 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhased DMD: Few-step Distribution Matching Distillation via Score Matching within Subintervals
Oct 31, 2025



Distribution Matching Distillation (DMD) distills score-based generative models into efficient one-step generators, without requiring a one-to-one correspondence with the sampling trajectories of their teachers. However, limited model capacity causes one-step distilled models underperform on complex generative tasks, e.g., synthesizing intricate object motions in text-to-video generation. Directly extending DMD to multi-step distillation increases memory usage and computational depth, leading to instability and reduced efficiency. While prior works propose stochastic gradient truncation as a potential solution, we observe that it substantially reduces the generation diversity of multi-step distilled models, bringing it down to the level of their one-step counterparts. To address these limitations, we propose Phased DMD, a multi-step distillation framework that bridges the idea of phase-wise distillation with Mixture-of-Experts (MoE), reducing learning difficulty while enhancing model capacity. Phased DMD is built upon two key ideas: progressive distribution matching and score matching within subintervals. First, our model divides the SNR range into subintervals, progressively refining the model to higher SNR levels, to better capture complex distributions. Next, to ensure the training objective within each subinterval is accurate, we have conducted rigorous mathematical derivations. We validate Phased DMD by distilling state-of-the-art image and video generation models, including Qwen-Image (20B parameters) and Wan2.2 (28B parameters). Experimental results demonstrate that Phased DMD preserves output diversity better than DMD while retaining key generative capabilities. We will release our code and models.
SCULPTOR: Skeleton-Consistent Face Creation Using a Learned Parametric Generator
Sep 14, 2022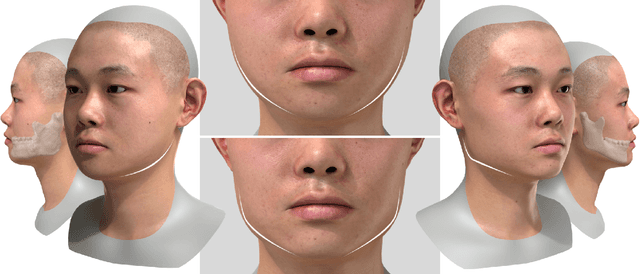
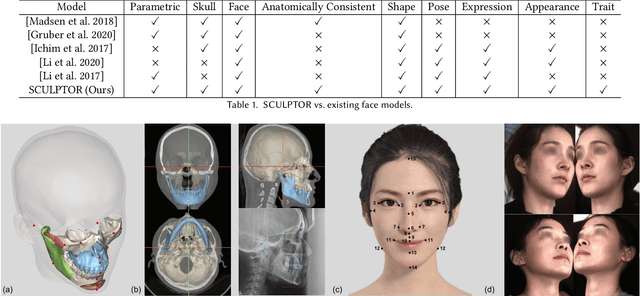
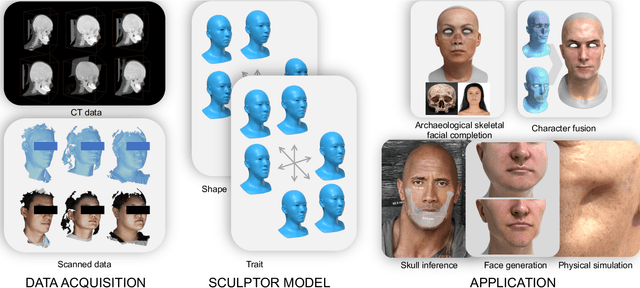
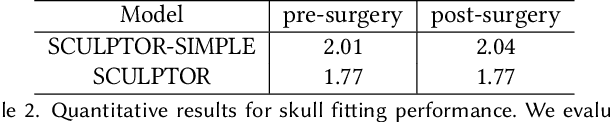
Recent years have seen growing interest in 3D human faces modelling due to its wide applications in digital human, character generation and animation. Existing approaches overwhelmingly emphasized on modeling the exterior shapes, textures and skin properties of faces, ignoring the inherent correlation between inner skeletal structures and appearance. In this paper, we present SCULPTOR, 3D face creations with Skeleton Consistency Using a Learned Parametric facial generaTOR, aiming to facilitate easy creation of both anatomically correct and visually convincing face models via a hybrid parametric-physical representation. At the core of SCULPTOR is LUCY, the first large-scale shape-skeleton face dataset in collaboration with plastic surgeons. Named after the fossils of one of the oldest known human ancestors, our LUCY dataset contains high-quality Computed Tomography (CT) scans of the complete human head before and after orthognathic surgeries, critical for evaluating surgery results. LUCY consists of 144 scans of 72 subjects (31 male and 41 female) where each subject has two CT scans taken pre- and post-orthognathic operations. Based on our LUCY dataset, we learn a novel skeleton consistent parametric facial generator, SCULPTOR, which can create the unique and nuanced facial features that help define a character and at the same time maintain physiological soundness. Our SCULPTOR jointly models the skull, face geometry and face appearance under a unified data-driven framework, by separating the depiction of a 3D face into shape blend shape, pose blend shape and facial expression blend shape. SCULPTOR preserves both anatomic correctness and visual realism in facial generation tasks compared with existing methods. Finally, we showcase the robustness and effectiveness of SCULPTOR in various fancy applications unseen before.
NIMBLE: A Non-rigid Hand Model with Bones and Muscles
Feb 09, 2022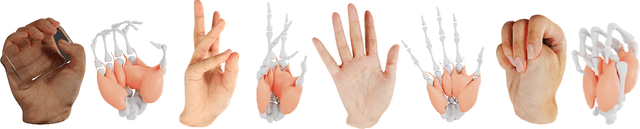
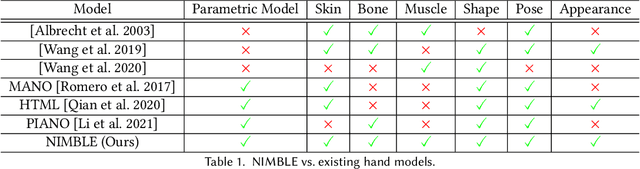

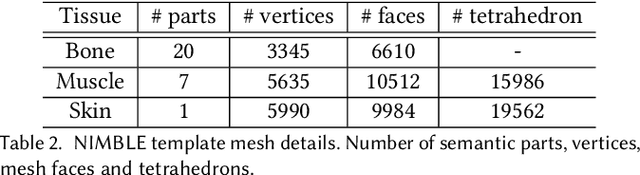
Emerging Metaverse applications demand reliable, accurate, and photorealistic reproductions of human hands to perform sophisticated operations as if in the physical world. While real human hand represents one of the most intricate coordination between bones, muscle, tendon, and skin, state-of-the-art techniques unanimously focus on modeling only the skeleton of the hand. In this paper, we present NIMBLE, a novel parametric hand model that includes the missing key components, bringing 3D hand model to a new level of realism. We first annotate muscles, bones and skins on the recent Magnetic Resonance Imaging hand (MRI-Hand) dataset and then register a volumetric template hand onto individual poses and subjects within the dataset. NIMBLE consists of 20 bones as triangular meshes, 7 muscle groups as tetrahedral meshes, and a skin mesh. Via iterative shape registration and parameter learning, it further produces shape blend shapes, pose blend shapes, and a joint regressor. We demonstrate applying NIMBLE to modeling, rendering, and visual inference tasks. By enforcing the inner bones and muscles to match anatomic and kinematic rules, NIMBLE can animate 3D hands to new poses at unprecedented realism. To model the appearance of skin, we further construct a photometric HandStage to acquire high-quality textures and normal maps to model wrinkles and palm print. Finally, NIMBLE also benefits learning-based hand pose and shape estimation by either synthesizing rich data or acting directly as a differentiable layer in the inference network.