 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePEER: A Collaborative Language Model
Aug 24, 2022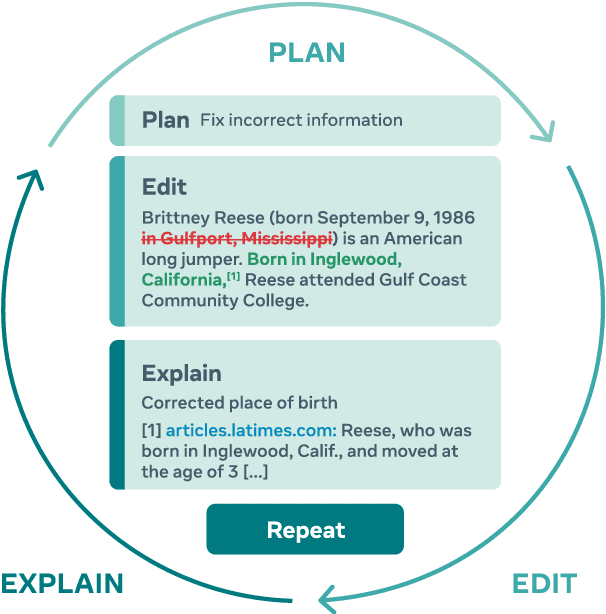
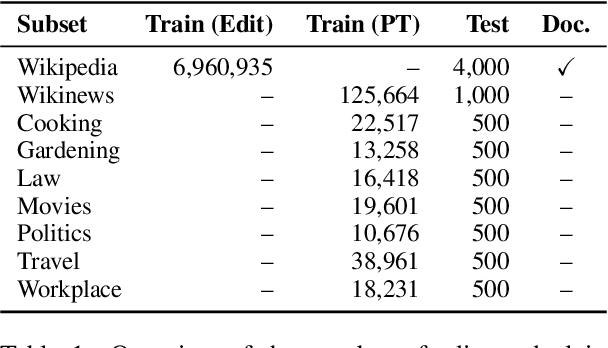
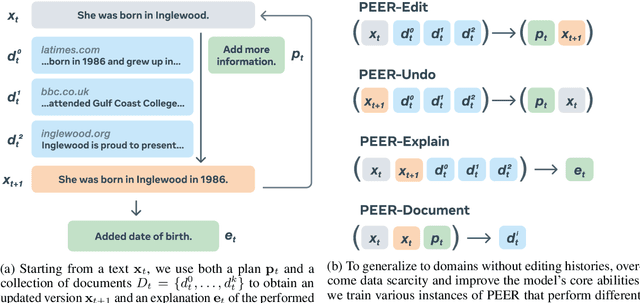
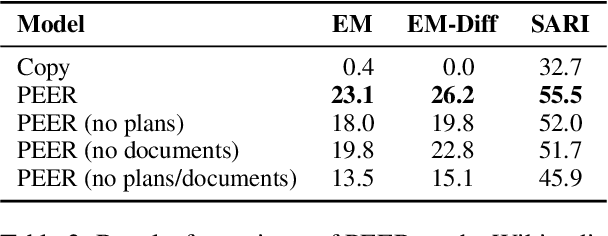
Textual content is often the output of a collaborative writing process: We start with an initial draft, ask for suggestions, and repeatedly make changes. Agnostic of this process, today's language models are trained to generate only the final result. As a consequence, they lack several abilities crucial for collaborative writing: They are unable to update existing texts, difficult to control and incapable of verbally planning or explaining their actions. To address these shortcomings, we introduce PEER, a collaborative language model that is trained to imitate the entire writing process itself: PEER can write drafts, add suggestions, propose edits and provide explanations for its actions. Crucially, we train multiple instances of PEER able to infill various parts of the writing process, enabling the use of self-training techniques for increasing the quality, amount and diversity of training data. This unlocks PEER's full potential by making it applicable in domains for which no edit histories are available and improving its ability to follow instructions, to write useful comments, and to explain its actions. We show that PEER achieves strong performance across various domains and editing tasks.
OmniTab: Pretraining with Natural and Synthetic Data for Few-shot Table-based Question Answering
Jul 08, 2022
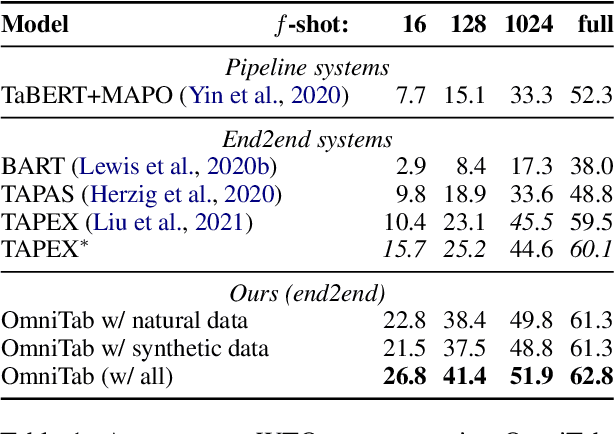
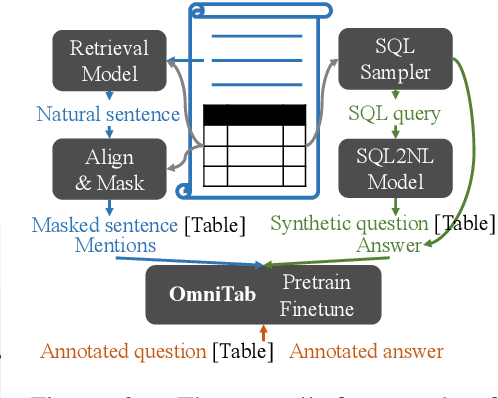
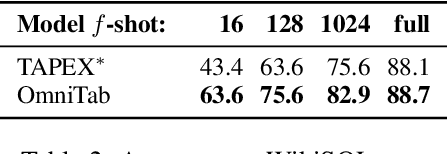
The information in tables can be an important complement to text, making table-based question answering (QA) systems of great value. The intrinsic complexity of handling tables often adds an extra burden to both model design and data annotation. In this paper, we aim to develop a simple table-based QA model with minimal annotation effort. Motivated by the fact that table-based QA requires both alignment between questions and tables and the ability to perform complicated reasoning over multiple table elements, we propose an omnivorous pretraining approach that consumes both natural and synthetic data to endow models with these respective abilities. Specifically, given freely available tables, we leverage retrieval to pair them with relevant natural sentences for mask-based pretraining, and synthesize NL questions by converting SQL sampled from tables for pretraining with a QA loss. We perform extensive experiments in both few-shot and full settings, and the results clearly demonstrate the superiority of our model OmniTab, with the best multitasking approach achieving an absolute gain of 16.2% and 2.7% in 128-shot and full settings respectively, also establishing a new state-of-the-art on WikiTableQuestions. Detailed ablations and analyses reveal different characteristics of natural and synthetic data, shedding light on future directions in omnivorous pretraining. Code, pretraining data, and pretrained models are available at https://github.com/jzbjyb/OmniTab.
Table Retrieval May Not Necessitate Table-specific Model Design
May 19, 2022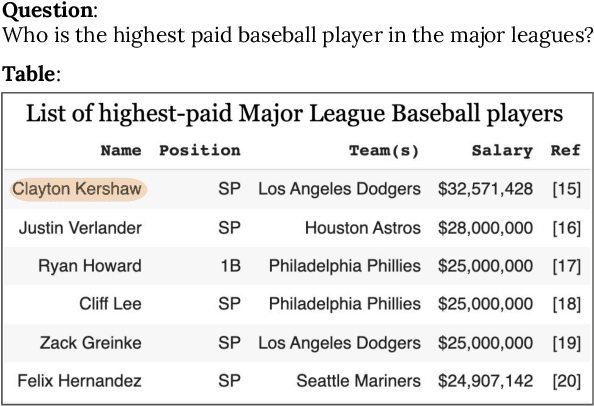

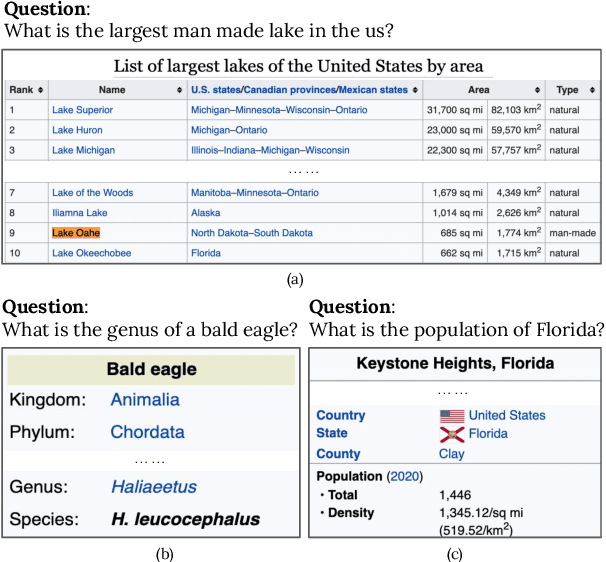

Tables are an important form of structured data for both human and machine readers alike, providing answers to questions that cannot, or cannot easily, be found in texts. Recent work has designed special models and training paradigms for table-related tasks such as table-based question answering and table retrieval. Though effective, they add complexity in both modeling and data acquisition compared to generic text solutions and obscure which elements are truly beneficial. In this work, we focus on the task of table retrieval, and ask: "is table-specific model design necessary for table retrieval, or can a simpler text-based model be effectively used to achieve a similar result?" First, we perform an analysis on a table-based portion of the Natural Questions dataset (NQ-table), and find that structure plays a negligible role in more than 70% of the cases. Based on this, we experiment with a general Dense Passage Retriever (DPR) based on text and a specialized Dense Table Retriever (DTR) that uses table-specific model designs. We find that DPR performs well without any table-specific design and training, and even achieves superior results compared to DTR when fine-tuned on properly linearized tables. We then experiment with three modules to explicitly encode table structures, namely auxiliary row/column embeddings, hard attention masks, and soft relation-based attention biases. However, none of these yielded significant improvements, suggesting that table-specific model design may not be necessary for table retrieval.
Pre-train, Prompt, and Predict: A Systematic Survey of Prompting Methods in Natural Language Processing
Jul 28, 2021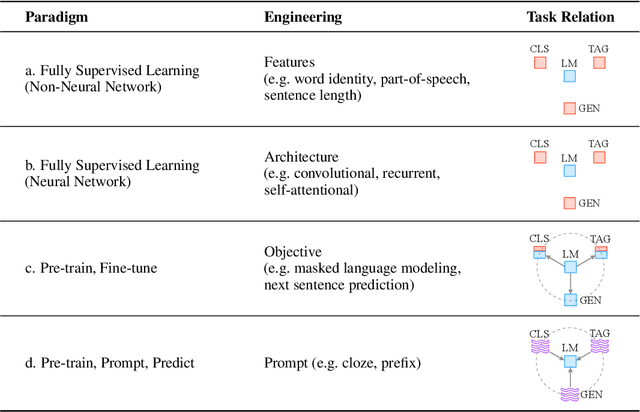
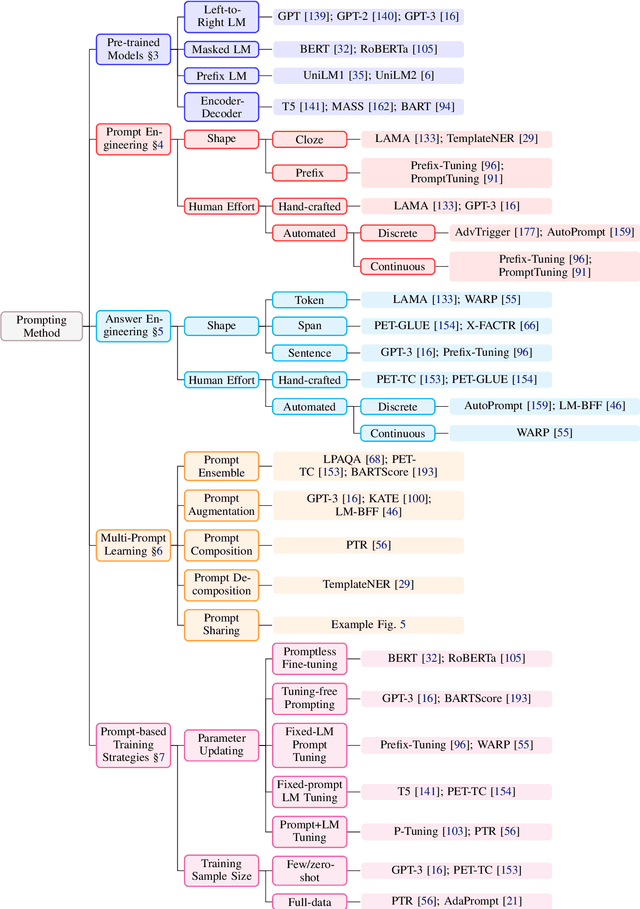
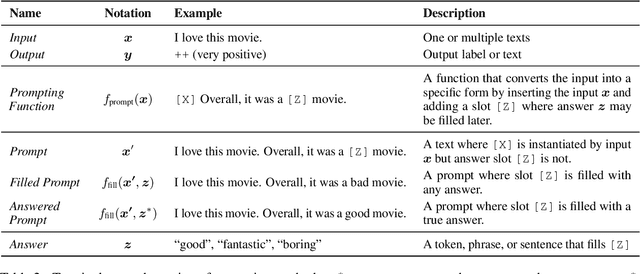
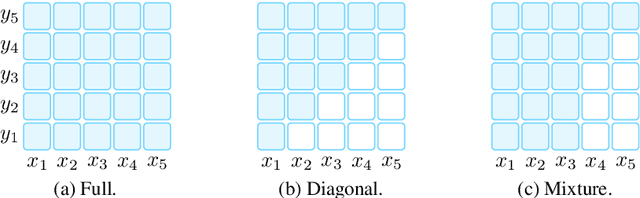
This paper surveys and organizes research works in a new paradigm in natural language processing, which we dub "prompt-based learning". Unlike traditional supervised learning, which trains a model to take in an input x and predict an output y as P(y|x), prompt-based learning is based on language models that model the probability of text directly. To use these models to perform prediction tasks, the original input x is modified using a template into a textual string prompt x' that has some unfilled slots, and then the language model is used to probabilistically fill the unfilled information to obtain a final string x, from which the final output y can be derived. This framework is powerful and attractive for a number of reasons: it allows the language model to be pre-trained on massive amounts of raw text, and by defining a new prompting function the model is able to perform few-shot or even zero-shot learning, adapting to new scenarios with few or no labeled data. In this paper we introduce the basics of this promising paradigm, describe a unified set of mathematical notations that can cover a wide variety of existing work, and organize existing work along several dimensions, e.g.the choice of pre-trained models, prompts, and tuning strategies. To make the field more accessible to interested beginners, we not only make a systematic review of existing works and a highly structured typology of prompt-based concepts, but also release other resources, e.g., a website http://pretrain.nlpedia.ai/ including constantly-updated survey, and paperlist.
CoRI: Collective Relation Integration with Data Augmentation for Open Information Extraction
Jun 01, 2021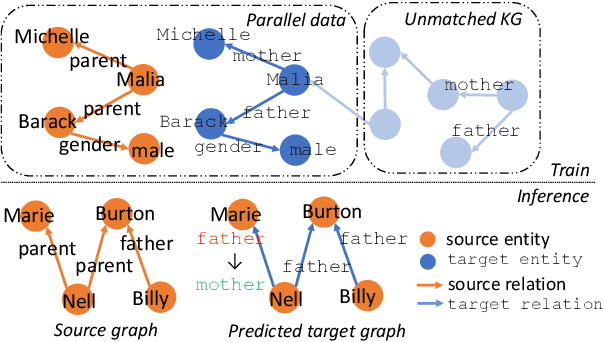
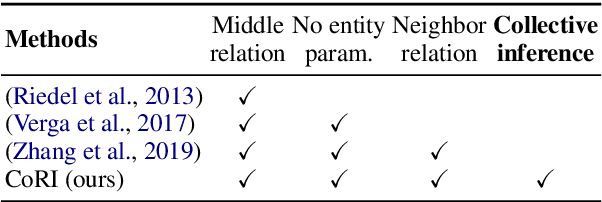
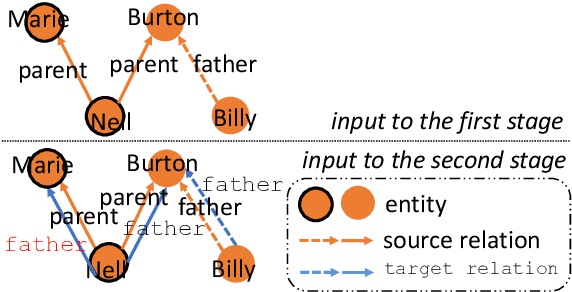
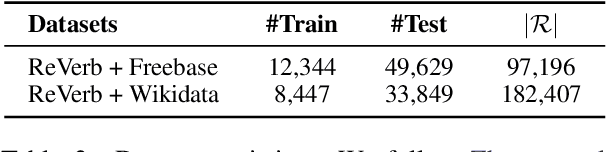
Integrating extracted knowledge from the Web to knowledge graphs (KGs) can facilitate tasks like question answering. We study relation integration that aims to align free-text relations in subject-relation-object extractions to relations in a target KG. To address the challenge that free-text relations are ambiguous, previous methods exploit neighbor entities and relations for additional context. However, the predictions are made independently, which can be mutually inconsistent. We propose a two-stage Collective Relation Integration (CoRI) model, where the first stage independently makes candidate predictions, and the second stage employs a collective model that accesses all candidate predictions to make globally coherent predictions. We further improve the collective model with augmented data from the portion of the target KG that is otherwise unused. Experiment results on two datasets show that CoRI can significantly outperform the baselines, improving AUC from .677 to .748 and from .716 to .780, respectively.
How Can We Know When Language Models Know?
Dec 02, 2020Recent works have shown that language models (LM) capture different types of knowledge regarding facts or common sense. However, because no model is perfect, they still fail to provide appropriate answers in many cases. In this paper, we ask the question "how can we know when language models know, with confidence, the answer to a particular query?" We examine this question from the point of view of calibration, the property of a probabilistic model's predicted probabilities actually being well correlated with the probability of correctness. We first examine a state-of-the-art generative QA model, T5, and examine whether its probabilities are well calibrated, finding the answer is a relatively emphatic no. We then examine methods to calibrate such models to make their confidence scores correlate better with the likelihood of correctness through fine-tuning, post-hoc probability modification, or adjustment of the predicted outputs or inputs. Experiments on a diverse range of datasets demonstrate the effectiveness of our methods. We also perform analysis to study the strengths and limitations of these methods, shedding light on further improvements that may be made in methods for calibrating LMs.
X-FACTR: Multilingual Factual Knowledge Retrieval from Pretrained Language Models
Oct 27, 2020

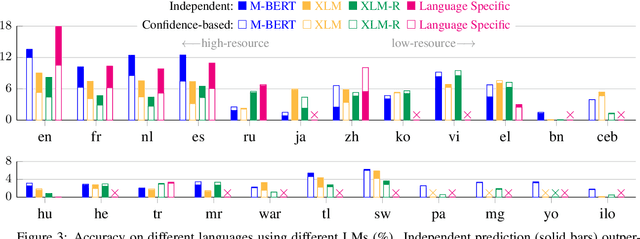
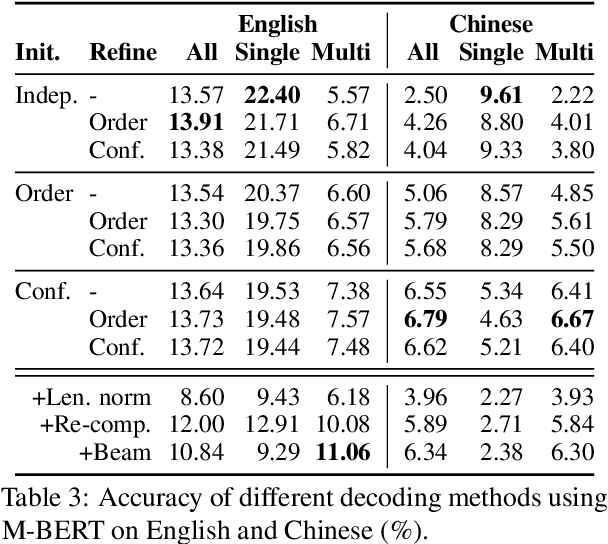
Language models (LMs) have proven surprisingly successful at capturing factual knowledge by completing cloze-style fill-in-the-blank questions such as "Punta Cana is located in _." However, while knowledge is both written and queried in many languages, studies on LMs' factual representation ability have almost invariably been performed on English. To assess factual knowledge retrieval in LMs in different languages, we create a multilingual benchmark of cloze-style probes for 23 typologically diverse languages. To properly handle language variations, we expand probing methods from single- to multi-word entities, and develop several decoding algorithms to generate multi-token predictions. Extensive experimental results provide insights about how well (or poorly) current state-of-the-art LMs perform at this task in languages with more or fewer available resources. We further propose a code-switching-based method to improve the ability of multilingual LMs to access knowledge, and verify its effectiveness on several benchmark languages. Benchmark data and code have been released at https://x-factr.github.io.
GSum: A General Framework for Guided Neural Abstractive Summarization
Oct 15, 2020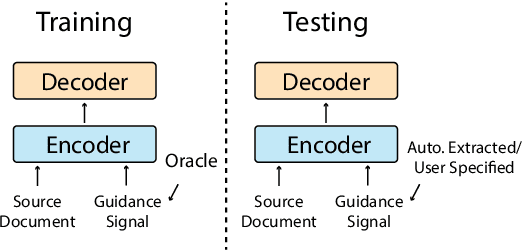
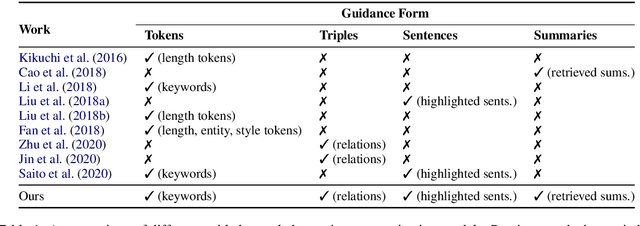
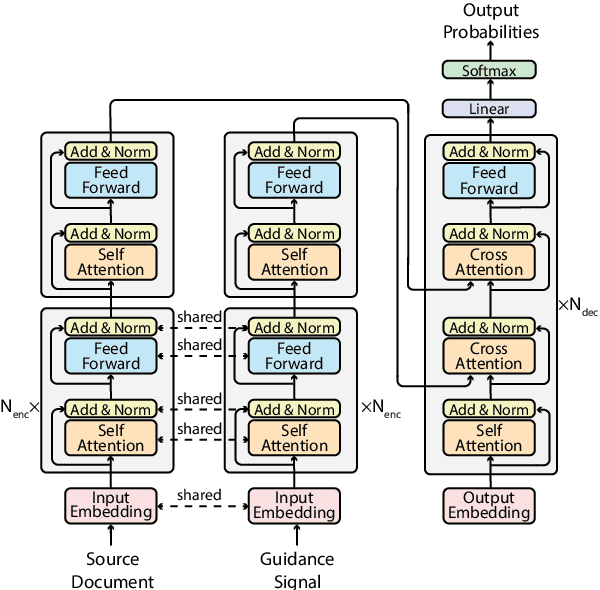
Neural abstractive summarization models are flexible and can produce coherent summaries, but they are sometimes unfaithful and can be difficult to control. While previous studies attempt to provide different types of guidance to control the output and increase faithfulness, it is not clear how these strategies compare and contrast to each other. In this paper, we propose a general and extensible guided summarization framework (GSum) that can effectively take different kinds of external guidance as input, and we perform experiments across several different varieties. Experiments demonstrate that this model is effective, achieving state-of-the-art performance according to ROUGE on 4 popular summarization datasets when using highlighted sentences as guidance. In addition, we show that our guided model can generate more faithful summaries and demonstrate how different types of guidance generate qualitatively different summaries, lending a degree of controllability to the learned models.
Incorporating External Knowledge through Pre-training for Natural Language to Code Generation
Apr 20, 2020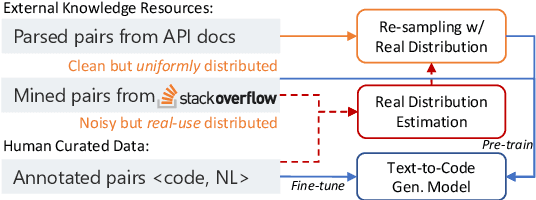
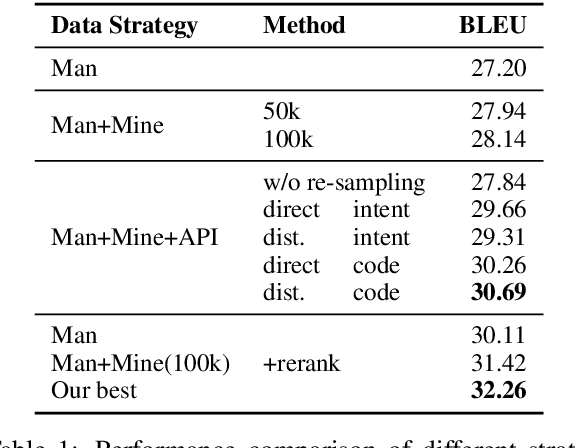


Open-domain code generation aims to generate code in a general-purpose programming language (such as Python) from natural language (NL) intents. Motivated by the intuition that developers usually retrieve resources on the web when writing code, we explore the effectiveness of incorporating two varieties of external knowledge into NL-to-code generation: automatically mined NL-code pairs from the online programming QA forum StackOverflow and programming language API documentation. Our evaluations show that combining the two sources with data augmentation and retrieval-based data re-sampling improves the current state-of-the-art by up to 2.2% absolute BLEU score on the code generation testbed CoNaLa. The code and resources are available at https://github.com/neulab/external-knowledge-codegen.
How Can We Know What Language Models Know?
Nov 28, 2019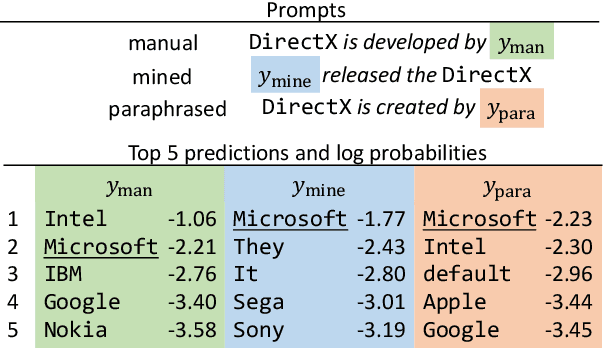
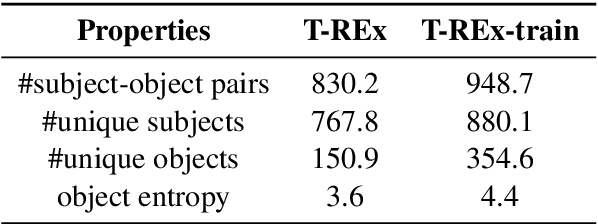
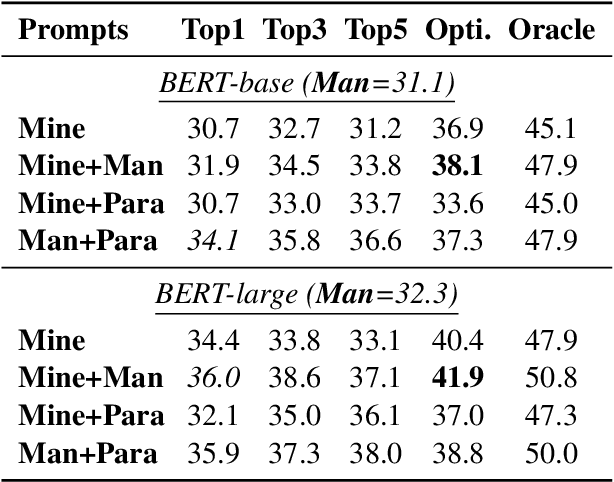
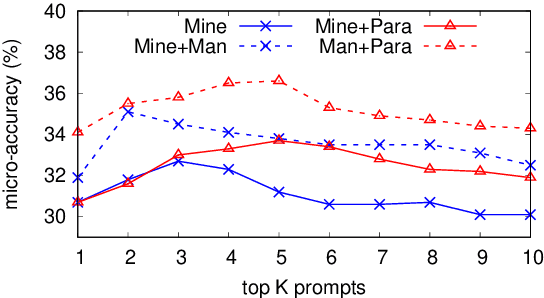
Recent work has presented intriguing results examining the knowledge contained in language models (LM) by having the LM fill in the blanks of prompts such as "Obama is a _ by profession". These prompts are usually manually created, and quite possibly sub-optimal; another prompt such as "Obama worked as a _" may result in more accurately predicting the correct profession. Because of this, given an inappropriate prompt, we might fail to retrieve facts that the LM does know, and thus any given prompt only provides a lower bound estimate of the knowledge contained in an LM. In this paper, we attempt to more accurately estimate the knowledge contained in LMs by automatically discovering better prompts to use in this querying process. Specifically, we propose mining-based and paraphrasing-based methods to automatically generate high-quality and diverse prompts and ensemble methods to combine answers from different prompts. Extensive experiments on the LAMA benchmark for extracting relational knowledge from LMs demonstrate that our methods can improve accuracy from 31.1% to 38.1%, providing a tighter lower bound on what LMs know. We have released the code and the resulting LM Prompt And Query Archive (LPAQA) at https://github.com/jzbjyb/LPAQA.