 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Quantization-aware Training with Adaptive Coreset Selection
Jun 12, 2023The expanding model size and computation of deep neural networks (DNNs) have increased the demand for efficient model deployment methods. Quantization-aware training (QAT) is a representative model compression method to leverage redundancy in weights and activations. However, most existing QAT methods require end-to-end training on the entire dataset, which suffers from long training time and high energy costs. Coreset selection, aiming to improve data efficiency utilizing the redundancy of training data, has also been widely used for efficient training. In this work, we propose a new angle through the coreset selection to improve the training efficiency of quantization-aware training. Based on the characteristics of QAT, we propose two metrics: error vector score and disagreement score, to quantify the importance of each sample during training. Guided by these two metrics of importance, we proposed a quantization-aware adaptive coreset selection (ACS) method to select the data for the current training epoch. We evaluate our method on various networks (ResNet-18, MobileNetV2), datasets(CIFAR-100, ImageNet-1K), and under different quantization settings. Compared with previous coreset selection methods, our method significantly improves QAT performance with different dataset fractions. Our method can achieve an accuracy of 68.39% of 4-bit quantized ResNet-18 on the ImageNet-1K dataset with only a 10% subset, which has an absolute gain of 4.24% compared to the baseline.
Mixture-of-Supernets: Improving Weight-Sharing Supernet Training with Architecture-Routed Mixture-of-Experts
Jun 08, 2023



Weight-sharing supernet has become a vital component for performance estimation in the state-of-the-art (SOTA) neural architecture search (NAS) frameworks. Although supernet can directly generate different subnetworks without retraining, there is no guarantee for the quality of these subnetworks because of weight sharing. In NLP tasks such as machine translation and pre-trained language modeling, we observe that given the same model architecture, there is a large performance gap between supernet and training from scratch. Hence, supernet cannot be directly used and retraining is necessary after finding the optimal architectures. In this work, we propose mixture-of-supernets, a generalized supernet formulation where mixture-of-experts (MoE) is adopted to enhance the expressive power of the supernet model, with negligible training overhead. In this way, different subnetworks do not share the model weights directly, but through an architecture-based routing mechanism. As a result, model weights of different subnetworks are customized towards their specific architectures and the weight generation is learned by gradient descent. Compared to existing weight-sharing supernet for NLP, our method can minimize the retraining time, greatly improving training efficiency. In addition, the proposed method achieves the SOTA performance in NAS for building fast machine translation models, yielding better latency-BLEU tradeoff compared to HAT, state-of-the-art NAS for MT. We also achieve the SOTA performance in NAS for building memory-efficient task-agnostic BERT models, outperforming NAS-BERT and AutoDistil in various model sizes.
Binary and Ternary Natural Language Generation
Jun 02, 2023



Ternary and binary neural networks enable multiplication-free computation and promise multiple orders of magnitude efficiency gains over full-precision networks if implemented on specialized hardware. However, since both the parameter and the output space are highly discretized, such networks have proven very difficult to optimize. The difficulties are compounded for the class of transformer text generation models due to the sensitivity of the attention operation to quantization and the noise-compounding effects of autoregressive decoding in the high-cardinality output space. We approach the problem with a mix of statistics-based quantization for the weights and elastic quantization of the activations and demonstrate the first ternary and binary transformer models on the downstream tasks of summarization and machine translation. Our ternary BART base achieves an R1 score of 41 on the CNN/DailyMail benchmark, which is merely 3.9 points behind the full model while being 16x more efficient. Our binary model, while less accurate, achieves a highly non-trivial score of 35.6. For machine translation, we achieved BLEU scores of 21.7 and 17.6 on the WMT16 En-Ro benchmark, compared with a full precision mBART model score of 26.8. We also compare our approach in the 8-bit activation setting, where our ternary and even binary weight models can match or outperform the best existing 8-bit weight models in the literature. Our code and models are available at: https://github.com/facebookresearch/Ternary_Binary_Transformer
LLM-QAT: Data-Free Quantization Aware Training for Large Language Models
May 29, 2023



Several post-training quantization methods have been applied to large language models (LLMs), and have been shown to perform well down to 8-bits. We find that these methods break down at lower bit precision, and investigate quantization aware training for LLMs (LLM-QAT) to push quantization levels even further. We propose a data-free distillation method that leverages generations produced by the pre-trained model, which better preserves the original output distribution and allows quantizing any generative model independent of its training data, similar to post-training quantization methods. In addition to quantizing weights and activations, we also quantize the KV cache, which is critical for increasing throughput and support long sequence dependencies at current model sizes. We experiment with LLaMA models of sizes 7B, 13B, and 30B, at quantization levels down to 4-bits. We observe large improvements over training-free methods, especially in the low-bit settings.
EBSR: Enhanced Binary Neural Network for Image Super-Resolution
Mar 22, 2023While the performance of deep convolutional neural networks for image super-resolution (SR) has improved significantly, the rapid increase of memory and computation requirements hinders their deployment on resource-constrained devices. Quantized networks, especially binary neural networks (BNN) for SR have been proposed to significantly improve the model inference efficiency but suffer from large performance degradation. We observe the activation distribution of SR networks demonstrates very large pixel-to-pixel, channel-to-channel, and image-to-image variation, which is important for high performance SR but gets lost during binarization. To address the problem, we propose two effective methods, including the spatial re-scaling as well as channel-wise shifting and re-scaling, which augments binary convolutions by retaining more spatial and channel-wise information. Our proposed models, dubbed EBSR, demonstrate superior performance over prior art methods both quantitatively and qualitatively across different datasets and different model sizes. Specifically, for x4 SR on Set5 and Urban100, EBSRlight improves the PSNR by 0.31 dB and 0.28 dB compared to SRResNet-E2FIF, respectively, while EBSR outperforms EDSR-E2FIF by 0.29 dB and 0.32 dB PSNR, respectively.
Oscillation-free Quantization for Low-bit Vision Transformers
Feb 04, 2023Weight oscillation is an undesirable side effect of quantization-aware training, in which quantized weights frequently jump between two quantized levels, resulting in training instability and a sub-optimal final model. We discover that the learnable scaling factor, a widely-used $\textit{de facto}$ setting in quantization aggravates weight oscillation. In this study, we investigate the connection between the learnable scaling factor and quantized weight oscillation and use ViT as a case driver to illustrate the findings and remedies. In addition, we also found that the interdependence between quantized weights in $\textit{query}$ and $\textit{key}$ of a self-attention layer makes ViT vulnerable to oscillation. We, therefore, propose three techniques accordingly: statistical weight quantization ($\rm StatsQ$) to improve quantization robustness compared to the prevalent learnable-scale-based method; confidence-guided annealing ($\rm CGA$) that freezes the weights with $\textit{high confidence}$ and calms the oscillating weights; and $\textit{query}$-$\textit{key}$ reparameterization ($\rm QKR$) to resolve the query-key intertwined oscillation and mitigate the resulting gradient misestimation. Extensive experiments demonstrate that these proposed techniques successfully abate weight oscillation and consistently achieve substantial accuracy improvement on ImageNet. Specifically, our 2-bit DeiT-T/DeiT-S algorithms outperform the previous state-of-the-art by 9.8% and 7.7%, respectively. The code is included in the supplementary material and will be released.
SDQ: Stochastic Differentiable Quantization with Mixed Precision
Jun 17, 2022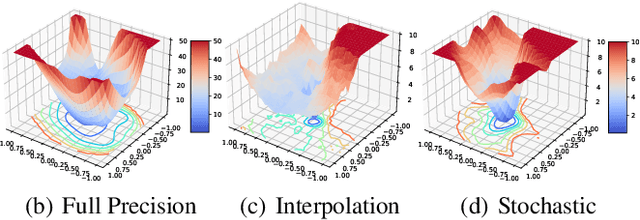
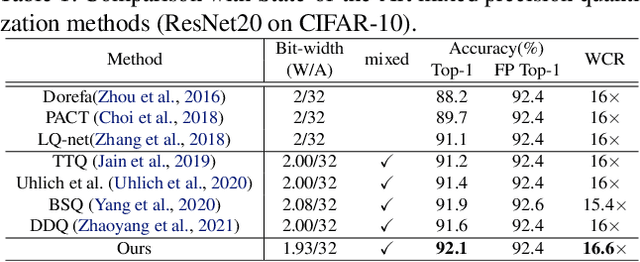
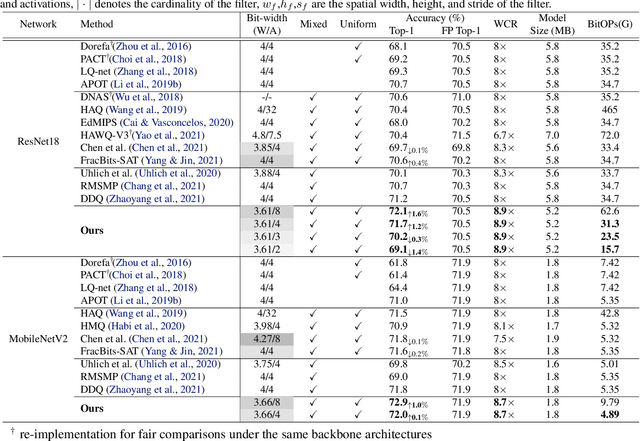
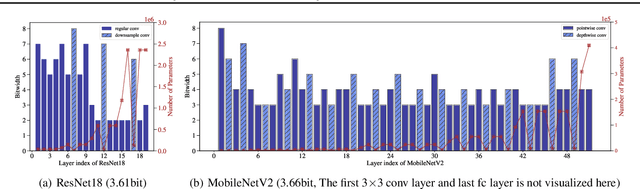
In order to deploy deep models in a computationally efficient manner, model quantization approaches have been frequently used. In addition, as new hardware that supports mixed bitwidth arithmetic operations, recent research on mixed precision quantization (MPQ) begins to fully leverage the capacity of representation by searching optimized bitwidths for different layers and modules in a network. However, previous studies mainly search the MPQ strategy in a costly scheme using reinforcement learning, neural architecture search, etc., or simply utilize partial prior knowledge for bitwidth assignment, which might be biased and sub-optimal. In this work, we present a novel Stochastic Differentiable Quantization (SDQ) method that can automatically learn the MPQ strategy in a more flexible and globally-optimized space with smoother gradient approximation. Particularly, Differentiable Bitwidth Parameters (DBPs) are employed as the probability factors in stochastic quantization between adjacent bitwidth choices. After the optimal MPQ strategy is acquired, we further train our network with entropy-aware bin regularization and knowledge distillation. We extensively evaluate our method for several networks on different hardware (GPUs and FPGA) and datasets. SDQ outperforms all state-of-the-art mixed or single precision quantization with a lower bitwidth and is even better than the full-precision counterparts across various ResNet and MobileNet families, demonstrating the effectiveness and superiority of our method.
BiT: Robustly Binarized Multi-distilled Transformer
May 25, 2022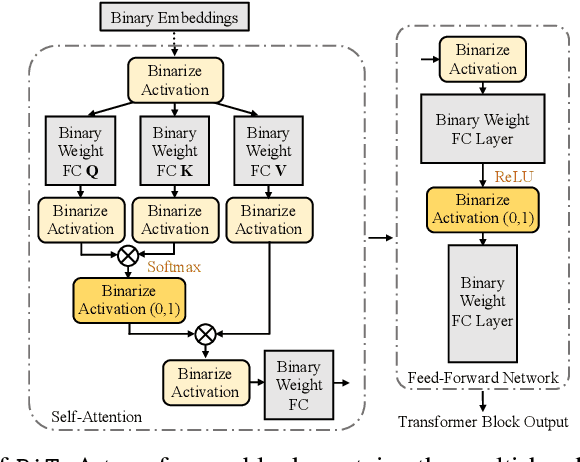
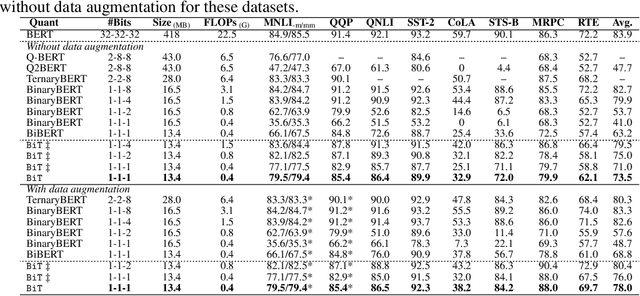

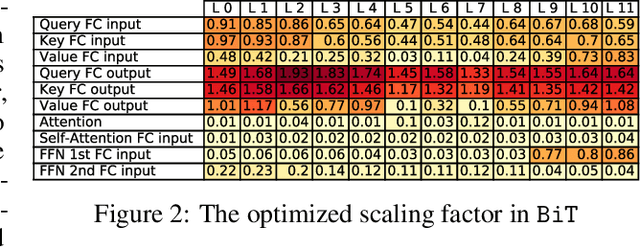
Modern pre-trained transformers have rapidly advanced the state-of-the-art in machine learning, but have also grown in parameters and computational complexity, making them increasingly difficult to deploy in resource-constrained environments. Binarization of the weights and activations of the network can significantly alleviate these issues, however is technically challenging from an optimization perspective. In this work, we identify a series of improvements which enables binary transformers at a much higher accuracy than what was possible previously. These include a two-set binarization scheme, a novel elastic binary activation function with learned parameters, and a method to quantize a network to its limit by successively distilling higher precision models into lower precision students. These approaches allow for the first time, fully binarized transformer models that are at a practical level of accuracy, approaching a full-precision BERT baseline on the GLUE language understanding benchmark within as little as 5.9%.
Stereo Neural Vernier Caliper
Mar 26, 2022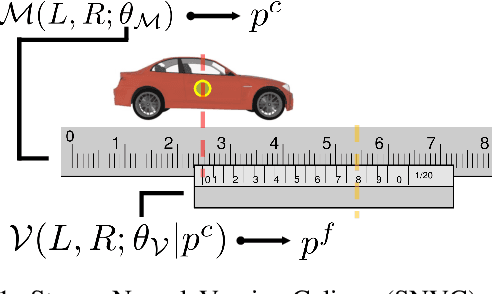
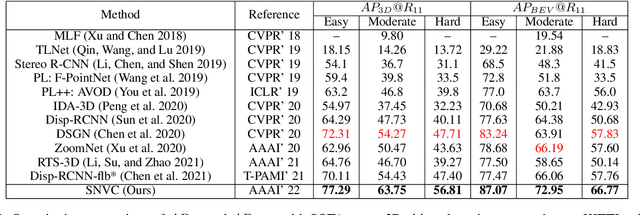
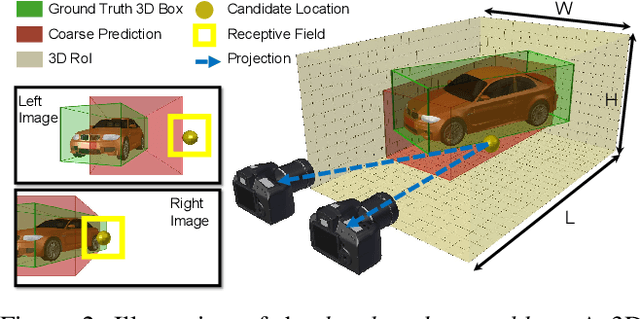
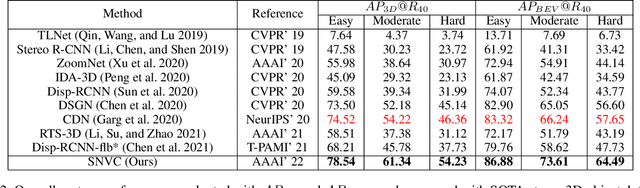
We propose a new object-centric framework for learning-based stereo 3D object detection. Previous studies build scene-centric representations that do not consider the significant variation among outdoor instances and thus lack the flexibility and functionalities that an instance-level model can offer. We build such an instance-level model by formulating and tackling a local update problem, i.e., how to predict a refined update given an initial 3D cuboid guess. We demonstrate how solving this problem can complement scene-centric approaches in (i) building a coarse-to-fine multi-resolution system, (ii) performing model-agnostic object location refinement, and (iii) conducting stereo 3D tracking-by-detection. Extensive experiments demonstrate the effectiveness of our approach, which achieves state-of-the-art performance on the KITTI benchmark. Code and pre-trained models are available at https://github.com/Nicholasli1995/SNVC.
Vision Transformer Slimming: Multi-Dimension Searching in Continuous Optimization Space
Jan 03, 2022
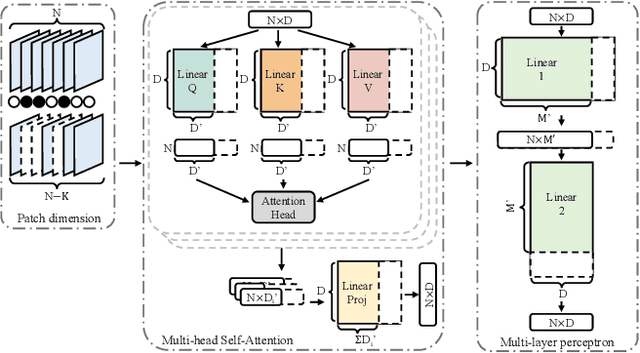
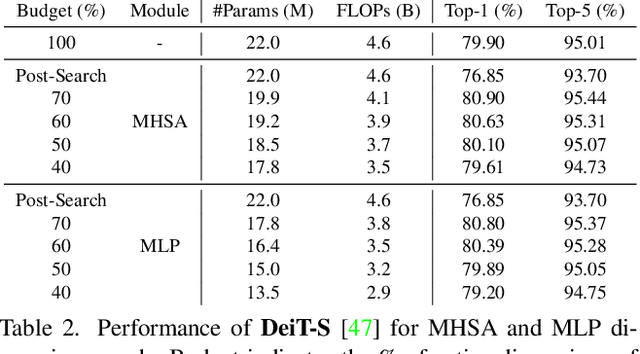
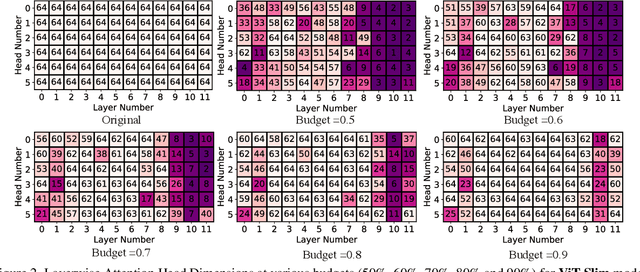
This paper explores the feasibility of finding an optimal sub-model from a vision transformer and introduces a pure vision transformer slimming (ViT-Slim) framework that can search such a sub-structure from the original model end-to-end across multiple dimensions, including the input tokens, MHSA and MLP modules with state-of-the-art performance. Our method is based on a learnable and unified l1 sparsity constraint with pre-defined factors to reflect the global importance in the continuous searching space of different dimensions. The searching process is highly efficient through a single-shot training scheme. For instance, on DeiT-S, ViT-Slim only takes ~43 GPU hours for searching process, and the searched structure is flexible with diverse dimensionalities in different modules. Then, a budget threshold is employed according to the requirements of accuracy-FLOPs trade-off on running devices, and a re-training process is performed to obtain the final models. The extensive experiments show that our ViT-Slim can compress up to 40% of parameters and 40% FLOPs on various vision transformers while increasing the accuracy by ~0.6% on ImageNet. We also demonstrate the advantage of our searched models on several downstream datasets. Our source code will be publicly available.