 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLEAR: Unlocking Generative Potential for Degraded Image Understanding in Unified Multimodal Models
Apr 06, 2026Image degradation from blur, noise, compression, and poor illumination severely undermines multimodal understanding in real-world settings. Unified multimodal models that combine understanding and generation within a single architecture are a natural fit for this challenge, as their generative pathway can model the fine-grained visual structure that degradation destroys. Yet these models fail to leverage their own generative capacity on degraded inputs. We trace this disconnect to two compounding factors: existing training regimes never ask the model to invoke generation during reasoning, and the standard decode-reencode pathway does not support effective joint optimization. We present CLEAR, a framework that connects the two capabilities through three progressive steps: (1) supervised fine-tuning on a degradation-aware dataset to establish the generate-then-answer reasoning pattern; (2) a Latent Representation Bridge that replaces the decode-reencode detour with a direct, optimizable connection between generation and reasoning; (3) Interleaved GRPO, a reinforcement learning method that jointly optimizes text reasoning and visual generation under answer-correctness rewards. We construct MMD-Bench, covering three degradation severity levels across six standard multimodal benchmarks. Experiments show that CLEAR substantially improves robustness on degraded inputs while preserving clean-image performance. Our analysis further reveals that removing pixel-level reconstruction supervision leads to intermediate visual states with higher perceptual quality, suggesting that task-driven optimization and visual quality are naturally aligned.
Sparse Growing Transformer: Training-Time Sparse Depth Allocation via Progressive Attention Looping
Mar 25, 2026Existing approaches to increasing the effective depth of Transformers predominantly rely on parameter reuse, extending computation through recursive execution. Under this paradigm, the network structure remains static along the training timeline, and additional computational depth is uniformly assigned to entire blocks at the parameter level. This rigidity across training time and parameter space leads to substantial computational redundancy during training. In contrast, we argue that depth allocation during training should not be a static preset, but rather a progressively growing structural process. Our systematic analysis reveals a deep-to-shallow maturation trajectory across layers, where high-entropy attention heads play a crucial role in semantic integration. Motivated by this observation, we introduce the Sparse Growing Transformer (SGT). SGT is a training-time sparse depth allocation framework that progressively extends recurrence from deeper to shallower layers via targeted attention looping on informative heads. This mechanism induces structural sparsity by selectively increasing depth only for a small subset of parameters as training evolves. Extensive experiments across multiple parameter scales demonstrate that SGT consistently outperforms training-time static block-level looping baselines under comparable settings, while reducing the additional training FLOPs overhead from approximately 16--20% to only 1--3% relative to a standard Transformer backbone.
S2CDR: Smoothing-Sharpening Process Model for Cross-Domain Recommendation
Mar 03, 2026User cold-start problem is a long-standing challenge in recommendation systems. Fortunately, cross-domain recommendation (CDR) has emerged as a highly effective remedy for the user cold-start challenge, with recently developed diffusion models (DMs) demonstrating exceptional performance. However, these DMs-based CDR methods focus on dealing with user-item interactions, overlooking correlations between items across the source and target domains. Meanwhile, the Gaussian noise added in the forward process of diffusion models would hurt user's personalized preference, leading to the difficulty in transferring user preference across domains. To this end, we propose a novel paradigm of Smoothing-Sharpening Process Model for CDR to cold-start users, termed as S2CDR which features a corruption-recovery architecture and is solved with respect to ordinary differential equations (ODEs). Specifically, the smoothing process gradually corrupts the original user-item/item-item interaction matrices derived from both domains into smoothed preference signals in a noise-free manner, and the sharpening process iteratively sharpens the preference signals to recover the unknown interactions for cold-start users. Wherein, for the smoothing process, we introduce the heat equation on the item-item similarity graph to better capture the correlations between items across domains, and further build the tailor-designed low-pass filter to filter out the high-frequency noise information for capturing user's intrinsic preference, in accordance with the graph signal processing (GSP) theory. Extensive experiments on three real-world CDR scenarios confirm that our S2CDR significantly outperforms previous SOTA methods in a training-free manner.
S1-Bench: A Simple Benchmark for Evaluating System 1 Thinking Capability of Large Reasoning Models
Apr 14, 2025



We introduce S1-Bench, a novel benchmark designed to evaluate Large Reasoning Models' (LRMs) performance on simple tasks that favor intuitive system 1 thinking rather than deliberative system 2 reasoning. While LRMs have achieved significant breakthroughs in complex reasoning tasks through explicit chains of thought, their reliance on deep analytical thinking may limit their system 1 thinking capabilities. Moreover, a lack of benchmark currently exists to evaluate LRMs' performance in tasks that require such capabilities. To fill this gap, S1-Bench presents a set of simple, diverse, and naturally clear questions across multiple domains and languages, specifically designed to assess LRMs' performance in such tasks. Our comprehensive evaluation of 22 LRMs reveals significant lower efficiency tendencies, with outputs averaging 15.5 times longer than those of traditional small LLMs. Additionally, LRMs often identify correct answers early but continue unnecessary deliberation, with some models even producing numerous errors. These findings highlight the rigid reasoning patterns of current LRMs and underscore the substantial development needed to achieve balanced dual-system thinking capabilities that can adapt appropriately to task complexity.
Revealing the Challenge of Detecting Character Knowledge Errors in LLM Role-Playing
Sep 18, 2024



Large language model (LLM) role-playing has gained widespread attention, where the authentic character knowledge is crucial for constructing realistic LLM role-playing agents. However, existing works usually overlook the exploration of LLMs' ability to detect characters' known knowledge errors (KKE) and unknown knowledge errors (UKE) while playing roles, which would lead to low-quality automatic construction of character trainable corpus. In this paper, we propose a probing dataset to evaluate LLMs' ability to detect errors in KKE and UKE. The results indicate that even the latest LLMs struggle to effectively detect these two types of errors, especially when it comes to familiar knowledge. We experimented with various reasoning strategies and propose an agent-based reasoning method, Self-Recollection and Self-Doubt (S2RD), to further explore the potential for improving error detection capabilities. Experiments show that our method effectively improves the LLMs' ability to detect error character knowledge, but it remains an issue that requires ongoing attention.
Optimal Transport Guided Correlation Assignment for Multimodal Entity Linking
Jun 04, 2024



Multimodal Entity Linking (MEL) aims to link ambiguous mentions in multimodal contexts to entities in a multimodal knowledge graph. A pivotal challenge is to fully leverage multi-element correlations between mentions and entities to bridge modality gap and enable fine-grained semantic matching. Existing methods attempt several local correlative mechanisms, relying heavily on the automatically learned attention weights, which may over-concentrate on partial correlations. To mitigate this issue, we formulate the correlation assignment problem as an optimal transport (OT) problem, and propose a novel MEL framework, namely OT-MEL, with OT-guided correlation assignment. Thereby, we exploit the correlation between multimodal features to enhance multimodal fusion, and the correlation between mentions and entities to enhance fine-grained matching. To accelerate model prediction, we further leverage knowledge distillation to transfer OT assignment knowledge to attention mechanism. Experimental results show that our model significantly outperforms previous state-of-the-art baselines and confirm the effectiveness of the OT-guided correlation assignment.
Neural Contextual Conversation Learning with Labeled Question-Answering Pairs
Jul 20, 2016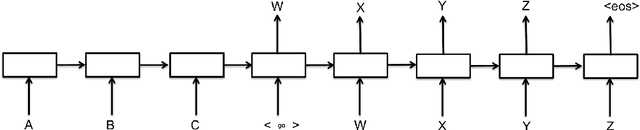


Neural conversational models tend to produce generic or safe responses in different contexts, e.g., reply \textit{"Of course"} to narrative statements or \textit{"I don't know"} to questions. In this paper, we propose an end-to-end approach to avoid such problem in neural generative models. Additional memory mechanisms have been introduced to standard sequence-to-sequence (seq2seq) models, so that context can be considered while generating sentences. Three seq2seq models, which memorize a fix-sized contextual vector from hidden input, hidden input/output and a gated contextual attention structure respectively, have been trained and tested on a dataset of labeled question-answering pairs in Chinese. The model with contextual attention outperforms others including the state-of-the-art seq2seq models on perplexity test. The novel contextual model generates diverse and robust responses, and is able to carry out conversations on a wide range of topics appropriately.