 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Efficient Probabilistic Solution to Mapping Errors in LiDAR-Camera Fusion for Autonomous Vehicles
Nov 08, 2023



LiDAR-camera fusion is one of the core processes for the perception system of current automated driving systems. The typical sensor fusion process includes a list of coordinate transformation operations following system calibration. Although a significant amount of research has been done to improve the fusion accuracy, there are still inherent data mapping errors in practice related to system synchronization offsets, vehicle vibrations, the small size of the target, and fast relative moving speeds. Moreover, more and more complicated algorithms to improve fusion accuracy can overwhelm the onboard computational resources, limiting the actual implementation. This study proposes a novel and low-cost probabilistic LiDAR-Camera fusion method to alleviate these inherent mapping errors in scene reconstruction. By calculating shape similarity using KL-divergence and applying RANSAC-regression-based trajectory smoother, the effects of LiDAR-camera mapping errors are minimized in object localization and distance estimation. Designed experiments are conducted to prove the robustness and effectiveness of the proposed strategy.
Risk assessment and mitigation of e-scooter crashes with naturalistic driving data
Dec 24, 2022



Recently, e-scooter-involved crashes have increased significantly but little information is available about the behaviors of on-road e-scooter riders. Most existing e-scooter crash research was based on retrospectively descriptive media reports, emergency room patient records, and crash reports. This paper presents a naturalistic driving study with a focus on e-scooter and vehicle encounters. The goal is to quantitatively measure the behaviors of e-scooter riders in different encounters to help facilitate crash scenario modeling, baseline behavior modeling, and the potential future development of in-vehicle mitigation algorithms. The data was collected using an instrumented vehicle and an e-scooter rider wearable system, respectively. A three-step data analysis process is developed. First, semi-automatic data labeling extracts e-scooter rider images and non-rider human images in similar environments to train an e-scooter-rider classifier. Then, a multi-step scene reconstruction pipeline generates vehicle and e-scooter trajectories in all encounters. The final step is to model e-scooter rider behaviors and e-scooter-vehicle encounter scenarios. A total of 500 vehicle to e-scooter interactions are analyzed. The variables pertaining to the same are also discussed in this paper.
A Wearable Data Collection System for Studying Micro-Level E-Scooter Behavior in Naturalistic Road Environment
Dec 22, 2022



As one of the most popular micro-mobility options, e-scooters are spreading in hundreds of big cities and college towns in the US and worldwide. In the meantime, e-scooters are also posing new challenges to traffic safety. In general, e-scooters are suggested to be ridden in bike lanes/sidewalks or share the road with cars at the maximum speed of about 15-20 mph, which is more flexible and much faster than the pedestrains and bicyclists. These features make e-scooters challenging for human drivers, pedestrians, vehicle active safety modules, and self-driving modules to see and interact. To study this new mobility option and address e-scooter riders' and other road users' safety concerns, this paper proposes a wearable data collection system for investigating the micro-level e-Scooter motion behavior in a Naturalistic road environment. An e-Scooter-based data acquisition system has been developed by integrating LiDAR, cameras, and GPS using the robot operating system (ROS). Software frameworks are developed to support hardware interfaces, sensor operation, sensor synchronization, and data saving. The integrated system can collect data continuously for hours, meeting all the requirements including calibration accuracy and capability of collecting the vehicle and e-Scooter encountering data.
SceNDD: A Scenario-based Naturalistic Driving Dataset
Dec 22, 2022



In this paper, we propose SceNDD: a scenario-based naturalistic driving dataset that is built upon data collected from an instrumented vehicle in downtown Indianapolis. The data collection was completed in 68 driving sessions with different drivers, where each session lasted about 20--40 minutes. The main goal of creating this dataset is to provide the research community with real driving scenarios that have diverse trajectories and driving behaviors. The dataset contains ego-vehicle's waypoints, velocity, yaw angle, as well as non-ego actor's waypoints, velocity, yaw angle, entry-time, and exit-time. Certain flexibility is provided to users so that actors, sensors, lanes, roads, and obstacles can be added to the existing scenarios. We used a Joint Probabilistic Data Association (JPDA) tracker to detect non-ego vehicles on the road. We present some preliminary results of the proposed dataset and a few applications associated with it. The complete dataset is expected to be released by early 2023.
Cause-and-Effect Analysis of ADAS: A Comparison Study between Literature Review and Complaint Data
Jul 30, 2022
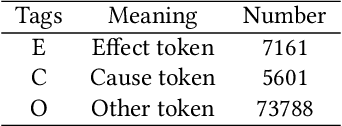
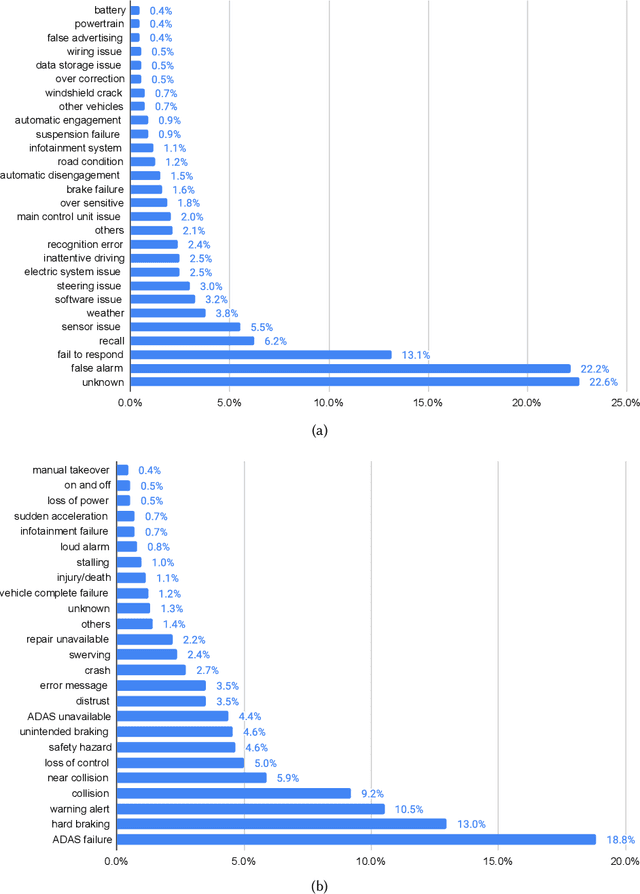

Advanced driver assistance systems (ADAS) are designed to improve vehicle safety. However, it is difficult to achieve such benefits without understanding the causes and limitations of the current ADAS and their possible solutions. This study 1) investigated the limitations and solutions of ADAS through a literature review, 2) identified the causes and effects of ADAS through consumer complaints using natural language processing models, and 3) compared the major differences between the two. These two lines of research identified similar categories of ADAS causes, including human factors, environmental factors, and vehicle factors. However, academic research focused more on human factors of ADAS issues and proposed advanced algorithms to mitigate such issues while drivers complained more of vehicle factors of ADAS failures, which led to associated top consequences. The findings from these two sources tend to complement each other and provide important implications for the improvement of ADAS in the future.
PSI: A Pedestrian Behavior Dataset for Socially Intelligent Autonomous Car
Dec 05, 2021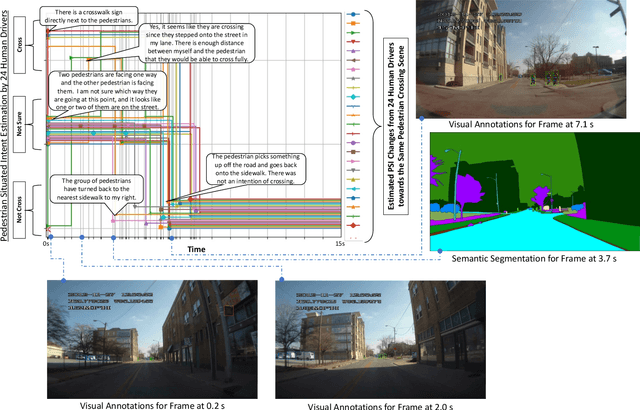
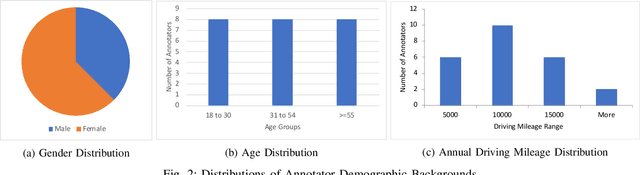


Prediction of pedestrian behavior is critical for fully autonomous vehicles to drive in busy city streets safely and efficiently. The future autonomous cars need to fit into mixed conditions with not only technical but also social capabilities. As more algorithms and datasets have been developed to predict pedestrian behaviors, these efforts lack the benchmark labels and the capability to estimate the temporal-dynamic intent changes of the pedestrians, provide explanations of the interaction scenes, and support algorithms with social intelligence. This paper proposes and shares another benchmark dataset called the IUPUI-CSRC Pedestrian Situated Intent (PSI) data with two innovative labels besides comprehensive computer vision labels. The first novel label is the dynamic intent changes for the pedestrians to cross in front of the ego-vehicle, achieved from 24 drivers with diverse backgrounds. The second one is the text-based explanations of the driver reasoning process when estimating pedestrian intents and predicting their behaviors during the interaction period. These innovative labels can enable several computer vision tasks, including pedestrian intent/behavior prediction, vehicle-pedestrian interaction segmentation, and video-to-language mapping for explainable algorithms. The released dataset can fundamentally improve the development of pedestrian behavior prediction models and develop socially intelligent autonomous cars to interact with pedestrians efficiently. The dataset has been evaluated with different tasks and is released to the public to access.
Detection of E-scooter Riders in Naturalistic Scenes
Nov 28, 2021



E-scooters have become ubiquitous vehicles in major cities around the world.The numbers of e-scooters keep escalating, increasing their interactions with other cars on the road. Normal behavior of an e-scooter rider varies enormously to other vulnerable road users. This situation creates new challenges for vehicle active safety systems and automated driving functionalities, which require the detection of e-scooter riders as the first step. To our best knowledge, there is no existing computer vision model to detect these e-scooter riders. This paper presents a novel vision-based system to differentiate between e-scooter riders and regular pedestrians and a benchmark data set for e-scooter riders in natural scenes. We propose an efficient pipeline built over two existing state-of-the-art convolutional neural networks (CNN), You Only Look Once (YOLOv3) and MobileNetV2. We fine-tune MobileNetV2 over our dataset and train the model to classify e-scooter riders and pedestrians. We obtain a recall of around 0.75 on our raw test sample to classify e-scooter riders with the whole pipeline. Moreover, the classification accuracy of trained MobileNetV2 on top of YOLOv3 is over 91%, with precision and recall over 0.9.
Value of Temporal Dynamics Information in Driving Scene Segmentation
Mar 21, 2019


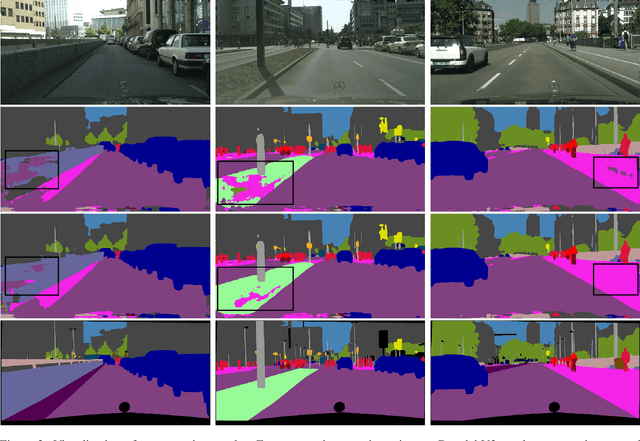
Semantic scene segmentation has primarily been addressed by forming representations of single images both with supervised and unsupervised methods. The problem of semantic segmentation in dynamic scenes has begun to recently receive attention with video object segmentation approaches. What is not known is how much extra information the temporal dynamics of the visual scene carries that is complimentary to the information available in the individual frames of the video. There is evidence that the human visual system can effectively perceive the scene from temporal dynamics information of the scene's changing visual characteristics without relying on the visual characteristics of individual snapshots themselves. Our work takes steps to explore whether machine perception can exhibit similar properties by combining appearance-based representations and temporal dynamics representations in a joint-learning problem that reveals the contribution of each toward successful dynamic scene segmentation. Additionally, we provide the MIT Driving Scene Segmentation dataset, which is a large-scale full driving scene segmentation dataset, densely annotated for every pixel and every one of 5,000 video frames. This dataset is intended to help further the exploration of the value of temporal dynamics information for semantic segmentation in video.