 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLEAR: Unlocking Generative Potential for Degraded Image Understanding in Unified Multimodal Models
Apr 06, 2026Image degradation from blur, noise, compression, and poor illumination severely undermines multimodal understanding in real-world settings. Unified multimodal models that combine understanding and generation within a single architecture are a natural fit for this challenge, as their generative pathway can model the fine-grained visual structure that degradation destroys. Yet these models fail to leverage their own generative capacity on degraded inputs. We trace this disconnect to two compounding factors: existing training regimes never ask the model to invoke generation during reasoning, and the standard decode-reencode pathway does not support effective joint optimization. We present CLEAR, a framework that connects the two capabilities through three progressive steps: (1) supervised fine-tuning on a degradation-aware dataset to establish the generate-then-answer reasoning pattern; (2) a Latent Representation Bridge that replaces the decode-reencode detour with a direct, optimizable connection between generation and reasoning; (3) Interleaved GRPO, a reinforcement learning method that jointly optimizes text reasoning and visual generation under answer-correctness rewards. We construct MMD-Bench, covering three degradation severity levels across six standard multimodal benchmarks. Experiments show that CLEAR substantially improves robustness on degraded inputs while preserving clean-image performance. Our analysis further reveals that removing pixel-level reconstruction supervision leads to intermediate visual states with higher perceptual quality, suggesting that task-driven optimization and visual quality are naturally aligned.
WirelessBench: A Tolerance-Aware LLM Agent Benchmark for Wireless Network Intelligence
Mar 22, 2026LLM agents are emerging as a key enabler for autonomous wireless network management. Reliably deploying them, however, demands benchmarks that reflect real engineering risk. Existing wireless benchmarks evaluate single isolated capabilities and treat all errors uniformly, missing both cascaded-chain failures and catastrophic unit confusions (\textit{e.g.}, dB vs.\ dBm). We present \wb{}, the first tolerance-aware, tool-integrated benchmark for LLM-based wireless agents. \wb{} is organized as a three-tier cognitive hierarchy: domain knowledge reasoning (WCHW, 1{,}392 items), intent-driven resource allocation (WCNS, 1{,}000 items), and proactive multi-step decisions under mobility (WCMSA, 1{,}000 items). Moreover, \wb{} is established on three design principles: \emph{(i)}~tolerance-aware scoring with catastrophic-error detection; \emph{(ii)}~tool-necessary tasks requiring a 3GPP-compliant ray-tracing query for channel quality; and \emph{(iii)}~Chain-of-Thought (CoT)-traceable items, where every benchmark item ships with a complete CoT trajectory enabling fine-grained diagnosis of where in the reasoning chain an agent fails. Our numerical results show that the direct-prompting model (GPT-4o) scores $68\%$, trailing a tool-integrated agent ($84.64\%$) by $16.64$\,pp; $23\%$ of errors are catastrophic failures invisible to exact-match metrics. More importantly, the hierarchy decomposes errors into four actionable diagnostic categories that flat evaluation cannot reveal. Code and data: https://wirelessbench.github.io/.
RoboPaint: From Human Demonstration to Any Robot and Any View
Feb 05, 2026Acquiring large-scale, high-fidelity robot demonstration data remains a critical bottleneck for scaling Vision-Language-Action (VLA) models in dexterous manipulation. We propose a Real-Sim-Real data collection and data editing pipeline that transforms human demonstrations into robot-executable, environment-specific training data without direct robot teleoperation. Standardized data collection rooms are built to capture multimodal human demonstrations (synchronized 3 RGB-D videos, 11 RGB videos, 29-DoF glove joint angles, and 14-channel tactile signals). Based on these human demonstrations, we introduce a tactile-aware retargeting method that maps human hand states to robot dex-hand states via geometry and force-guided optimization. Then the retargeted robot trajectories are rendered in a photorealistic Isaac Sim environment to build robot training data. Real world experiments have demonstrated: (1) The retargeted dex-hand trajectories achieve an 84\% success rate across 10 diverse object manipulation tasks. (2) VLA policies (Pi0.5) trained exclusively on our generated data achieve 80\% average success rate on three representative tasks, i.e., pick-and-place, pushing and pouring. To conclude, robot training data can be efficiently "painted" from human demonstrations using our real-sim-real data pipeline. We offer a scalable, cost-effective alternative to teleoperation with minimal performance loss for complex dexterous manipulation.
Reasoning While Asking: Transforming Reasoning Large Language Models from Passive Solvers to Proactive Inquirers
Jan 29, 2026Reasoning-oriented Large Language Models (LLMs) have achieved remarkable progress with Chain-of-Thought (CoT) prompting, yet they remain fundamentally limited by a \emph{blind self-thinking} paradigm: performing extensive internal reasoning even when critical information is missing or ambiguous. We propose Proactive Interactive Reasoning (PIR), a new reasoning paradigm that transforms LLMs from passive solvers into proactive inquirers that interleave reasoning with clarification. Unlike existing search- or tool-based frameworks that primarily address knowledge uncertainty by querying external environments, PIR targets premise- and intent-level uncertainty through direct interaction with the user. PIR is implemented via two core components: (1) an uncertainty-aware supervised fine-tuning procedure that equips models with interactive reasoning capability, and (2) a user-simulator-based policy optimization framework driven by a composite reward that aligns model behavior with user intent. Extensive experiments on mathematical reasoning, code generation, and document editing demonstrate that PIR consistently outperforms strong baselines, achieving up to 32.70\% higher accuracy, 22.90\% higher pass rate, and 41.36 BLEU improvement, while reducing nearly half of the reasoning computation and unnecessary interaction turns. Further reliability evaluations on factual knowledge, question answering, and missing-premise scenarios confirm the strong generalization and robustness of PIR. Model and code are publicly available at: \href{https://github.com/SUAT-AIRI/Proactive-Interactive-R1}
OmniVTLA: Vision-Tactile-Language-Action Model with Semantic-Aligned Tactile Sensing
Aug 12, 2025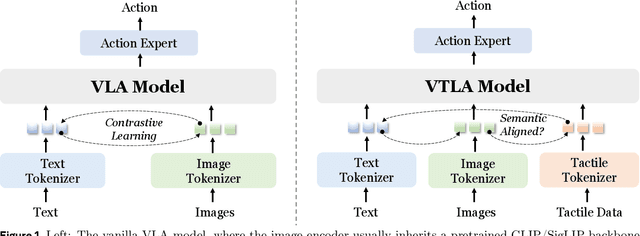

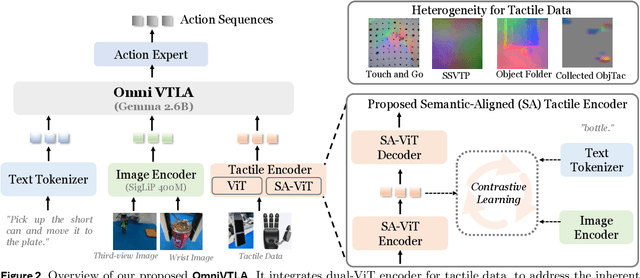

Recent vision-language-action (VLA) models build upon vision-language foundations, and have achieved promising results and exhibit the possibility of task generalization in robot manipulation. However, due to the heterogeneity of tactile sensors and the difficulty of acquiring tactile data, current VLA models significantly overlook the importance of tactile perception and fail in contact-rich tasks. To address this issue, this paper proposes OmniVTLA, a novel architecture involving tactile sensing. Specifically, our contributions are threefold. First, our OmniVTLA features a dual-path tactile encoder framework. This framework enhances tactile perception across diverse vision-based and force-based tactile sensors by using a pretrained vision transformer (ViT) and a semantically-aligned tactile ViT (SA-ViT). Second, we introduce ObjTac, a comprehensive force-based tactile dataset capturing textual, visual, and tactile information for 56 objects across 10 categories. With 135K tri-modal samples, ObjTac supplements existing visuo-tactile datasets. Third, leveraging this dataset, we train a semantically-aligned tactile encoder to learn a unified tactile representation, serving as a better initialization for OmniVTLA. Real-world experiments demonstrate substantial improvements over state-of-the-art VLA baselines, achieving 96.9% success rates with grippers, (21.9% higher over baseline) and 100% success rates with dexterous hands (6.2% higher over baseline) in pick-and-place tasks. Besides, OmniVTLA significantly reduces task completion time and generates smoother trajectories through tactile sensing compared to existing VLA.