 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging the Gap: Cross-Lingual Summarization with Compression Rate
Oct 15, 2021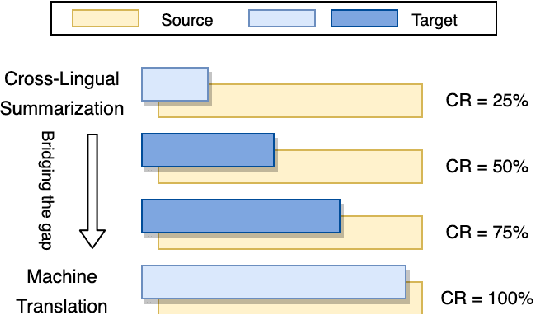
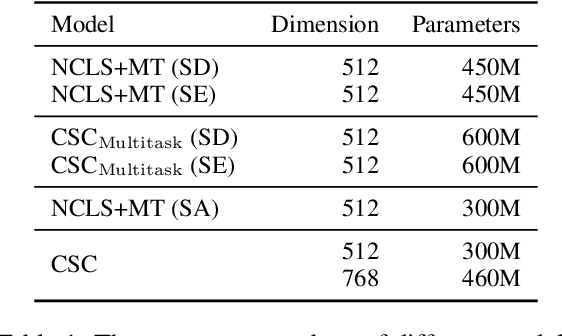
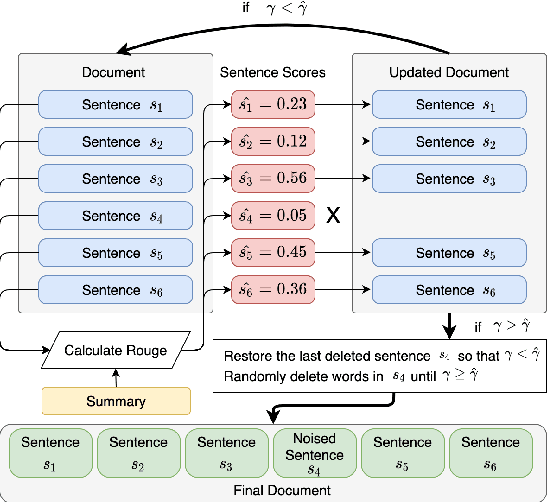
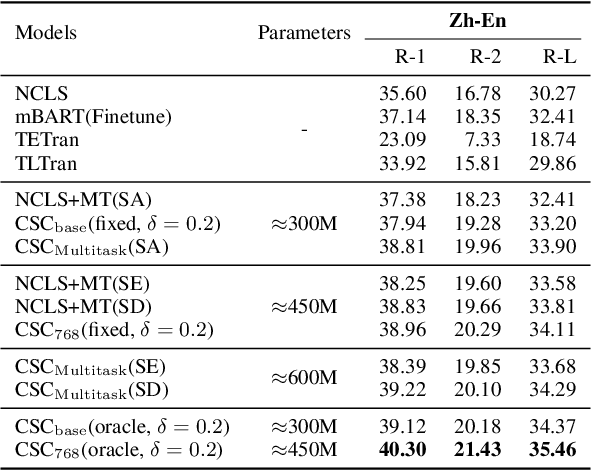
Cross-lingual Summarization (CLS), converting a document into a cross-lingual summary, is highly related to Machine Translation (MT) task. However, MT resources are still underutilized for the CLS task. In this paper, we propose a novel task, Cross-lingual Summarization with Compression rate (CSC), to benefit cross-lingual summarization through large-scale MT corpus. Through introducing compression rate, we regard MT task as a special CLS task with the compression rate of 100%. Hence they can be trained as a unified task, sharing knowledge more effectively. Moreover, to bridge these two tasks smoothly, we propose a simple yet effective data augmentation method to produce document-summary pairs with different compression rates. The proposed method not only improves the performance of CLS task, but also provides controllability to generate summaries in desired lengths. Experiments demonstrate that our method outperforms various strong baselines.
Cross-Lingual Language Model Meta-Pretraining
Sep 23, 2021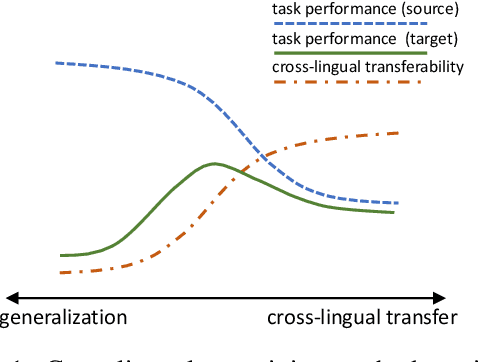
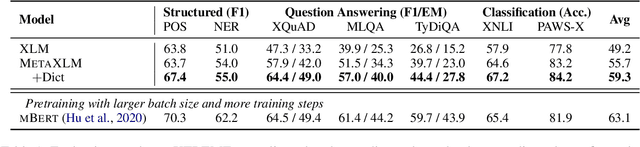
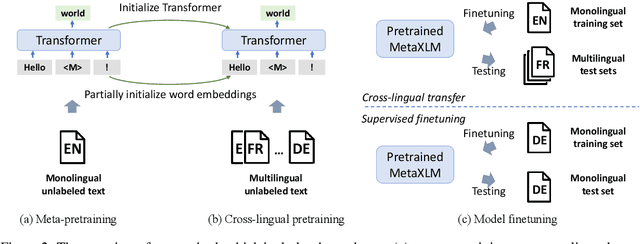

The success of pretrained cross-lingual language models relies on two essential abilities, i.e., generalization ability for learning downstream tasks in a source language, and cross-lingual transferability for transferring the task knowledge to other languages. However, current methods jointly learn the two abilities in a single-phase cross-lingual pretraining process, resulting in a trade-off between generalization and cross-lingual transfer. In this paper, we propose cross-lingual language model meta-pretraining, which learns the two abilities in different training phases. Our method introduces an additional meta-pretraining phase before cross-lingual pretraining, where the model learns generalization ability on a large-scale monolingual corpus. Then, the model focuses on learning cross-lingual transfer on a multilingual corpus. Experimental results show that our method improves both generalization and cross-lingual transfer, and produces better-aligned representations across different languages.
XLM-E: Cross-lingual Language Model Pre-training via ELECTRA
Jun 30, 2021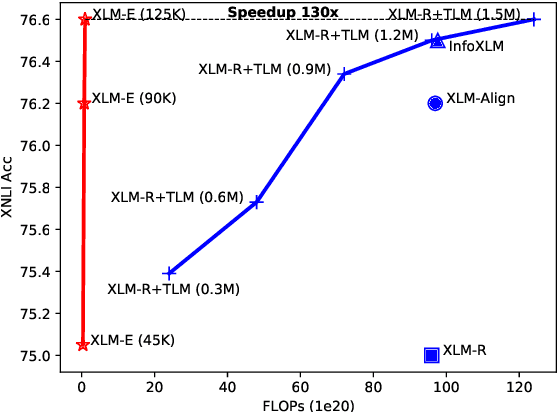
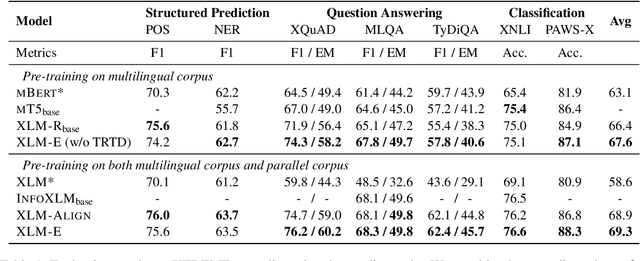
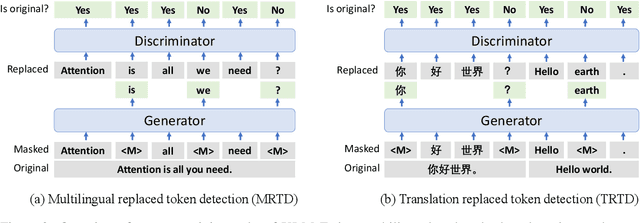
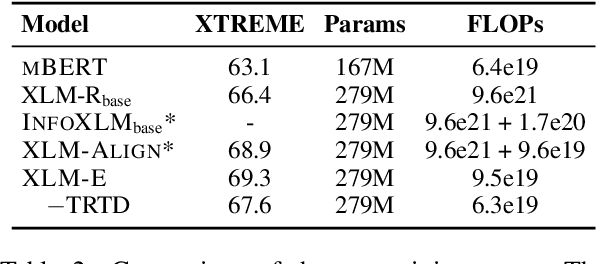
In this paper, we introduce ELECTRA-style tasks to cross-lingual language model pre-training. Specifically, we present two pre-training tasks, namely multilingual replaced token detection, and translation replaced token detection. Besides, we pretrain the model, named as XLM-E, on both multilingual and parallel corpora. Our model outperforms the baseline models on various cross-lingual understanding tasks with much less computation cost. Moreover, analysis shows that XLM-E tends to obtain better cross-lingual transferability.
Consistency Regularization for Cross-Lingual Fine-Tuning
Jun 15, 2021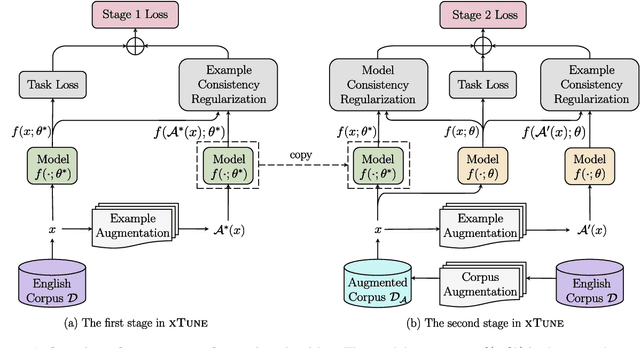
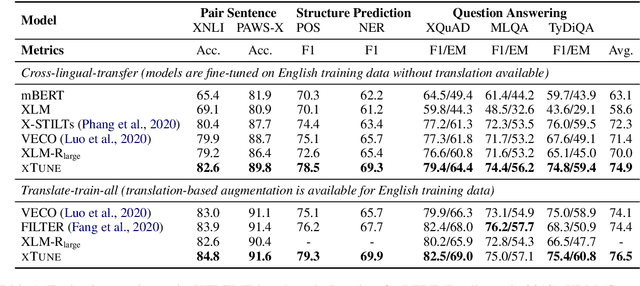
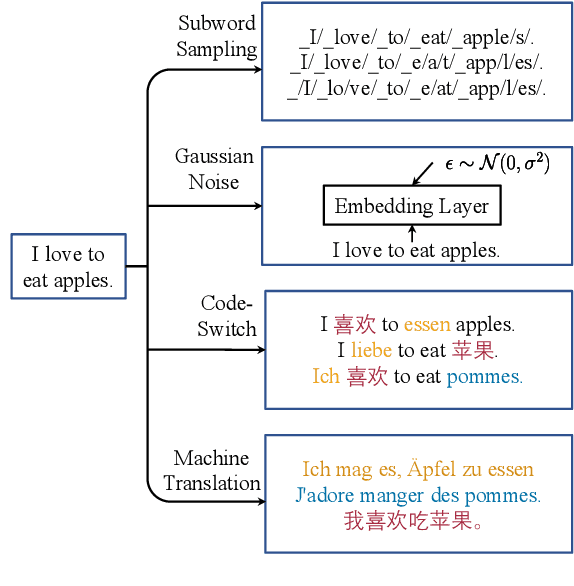
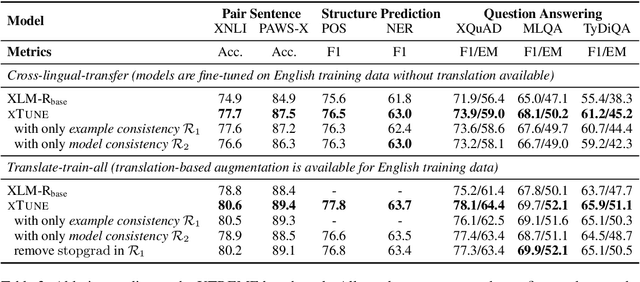
Fine-tuning pre-trained cross-lingual language models can transfer task-specific supervision from one language to the others. In this work, we propose to improve cross-lingual fine-tuning with consistency regularization. Specifically, we use example consistency regularization to penalize the prediction sensitivity to four types of data augmentations, i.e., subword sampling, Gaussian noise, code-switch substitution, and machine translation. In addition, we employ model consistency to regularize the models trained with two augmented versions of the same training set. Experimental results on the XTREME benchmark show that our method significantly improves cross-lingual fine-tuning across various tasks, including text classification, question answering, and sequence labeling.
Improving Pretrained Cross-Lingual Language Models via Self-Labeled Word Alignment
Jun 11, 2021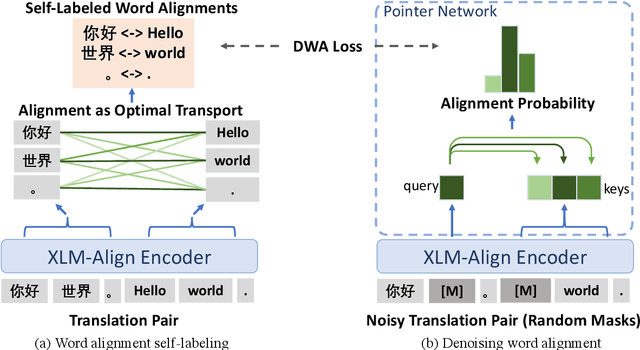
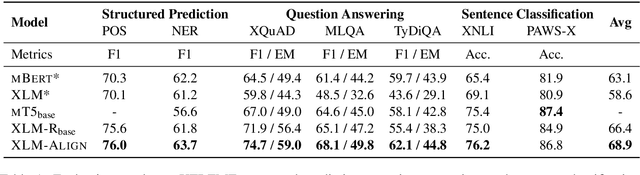
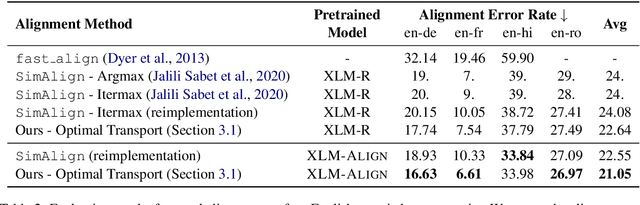
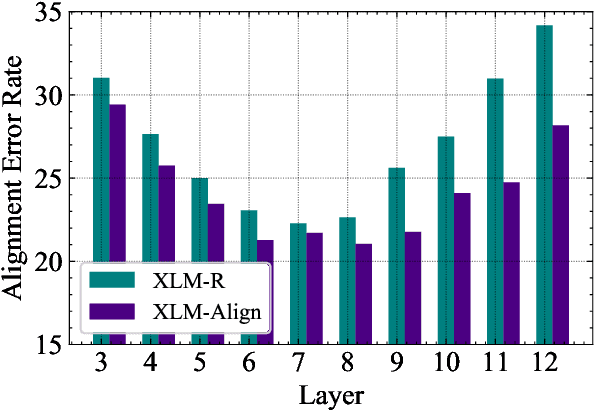
The cross-lingual language models are typically pretrained with masked language modeling on multilingual text or parallel sentences. In this paper, we introduce denoising word alignment as a new cross-lingual pre-training task. Specifically, the model first self-labels word alignments for parallel sentences. Then we randomly mask tokens in a bitext pair. Given a masked token, the model uses a pointer network to predict the aligned token in the other language. We alternately perform the above two steps in an expectation-maximization manner. Experimental results show that our method improves cross-lingual transferability on various datasets, especially on the token-level tasks, such as question answering, and structured prediction. Moreover, the model can serve as a pretrained word aligner, which achieves reasonably low error rates on the alignment benchmarks. The code and pretrained parameters are available at https://github.com/CZWin32768/XLM-Align.
mT6: Multilingual Pretrained Text-to-Text Transformer with Translation Pairs
Apr 18, 2021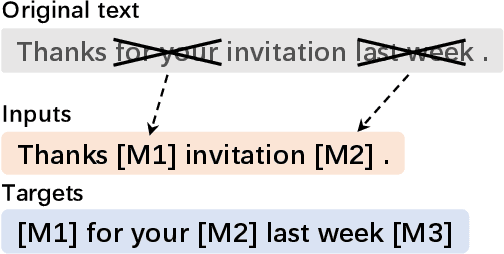
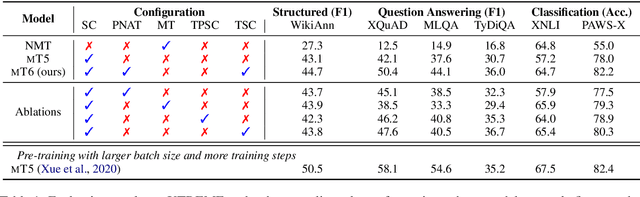
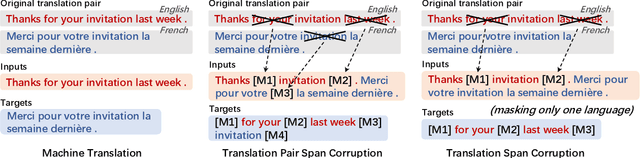
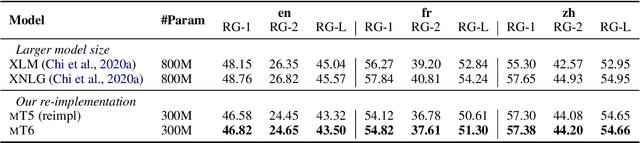
Multilingual T5 (mT5) pretrains a sequence-to-sequence model on massive monolingual texts, which has shown promising results on many cross-lingual tasks. In this paper, we improve multilingual text-to-text transfer Transformer with translation pairs (mT6). Specifically, we explore three cross-lingual text-to-text pre-training tasks, namely, machine translation, translation pair span corruption, and translation span corruption. In addition, we propose a partially non-autoregressive objective for text-to-text pre-training. We evaluate the methods on seven multilingual benchmark datasets, including sentence classification, named entity recognition, question answering, and abstractive summarization. Experimental results show that the proposed mT6 improves cross-lingual transferability over mT5.
A Robust and Domain-Adaptive Approach for Low-Resource Named Entity Recognition
Jan 02, 2021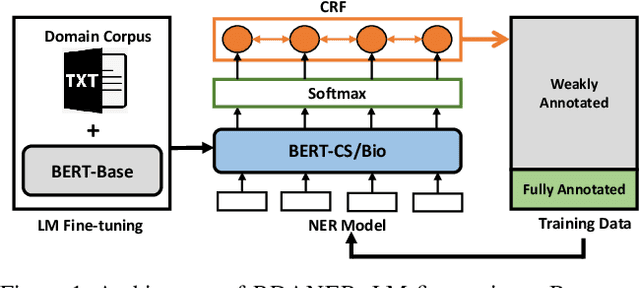
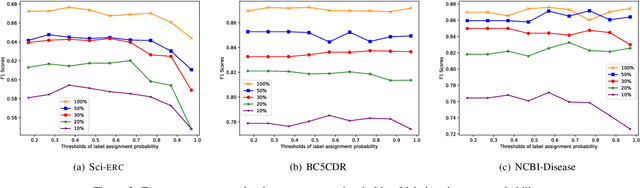

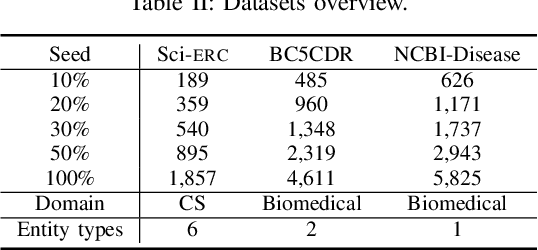
Recently, it has attracted much attention to build reliable named entity recognition (NER) systems using limited annotated data. Nearly all existing works heavily rely on domain-specific resources, such as external lexicons and knowledge bases. However, such domain-specific resources are often not available, meanwhile it's difficult and expensive to construct the resources, which has become a key obstacle to wider adoption. To tackle the problem, in this work, we propose a novel robust and domain-adaptive approach RDANER for low-resource NER, which only uses cheap and easily obtainable resources. Extensive experiments on three benchmark datasets demonstrate that our approach achieves the best performance when only using cheap and easily obtainable resources, and delivers competitive results against state-of-the-art methods which use difficultly obtainable domainspecific resources. All our code and corpora can be found on https://github.com/houking-can/RDANER.
* Best Student Paper of 2020 IEEE International Conference on Knowledge Graph (ICKG)
XLM-T: Scaling up Multilingual Machine Translation with Pretrained Cross-lingual Transformer Encoders
Dec 31, 2020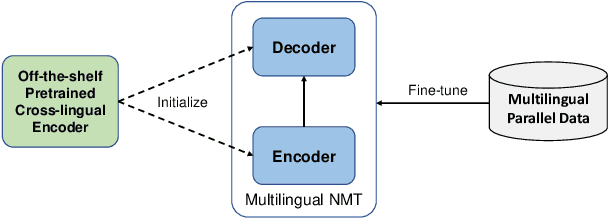
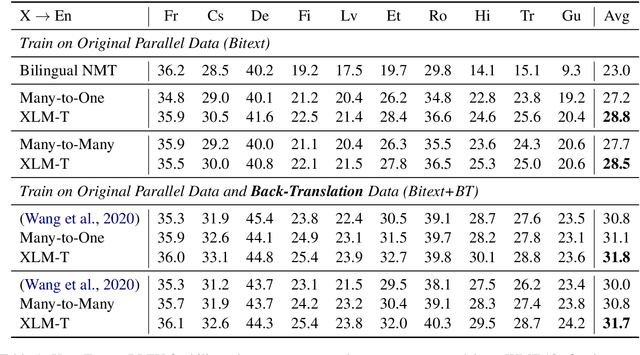
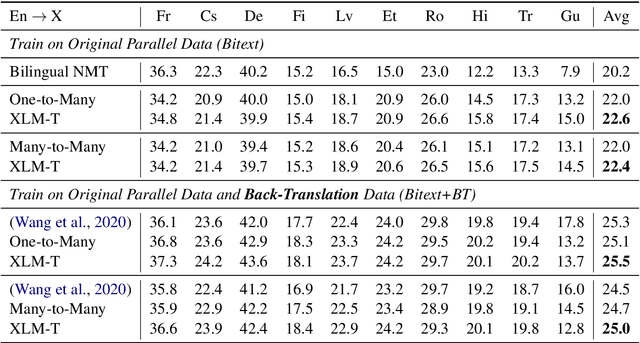

Multilingual machine translation enables a single model to translate between different languages. Most existing multilingual machine translation systems adopt a randomly initialized Transformer backbone. In this work, inspired by the recent success of language model pre-training, we present XLM-T, which initializes the model with an off-the-shelf pretrained cross-lingual Transformer encoder and fine-tunes it with multilingual parallel data. This simple method achieves significant improvements on a WMT dataset with 10 language pairs and the OPUS-100 corpus with 94 pairs. Surprisingly, the method is also effective even upon the strong baseline with back-translation. Moreover, extensive analysis of XLM-T on unsupervised syntactic parsing, word alignment, and multilingual classification explains its effectiveness for machine translation. The code will be at https://aka.ms/xlm-t.
InfoXLM: An Information-Theoretic Framework for Cross-Lingual Language Model Pre-Training
Jul 15, 2020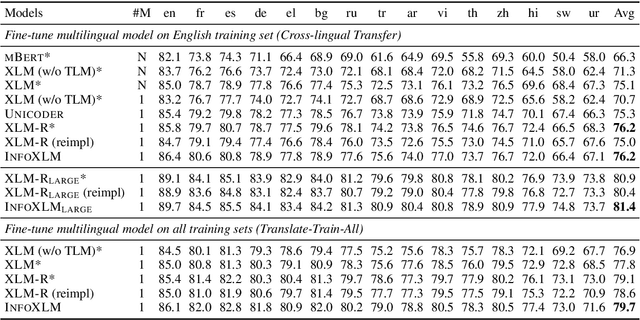
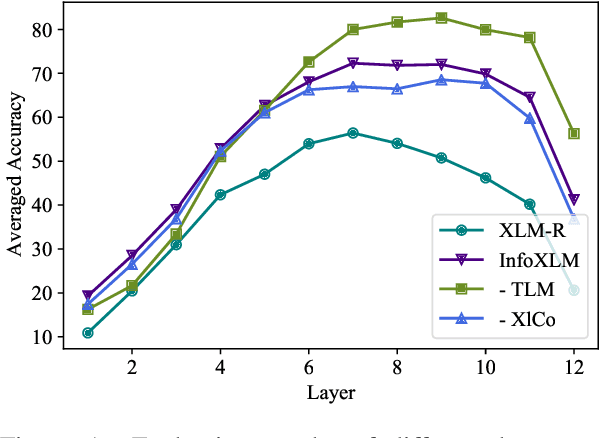
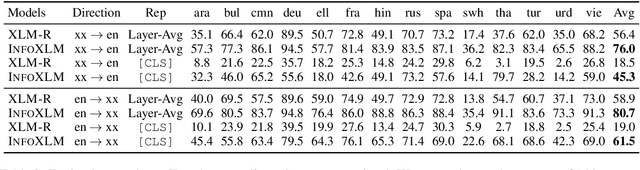
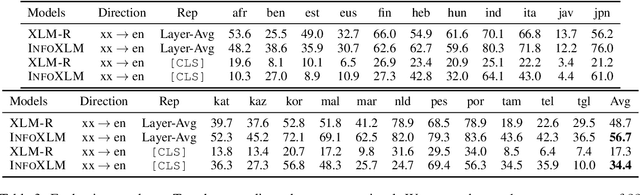
In this work, we formulate cross-lingual language model pre-training as maximizing mutual information between multilingual-multi-granularity texts. The unified view helps us to better understand the existing methods for learning cross-lingual representations. More importantly, the information-theoretic framework inspires us to propose a pre-training task based on contrastive learning. Given a bilingual sentence pair, we regard them as two views of the same meaning, and encourage their encoded representations to be more similar than the negative examples. By leveraging both monolingual and parallel corpora, we jointly train the pretext tasks to improve the cross-lingual transferability of pre-trained models. Experimental results on several benchmarks show that our approach achieves considerably better performance. The code and pre-trained models are available at http://aka.ms/infoxlm.
Generating Informative Dialogue Responses with Keywords-Guided Networks
Jul 03, 2020



Recently, open-domain dialogue systems have attracted growing attention. Most of them use the sequence-to-sequence (Seq2Seq) architecture to generate responses. However, traditional Seq2Seq-based open-domain dialogue models tend to generate generic and safe responses, which are less informative, unlike human responses. In this paper, we propose a simple but effective keywords-guided Sequence-to-Sequence model (KW-Seq2Seq) which uses keywords information as guidance to generate open-domain dialogue responses. Specifically, KW-Seq2Seq first uses a keywords decoder to predict some topic keywords, and then generates the final response under the guidance of them. Extensive experiments demonstrate that the KW-Seq2Seq model produces more informative, coherent and fluent responses, yielding substantive gain in both automatic and human evaluation metrics.