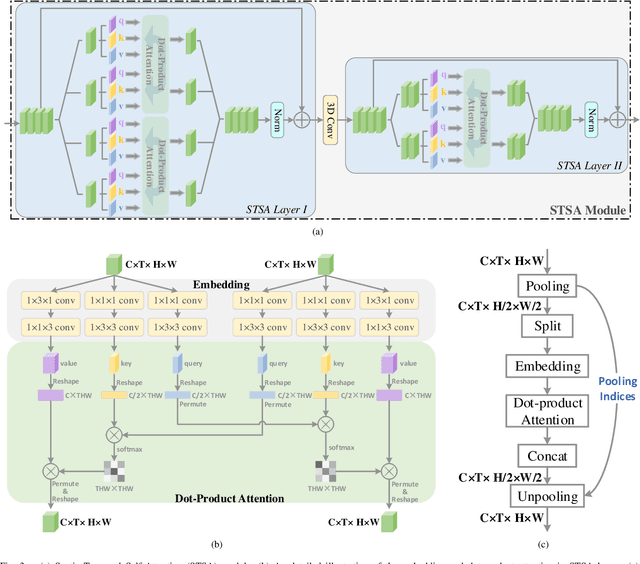
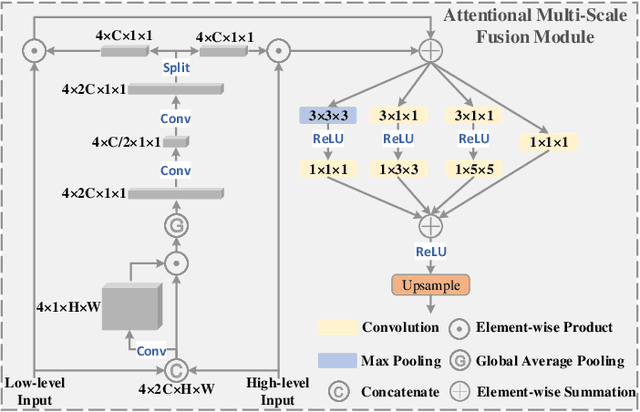
3D convolutional neural networks have achieved promising results for video tasks in computer vision, including video saliency prediction that is explored in this paper. However, 3D convolution encodes visual representation merely on fixed local spacetime according to its kernel size, while human attention is always attracted by relational visual features at different time of a video. To overcome this limitation, we propose a novel Spatio-Temporal Self-Attention 3D Network (STSANet) for video saliency prediction, in which multiple Spatio-Temporal Self-Attention (STSA) modules are employed at different levels of 3D convolutional backbone to directly capture long-range relations between spatio-temporal features of different time steps. Besides, we propose an Attentional Multi-Scale Fusion (AMSF) module to integrate multi-level features with the perception of context in semantic and spatio-temporal subspaces. Extensive experiments demonstrate the contributions of key components of our method, and the results on DHF1K, Hollywood-2, UCF, and DIEM benchmark datasets clearly prove the superiority of the proposed model compared with all state-of-the-art models.
On Sampling Top-K Recommendation Evaluation
Jun 20, 2021
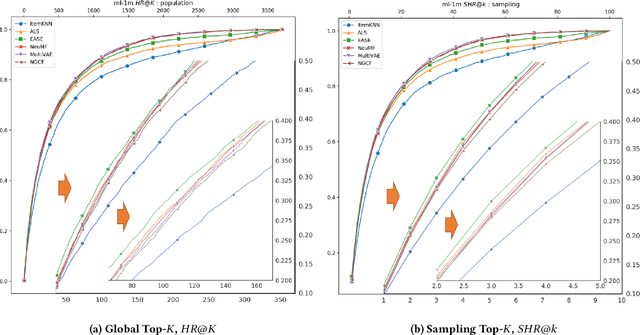
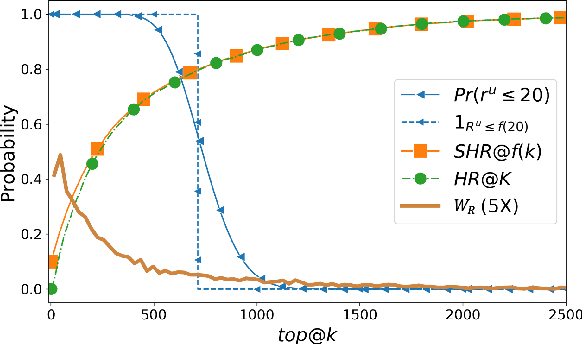
Recently, Rendle has warned that the use of sampling-based top-$k$ metrics might not suffice. This throws a number of recent studies on deep learning-based recommendation algorithms, and classic non-deep-learning algorithms using such a metric, into jeopardy. In this work, we thoroughly investigate the relationship between the sampling and global top-$K$ Hit-Ratio (HR, or Recall), originally proposed by Koren[2] and extensively used by others. By formulating the problem of aligning sampling top-$k$ ($SHR@k$) and global top-$K$ ($HR@K$) Hit-Ratios through a mapping function $f$, so that $SHR@k\approx HR@f(k)$, we demonstrate both theoretically and experimentally that the sampling top-$k$ Hit-Ratio provides an accurate approximation of its global (exact) counterpart, and can consistently predict the correct winners (the same as indicate by their corresponding global Hit-Ratios).