 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnchor3R: Streaming 3D Reconstruction with Transient Anchors for Long-Horizon Visual Mapping
Jun 03, 2026Long-horizon online visual mapping is a core capability for robot perception, requiring continuous camera-motion and scene-geometry estimation from visual streams under bounded memory and computation. Recent feed-forward 3D reconstruction models provide strong geometric priors, but their streaming variants often predict poses in a fixed coordinate system tied to the first frame or a persistent scene memory. This fixed-gauge design leads to train--test mismatch, attention bias toward early anchors, and accumulated drift on sequences much longer than those seen during training. We propose \emph{Anchor3R}, a streaming 3D reconstruction framework that treats feed-forward reconstruction as current-centric local measurement prediction rather than persistent global-gauge regression. At each time step, Anchor3R predicts window-relative poses and a local pointmap in the current-frame coordinate system, turning streaming reconstruction into relative-pose measurement generation. These measurements support online pose updates, while loop-closure reinsertion and motion averaging align the trajectory and transform local pointmaps into a coherent global reconstruction. Experiments on indoor, outdoor, driving, and RGB-D benchmarks show that Anchor3R improves long-horizon pose accuracy and dense reconstruction quality over existing streaming baselines, while supporting bounded-memory online inference.
HorizonStream: Long-Horizon Attention for Streaming 3D Reconstruction
May 22, 2026Online 3D reconstruction requires estimating camera pose and scene geometry under strict causal and bounded-memory constraints. Existing methods often suffer from drift, jitter, or collapse on long sequences. We trace these failures to a fundamental mismatch. Streaming geometry is inherently temporally heterogeneous, with evidence ranging from short-lived correspondences to persistent global scale. However, current architectures impose uniform and pathological influence patterns. For example, sliding windows enforce hard cutoffs, while ungated recurrence and causal attention cause cache saturation and spike-like attention sinks. To resolve this, we formalize geometric propagation as an \emph{evidence influence kernel} and propose HorizonStream, a long-horizon Transformer that explicitly factorizes this kernel. For the long-range temporal factor, Geometric Linear Attention learns channel-wise decay rates to enable bounded, multi-timescale propagation of geometric evidence. For the short-range spatial factor, Geometric Local Attention with Spatiotemporal RoPE performs reliable 3D matching while suppressing attention sinks. Finally, Metric Readout Tokens recover stable scale and rigid pose directly from the persistent geometric state. Extensive experiments show that HorizonStream, trained on only 48-frame clips, generalizes stably to sequences exceeding 10,000\ frames with constant memory and linear time, achieving state-of-the-art streaming 3D reconstruction performance. Project Page: https://3dagentworld.github.io/horizonstream/
HorizonDrive: Self-Corrective Autoregressive World Model for Long-horizon Driving Simulation
May 12, 2026Closed-loop driving simulation requires real-time interaction beyond short offline clips, pushing current driving world models toward autoregressive (AR) rollout. Existing AR distillation approaches typically rely on frame sinks or student-side degradation training. The former transfers poorly to driving due to fast ego-motion and rapid scene changes, while the latter remains bounded by the teacher's single-pass output length and thus provides only a limited supervision horizon. A natural question is: can the teacher itself be extended via AR rollout to provide unbounded-horizon supervision at bounded memory cost? The key difficulty is that a standard teacher drifts under its own predictions, contaminating the supervision it provides. Our key insight is to make the teacher rollout-capable, ensuring reliable supervision from its own AR rollouts. This is instantiated as HorizonDrive, an anti-drifting training-and-distillation framework for AR driving simulation. First, scheduled rollout recovery (SRR) trains the base model to reconstruct ground-truth future clips from prediction-corrupted histories, yielding a teacher that remains stable across long AR rollouts. Second, the rollout-capable teacher is extended via AR rollout, providing long-horizon distribution-matching supervision under bounded memory, while a short-window student aligns to it with teacher rollout DMD (TRD) for efficient real-time deployment. HorizonDrive natively supports minute-scale AR rollout under bounded memory; on nuScenes, HorizonDrive reduces FID by 52% and FVD by 37%, and lowers ARE and DTW by 21% and 9% relative to the strongest long-horizon streaming baselines, while remaining competitive with single-pass driving video generators.
Composing Driving Worlds through Disentangled Control for Adversarial Scenario Generation
Mar 13, 2026A major challenge in autonomous driving is the "long tail" of safety-critical edge cases, which often emerge from unusual combinations of common traffic elements. Synthesizing these scenarios is crucial, yet current controllable generative models provide incomplete or entangled guidance, preventing the independent manipulation of scene structure, object identity, and ego actions. We introduce CompoSIA, a compositional driving video simulator that disentangles these traffic factors, enabling fine-grained control over diverse adversarial driving scenarios. To support controllable identity replacement of scene elements, we propose a noise-level identity injection, allowing pose-agnostic identity generation across diverse element poses, all from a single reference image. Furthermore, a hierarchical dual-branch action control mechanism is introduced to improve action controllability. Such disentangled control enables adversarial scenario synthesis-systematically combining safe elements into dangerous configurations that entangled generators cannot produce. Extensive comparisons demonstrate superior controllable generation quality over state-of-the-art baselines, with a 17% improvement in FVD for identity editing and reductions of 30% and 47% in rotation and translation errors for action control. Furthermore, downstream stress-testing reveals substantial planner failures: across editing modalities, the average collision rate of 3s increases by 173%.
Deep Hybrid Self-Prior for Full 3D Mesh Generation
Aug 24, 2021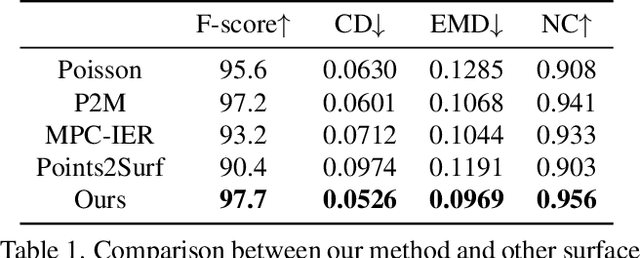
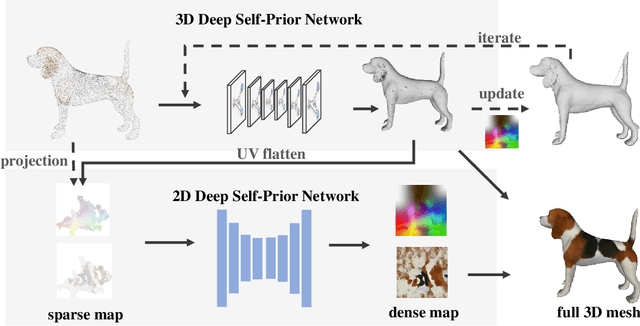
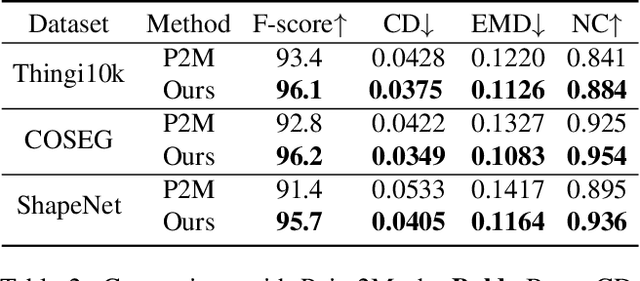
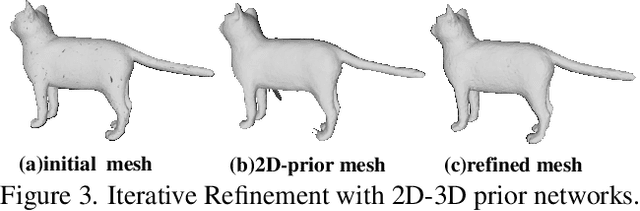
We present a deep learning pipeline that leverages network self-prior to recover a full 3D model consisting of both a triangular mesh and a texture map from the colored 3D point cloud. Different from previous methods either exploiting 2D self-prior for image editing or 3D self-prior for pure surface reconstruction, we propose to exploit a novel hybrid 2D-3D self-prior in deep neural networks to significantly improve the geometry quality and produce a high-resolution texture map, which is typically missing from the output of commodity-level 3D scanners. In particular, we first generate an initial mesh using a 3D convolutional neural network with 3D self-prior, and then encode both 3D information and color information in the 2D UV atlas, which is further refined by 2D convolutional neural networks with the self-prior. In this way, both 2D and 3D self-priors are utilized for the mesh and texture recovery. Experiments show that, without the need of any additional training data, our method recovers the 3D textured mesh model of high quality from sparse input, and outperforms the state-of-the-art methods in terms of both the geometry and texture quality.