 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEarthSpatialBench: Benchmarking Spatial Reasoning Capabilities of Multimodal LLMs on Earth Imagery
Feb 17, 2026Benchmarking spatial reasoning in multimodal large language models (MLLMs) has attracted growing interest in computer vision due to its importance for embodied AI and other agentic systems that require precise interaction with the physical world. However, spatial reasoning on Earth imagery has lagged behind, as it uniquely involves grounding objects in georeferenced images and quantitatively reasoning about distances, directions, and topological relations using both visual cues and vector geometry coordinates (e.g., 2D bounding boxes, polylines, and polygons). Existing benchmarks for Earth imagery primarily focus on 2D spatial grounding, image captioning, and coarse spatial relations (e.g., simple directional or proximity cues). They lack support for quantitative direction and distance reasoning, systematic topological relations, and complex object geometries beyond bounding boxes. To fill this gap, we propose \textbf{EarthSpatialBench}, a comprehensive benchmark for evaluating spatial reasoning in MLLMs on Earth imagery. The benchmark contains over 325K question-answer pairs spanning: (1) qualitative and quantitative reasoning about spatial distance and direction; (2) systematic topological relations; (3) single-object queries, object-pair queries, and compositional aggregate group queries; and (4) object references expressed via textual descriptions, visual overlays, and explicit geometry coordinates, including 2D bounding boxes, polylines, and polygons. We conducted extensive experiments on both open-source and proprietary models to identify limitations in the spatial reasoning of MLLMs.
ResWorld: Temporal Residual World Model for End-to-End Autonomous Driving
Feb 11, 2026The comprehensive understanding capabilities of world models for driving scenarios have significantly improved the planning accuracy of end-to-end autonomous driving frameworks. However, the redundant modeling of static regions and the lack of deep interaction with trajectories hinder world models from exerting their full effectiveness. In this paper, we propose Temporal Residual World Model (TR-World), which focuses on dynamic object modeling. By calculating the temporal residuals of scene representations, the information of dynamic objects can be extracted without relying on detection and tracking. TR-World takes only temporal residuals as input, thus predicting the future spatial distribution of dynamic objects more precisely. By combining the prediction with the static object information contained in the current BEV features, accurate future BEV features can be obtained. Furthermore, we propose Future-Guided Trajectory Refinement (FGTR) module, which conducts interaction between prior trajectories (predicted from the current scene representation) and the future BEV features. This module can not only utilize future road conditions to refine trajectories, but also provides sparse spatial-temporal supervision on future BEV features to prevent world model collapse. Comprehensive experiments conducted on the nuScenes and NAVSIM datasets demonstrate that our method, namely ResWorld, achieves state-of-the-art planning performance. The code is available at https://github.com/mengtan00/ResWorld.git.
DecoyDB: A Dataset for Graph Contrastive Learning in Protein-Ligand Binding Affinity Prediction
Jul 08, 2025Predicting the binding affinity of protein-ligand complexes plays a vital role in drug discovery. Unfortunately, progress has been hindered by the lack of large-scale and high-quality binding affinity labels. The widely used PDBbind dataset has fewer than 20K labeled complexes. Self-supervised learning, especially graph contrastive learning (GCL), provides a unique opportunity to break the barrier by pre-training graph neural network models based on vast unlabeled complexes and fine-tuning the models on much fewer labeled complexes. However, the problem faces unique challenges, including a lack of a comprehensive unlabeled dataset with well-defined positive/negative complex pairs and the need to design GCL algorithms that incorporate the unique characteristics of such data. To fill the gap, we propose DecoyDB, a large-scale, structure-aware dataset specifically designed for self-supervised GCL on protein-ligand complexes. DecoyDB consists of high-resolution ground truth complexes (less than 2.5 Angstrom) and diverse decoy structures with computationally generated binding poses that range from realistic to suboptimal (negative pairs). Each decoy is annotated with a Root Mean Squared Deviation (RMSD) from the native pose. We further design a customized GCL framework to pre-train graph neural networks based on DecoyDB and fine-tune the models with labels from PDBbind. Extensive experiments confirm that models pre-trained with DecoyDB achieve superior accuracy, label efficiency, and generalizability.
A Fast AI Surrogate for Coastal Ocean Circulation Models
Oct 19, 2024



Nearly 900 million people live in low-lying coastal zones around the world and bear the brunt of impacts from more frequent and severe hurricanes and storm surges. Oceanographers simulate ocean current circulation along the coasts to develop early warning systems that save lives and prevent loss and damage to property from coastal hazards. Traditionally, such simulations are conducted using coastal ocean circulation models such as the Regional Ocean Modeling System (ROMS), which usually runs on an HPC cluster with multiple CPU cores. However, the process is time-consuming and energy expensive. While coarse-grained ROMS simulations offer faster alternatives, they sacrifice detail and accuracy, particularly in complex coastal environments. Recent advances in deep learning and GPU architecture have enabled the development of faster AI (neural network) surrogates. This paper introduces an AI surrogate based on a 4D Swin Transformer to simulate coastal tidal wave propagation in an estuary for both hindcast and forecast (up to 12 days). Our approach not only accelerates simulations but also incorporates a physics-based constraint to detect and correct inaccurate results, ensuring reliability while minimizing manual intervention. We develop a fully GPU-accelerated workflow, optimizing the model training and inference pipeline on NVIDIA DGX-2 A100 GPUs. Our experiments demonstrate that our AI surrogate reduces the time cost of 12-day forecasting of traditional ROMS simulations from 9,908 seconds (on 512 CPU cores) to 22 seconds (on one A100 GPU), achieving over 450$\times$ speedup while maintaining high-quality simulation results. This work contributes to oceanographic modeling by offering a fast, accurate, and physically consistent alternative to traditional simulation models, particularly for real-time forecasting in rapid disaster response.
Spatio-Temporal Partial Sensing Forecast for Long-term Traffic
Aug 02, 2024Traffic forecasting uses recent measurements by sensors installed at chosen locations to forecast the future road traffic. Existing work either assumes all locations are equipped with sensors or focuses on short-term forecast. This paper studies partial sensing traffic forecast of long-term traffic, assuming sensors only at some locations. The study is important in lowering the infrastructure investment cost in traffic management since deploying sensors at all locations could incur prohibitively high cost. However, the problem is challenging due to the unknown distribution at unsensed locations, the intricate spatio-temporal correlation in long-term forecasting, as well as noise in data and irregularities in traffic patterns (e.g., road closure). We propose a Spatio-Temporal Partial Sensing (STPS) forecast model for long-term traffic prediction, with several novel contributions, including a rank-based embedding technique to capture irregularities and overcome noise, a spatial transfer matrix to overcome the spatial distribution shift from permanently sensed locations to unsensed locations, and a multi-step training process that utilizes all available data to successively refine the model parameters for better accuracy. Extensive experiments on several real-world traffic datasets demonstrate that STPS outperforms the state-of-the-art and achieves superior accuracy in partial sensing long-term forecasting.
XTSFormer: Cross-Temporal-Scale Transformer for Irregular Time Event Prediction
Feb 03, 2024



Event prediction aims to forecast the time and type of a future event based on a historical event sequence. Despite its significance, several challenges exist, including the irregularity of time intervals between consecutive events, the existence of cycles, periodicity, and multi-scale event interactions, as well as the high computational costs for long event sequences. Existing neural temporal point processes (TPPs) methods do not capture the multi-scale nature of event interactions, which is common in many real-world applications such as clinical event data. To address these issues, we propose the cross-temporal-scale transformer (XTSFormer), designed specifically for irregularly timed event data. Our model comprises two vital components: a novel Feature-based Cycle-aware Time Positional Encoding (FCPE) that adeptly captures the cyclical nature of time, and a hierarchical multi-scale temporal attention mechanism. These scales are determined by a bottom-up clustering algorithm. Extensive experiments on several real-world datasets show that our XTSFormer outperforms several baseline methods in prediction performance.
Spatial Knowledge-Infused Hierarchical Learning: An Application in Flood Mapping on Earth Imagery
Dec 12, 2023



Deep learning for Earth imagery plays an increasingly important role in geoscience applications such as agriculture, ecology, and natural disaster management. Still, progress is often hindered by the limited training labels. Given Earth imagery with limited training labels, a base deep neural network model, and a spatial knowledge base with label constraints, our problem is to infer the full labels while training the neural network. The problem is challenging due to the sparse and noisy input labels, spatial uncertainty within the label inference process, and high computational costs associated with a large number of sample locations. Existing works on neuro-symbolic models focus on integrating symbolic logic into neural networks (e.g., loss function, model architecture, and training label augmentation), but these methods do not fully address the challenges of spatial data (e.g., spatial uncertainty, the trade-off between spatial granularity and computational costs). To bridge this gap, we propose a novel Spatial Knowledge-Infused Hierarchical Learning (SKI-HL) framework that iteratively infers sample labels within a multi-resolution hierarchy. Our framework consists of a module to selectively infer labels in different resolutions based on spatial uncertainty and a module to train neural network parameters with uncertainty-aware multi-instance learning. Extensive experiments on real-world flood mapping datasets show that the proposed model outperforms several baseline methods. The code is available at \url{https://github.com/ZelinXu2000/SKI-HL}.
A Hierarchical Spatial Transformer for Massive Point Samples in Continuous Space
Nov 08, 2023Transformers are widely used deep learning architectures. Existing transformers are mostly designed for sequences (texts or time series), images or videos, and graphs. This paper proposes a novel transformer model for massive (up to a million) point samples in continuous space. Such data are ubiquitous in environment sciences (e.g., sensor observations), numerical simulations (e.g., particle-laden flow, astrophysics), and location-based services (e.g., POIs and trajectories). However, designing a transformer for massive spatial points is non-trivial due to several challenges, including implicit long-range and multi-scale dependency on irregular points in continuous space, a non-uniform point distribution, the potential high computational costs of calculating all-pair attention across massive points, and the risks of over-confident predictions due to varying point density. To address these challenges, we propose a new hierarchical spatial transformer model, which includes multi-resolution representation learning within a quad-tree hierarchy and efficient spatial attention via coarse approximation. We also design an uncertainty quantification branch to estimate prediction confidence related to input feature noise and point sparsity. We provide a theoretical analysis of computational time complexity and memory costs. Extensive experiments on both real-world and synthetic datasets show that our method outperforms multiple baselines in prediction accuracy and our model can scale up to one million points on one NVIDIA A100 GPU. The code is available at \url{https://github.com/spatialdatasciencegroup/HST}.
Manifold-Aware Self-Training for Unsupervised Domain Adaptation on Regressing 6D Object Pose
May 18, 2023



Domain gap between synthetic and real data in visual regression (\eg 6D pose estimation) is bridged in this paper via global feature alignment and local refinement on the coarse classification of discretized anchor classes in target space, which imposes a piece-wise target manifold regularization into domain-invariant representation learning. Specifically, our method incorporates an explicit self-supervised manifold regularization, revealing consistent cumulative target dependency across domains, to a self-training scheme (\eg the popular Self-Paced Self-Training) to encourage more discriminative transferable representations of regression tasks. Moreover, learning unified implicit neural functions to estimate relative direction and distance of targets to their nearest class bins aims to refine target classification predictions, which can gain robust performance against inconsistent feature scaling sensitive to UDA regressors. Experiment results on three public benchmarks of the challenging 6D pose estimation task can verify the effectiveness of our method, consistently achieving superior performance to the state-of-the-art for UDA on 6D pose estimation.
BiCo-Net: Regress Globally, Match Locally for Robust 6D Pose Estimation
May 07, 2022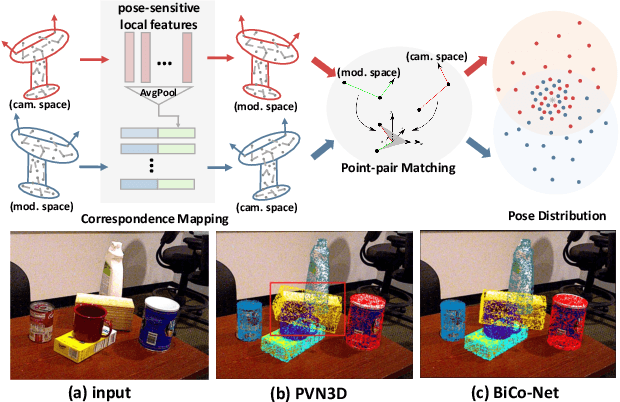
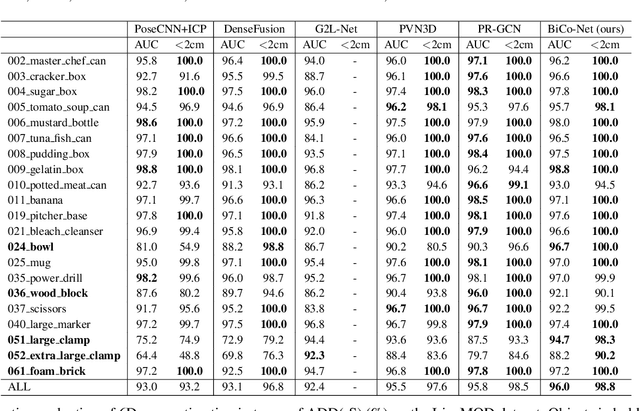
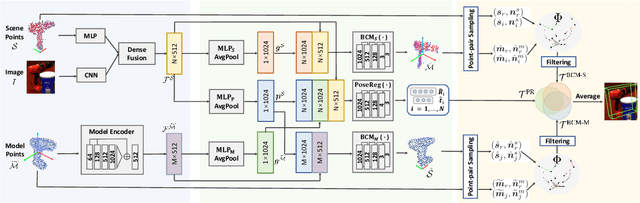

The challenges of learning a robust 6D pose function lie in 1) severe occlusion and 2) systematic noises in depth images. Inspired by the success of point-pair features, the goal of this paper is to recover the 6D pose of an object instance segmented from RGB-D images by locally matching pairs of oriented points between the model and camera space. To this end, we propose a novel Bi-directional Correspondence Mapping Network (BiCo-Net) to first generate point clouds guided by a typical pose regression, which can thus incorporate pose-sensitive information to optimize generation of local coordinates and their normal vectors. As pose predictions via geometric computation only rely on one single pair of local oriented points, our BiCo-Net can achieve robustness against sparse and occluded point clouds. An ensemble of redundant pose predictions from locally matching and direct pose regression further refines final pose output against noisy observations. Experimental results on three popularly benchmarking datasets can verify that our method can achieve state-of-the-art performance, especially for the more challenging severe occluded scenes. Source codes are available at https://github.com/Gorilla-Lab-SCUT/BiCo-Net.