 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecoding and Diversity in Machine Translation
Nov 26, 2020

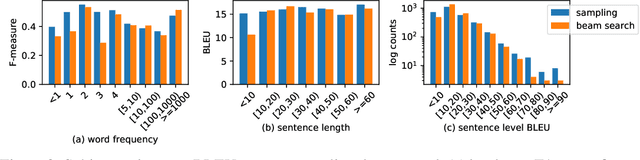
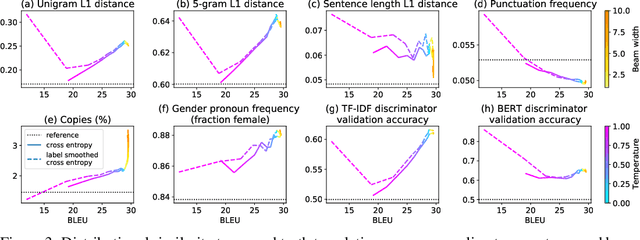
Neural Machine Translation (NMT) systems are typically evaluated using automated metrics that assess the agreement between generated translations and ground truth candidates. To improve systems with respect to these metrics, NLP researchers employ a variety of heuristic techniques, including searching for the conditional mode (vs. sampling) and incorporating various training heuristics (e.g., label smoothing). While search strategies significantly improve BLEU score, they yield deterministic outputs that lack the diversity of human translations. Moreover, search tends to bias the distribution of translated gender pronouns. This makes human-level BLEU a misleading benchmark in that modern MT systems cannot approach human-level BLEU while simultaneously maintaining human-level translation diversity. In this paper, we characterize distributional differences between generated and real translations, examining the cost in diversity paid for the BLEU scores enjoyed by NMT. Moreover, our study implicates search as a salient source of known bias when translating gender pronouns.
Rebounding Bandits for Modeling Satiation Effects
Nov 13, 2020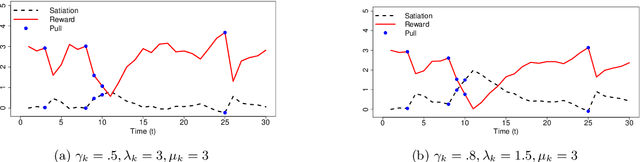
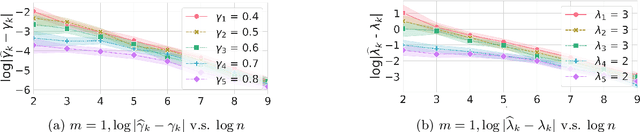
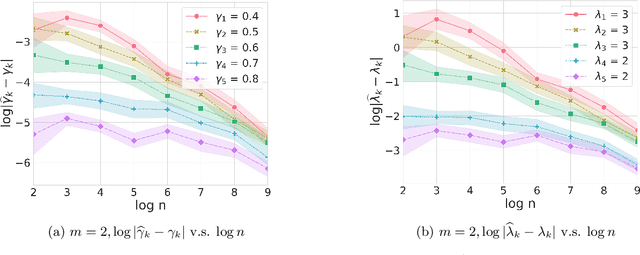
Psychological research shows that enjoyment of many goods is subject to satiation, with enjoyment declining after repeated exposures to the same item. Nevertheless, proposed algorithms for powering recommender systems seldom model these dynamics, instead proceeding as though user preferences were fixed in time. In this work, we adopt a multi-armed bandit setup, modeling satiation dynamics as a time-invariant linear dynamical system. In our model, the expected rewards for each arm decline monotonically with consecutive exposures and rebound towards the initial reward whenever that arm is not pulled. We analyze this model, showing that, when the arms exhibit deterministic identical dynamics, our problem is equivalent to a specific instance of Max K-Cut. In this case, a greedy policy, which plays the arms in a cyclic order, is optimal. In the general setting, where each arm's satiation dynamics are stochastic and governed by different (unknown) parameters, we propose an algorithm that first uses offline data to estimate each arm's reward model and then plans using a generalization of the greedy policy.
Fair Machine Learning Under Partial Compliance
Nov 10, 2020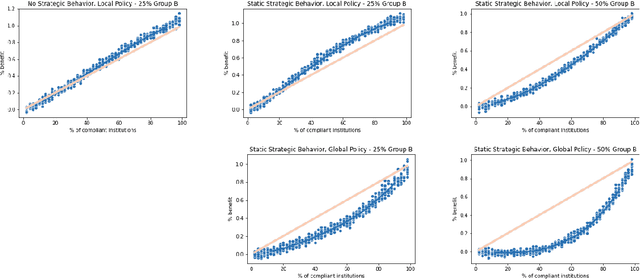
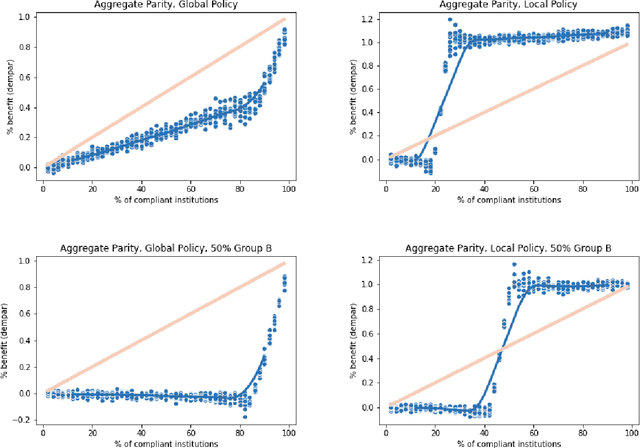
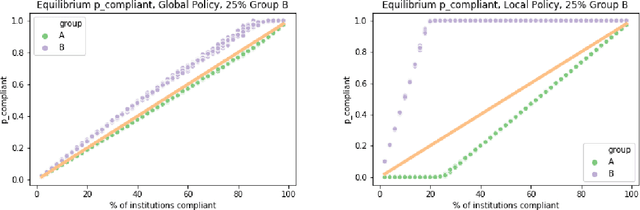
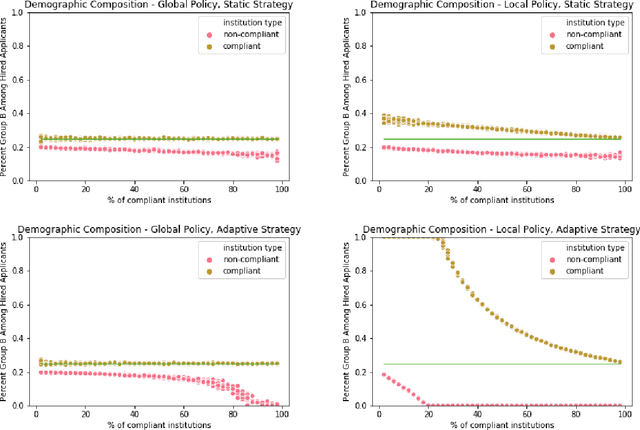
Typically, fair machine learning research focuses on a single decisionmaker and assumes that the underlying population is stationary. However, many of the critical domains motivating this work are characterized by competitive marketplaces with many decisionmakers. Realistically, we might expect only a subset of them to adopt any non-compulsory fairness-conscious policy, a situation that political philosophers call partial compliance. This possibility raises important questions: how does the strategic behavior of decision subjects in partial compliance settings affect the allocation outcomes? If k% of employers were to voluntarily adopt a fairness-promoting intervention, should we expect k% progress (in aggregate) towards the benefits of universal adoption, or will the dynamics of partial compliance wash out the hoped-for benefits? How might adopting a global (versus local) perspective impact the conclusions of an auditor? In this paper, we propose a simple model of an employment market, leveraging simulation as a tool to explore the impact of both interaction effects and incentive effects on outcomes and auditing metrics. Our key findings are that at equilibrium: (1) partial compliance (k% of employers) can result in far less than proportional (k%) progress towards the full compliance outcomes; (2) the gap is more severe when fair employers match global (vs local) statistics; (3) choices of local vs global statistics can paint dramatically different pictures of the performance vis-a-vis fairness desiderata of compliant versus non-compliant employers; and (4) partial compliance to local parity measures can induce extreme segregation.
Weakly- and Semi-supervised Evidence Extraction
Nov 03, 2020
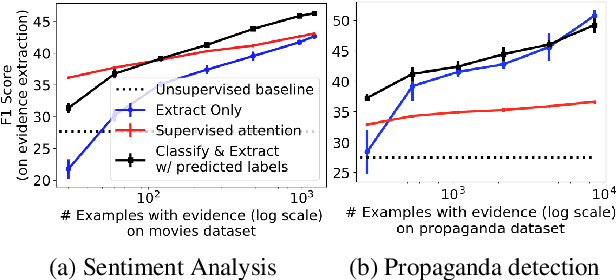

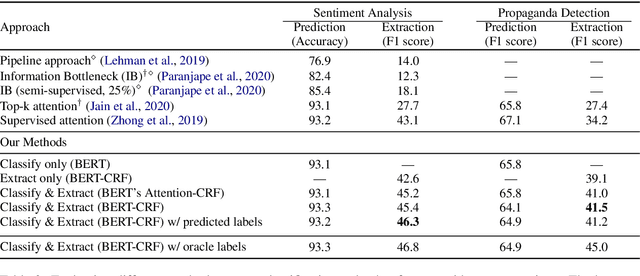
For many prediction tasks, stakeholders desire not only predictions but also supporting evidence that a human can use to verify its correctness. However, in practice, additional annotations marking supporting evidence may only be available for a minority of training examples (if available at all). In this paper, we propose new methods to combine few evidence annotations (strong semi-supervision) with abundant document-level labels (weak supervision) for the task of evidence extraction. Evaluating on two classification tasks that feature evidence annotations, we find that our methods outperform baselines adapted from the interpretability literature to our task. Our approach yields substantial gains with as few as hundred evidence annotations. Code and datasets to reproduce our work are available at https://github.com/danishpruthi/evidence-extraction.
Unsupervised Data Augmentation with Naive Augmentation and without Unlabeled Data
Oct 22, 2020
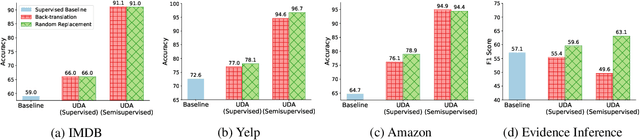
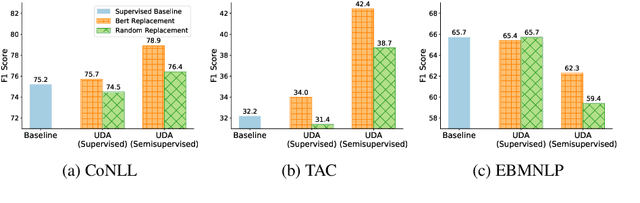

Unsupervised Data Augmentation (UDA) is a semi-supervised technique that applies a consistency loss to penalize differences between a model's predictions on (a) observed (unlabeled) examples; and (b) corresponding 'noised' examples produced via data augmentation. While UDA has gained popularity for text classification, open questions linger over which design decisions are necessary and over how to extend the method to sequence labeling tasks. This method has recently gained traction for text classification. In this paper, we re-examine UDA and demonstrate its efficacy on several sequential tasks. Our main contribution is an empirical study of UDA to establish which components of the algorithm confer benefits in NLP. Notably, although prior work has emphasized the use of clever augmentation techniques including back-translation, we find that enforcing consistency between predictions assigned to observed and randomly substituted words often yields comparable (or greater) benefits compared to these complex perturbation models. Furthermore, we find that applying its consistency loss affords meaningful gains without any unlabeled data at all, i.e., in a standard supervised setting. In short: UDA need not be unsupervised, and does not require complex data augmentation to be effective.
On Negative Interference in Multilingual Models: Findings and A Meta-Learning Treatment
Oct 06, 2020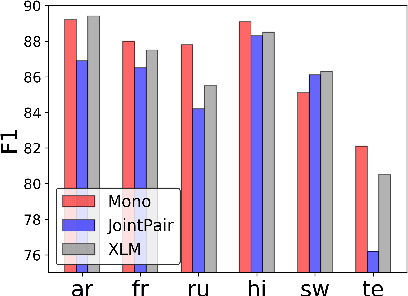
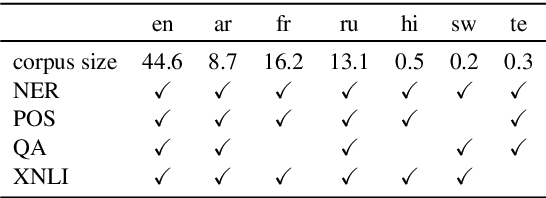
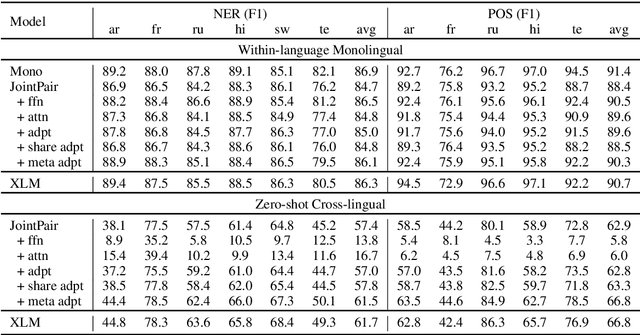
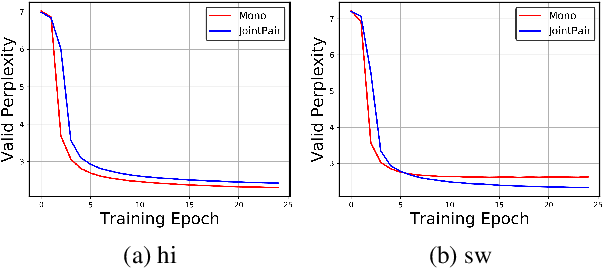
Modern multilingual models are trained on concatenated text from multiple languages in hopes of conferring benefits to each (positive transfer), with the most pronounced benefits accruing to low-resource languages. However, recent work has shown that this approach can degrade performance on high-resource languages, a phenomenon known as negative interference. In this paper, we present the first systematic study of negative interference. We show that, contrary to previous belief, negative interference also impacts low-resource languages. While parameters are maximally shared to learn language-universal structures, we demonstrate that language-specific parameters do exist in multilingual models and they are a potential cause of negative interference. Motivated by these observations, we also present a meta-learning algorithm that obtains better cross-lingual transferability and alleviates negative interference, by adding language-specific layers as meta-parameters and training them in a manner that explicitly improves shared layers' generalization on all languages. Overall, our results show that negative interference is more common than previously known, suggesting new directions for improving multilingual representations.
Explaining The Efficacy of Counterfactually-Augmented Data
Oct 06, 2020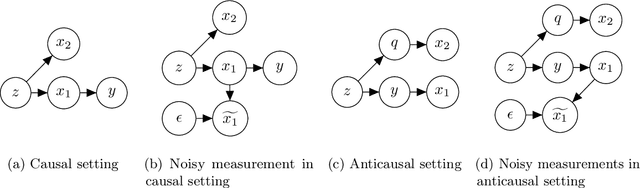
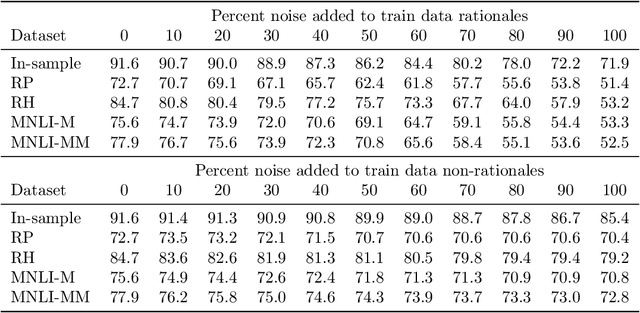
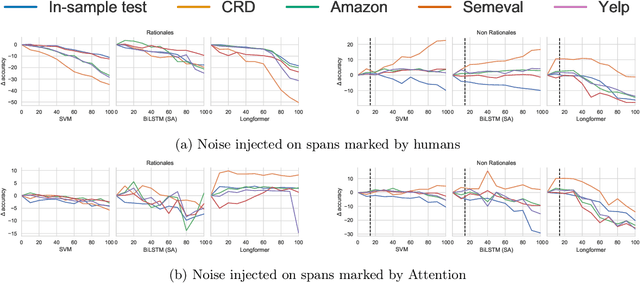
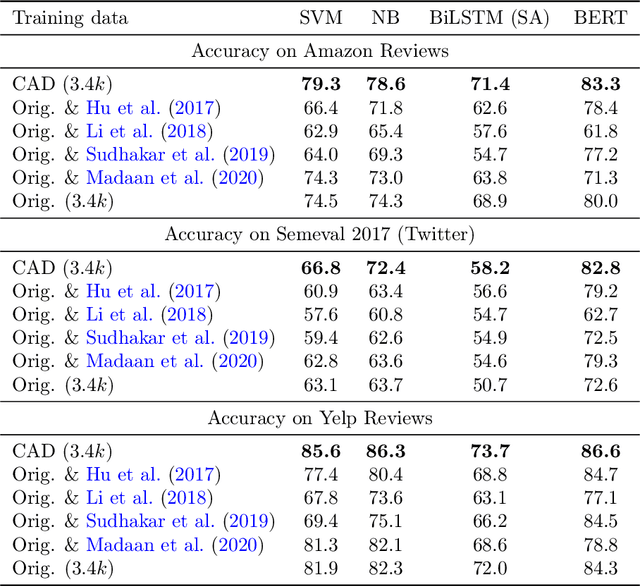
In attempts to produce machine learning models less reliant on spurious patterns in training data, researchers have recently proposed a human-in-the-loop process for generating counterfactually augmented datasets. As applied in NLP, given some documents and their (initial) labels, humans are tasked with revising the text to make a (given) counterfactual label applicable. Importantly, the instructions prohibit edits that are not necessary to flip the applicable label. Models trained on the augmented (original and revised) data have been shown to rely less on semantically irrelevant words and to generalize better out-of-domain. While this work draws on causal thinking, casting edits as interventions and relying on human understanding to assess outcomes, the underlying causal model is not clear nor are the principles underlying the observed improvements in out-of-domain evaluation. In this paper, we explore a toy analog, using linear Gaussian models. Our analysis reveals interesting relationships between causal models, measurement noise, out-of-domain generalization, and reliance on spurious signals. Interestingly our analysis suggests that data corrupted by adding noise to causal features will degrade out-of-domain performance, while noise added to non-causal features may make models more robust out-of-domain. This analysis yields interesting insights that help to explain the efficacy of counterfactually augmented data. Finally, we present a large-scale empirical study that supports this hypothesis.
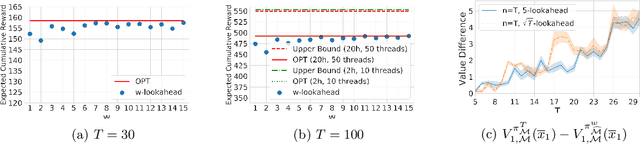
Uncertainty-Aware Lookahead Factor Models for Quantitative Investing
Jul 15, 2020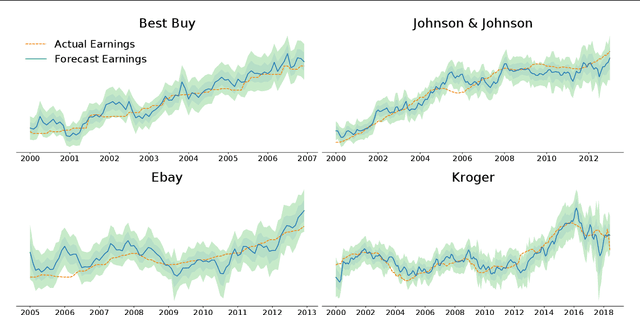
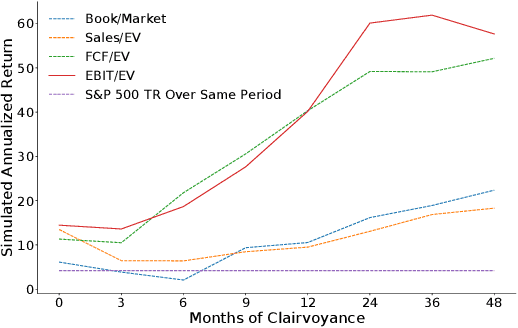
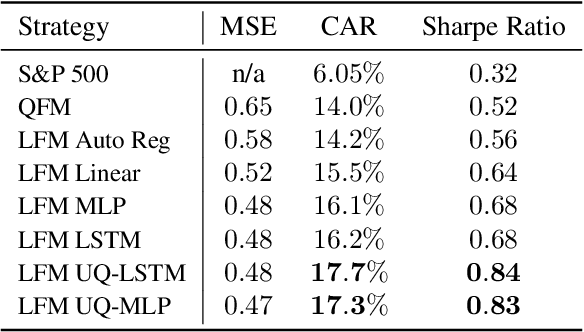
On a periodic basis, publicly traded companies report fundamentals, financial data including revenue, earnings, debt, among others. Quantitative finance research has identified several factors, functions of the reported data that historically correlate with stock market performance. In this paper, we first show through simulation that if we could select stocks via factors calculated on future fundamentals (via oracle), that our portfolios would far outperform standard factor models. Motivated by this insight, we train deep nets to forecast future fundamentals from a trailing 5-year history. We propose lookahead factor models which plug these predicted future fundamentals into traditional factors. Finally, we incorporate uncertainty estimates from both neural heteroscedastic regression and a dropout-based heuristic, improving performance by adjusting our portfolios to avert risk. In retrospective analysis, we leverage an industry-grade portfolio simulator (backtester) to show simultaneous improvement in annualized return and Sharpe ratio. Specifically, the simulated annualized return for the uncertainty-aware model is 17.7% (vs 14.0% for a standard factor model) and the Sharpe ratio is 0.84 (vs 0.52).
Extracting Structured Data from Physician-Patient Conversations By Predicting Noteworthy Utterances
Jul 14, 2020
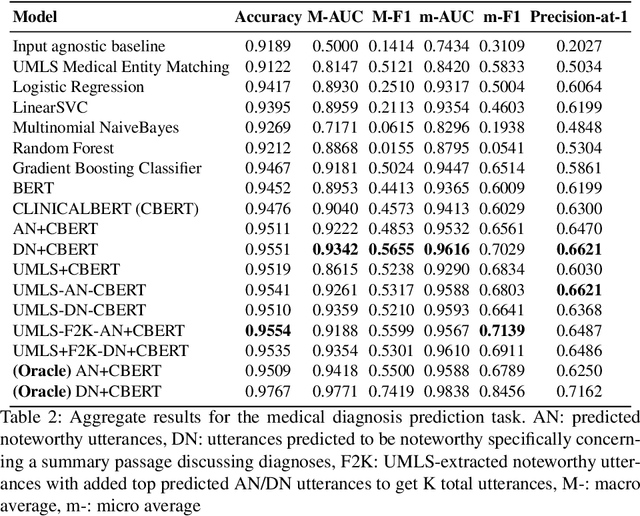
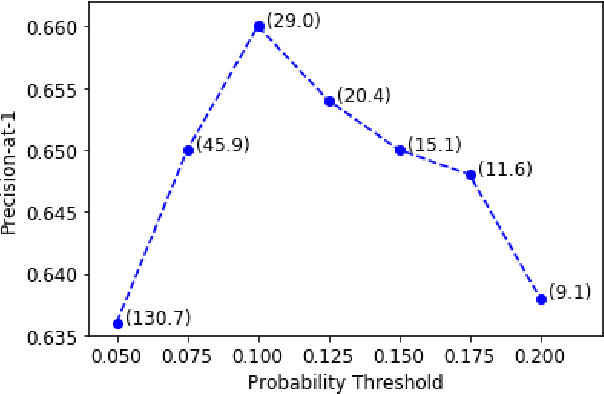
Despite diverse efforts to mine various modalities of medical data, the conversations between physicians and patients at the time of care remain an untapped source of insights. In this paper, we leverage this data to extract structured information that might assist physicians with post-visit documentation in electronic health records, potentially lightening the clerical burden. In this exploratory study, we describe a new dataset consisting of conversation transcripts, post-visit summaries, corresponding supporting evidence (in the transcript), and structured labels. We focus on the tasks of recognizing relevant diagnoses and abnormalities in the review of organ systems (RoS). One methodological challenge is that the conversations are long (around 1500 words), making it difficult for modern deep-learning models to use them as input. To address this challenge, we extract noteworthy utterances---parts of the conversation likely to be cited as evidence supporting some summary sentence. We find that by first filtering for (predicted) noteworthy utterances, we can significantly boost predictive performance for recognizing both diagnoses and RoS abnormalities.
Predicting Mortality Risk in Viral and Unspecified Pneumonia to Assist Clinicians with COVID-19 ECMO Planning
Jun 02, 2020
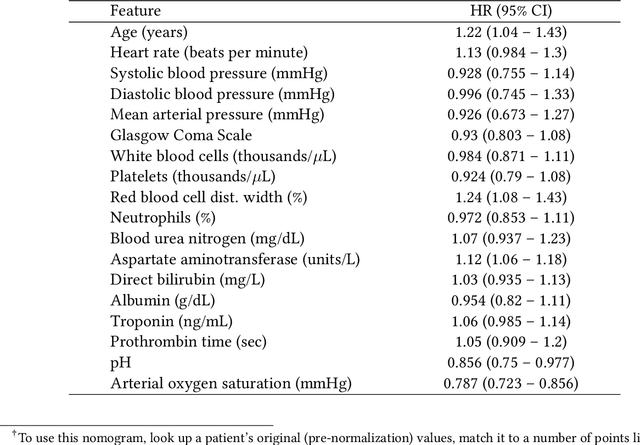
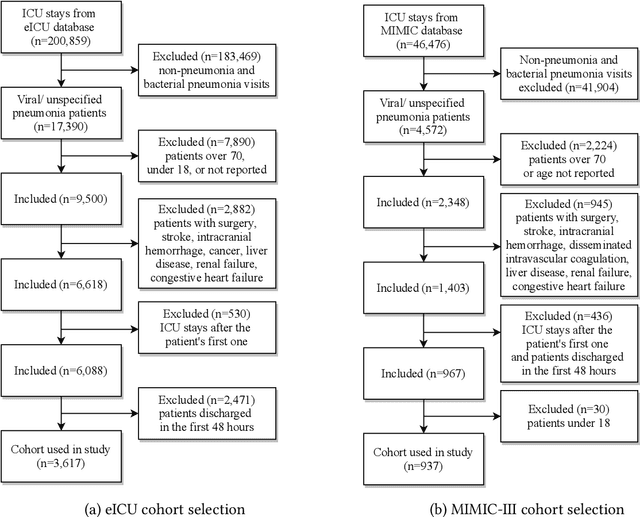
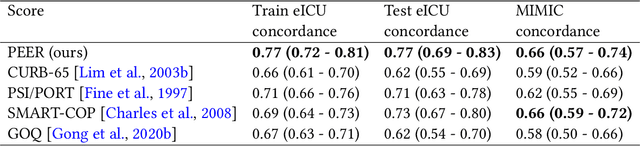
Respiratory complications due to coronavirus disease COVID-19 have claimed tens of thousands of lives in 2020. Many cases of COVID-19 escalate from Severe Acute Respiratory Syndrome (SARS-CoV-2) to viral pneumonia to acute respiratory distress syndrome (ARDS) to death. Extracorporeal membranous oxygenation (ECMO) is a life-sustaining oxygenation and ventilation therapy that may be used for patients with severe ARDS when mechanical ventilation is insufficient to sustain life. While early planning and surgical cannulation for ECMO can increase survival, clinicians report the lack of a risk score hinders these efforts. In this work, we leverage machine learning techniques to develop the PEER score, used to highlight critically ill patients with viral or unspecified pneumonia at high risk of mortality or decompensation in a subpopulation eligible for ECMO. The PEER score is validated on two large, publicly available critical care databases and predicts mortality at least as well as other existing risk scores. Stratifying our cohorts into low-risk and high-risk groups, we find that the high-risk group also has a higher proportion of decompensation indicators such as vasopressor and ventilator use. Finally, the PEER score is provided in the form of a nomogram for direct calculation of patient risk, and can be used to highlight at-risk patients among critical care patients eligible for ECMO.