 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRandomization Techniques to Mitigate the Risk of Copyright Infringement
Aug 21, 2024



In this paper, we investigate potential randomization approaches that can complement current practices of input-based methods (such as licensing data and prompt filtering) and output-based methods (such as recitation checker, license checker, and model-based similarity score) for copyright protection. This is motivated by the inherent ambiguity of the rules that determine substantial similarity in copyright precedents. Given that there is no quantifiable measure of substantial similarity that is agreed upon, complementary approaches can potentially further decrease liability. Similar randomized approaches, such as differential privacy, have been successful in mitigating privacy risks. This document focuses on the technical and research perspective on mitigating copyright violation and hence is not confidential. After investigating potential solutions and running numerical experiments, we concluded that using the notion of Near Access-Freeness (NAF) to measure the degree of substantial similarity is challenging, and the standard approach of training a Differentially Private (DP) model costs significantly when used to ensure NAF. Alternative approaches, such as retrieval models, might provide a more controllable scheme for mitigating substantial similarity.
A Hassle-free Algorithm for Private Learning in Practice: Don't Use Tree Aggregation, Use BLTs
Aug 16, 2024



The state-of-the-art for training on-device language models for mobile keyboard applications combines federated learning (FL) with differential privacy (DP) via the DP-Follow-the-Regularized-Leader (DP-FTRL) algorithm. Two variants of DP-FTRL are used in practice, tree aggregation and matrix factorization. However, tree aggregation suffers from significantly suboptimal privacy/utility tradeoffs, while matrix mechanisms require expensive optimization parameterized by hard-to-estimate-in-advance constants, and high runtime memory costs.This paper extends the recently introduced Buffered Linear Toeplitz (BLT) mechanism to multi-participation scenarios. Our BLT-DP-FTRL maintains the ease-of-use advantages of tree aggregation, while essentially matching matrix factorization in terms of utility and privacy. We evaluate BLT-DP-FTRL on the StackOverflow dataset, serving as a re-producible simulation benchmark, and across four on-device language model tasks in a production FL system. Our empirical results highlight the advantages of the BLT mechanism and elevate the practicality and effectiveness of DP in real-world scenarios.
Improved Communication-Privacy Trade-offs in $L_2$ Mean Estimation under Streaming Differential Privacy
May 02, 2024



We study $L_2$ mean estimation under central differential privacy and communication constraints, and address two key challenges: firstly, existing mean estimation schemes that simultaneously handle both constraints are usually optimized for $L_\infty$ geometry and rely on random rotation or Kashin's representation to adapt to $L_2$ geometry, resulting in suboptimal leading constants in mean square errors (MSEs); secondly, schemes achieving order-optimal communication-privacy trade-offs do not extend seamlessly to streaming differential privacy (DP) settings (e.g., tree aggregation or matrix factorization), rendering them incompatible with DP-FTRL type optimizers. In this work, we tackle these issues by introducing a novel privacy accounting method for the sparsified Gaussian mechanism that incorporates the randomness inherent in sparsification into the DP noise. Unlike previous approaches, our accounting algorithm directly operates in $L_2$ geometry, yielding MSEs that fast converge to those of the uncompressed Gaussian mechanism. Additionally, we extend the sparsification scheme to the matrix factorization framework under streaming DP and provide a precise accountant tailored for DP-FTRL type optimizers. Empirically, our method demonstrates at least a 100x improvement of compression for DP-SGD across various FL tasks.
Prompt Public Large Language Models to Synthesize Data for Private On-device Applications
Apr 05, 2024



Pre-training on public data is an effective method to improve the performance for federated learning (FL) with differential privacy (DP). This paper investigates how large language models (LLMs) trained on public data can improve the quality of pre-training data for the on-device language models trained with DP and FL. We carefully design LLM prompts to filter and transform existing public data, and generate new data to resemble the real user data distribution. The model pre-trained on our synthetic dataset achieves relative improvement of 19.0% and 22.8% in next word prediction accuracy compared to the baseline model pre-trained on a standard public dataset, when evaluated over the real user data in Gboard (Google Keyboard, a production mobile keyboard application). Furthermore, our method achieves evaluation accuracy better than or comparable to the baseline during the DP FL fine-tuning over millions of mobile devices, and our final model outperforms the baseline in production A/B testing. Our experiments demonstrate the strengths of LLMs in synthesizing data close to the private distribution even without accessing the private data, and also suggest future research directions to further reduce the distribution gap.
Comprehensive Implementation of TextCNN for Enhanced Collaboration between Natural Language Processing and System Recommendation
Mar 12, 2024


Natural Language Processing (NLP) is an important branch of artificial intelligence that studies how to enable computers to understand, process, and generate human language. Text classification is a fundamental task in NLP, which aims to classify text into different predefined categories. Text classification is the most basic and classic task in natural language processing, and most of the tasks in natural language processing can be regarded as classification tasks. In recent years, deep learning has achieved great success in many research fields, and today, it has also become a standard technology in the field of NLP, which is widely integrated into text classification tasks. Unlike numbers and images, text processing emphasizes fine-grained processing ability. Traditional text classification methods generally require preprocessing the input model's text data. Additionally, they also need to obtain good sample features through manual annotation and then use classical machine learning algorithms for classification. Therefore, this paper analyzes the application status of deep learning in the three core tasks of NLP (including text representation, word order modeling, and knowledge representation). This content explores the improvement and synergy achieved through natural language processing in the context of text classification, while also taking into account the challenges posed by adversarial techniques in text generation, text classification, and semantic parsing. An empirical study on text classification tasks demonstrates the effectiveness of interactive integration training, particularly in conjunction with TextCNN, highlighting the significance of these advancements in text classification augmentation and enhancement.
Efficient Language Model Architectures for Differentially Private Federated Learning
Mar 12, 2024



Cross-device federated learning (FL) is a technique that trains a model on data distributed across typically millions of edge devices without data leaving the devices. SGD is the standard client optimizer for on device training in cross-device FL, favored for its memory and computational efficiency. However, in centralized training of neural language models, adaptive optimizers are preferred as they offer improved stability and performance. In light of this, we ask if language models can be modified such that they can be efficiently trained with SGD client optimizers and answer this affirmatively. We propose a scale-invariant Coupled Input Forget Gate (SI CIFG) recurrent network by modifying the sigmoid and tanh activations in the recurrent cell and show that this new model converges faster and achieves better utility than the standard CIFG recurrent model in cross-device FL in large scale experiments. We further show that the proposed scale invariant modification also helps in federated learning of larger transformer models. Finally, we demonstrate the scale invariant modification is also compatible with other non-adaptive algorithms. Particularly, our results suggest an improved privacy utility trade-off in federated learning with differential privacy.
Privacy-Preserving Instructions for Aligning Large Language Models
Feb 21, 2024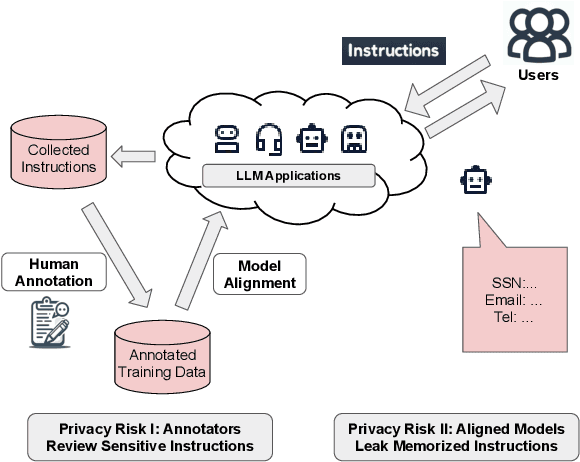
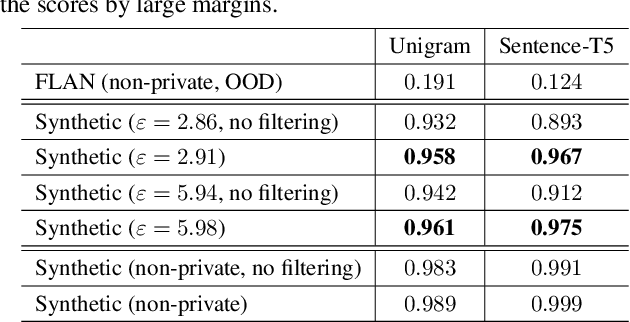
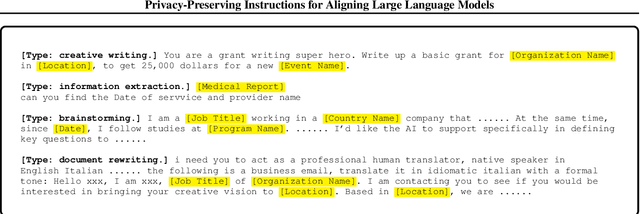
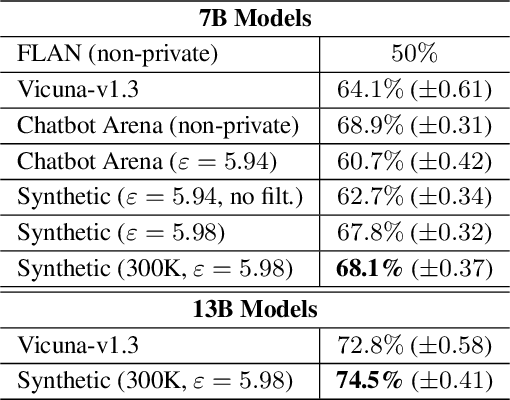
Service providers of large language model (LLM) applications collect user instructions in the wild and use them in further aligning LLMs with users' intentions. These instructions, which potentially contain sensitive information, are annotated by human workers in the process. This poses a new privacy risk not addressed by the typical private optimization. To this end, we propose using synthetic instructions to replace real instructions in data annotation and model fine-tuning. Formal differential privacy is guaranteed by generating those synthetic instructions using privately fine-tuned generators. Crucial in achieving the desired utility is our novel filtering algorithm that matches the distribution of the synthetic instructions to that of the real ones. In both supervised fine-tuning and reinforcement learning from human feedback, our extensive experiments demonstrate the high utility of the final set of synthetic instructions by showing comparable results to real instructions. In supervised fine-tuning, models trained with private synthetic instructions outperform leading open-source models such as Vicuna.
PaLM2-VAdapter: Progressively Aligned Language Model Makes a Strong Vision-language Adapter
Feb 16, 2024This paper demonstrates that a progressively aligned language model can effectively bridge frozen vision encoders and large language models (LLMs). While the fundamental architecture and pre-training methods of vision encoders and LLMs have been extensively studied, the architecture and training strategy of vision-language adapters vary significantly across recent works. Our research undertakes a thorough exploration of the state-of-the-art perceiver resampler architecture and builds a strong baseline. However, we observe that the vision-language alignment with perceiver resampler exhibits slow convergence and limited scalability with a lack of direct supervision. To address this issue, we propose PaLM2-VAdapter, employing a progressively aligned language model as the vision-language adapter. Compared to the strong baseline with perceiver resampler, our method empirically shows faster convergence, higher performance, and stronger scalability. Extensive experiments across various Visual Question Answering (VQA) and captioning tasks on both images and videos demonstrate that our model exhibits state-of-the-art visual understanding and multi-modal reasoning capabilities. Notably, our method achieves these advancements with 30~70% fewer parameters than the state-of-the-art large vision-language models, marking a significant efficiency improvement.
Heterogeneous Low-Rank Approximation for Federated Fine-tuning of On-Device Foundation Models
Jan 12, 2024Large foundation models (FMs) adapt surprisingly well to specific domains or tasks with fine-tuning. Federated learning (FL) further enables private FM fine-tuning using the local data on devices. However, the standard FMs' large size poses challenges for resource-constrained and heterogeneous devices. To address this, we consider FMs with reduced parameter sizes, referred to as on-device FMs (ODFMs). While ODFMs allow on-device inference, computational constraints still hinder efficient federated fine-tuning. We propose a parameter-efficient federated fine-tuning method for ODFMs using heterogeneous low-rank approximations (LoRAs) that addresses system and data heterogeneity. We show that homogeneous LoRA ranks face a trade-off between overfitting and slow convergence, and propose HetLoRA, which employs heterogeneous ranks across clients and eliminates the shortcomings of homogeneous HetLoRA. By applying rank self-pruning locally and sparsity-weighted aggregation at the server, we combine the advantages of high and low-rank LoRAs, which achieves improved convergence speed and final performance compared to homogeneous LoRA. Furthermore, it offers enhanced computation efficiency compared to full fine-tuning, making it suitable for heterogeneous devices while preserving data privacy.
InstructPipe: Building Visual Programming Pipelines with Human Instructions
Dec 15, 2023



Visual programming provides beginner-level programmers with a coding-free experience to build their customized pipelines. Existing systems require users to build a pipeline entirely from scratch, implying that novice users need to set up and link appropriate nodes all by themselves, starting from a blank workspace. We present InstructPipe, an AI assistant that enables users to start prototyping machine learning (ML) pipelines with text instructions. We designed two LLM modules and a code interpreter to execute our solution. LLM modules generate pseudocode of a target pipeline, and the interpreter renders a pipeline in the node-graph editor for further human-AI collaboration. Technical evaluations reveal that InstructPipe reduces user interactions by 81.1% compared to traditional methods. Our user study (N=16) showed that InstructPipe empowers novice users to streamline their workflow in creating desired ML pipelines, reduce their learning curve, and spark innovative ideas with open-ended commands.