 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Generalist Intelligence in Dentistry: Vision Foundation Models for Oral and Maxillofacial Radiology
Oct 16, 2025Oral and maxillofacial radiology plays a vital role in dental healthcare, but radiographic image interpretation is limited by a shortage of trained professionals. While AI approaches have shown promise, existing dental AI systems are restricted by their single-modality focus, task-specific design, and reliance on costly labeled data, hindering their generalization across diverse clinical scenarios. To address these challenges, we introduce DentVFM, the first family of vision foundation models (VFMs) designed for dentistry. DentVFM generates task-agnostic visual representations for a wide range of dental applications and uses self-supervised learning on DentVista, a large curated dental imaging dataset with approximately 1.6 million multi-modal radiographic images from various medical centers. DentVFM includes 2D and 3D variants based on the Vision Transformer (ViT) architecture. To address gaps in dental intelligence assessment and benchmarks, we introduce DentBench, a comprehensive benchmark covering eight dental subspecialties, more diseases, imaging modalities, and a wide geographical distribution. DentVFM shows impressive generalist intelligence, demonstrating robust generalization to diverse dental tasks, such as disease diagnosis, treatment analysis, biomarker identification, and anatomical landmark detection and segmentation. Experimental results indicate DentVFM significantly outperforms supervised, self-supervised, and weakly supervised baselines, offering superior generalization, label efficiency, and scalability. Additionally, DentVFM enables cross-modality diagnostics, providing more reliable results than experienced dentists in situations where conventional imaging is unavailable. DentVFM sets a new paradigm for dental AI, offering a scalable, adaptable, and label-efficient model to improve intelligent dental healthcare and address critical gaps in global oral healthcare.
Unsupervised Density Neural Representation for CT Metal Artifact Reduction
May 11, 2024



Emerging unsupervised reconstruction techniques based on implicit neural representation (INR), such as NeRP, CoIL, and SCOPE, have shown unique capabilities in CT linear inverse imaging. In this work, we propose a novel unsupervised density neural representation (Diner) to tackle the challenging problem of CT metal artifacts when scanned objects contain metals. The drastic variation of linear attenuation coefficients (LACs) of metals over X-ray spectra leads to a nonlinear beam hardening effect (BHE) in CT measurements. Recovering CT images from metal-affected measurements therefore poses a complicated nonlinear inverse problem. Existing metal artifact reduction (MAR) techniques mostly formulate the MAR as an image inpainting task, which ignores the energy-induced BHE and produces suboptimal performance. Instead, our Diner introduces an energy-dependent polychromatic CT forward model to the INR framework, addressing the nonlinear nature of the MAR problem. Specifically, we decompose the energy-dependent LACs into energy-independent densities and energy-dependent mass attenuation coefficients (MACs) by fully considering the physical model of X-ray absorption. Using the densities as pivot variables and the MACs as known prior knowledge, the LACs can be accurately reconstructed from the raw measurements. Technically, we represent the unknown density map as an implicit function of coordinates. Combined with a novel differentiable forward model simulating the physical acquisition from the densities to the measurements, our Diner optimizes a multi-layer perception network to approximate the implicit function by minimizing predicted errors between the estimated and real measurements. Experimental results on simulated and real datasets confirm the superiority of our unsupervised Diner against popular supervised techniques in MAR performance and robustness.
SCULPTOR: Skeleton-Consistent Face Creation Using a Learned Parametric Generator
Sep 14, 2022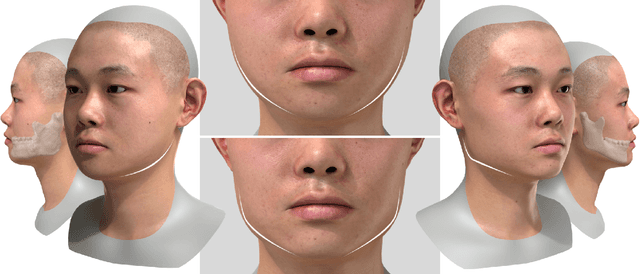
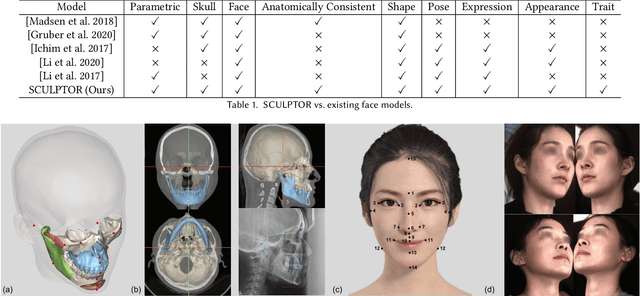
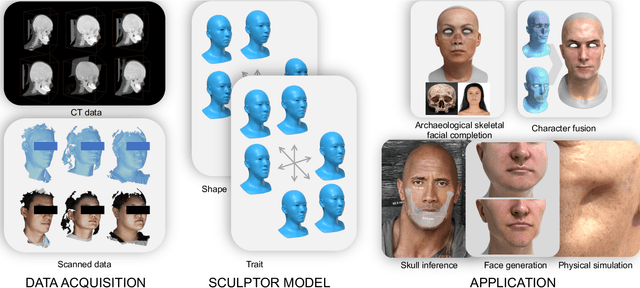
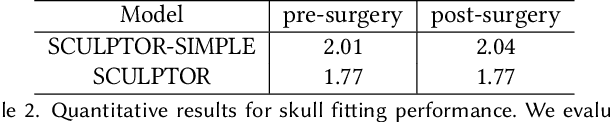
Recent years have seen growing interest in 3D human faces modelling due to its wide applications in digital human, character generation and animation. Existing approaches overwhelmingly emphasized on modeling the exterior shapes, textures and skin properties of faces, ignoring the inherent correlation between inner skeletal structures and appearance. In this paper, we present SCULPTOR, 3D face creations with Skeleton Consistency Using a Learned Parametric facial generaTOR, aiming to facilitate easy creation of both anatomically correct and visually convincing face models via a hybrid parametric-physical representation. At the core of SCULPTOR is LUCY, the first large-scale shape-skeleton face dataset in collaboration with plastic surgeons. Named after the fossils of one of the oldest known human ancestors, our LUCY dataset contains high-quality Computed Tomography (CT) scans of the complete human head before and after orthognathic surgeries, critical for evaluating surgery results. LUCY consists of 144 scans of 72 subjects (31 male and 41 female) where each subject has two CT scans taken pre- and post-orthognathic operations. Based on our LUCY dataset, we learn a novel skeleton consistent parametric facial generator, SCULPTOR, which can create the unique and nuanced facial features that help define a character and at the same time maintain physiological soundness. Our SCULPTOR jointly models the skull, face geometry and face appearance under a unified data-driven framework, by separating the depiction of a 3D face into shape blend shape, pose blend shape and facial expression blend shape. SCULPTOR preserves both anatomic correctness and visual realism in facial generation tasks compared with existing methods. Finally, we showcase the robustness and effectiveness of SCULPTOR in various fancy applications unseen before.