 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTODE-Trans: Transparent Object Depth Estimation with Transformer
Sep 18, 2022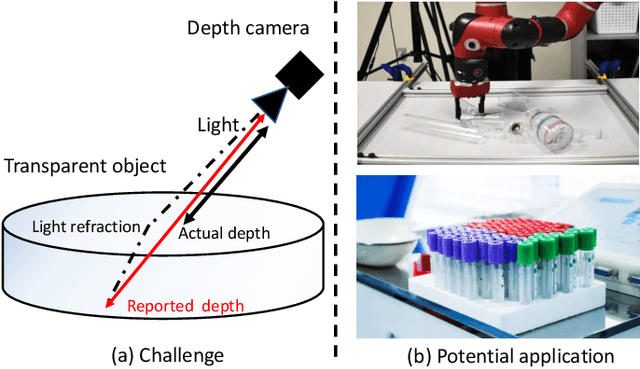
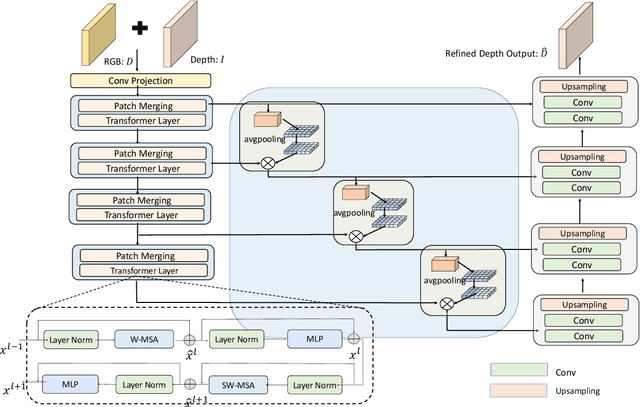


Transparent objects are widely used in industrial automation and daily life. However, robust visual recognition and perception of transparent objects have always been a major challenge. Currently, most commercial-grade depth cameras are still not good at sensing the surfaces of transparent objects due to the refraction and reflection of light. In this work, we present a transformer-based transparent object depth estimation approach from a single RGB-D input. We observe that the global characteristics of the transformer make it easier to extract contextual information to perform depth estimation of transparent areas. In addition, to better enhance the fine-grained features, a feature fusion module (FFM) is designed to assist coherent prediction. Our empirical evidence demonstrates that our model delivers significant improvements in recent popular datasets, e.g., 25% gain on RMSE and 21% gain on REL compared to previous state-of-the-art convolutional-based counterparts in ClearGrasp dataset. Extensive results show that our transformer-based model enables better aggregation of the object's RGB and inaccurate depth information to obtain a better depth representation. Our code and the pre-trained model will be available at https://github.com/yuchendoudou/TODE.
A Robotic Visual Grasping Design: Rethinking Convolution Neural Network with High-Resolutions
Sep 16, 2022
High-resolution representations are important for vision-based robotic grasping problems. Existing works generally encode the input images into low-resolution representations via sub-networks and then recover high-resolution representations. This will lose spatial information, and errors introduced by the decoder will be more serious when multiple types of objects are considered or objects are far away from the camera. To address these issues, we revisit the design paradigm of CNN for robotic perception tasks. We demonstrate that using parallel branches as opposed to serial stacked convolutional layers will be a more powerful design for robotic visual grasping tasks. In particular, guidelines of neural network design are provided for robotic perception tasks, e.g., high-resolution representation and lightweight design, which respond to the challenges in different manipulation scenarios. We then develop a novel grasping visual architecture referred to as HRG-Net, a parallel-branch structure that always maintains a high-resolution representation and repeatedly exchanges information across resolutions. Extensive experiments validate that these two designs can effectively enhance the accuracy of visual-based grasping and accelerate network training. We show a series of comparative experiments in real physical environments at Youtube: https://youtu.be/Jhlsp-xzHFY.
What You See is What You Grasp: User-Friendly Grasping Guided by Near-eye-tracking
Sep 13, 2022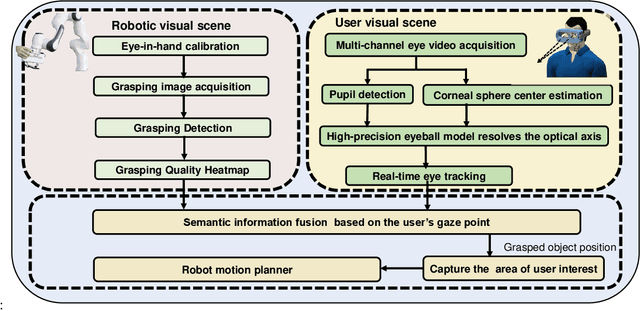

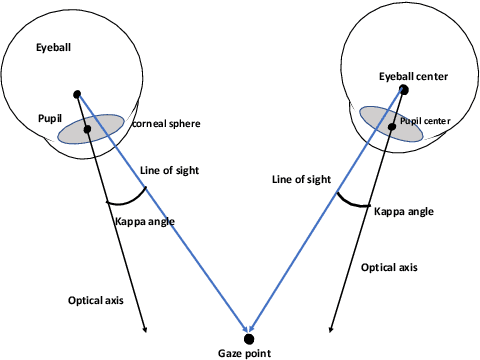
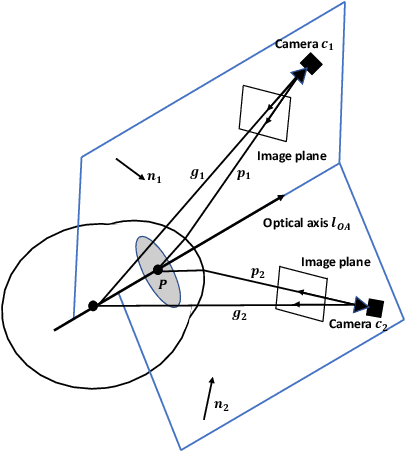
This work presents a next-generation human-robot interface that can infer and realize the user's manipulation intention via sight only. Specifically, we develop a system that integrates near-eye-tracking and robotic manipulation to enable user-specified actions (e.g., grasp, pick-and-place, etc), where visual information is merged with human attention to create a mapping for desired robot actions. To enable sight guided manipulation, a head-mounted near-eye-tracking device is developed to track the eyeball movements in real-time, so that the user's visual attention can be identified. To improve the grasping performance, a transformer based grasp model is then developed. Stacked transformer blocks are used to extract hierarchical features where the volumes of channels are expanded at each stage while squeezing the resolution of feature maps. Experimental validation demonstrates that the eye-tracking system yields low gaze estimation error and the grasping system yields promising results on multiple grasping datasets. This work is a proof of concept for gaze interaction-based assistive robot, which holds great promise to help the elder or upper limb disabilities in their daily lives. A demo video is available at \url{https://www.youtube.com/watch?v=yuZ1hukYUrM}.
When Transformer Meets Robotic Grasping: Exploits Context for Efficient Grasp Detection
Feb 24, 2022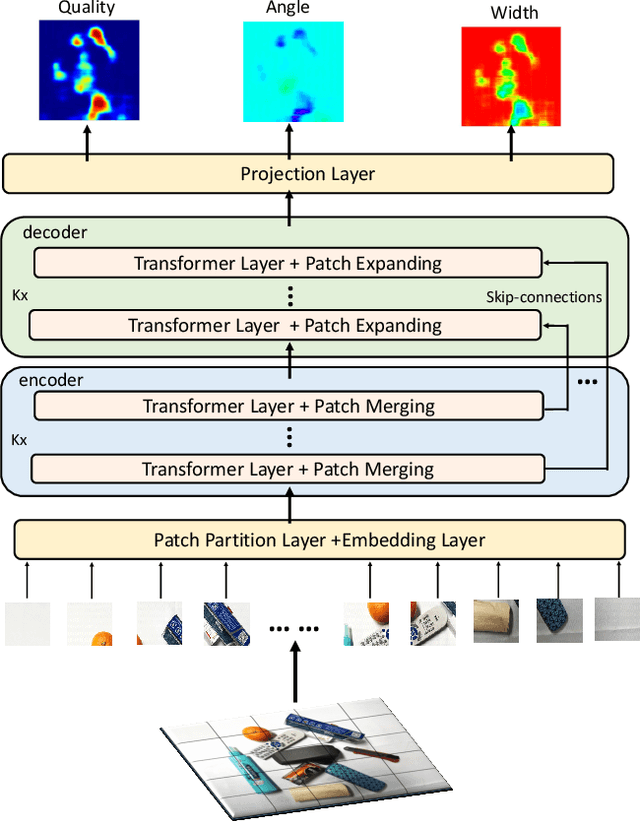
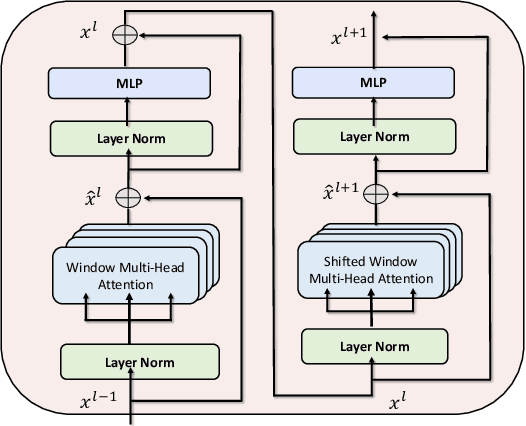


In this paper, we present a transformer-based architecture, namely TF-Grasp, for robotic grasp detection. The developed TF-Grasp framework has two elaborate designs making it well suitable for visual grasping tasks. The first key design is that we adopt the local window attention to capture local contextual information and detailed features of graspable objects. Then, we apply the cross window attention to model the long-term dependencies between distant pixels. Object knowledge, environmental configuration, and relationships between different visual entities are aggregated for subsequent grasp detection. The second key design is that we build a hierarchical encoder-decoder architecture with skip-connections, delivering shallow features from encoder to decoder to enable a multi-scale feature fusion. Due to the powerful attention mechanism, the TF-Grasp can simultaneously obtain the local information (i.e., the contours of objects), and model long-term connections such as the relationships between distinct visual concepts in clutter. Extensive computational experiments demonstrate that the TF-Grasp achieves superior results versus state-of-art grasping convolutional models and attain a higher accuracy of 97.99% and 94.6% on Cornell and Jacquard grasping datasets, respectively. Real-world experiments using a 7DoF Franka Emika Panda robot also demonstrate its capability of grasping unseen objects in a variety of scenarios. The code and pre-trained models will be available at https://github.com/WangShaoSUN/grasp-transformer
Temporal Logic Guided Motion Primitives for Complex Manipulation Tasks with User Preferences
Feb 09, 2022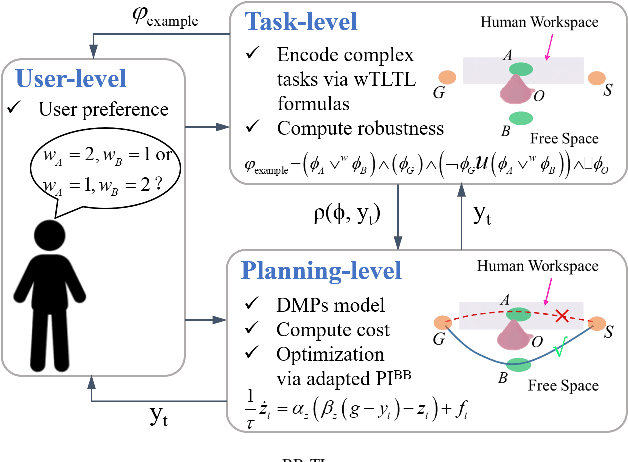

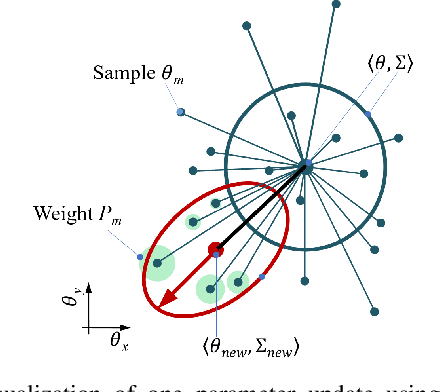
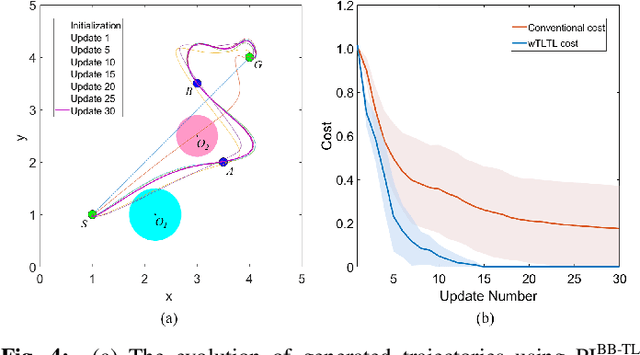
Dynamic movement primitives (DMPs) are a flexible trajectory learning scheme widely used in motion generation of robotic systems. However, existing DMP-based methods mainly focus on simple go-to-goal tasks. Motivated to handle tasks beyond point-to-point motion planning, this work presents temporal logic guided optimization of motion primitives, namely PIBB-TL algorithm, for complex manipulation tasks with user preferences. In particular, weighted truncated linear temporal logic (wTLTL) is incorporated in the PIBB-TL algorithm, which not only enables the encoding of complex tasks that involve a sequence of logically organized action plans with user preferences, but also provides a convenient and efficient means to design the cost function. The black-box optimization is then adapted to identify optimal shape parameters of DMPs to enable motion planning of robotic systems. The effectiveness of the PIBB-TL algorithm is demonstrated via simulation and experime
Online Motion Planning with Soft Timed Temporal Logic in Dynamic and Unknown Environment
Oct 21, 2021
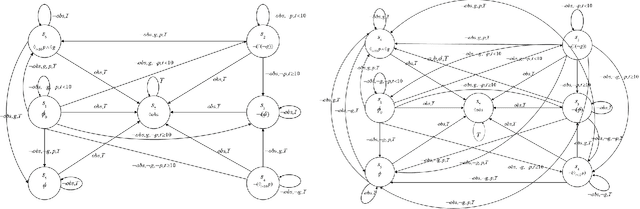
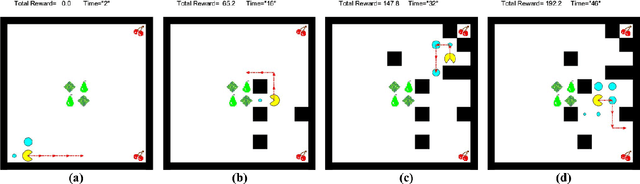
Motion planning of an autonomous system with high-level specifications has wide applications. However, research of formal languages involving timed temporal logic is still under investigation. Furthermore, many existing results rely on a key assumption that user-specified tasks are feasible in the given environment. Challenges arise when the operating environment is dynamic and unknown since the environment can be found prohibitive, leading to potentially conflicting tasks where pre-specified timed missions cannot be fully satisfied. Such issues become even more challenging when considering timed requirements. To address these challenges, this work proposes a control framework that considers hard constraints to enforce safety requirements and soft constraints to enable task relaxation. The metric interval temporal logic (MITL) specifications are employed to deal with time constraints. By constructing a relaxed timed product automaton, an online motion planning strategy is synthesized with a receding horizon controller to generate policies, achieving multiple objectives in decreasing order of priority 1) formally guarantee the satisfaction of hard safety constraints; 2) mostly fulfill soft timed tasks; and 3) collect time-varying rewards as much as possible. Another novelty of the relaxed structure is to consider violations of both time and tasks for infeasible cases. Simulation results are provided to validate the proposed approach.
Modular Deep Reinforcement Learning for Continuous Motion Planning with Temporal Logic
Feb 24, 2021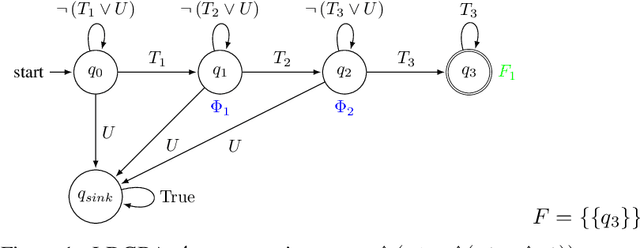
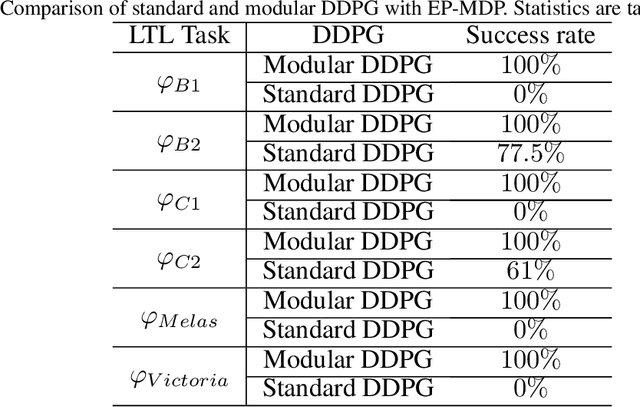
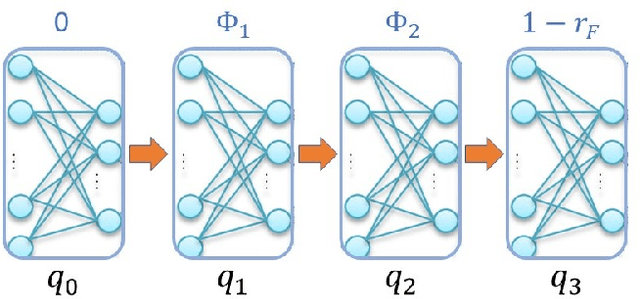
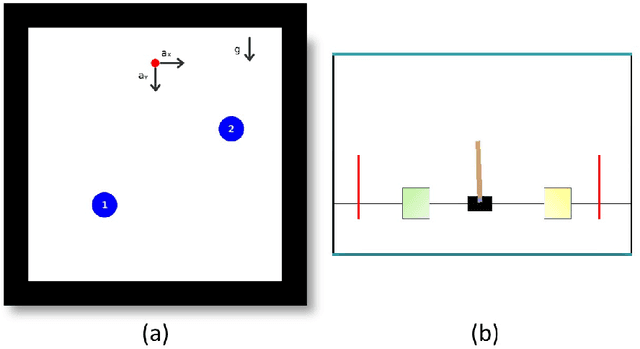
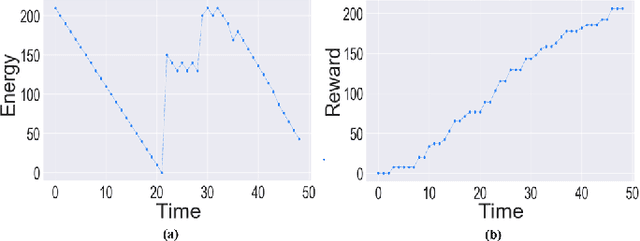
This paper investigates the motion planning of autonomous dynamical systems modeled by Markov decision processes (MDP) with unknown transition probabilities over continuous state and action spaces. Linear temporal logic (LTL) is used to specify high-level tasks over infinite horizon, which can be converted into a limit deterministic generalized B\"uchi automaton (LDGBA) with several accepting sets. The novelty is to design an embedded product MDP (EP-MDP) between the LDGBA and the MDP by incorporating a synchronous tracking-frontier function to record unvisited accepting sets of the automaton, and to facilitate the satisfaction of the accepting conditions. The proposed LDGBA-based reward shaping and discounting schemes for the model-free reinforcement learning (RL) only depend on the EP-MDP states and can overcome the issues of sparse rewards. Rigorous analysis shows that any RL method that optimizes the expected discounted return is guaranteed to find an optimal policy whose traces maximize the satisfaction probability. A modular deep deterministic policy gradient (DDPG) is then developed to generate such policies over continuous state and action spaces. The performance of our framework is evaluated via an array of OpenAI gym environments.
Reinforcement Learning Based Temporal Logic Control with Soft Constraints Using Limit-deterministic Generalized Buchi Automata
Jan 31, 2021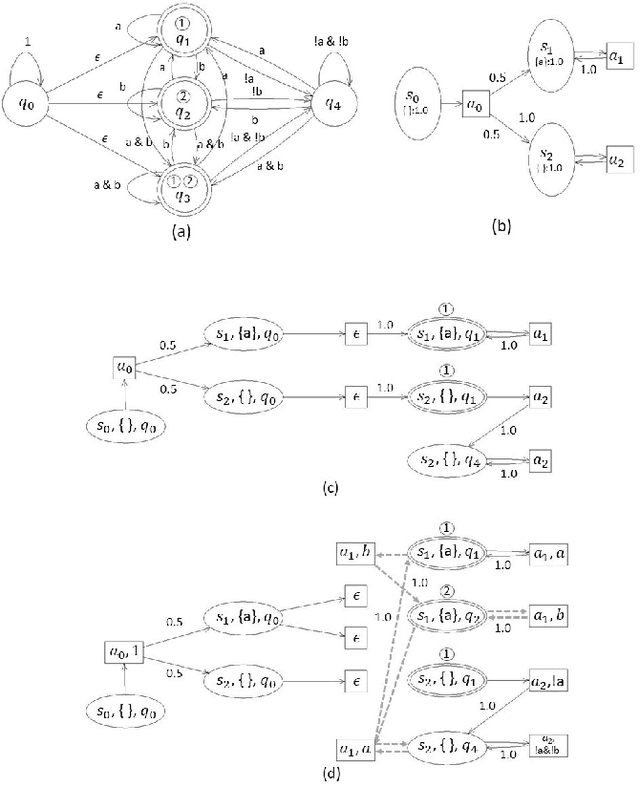
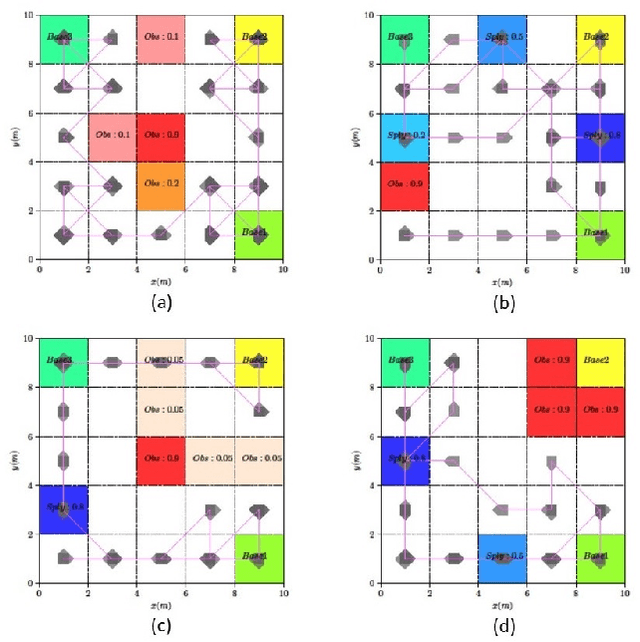
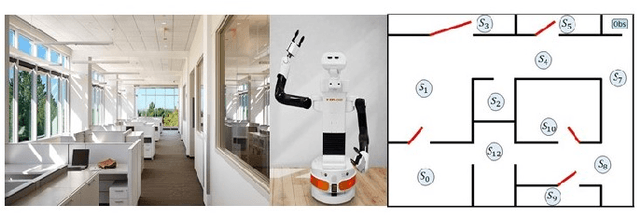
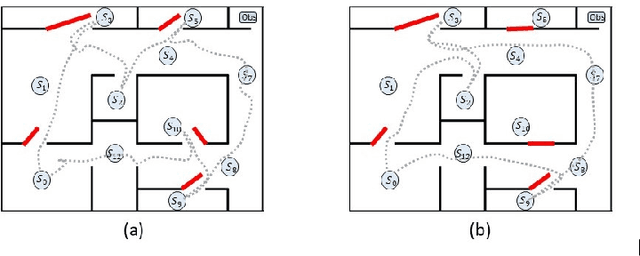
This paper studies the control synthesis of motion planning subject to uncertainties. The uncertainties are considered in robot motion and environment properties, giving rise to the probabilistic labeled Markov decision process (MDP). A model-free reinforcement learning (RL) is developed to generate a finite-memory control policy to satisfy high-level tasks expressed in linear temporal logic (LTL) formulas. One of the novelties is to translate LTL into a limit deterministic generalized B\"uchi automaton (LDGBA) and develop a corresponding embedded LDGBA (E-LDGBA) by incorporating a tracking-frontier function to overcome the issue of sparse accepting rewards, resulting in improved learning performance without increasing computational complexity. Due to potentially conflicting tasks, a relaxed product MDP is developed to allow the agent to revise its motion plan without strictly following the desired LTL constraints if the desired tasks can only be partially fulfilled. An expected return composed of violation rewards and accepting rewards is developed. The designed violation function quantifies the differences between the revised and the desired motion planning, while the accepting rewards are designed to enforce the satisfaction of the acceptance condition of the relaxed product MDP. Rigorous analysis shows that any RL algorithm that optimizes the expected return is guaranteed to find policies that, in decreasing order, can 1) satisfy acceptance condition of relaxed product MDP and 2) reduce the violation cost over long-term behaviors. Also, we validate the control synthesis approach via simulation and experimental results.
Reinforcement Learning Based Temporal Logic Control with Maximum Probabilistic Satisfaction
Oct 15, 2020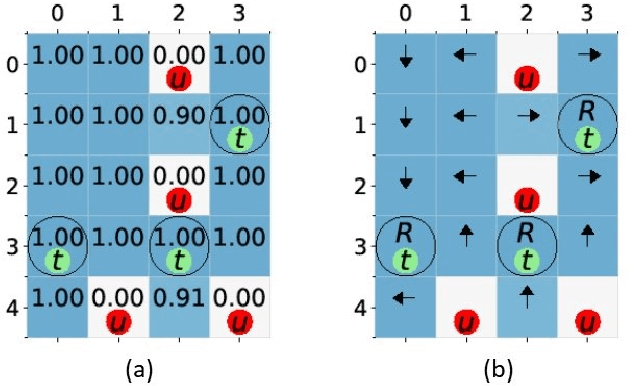
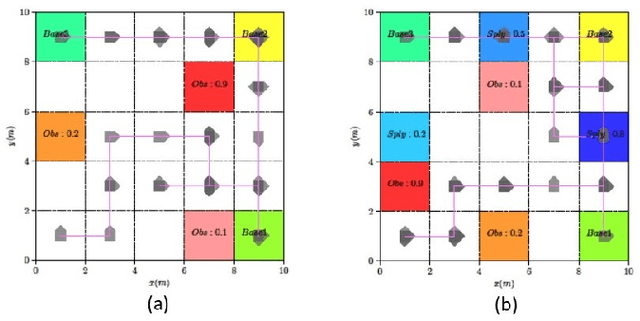
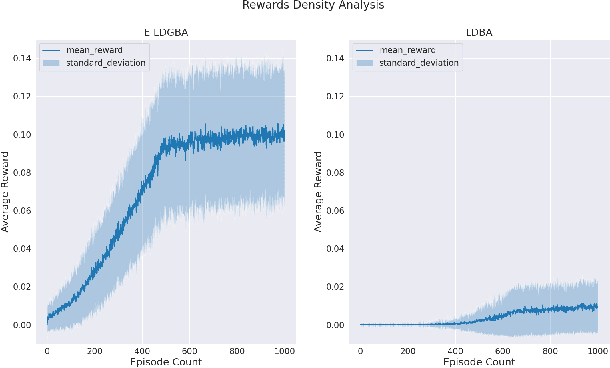
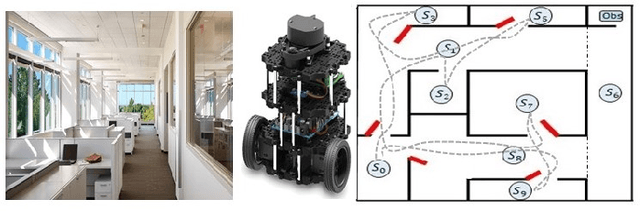
This paper presents a model-free reinforcement learning (RL) algorithm to synthesize a control policy that maximizes the satisfaction probability of linear temporal logic (LTL) specifications. Due to the consideration of environment and motion uncertainties, we model the robot motion as a probabilistic labeled Markov decision process with unknown transition probabilities and unknown probabilistic label functions. The LTL task specification is converted to a limit deterministic generalized B\"uchi automaton (LDGBA) with several accepting sets to maintain dense rewards during learning. The novelty of applying LDGBA is to construct an embedded LDGBA (E-LDGBA) by designing a synchronous tracking-frontier function, which enables the record of non-visited accepting sets without increasing dimensional and computational complexity. With appropriate dependent reward and discount functions, rigorous analysis shows that any method that optimizes the expected discount return of the RL-based approach is guaranteed to find the optimal policy that maximizes the satisfaction probability of the LTL specifications. A model-free RL-based motion planning strategy is developed to generate the optimal policy in this paper. The effectiveness of the RL-based control synthesis is demonstrated via simulation and experimental results.
Optimal Probabilistic Motion Planning with Partially Infeasible LTL Constraints
Jul 28, 2020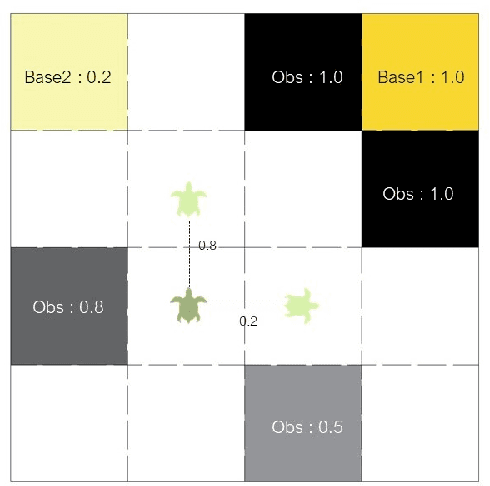
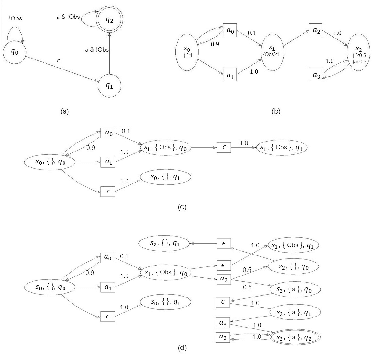
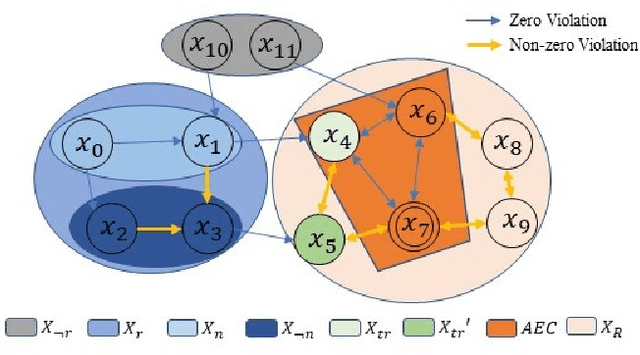
This paper studies optimal probabilistic motion planning of a mobile agent in an uncertain environment where pre-specified tasks might not be fully realized. The agent's motion is modeled by a probabilistic labeled Markov decision process (MDP). A relaxed product MDP is developed, which allows the agent to revise its motion plan to not strictly follow the desired LTL constraints whenever the task is found to be infeasible. To evaluate the revised motion plan, a utility function composed of violation and implementation cost is developed, where the violation cost function is designed to quantify the differences between the revised and the desired motion plan, and the implementation cost are designed to bias the selection towards cost-efficient plans. Based on the developed utility function, a multi-objective optimization problem is formulated to jointly consider the implementation cost, the violation cost, and the satisfaction probability of tasks. Cost optimization in both prefix and suffix of the agent trajectory is then solved via coupled linear programs. Simulation results are provided to demonstrate its effectiveness.