 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSupervised Learning with General Risk Functionals
Jun 27, 2022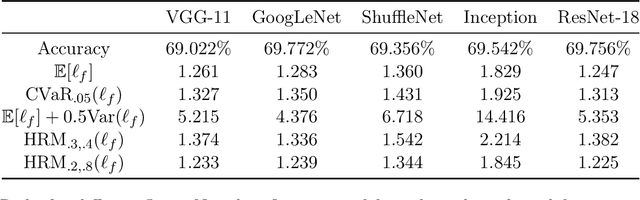
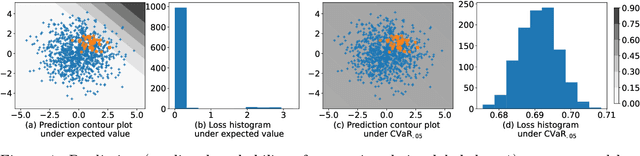
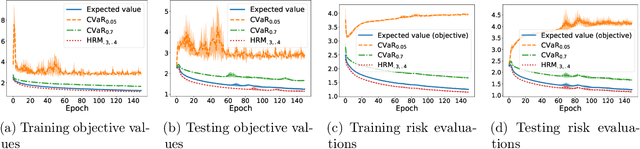
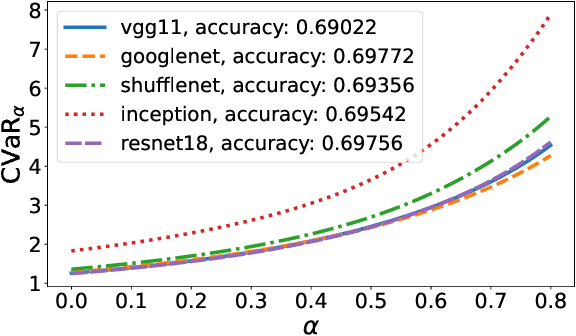
Standard uniform convergence results bound the generalization gap of the expected loss over a hypothesis class. The emergence of risk-sensitive learning requires generalization guarantees for functionals of the loss distribution beyond the expectation. While prior works specialize in uniform convergence of particular functionals, our work provides uniform convergence for a general class of H\"older risk functionals for which the closeness in the Cumulative Distribution Function (CDF) entails closeness in risk. We establish the first uniform convergence results for estimating the CDF of the loss distribution, yielding guarantees that hold simultaneously both over all H\"older risk functionals and over all hypotheses. Thus licensed to perform empirical risk minimization, we develop practical gradient-based methods for minimizing distortion risks (widely studied subset of H\"older risks that subsumes the spectral risks, including the mean, conditional value at risk, cumulative prospect theory risks, and others) and provide convergence guarantees. In experiments, we demonstrate the efficacy of our learning procedure, both in settings where uniform convergence results hold and in high-dimensional settings with deep networks.
On the Maximum Hessian Eigenvalue and Generalization
Jun 21, 2022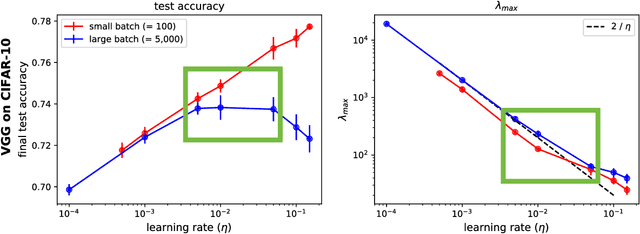
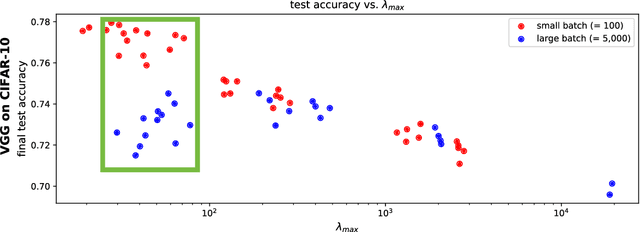
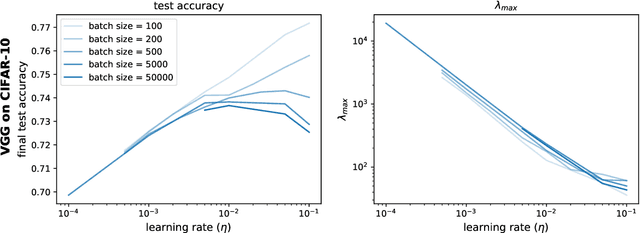
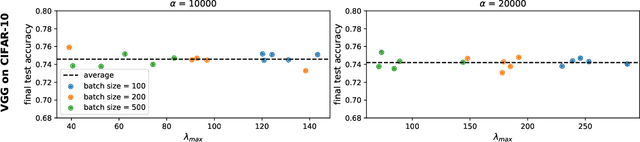
The mechanisms by which certain training interventions, such as increasing learning rates and applying batch normalization, improve the generalization of deep networks remains a mystery. Prior works have speculated that "flatter" solutions generalize better than "sharper" solutions to unseen data, motivating several metrics for measuring flatness (particularly $\lambda_{max}$, the largest eigenvalue of the Hessian of the loss); and algorithms, such as Sharpness-Aware Minimization (SAM) [1], that directly optimize for flatness. Other works question the link between $\lambda_{max}$ and generalization. In this paper, we present findings that call $\lambda_{max}$'s influence on generalization further into question. We show that: (1) while larger learning rates reduce $\lambda_{max}$ for all batch sizes, generalization benefits sometimes vanish at larger batch sizes; (2) by scaling batch size and learning rate simultaneously, we can change $\lambda_{max}$ without affecting generalization; (3) while SAM produces smaller $\lambda_{max}$ for all batch sizes, generalization benefits (also) vanish with larger batch sizes; (4) for dropout, excessively high dropout probabilities can degrade generalization, even as they promote smaller $\lambda_{max}$; and (5) while batch-normalization does not consistently produce smaller $\lambda_{max}$, it nevertheless confers generalization benefits. While our experiments affirm the generalization benefits of large learning rates and SAM for minibatch SGD, the GD-SGD discrepancy demonstrates limits to $\lambda_{max}$'s ability to explain generalization in neural networks.
Resolving the Human Subjects Status of Machine Learning's Crowdworkers
Jun 08, 2022
In recent years, machine learning (ML) has come to rely more heavily on crowdworkers, both for building bigger datasets and for addressing research questions requiring human interaction or judgment. Owing to the diverse tasks performed by crowdworkers, and the myriad ways the resulting datasets are used, it can be difficult to determine when these individuals are best thought of as workers, versus as human subjects. These difficulties are compounded by conflicting policies, with some institutions and researchers treating all ML crowdwork as human subjects research, and other institutions holding that ML crowdworkers rarely constitute human subjects. Additionally, few ML papers involving crowdwork mention IRB oversight, raising the prospect that many might not be in compliance with ethical and regulatory requirements. In this paper, we focus on research in natural language processing to investigate the appropriate designation of crowdsourcing studies and the unique challenges that ML research poses for research oversight. Crucially, under the U.S. Common Rule, these judgments hinge on determinations of "aboutness", both whom (or what) the collected data is about and whom (or what) the analysis is about. We highlight two challenges posed by ML: (1) the same set of workers can serve multiple roles and provide many sorts of information; and (2) compared to the life sciences and social sciences, ML research tends to embrace a dynamic workflow, where research questions are seldom stated ex ante and data sharing opens the door for future studies to ask questions about different targets from the original study. In particular, our analysis exposes a potential loophole in the Common Rule, where researchers can elude research ethics oversight by splitting data collection and analysis into distinct studies. We offer several policy recommendations to address these concerns.
Modeling Attrition in Recommender Systems with Departing Bandits
Mar 25, 2022

Traditionally, when recommender systems are formalized as multi-armed bandits, the policy of the recommender system influences the rewards accrued, but not the length of interaction. However, in real-world systems, dissatisfied users may depart (and never come back). In this work, we propose a novel multi-armed bandit setup that captures such policy-dependent horizons. Our setup consists of a finite set of user types, and multiple arms with Bernoulli payoffs. Each (user type, arm) tuple corresponds to an (unknown) reward probability. Each user's type is initially unknown and can only be inferred through their response to recommendations. Moreover, if a user is dissatisfied with their recommendation, they might depart the system. We first address the case where all users share the same type, demonstrating that a recent UCB-based algorithm is optimal. We then move forward to the more challenging case, where users are divided among two types. While naive approaches cannot handle this setting, we provide an efficient learning algorithm that achieves $\tilde{O}(\sqrt{T})$ regret, where $T$ is the number of users.
Can Transformers be Strong Treatment Effect Estimators?
Feb 14, 2022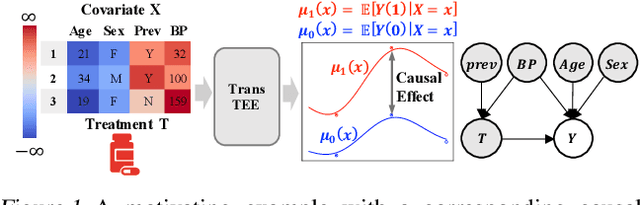

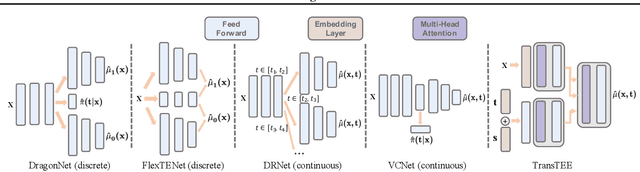
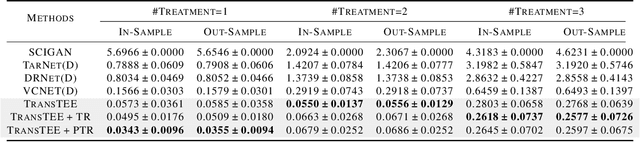
In this paper, we develop a general framework based on the Transformer architecture to address a variety of challenging treatment effect estimation (TEE) problems. Our methods are applicable both when covariates are tabular and when they consist of sequences (e.g., in text), and can handle discrete, continuous, structured, or dosage-associated treatments. While Transformers have already emerged as dominant methods for diverse domains, including natural language and computer vision, our experiments with Transformers as Treatment Effect Estimators (TransTEE) demonstrate that these inductive biases are also effective on the sorts of estimation problems and datasets that arise in research aimed at estimating causal effects. Moreover, we propose a propensity score network that is trained with TransTEE in an adversarial manner to promote independence between covariates and treatments to further address selection bias. Through extensive experiments, we show that TransTEE significantly outperforms competitive baselines with greater parameter efficiency over a wide range of benchmarks and settings.
Leveraging Unlabeled Data to Predict Out-of-Distribution Performance
Feb 09, 2022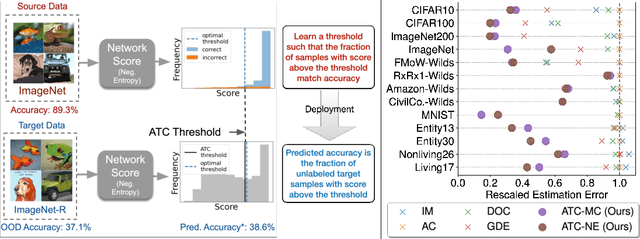
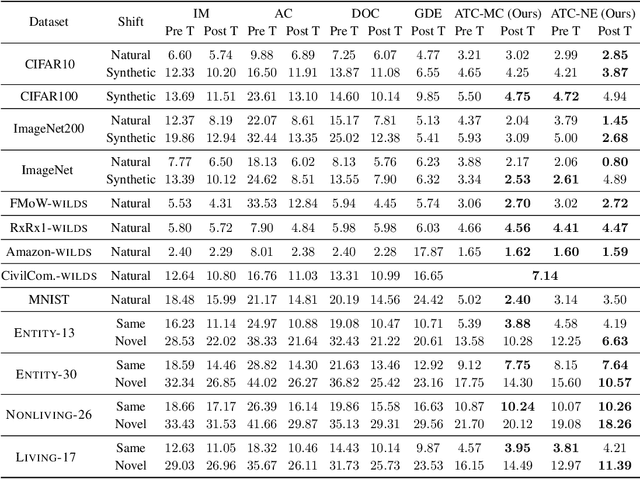
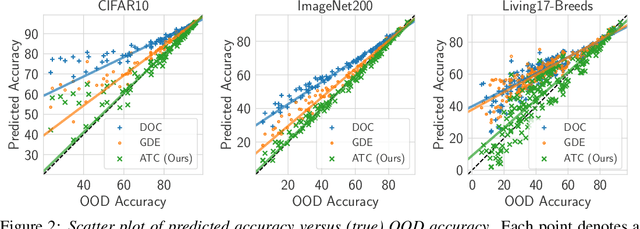
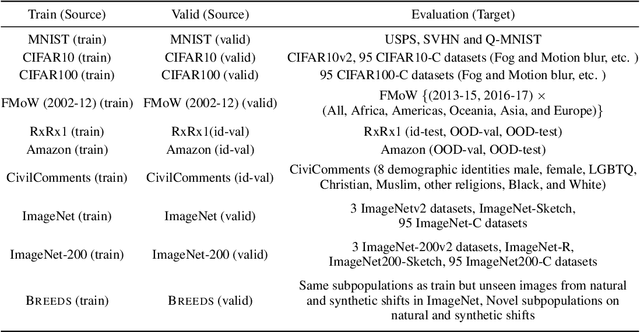
Real-world machine learning deployments are characterized by mismatches between the source (training) and target (test) distributions that may cause performance drops. In this work, we investigate methods for predicting the target domain accuracy using only labeled source data and unlabeled target data. We propose Average Thresholded Confidence (ATC), a practical method that learns a threshold on the model's confidence, predicting accuracy as the fraction of unlabeled examples for which model confidence exceeds that threshold. ATC outperforms previous methods across several model architectures, types of distribution shifts (e.g., due to synthetic corruptions, dataset reproduction, or novel subpopulations), and datasets (Wilds, ImageNet, Breeds, CIFAR, and MNIST). In our experiments, ATC estimates target performance $2$-$4\times$ more accurately than prior methods. We also explore the theoretical foundations of the problem, proving that, in general, identifying the accuracy is just as hard as identifying the optimal predictor and thus, the efficacy of any method rests upon (perhaps unstated) assumptions on the nature of the shift. Finally, analyzing our method on some toy distributions, we provide insights concerning when it works.
Explain, Edit, and Understand: Rethinking User Study Design for Evaluating Model Explanations
Dec 17, 2021

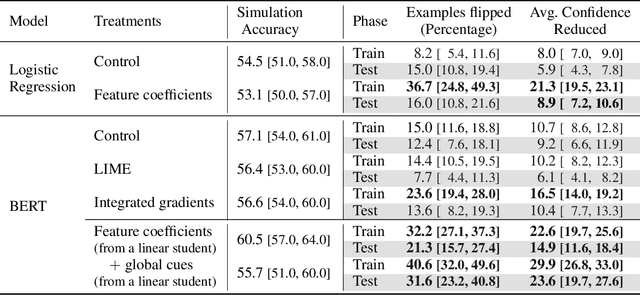
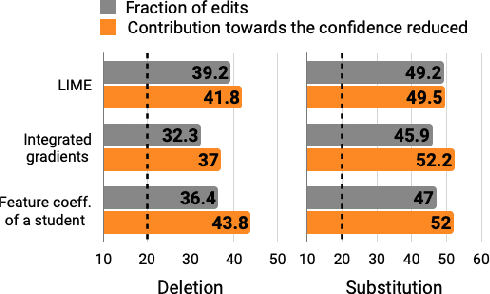
In attempts to "explain" predictions of machine learning models, researchers have proposed hundreds of techniques for attributing predictions to features that are deemed important. While these attributions are often claimed to hold the potential to improve human "understanding" of the models, surprisingly little work explicitly evaluates progress towards this aspiration. In this paper, we conduct a crowdsourcing study, where participants interact with deception detection models that have been trained to distinguish between genuine and fake hotel reviews. They are challenged both to simulate the model on fresh reviews, and to edit reviews with the goal of lowering the probability of the originally predicted class. Successful manipulations would lead to an adversarial example. During the training (but not the test) phase, input spans are highlighted to communicate salience. Through our evaluation, we observe that for a linear bag-of-words model, participants with access to the feature coefficients during training are able to cause a larger reduction in model confidence in the testing phase when compared to the no-explanation control. For the BERT-based classifier, popular local explanations do not improve their ability to reduce the model confidence over the no-explanation case. Remarkably, when the explanation for the BERT model is given by the (global) attributions of a linear model trained to imitate the BERT model, people can effectively manipulate the model.
Mixture Proportion Estimation and PU Learning: A Modern Approach
Nov 01, 2021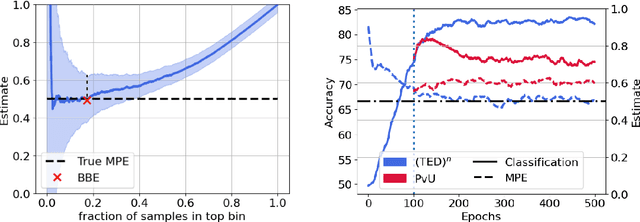
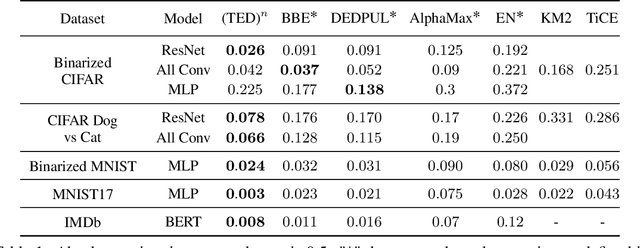
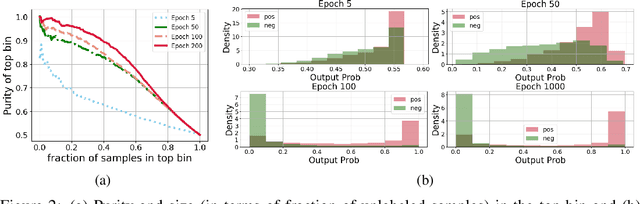
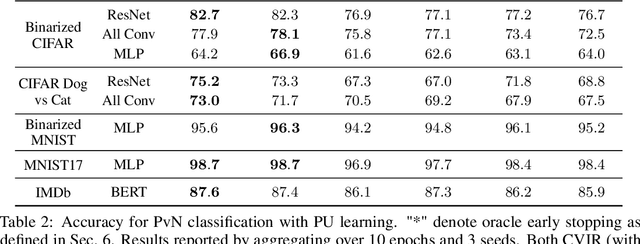
Given only positive examples and unlabeled examples (from both positive and negative classes), we might hope nevertheless to estimate an accurate positive-versus-negative classifier. Formally, this task is broken down into two subtasks: (i) Mixture Proportion Estimation (MPE) -- determining the fraction of positive examples in the unlabeled data; and (ii) PU-learning -- given such an estimate, learning the desired positive-versus-negative classifier. Unfortunately, classical methods for both problems break down in high-dimensional settings. Meanwhile, recently proposed heuristics lack theoretical coherence and depend precariously on hyperparameter tuning. In this paper, we propose two simple techniques: Best Bin Estimation (BBE) (for MPE); and Conditional Value Ignoring Risk (CVIR), a simple objective for PU-learning. Both methods dominate previous approaches empirically, and for BBE, we establish formal guarantees that hold whenever we can train a model to cleanly separate out a small subset of positive examples. Our final algorithm (TED)$^n$, alternates between the two procedures, significantly improving both our mixture proportion estimator and classifier
Practical Benefits of Feature Feedback Under Distribution Shift
Oct 14, 2021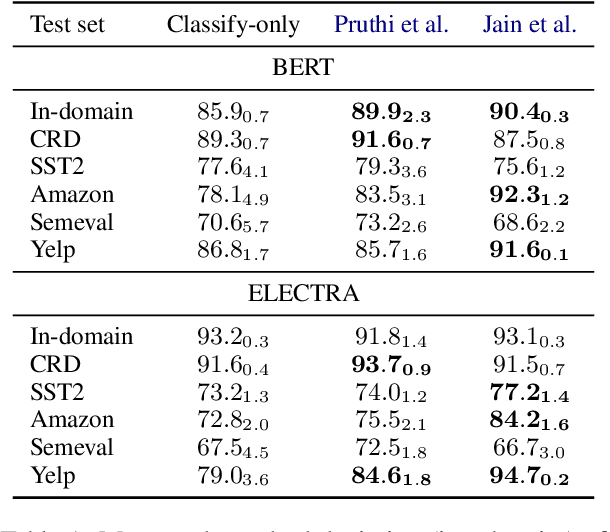
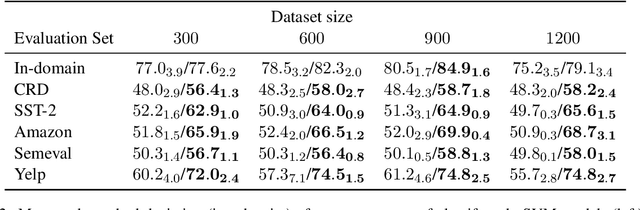
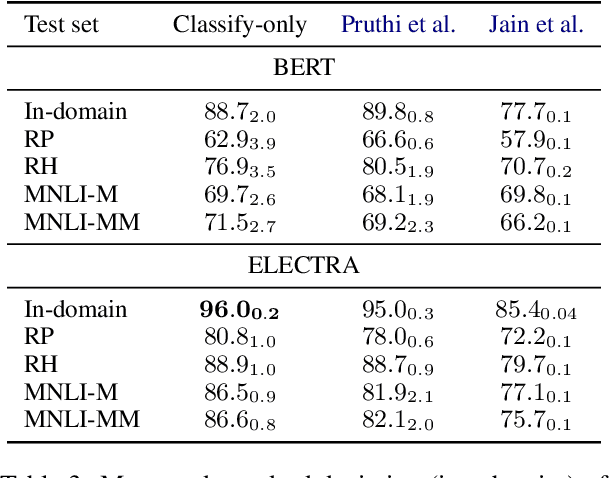
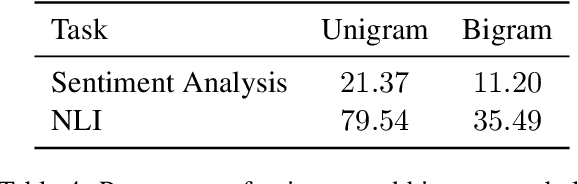
In attempts to develop sample-efficient algorithms, researcher have explored myriad mechanisms for collecting and exploiting feature feedback, auxiliary annotations provided for training (but not test) instances that highlight salient evidence. Examples include bounding boxes around objects and salient spans in text. Despite its intuitive appeal, feature feedback has not delivered significant gains in practical problems as assessed on iid holdout sets. However, recent works on counterfactually augmented data suggest an alternative benefit of supplemental annotations: lessening sensitivity to spurious patterns and consequently delivering gains in out-of-domain evaluations. Inspired by these findings, we hypothesize that while the numerous existing methods for incorporating feature feedback have delivered negligible in-sample gains, they may nevertheless generalize better out-of-domain. In experiments addressing sentiment analysis, we show that feature feedback methods perform significantly better on various natural out-of-domain datasets even absent differences on in-domain evaluation. By contrast, on natural language inference tasks, performance remains comparable. Finally, we compare those tasks where feature feedback does (and does not) help.
Does Pretraining for Summarization Require Knowledge Transfer?
Sep 10, 2021
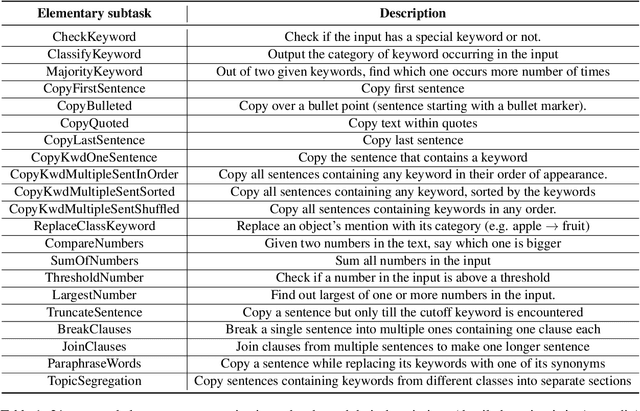
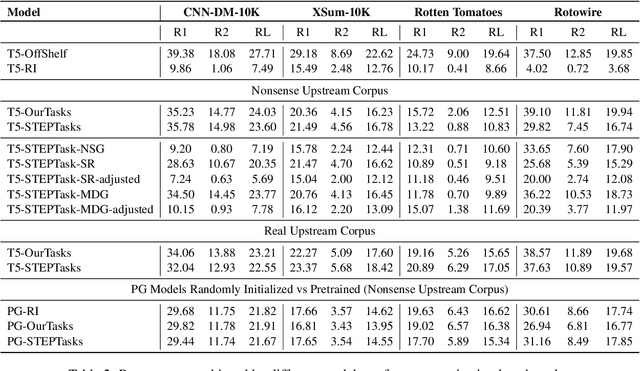
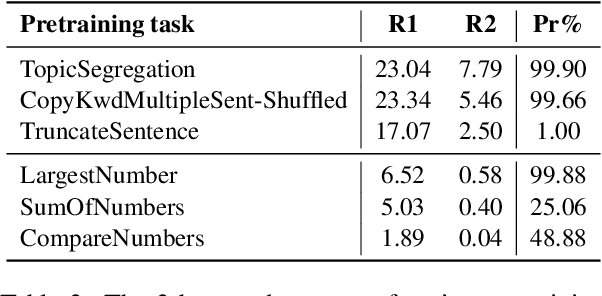
Pretraining techniques leveraging enormous datasets have driven recent advances in text summarization. While folk explanations suggest that knowledge transfer accounts for pretraining's benefits, little is known about why it works or what makes a pretraining task or dataset suitable. In this paper, we challenge the knowledge transfer story, showing that pretraining on documents consisting of character n-grams selected at random, we can nearly match the performance of models pretrained on real corpora. This work holds the promise of eliminating upstream corpora, which may alleviate some concerns over offensive language, bias, and copyright issues. To see whether the small residual benefit of using real data could be accounted for by the structure of the pretraining task, we design several tasks motivated by a qualitative study of summarization corpora. However, these tasks confer no appreciable benefit, leaving open the possibility of a small role for knowledge transfer.