 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImaging foundation model for universal enhancement of non-ideal measurement CT
Oct 02, 2024Non-ideal measurement computed tomography (NICT), which sacrifices optimal imaging standards for new advantages in CT imaging, is expanding the clinical application scope of CT images. However, with the reduction of imaging standards, the image quality has also been reduced, extremely limiting the clinical acceptability. Although numerous studies have demonstrated the feasibility of deep learning for the NICT enhancement in specific scenarios, their high data cost and limited generalizability have become large obstacles. The recent research on the foundation model has brought new opportunities for building a universal NICT enhancement model - bridging the image quality degradation with minimal data cost. However, owing to the challenges in the collection of large pre-training datasets and the compatibility of data variation, no success has been reported. In this paper, we propose a multi-scale integrated Transformer AMPlifier (TAMP), the first imaging foundation model for universal NICT enhancement. It has been pre-trained on a large-scale physical-driven simulation dataset with 3.6 million NICT-ICT image pairs, and is able to directly generalize to the NICT enhancement tasks with various non-ideal settings and body regions. Via the adaptation with few data, it can further achieve professional performance in real-world specific scenarios. Our extensive experiments have demonstrated that the proposed TAMP has significant potential for promoting the exploration and application of NICT and serving a wider range of medical scenarios.
Respiratory Subtraction for Pulmonary Microwave Ablation Evaluation
Aug 08, 2024



Currently, lung cancer is a leading cause of global cancer mortality, often necessitating minimally invasive interventions. Microwave ablation (MWA) is extensively utilized for both primary and secondary lung tumors. Although numerous clinical guidelines and standards for MWA have been established, the clinical evaluation of ablation surgery remains challenging and requires long-term patient follow-up for confirmation. In this paper, we propose a method termed respiratory subtraction to evaluate lung tumor ablation therapy performance based on pre- and post-operative image guidance. Initially, preoperative images undergo coarse rigid registration to their corresponding postoperative positions, followed by further non-rigid registration. Subsequently, subtraction images are generated by subtracting the registered preoperative images from the postoperative ones. Furthermore, to enhance the clinical assessment of MWA treatment performance, we devise a quantitative analysis metric to evaluate ablation efficacy by comparing differences between tumor areas and treatment areas. To the best of our knowledge, this is the pioneering work in the field to facilitate the assessment of MWA surgery performance on pulmonary tumors. Extensive experiments involving 35 clinical cases further validate the efficacy of the respiratory subtraction method. The experimental results confirm the effectiveness of the respiratory subtraction method and the proposed quantitative evaluation metric in assessing lung tumor treatment.
LoMAE: Low-level Vision Masked Autoencoders for Low-dose CT Denoising
Oct 19, 2023



Low-dose computed tomography (LDCT) offers reduced X-ray radiation exposure but at the cost of compromised image quality, characterized by increased noise and artifacts. Recently, transformer models emerged as a promising avenue to enhance LDCT image quality. However, the success of such models relies on a large amount of paired noisy and clean images, which are often scarce in clinical settings. In the fields of computer vision and natural language processing, masked autoencoders (MAE) have been recognized as an effective label-free self-pretraining method for transformers, due to their exceptional feature representation ability. However, the original pretraining and fine-tuning design fails to work in low-level vision tasks like denoising. In response to this challenge, we redesign the classical encoder-decoder learning model and facilitate a simple yet effective low-level vision MAE, referred to as LoMAE, tailored to address the LDCT denoising problem. Moreover, we introduce an MAE-GradCAM method to shed light on the latent learning mechanisms of the MAE/LoMAE. Additionally, we explore the LoMAE's robustness and generability across a variety of noise levels. Experiments results show that the proposed LoMAE can enhance the transformer's denoising performance and greatly relieve the dependence on the ground truth clean data. It also demonstrates remarkable robustness and generalizability over a spectrum of noise levels.
PDS-MAR: a fine-grained Projection-Domain Segmentation-based Metal Artifact Reduction method for intraoperative CBCT images with guidewires
Jun 21, 2023Since the invention of modern CT systems, metal artifacts have been a persistent problem. Due to increased scattering, amplified noise, and insufficient data collection, it is more difficult to suppress metal artifacts in cone-beam CT, limiting its use in human- and robot-assisted spine surgeries where metallic guidewires and screws are commonly used. In this paper, we demonstrate that conventional image-domain segmentation-based MAR methods are unable to eliminate metal artifacts for intraoperative CBCT images with guidewires. To solve this problem, we present a fine-grained projection-domain segmentation-based MAR method termed PDS-MAR, in which metal traces are augmented and segmented in the projection domain before being inpainted using triangular interpolation. In addition, a metal reconstruction phase is proposed to restore metal areas in the image domain. The digital phantom study and real CBCT data study demonstrate that the proposed algorithm achieves significantly better artifact suppression than other comparing methods and has the potential to advance the use of intraoperative CBCT imaging in clinical spine surgeries.
CTformer: Convolution-free Token2Token Dilated Vision Transformer for Low-dose CT Denoising
Feb 28, 2022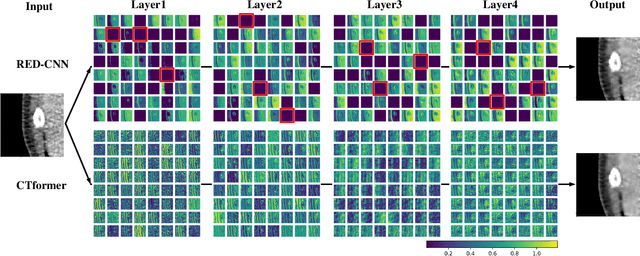

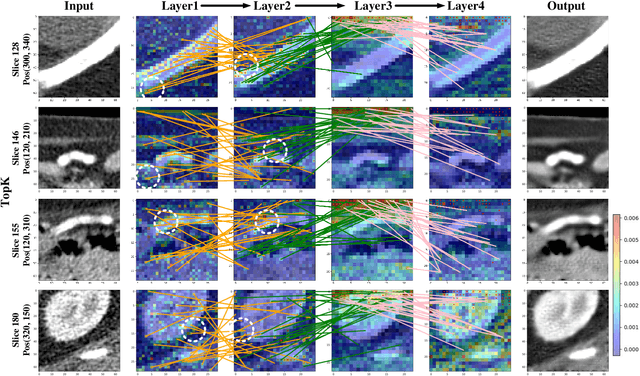
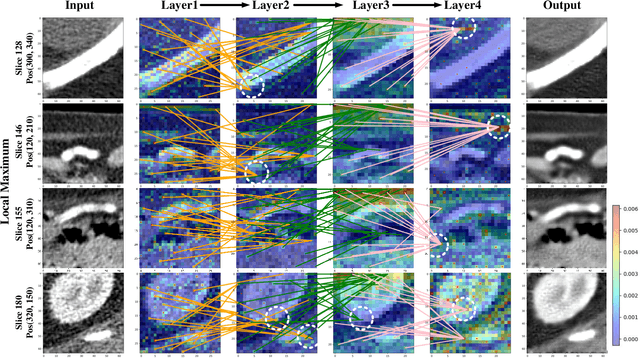
Low-dose computed tomography (LDCT) denoising is an important problem in CT research. Compared to the normal dose CT (NDCT), LDCT images are subjected to severe noise and artifacts. Recently in many studies, vision transformers have shown superior feature representation ability over convolutional neural networks (CNNs). However, unlike CNNs, the potential of vision transformers in LDCT denoising was little explored so far. To fill this gap, we propose a Convolution-free Token2Token Dilated Vision Transformer for low-dose CT denoising. The CTformer uses a more powerful token rearrangement to encompass local contextual information and thus avoids convolution. It also dilates and shifts feature maps to capture longer-range interaction. We interpret the CTformer by statically inspecting patterns of its internal attention maps and dynamically tracing the hierarchical attention flow with an explanatory graph. Furthermore, an overlapped inference mechanism is introduced to effectively eliminate the boundary artifacts that are common for encoder-decoder-based denoising models. Experimental results on Mayo LDCT dataset suggest that the CTformer outperforms the state-of-the-art denoising methods with a low computation overhead.
TED-net: Convolution-free T2T Vision Transformer-based Encoder-decoder Dilation network for Low-dose CT Denoising
Jun 08, 2021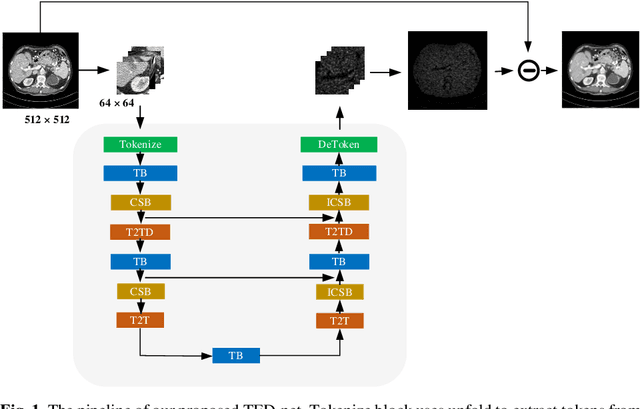
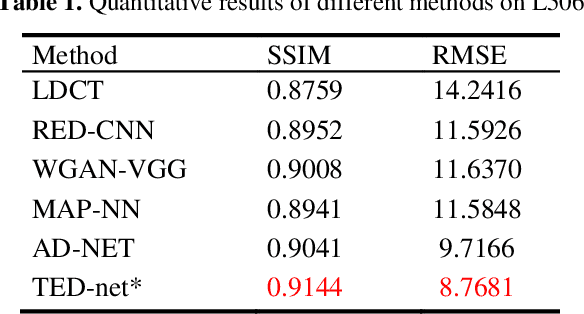
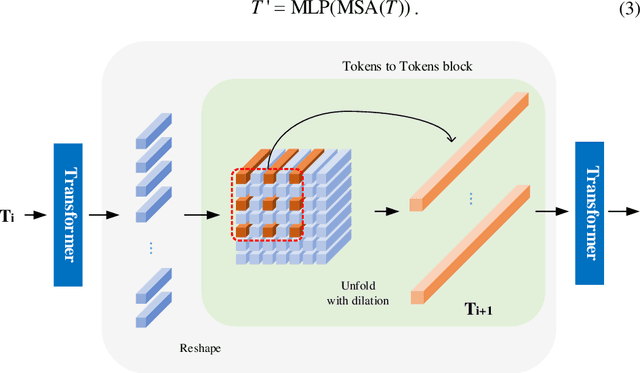
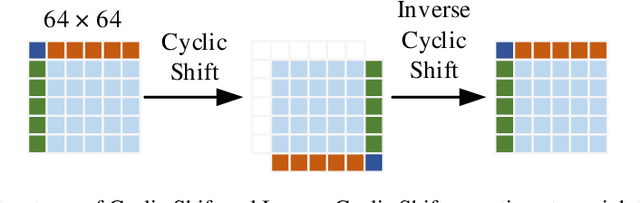
Low dose computed tomography is a mainstream for clinical applications. How-ever, compared to normal dose CT, in the low dose CT (LDCT) images, there are stronger noise and more artifacts which are obstacles for practical applications. In the last few years, convolution-based end-to-end deep learning methods have been widely used for LDCT image denoising. Recently, transformer has shown superior performance over convolution with more feature interactions. Yet its ap-plications in LDCT denoising have not been fully cultivated. Here, we propose a convolution-free T2T vision transformer-based Encoder-decoder Dilation net-work (TED-net) to enrich the family of LDCT denoising algorithms. The model is free of convolution blocks and consists of a symmetric encoder-decoder block with sole transformer. Our model is evaluated on the AAPM-Mayo clinic LDCT Grand Challenge dataset, and results show outperformance over the state-of-the-art denoising methods.