 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLabel Smoothing Improves Machine Unlearning
Jun 11, 2024



The objective of machine unlearning (MU) is to eliminate previously learned data from a model. However, it is challenging to strike a balance between computation cost and performance when using existing MU techniques. Taking inspiration from the influence of label smoothing on model confidence and differential privacy, we propose a simple gradient-based MU approach that uses an inverse process of label smoothing. This work introduces UGradSL, a simple, plug-and-play MU approach that uses smoothed labels. We provide theoretical analyses demonstrating why properly introducing label smoothing improves MU performance. We conducted extensive experiments on six datasets of various sizes and different modalities, demonstrating the effectiveness and robustness of our proposed method. The consistent improvement in MU performance is only at a marginal cost of additional computations. For instance, UGradSL improves over the gradient ascent MU baseline by 66% unlearning accuracy without sacrificing unlearning efficiency.
FedFixer: Mitigating Heterogeneous Label Noise in Federated Learning
Mar 25, 2024Federated Learning (FL) heavily depends on label quality for its performance. However, the label distribution among individual clients is always both noisy and heterogeneous. The high loss incurred by client-specific samples in heterogeneous label noise poses challenges for distinguishing between client-specific and noisy label samples, impacting the effectiveness of existing label noise learning approaches. To tackle this issue, we propose FedFixer, where the personalized model is introduced to cooperate with the global model to effectively select clean client-specific samples. In the dual models, updating the personalized model solely at a local level can lead to overfitting on noisy data due to limited samples, consequently affecting both the local and global models' performance. To mitigate overfitting, we address this concern from two perspectives. Firstly, we employ a confidence regularizer to alleviate the impact of unconfident predictions caused by label noise. Secondly, a distance regularizer is implemented to constrain the disparity between the personalized and global models. We validate the effectiveness of FedFixer through extensive experiments on benchmark datasets. The results demonstrate that FedFixer can perform well in filtering noisy label samples on different clients, especially in highly heterogeneous label noise scenarios.
Fair Classifiers Without Fair Training: An Influence-Guided Data Sampling Approach
Feb 20, 2024



A fair classifier should ensure the benefit of people from different groups, while the group information is often sensitive and unsuitable for model training. Therefore, learning a fair classifier but excluding sensitive attributes in the training dataset is important. In this paper, we study learning fair classifiers without implementing fair training algorithms to avoid possible leakage of sensitive information. Our theoretical analyses validate the possibility of this approach, that traditional training on a dataset with an appropriate distribution shift can reduce both the upper bound for fairness disparity and model generalization error, indicating that fairness and accuracy can be improved simultaneously with simply traditional training. We then propose a tractable solution to progressively shift the original training data during training by sampling influential data, where the sensitive attribute of new data is not accessed in sampling or used in training. Extensive experiments on real-world data demonstrate the effectiveness of our proposed algorithm.
Unmasking and Improving Data Credibility: A Study with Datasets for Training Harmless Language Models
Nov 19, 2023
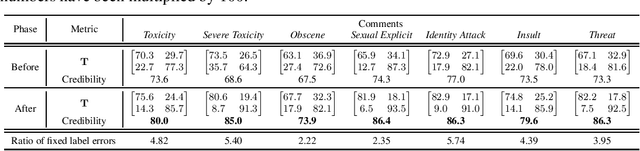
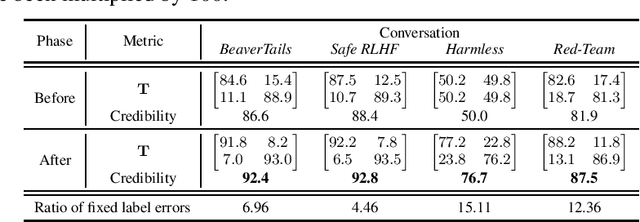
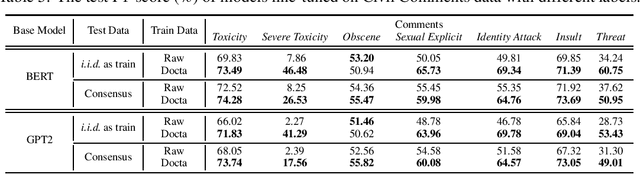
Language models have shown promise in various tasks but can be affected by undesired data during training, fine-tuning, or alignment. For example, if some unsafe conversations are wrongly annotated as safe ones, the model fine-tuned on these samples may be harmful. Therefore, the correctness of annotations, i.e., the credibility of the dataset, is important. This study focuses on the credibility of real-world datasets, including the popular benchmarks Jigsaw Civil Comments, Anthropic Harmless & Red Team, PKU BeaverTails & SafeRLHF, that can be used for training a harmless language model. Given the cost and difficulty of cleaning these datasets by humans, we introduce a systematic framework for evaluating the credibility of datasets, identifying label errors, and evaluating the influence of noisy labels in the curated language data, specifically focusing on unsafe comments and conversation classification. With the framework, we find and fix an average of 6.16% label errors in 11 datasets constructed from the above benchmarks. The data credibility and downstream learning performance can be remarkably improved by directly fixing label errors, indicating the significance of cleaning existing real-world datasets. Open-source: https://github.com/Docta-ai/docta.
Fairness Improves Learning from Noisily Labeled Long-Tailed Data
Mar 22, 2023Both long-tailed and noisily labeled data frequently appear in real-world applications and impose significant challenges for learning. Most prior works treat either problem in an isolated way and do not explicitly consider the coupling effects of the two. Our empirical observation reveals that such solutions fail to consistently improve the learning when the dataset is long-tailed with label noise. Moreover, with the presence of label noise, existing methods do not observe universal improvements across different sub-populations; in other words, some sub-populations enjoyed the benefits of improved accuracy at the cost of hurting others. Based on these observations, we introduce the Fairness Regularizer (FR), inspired by regularizing the performance gap between any two sub-populations. We show that the introduced fairness regularizer improves the performances of sub-populations on the tail and the overall learning performance. Extensive experiments demonstrate the effectiveness of the proposed solution when complemented with certain existing popular robust or class-balanced methods.
Evaluating Fairness Without Sensitive Attributes: A Framework Using Only Auxiliary Models
Oct 06, 2022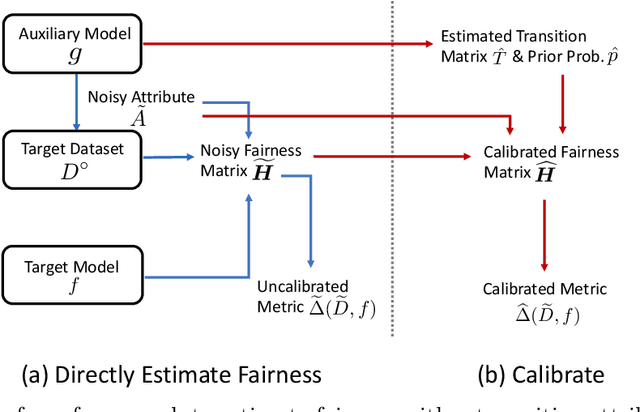
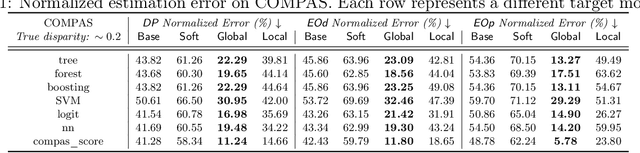
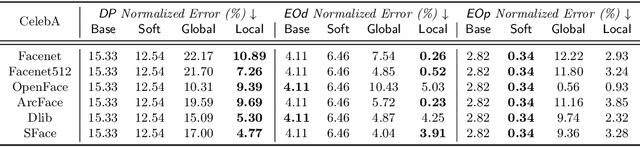

Although the volume of literature and public attention on machine learning fairness has been growing significantly, in practice some tasks as basic as measuring fairness, which is the first step in studying and promoting fairness, can be challenging. This is because sensitive attributes are often unavailable due to privacy regulations. The straightforward solution is to use auxiliary models to predict the missing sensitive attributes. However, our theoretical analyses show that the estimation error of the directly measured fairness metrics is proportional to the error rates of auxiliary models' predictions. Existing works that attempt to reduce the estimation error often require strong assumptions, e.g. access to the ground-truth sensitive attributes or some form of conditional independence. In this paper, we drop those assumptions and propose a framework that uses only off-the-shelf auxiliary models. The main challenge is how to reduce the negative impact of imperfectly predicted sensitive attributes on the fairness metrics without knowing the ground-truth sensitive attributes. Inspired by the noisy label learning literature, we first derive a closed-form relationship between the directly measured fairness metrics and their corresponding ground-truth metrics. And then we estimate some key statistics (most importantly transition matrix in the noisy label literature), which we use, together with the derived relationship, to calibrate the fairness metrics. In addition, we theoretically prove the upper bound of the estimation error in our calibrated metrics and show our method can substantially decrease the estimation error especially when auxiliary models are inaccurate or the target model is highly biased. Experiments on COMPAS and CelebA validate our theoretical analyses and show our method can measure fairness significantly more accurately than baselines under favorable circumstances.
To Aggregate or Not? Learning with Separate Noisy Labels
Jun 14, 2022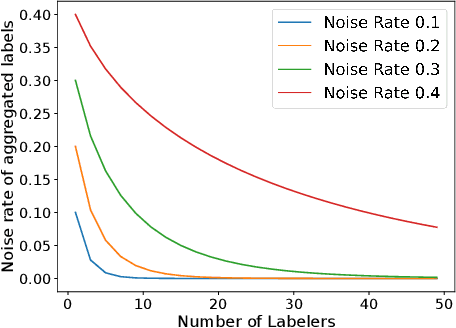
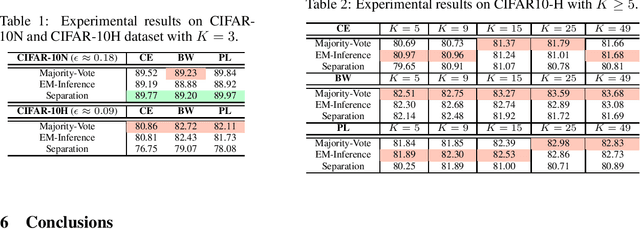
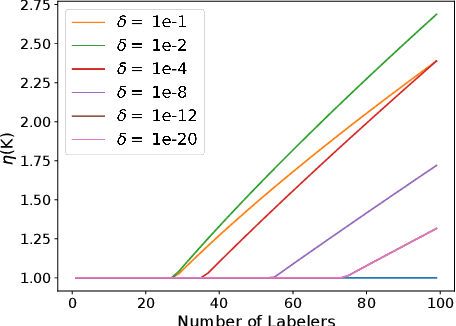
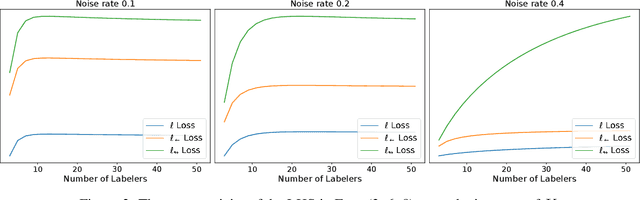
The rawly collected training data often comes with separate noisy labels collected from multiple imperfect annotators (e.g., via crowdsourcing). Typically one would first aggregate the separate noisy labels into one and apply standard training methods. The literature has also studied extensively on effective aggregation approaches. This paper revisits this choice and aims to provide an answer to the question of whether one should aggregate separate noisy labels into single ones or use them separately as given. We theoretically analyze the performance of both approaches under the empirical risk minimization framework for a number of popular loss functions, including the ones designed specifically for the problem of learning with noisy labels. Our theorems conclude that label separation is preferred over label aggregation when the noise rates are high, or the number of labelers/annotations is insufficient. Extensive empirical results validate our conclusion.
Beyond Images: Label Noise Transition Matrix Estimation for Tasks with Lower-Quality Features
Feb 02, 2022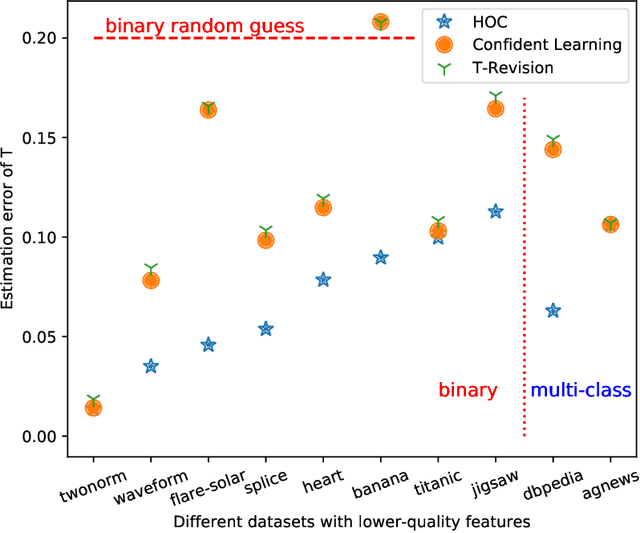
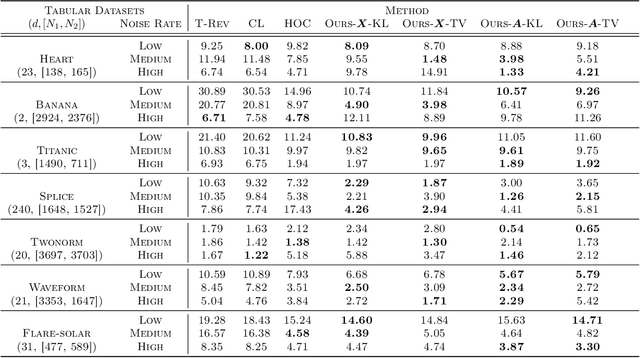
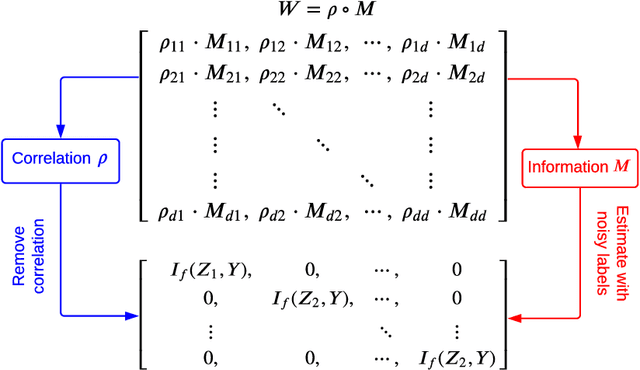
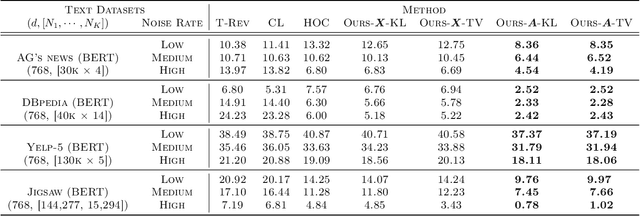
The label noise transition matrix, denoting the transition probabilities from clean labels to noisy labels, is crucial knowledge for designing statistically robust solutions. Existing estimators for noise transition matrices, e.g., using either anchor points or clusterability, focus on computer vision tasks that are relatively easier to obtain high-quality representations. However, for other tasks with lower-quality features, the uninformative variables may obscure the useful counterpart and make anchor-point or clusterability conditions hard to satisfy. We empirically observe the failures of these approaches on a number of commonly used datasets. In this paper, to handle this issue, we propose a generally practical information-theoretic approach to down-weight the less informative parts of the lower-quality features. The salient technical challenge is to compute the relevant information-theoretical metrics using only noisy labels instead of clean ones. We prove that the celebrated $f$-mutual information measure can often preserve the order when calculated using noisy labels. The necessity and effectiveness of the proposed method is also demonstrated by evaluating the estimation error on a varied set of tabular data and text classification tasks with lower-quality features. Code is available at github.com/UCSC-REAL/Est-T-MI.
Learning with Noisy Labels Revisited: A Study Using Real-World Human Annotations
Oct 22, 2021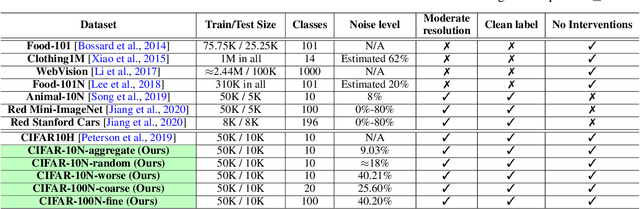


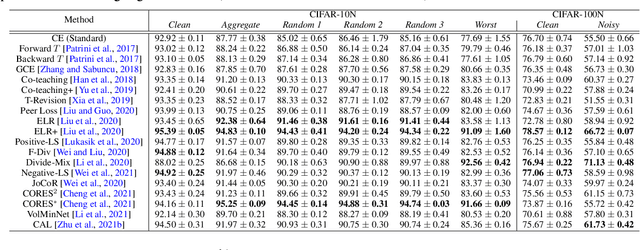
Existing research on learning with noisy labels mainly focuses on synthetic label noise. Synthetic label noise, though has clean structures which greatly enable statistical analyses, often fails to model the real-world noise patterns. The recent literature has observed several efforts to offer real-world noisy datasets, yet the existing efforts suffer from two caveats: firstly, the lack of ground-truth verification makes it hard to theoretically study the property and treatment of real-world label noise. Secondly, these efforts are often of large scales, which may lead to unfair comparisons of robust methods within reasonable and accessible computation power. To better understand real-world label noise, it is important to establish controllable and moderate-sized real-world noisy datasets with both ground-truth and noisy labels. This work presents two new benchmark datasets (CIFAR-10N, CIFAR-100N), equipping the train dataset of CIFAR-10 and CIFAR-100 with human-annotated real-world noisy labels that we collect from Amazon Mechanical Turk. We quantitatively and qualitatively show that real-world noisy labels follow an instance-dependent pattern rather than the classically adopted class-dependent ones. We then initiate an effort to benchmark a subset of existing solutions using CIFAR-10N, CIFAR-100N. We next proceed to study the memorization of model predictions, which further illustrates the difference between human noise and class-dependent synthetic noise. We show indeed the real-world noise patterns impose new and outstanding challenges as compared to synthetic ones. These observations require us to rethink the treatment of noisy labels, and we hope the availability of these two datasets would facilitate the development and evaluation of future learning with noisy label solutions. The corresponding datasets and the leaderboard are publicly available at \url{http://noisylabels.com}.
Demystifying How Self-Supervised Features Improve Training from Noisy Labels
Oct 18, 2021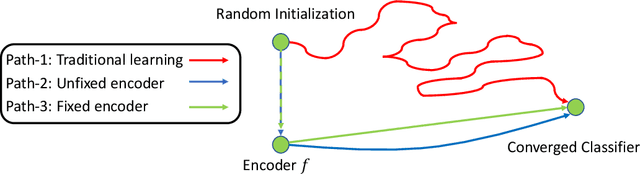

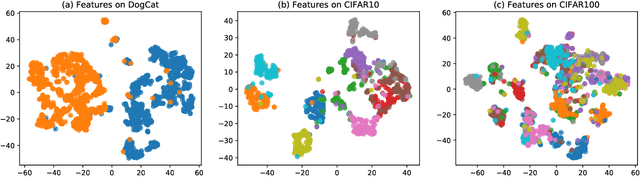
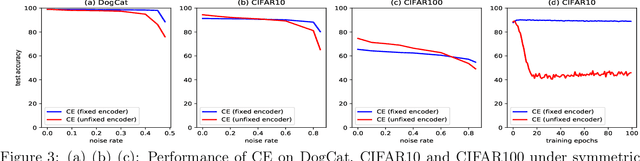
The advancement of self-supervised learning (SSL) motivates researchers to apply SSL on other tasks such as learning with noisy labels. Recent literature indicates that methods built on SSL features can substantially improve the performance of learning with noisy labels. Nonetheless, the deeper reasons why (and how) SSL features benefit the training from noisy labels are less understood. In this paper, we study why and how self-supervised features help networks resist label noise using both theoretical analyses and numerical experiments. Our result shows that, given a quality encoder pre-trained from SSL, a simple linear layer trained by the cross-entropy loss is theoretically robust to symmetric label noise. Further, we provide insights for how knowledge distilled from SSL features can alleviate the over-fitting problem. We hope our work provides a better understanding for learning with noisy labels from the perspective of self-supervised learning and can potentially serve as a guideline for further research. Code is available at github.com/UCSC-REAL/SelfSup_NoisyLabel.