 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Data Augmentation with Naive Augmentation and without Unlabeled Data
Oct 22, 2020
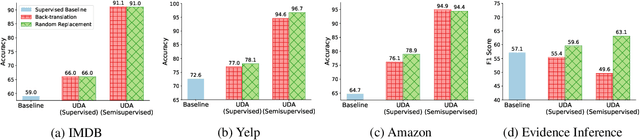
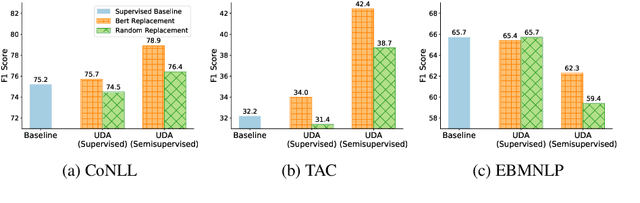

Unsupervised Data Augmentation (UDA) is a semi-supervised technique that applies a consistency loss to penalize differences between a model's predictions on (a) observed (unlabeled) examples; and (b) corresponding 'noised' examples produced via data augmentation. While UDA has gained popularity for text classification, open questions linger over which design decisions are necessary and over how to extend the method to sequence labeling tasks. This method has recently gained traction for text classification. In this paper, we re-examine UDA and demonstrate its efficacy on several sequential tasks. Our main contribution is an empirical study of UDA to establish which components of the algorithm confer benefits in NLP. Notably, although prior work has emphasized the use of clever augmentation techniques including back-translation, we find that enforcing consistency between predictions assigned to observed and randomly substituted words often yields comparable (or greater) benefits compared to these complex perturbation models. Furthermore, we find that applying its consistency loss affords meaningful gains without any unlabeled data at all, i.e., in a standard supervised setting. In short: UDA need not be unsupervised, and does not require complex data augmentation to be effective.
How transferable are the datasets collected by active learners?
Jul 12, 2018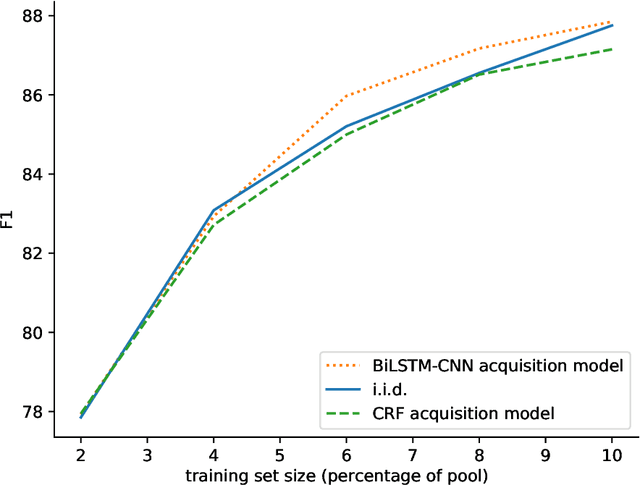

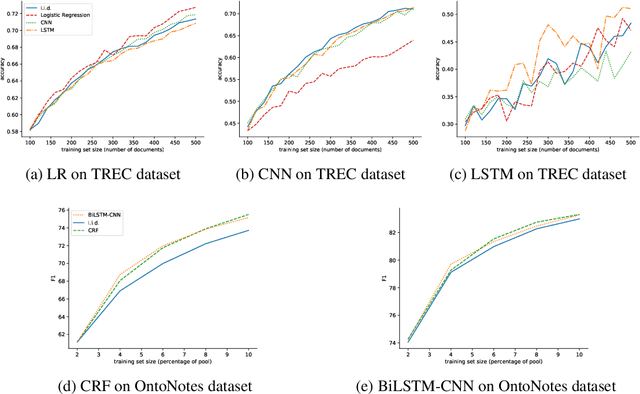
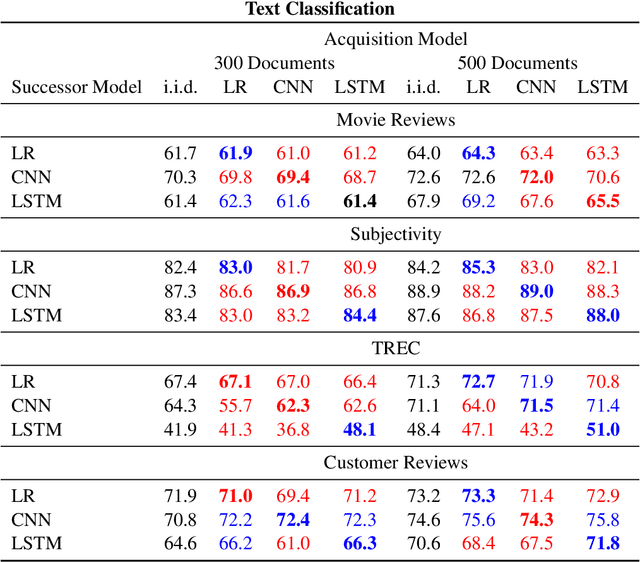
Active learning is a widely-used training strategy for maximizing predictive performance subject to a fixed annotation budget. Between rounds of training, an active learner iteratively selects examples for annotation, typically based on some measure of the model's uncertainty, coupling the acquired dataset with the underlying model. However, owing to the high cost of annotation and the rapid pace of model development, labeled datasets may remain valuable long after a particular model is surpassed by new technology. In this paper, we investigate the transferability of datasets collected with an acquisition model A to a distinct successor model S. We seek to characterize whether the benefits of active learning persist when A and S are different models. To this end, we consider two standard NLP tasks and associated datasets: text classification and sequence tagging. We find that training S on a dataset actively acquired with a (different) model A typically yields worse performance than when S is trained with "native" data (i.e., acquired actively using S), and often performs worse than training on i.i.d. sampled data. These findings have implications for the use of active learning in practice,suggesting that it is better suited to cases where models are updated no more frequently than labeled data.