 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDySem: Uncovering Dynamic Semantic Components via Multilingual Consensus for Calculating Semantic Textual Similarity
May 28, 2026Calculating semantic textual similarity is a foundational task in natural language processing. Current large language models (LLMs) based methods typically rely on extracting last-layer hidden states with fixed dimensions to compute similarity for every text pairs. We argue that this paradigm is suffer from two limitations: (i) The last hidden layer encodes more general knowledge rather than just semantic knowledge, making it suboptimal for semantic similarity computation; (ii) The hidden layer dimensions of LLMs are generally very large, which introduces some redundancy and noise for representing semantics. In this work, we propose DySem, a novel training-free framework that investigates more semantic-related internal components of LLMs via multilingual consensus, and shifts away from static representation spaces in favor of dynamic, sample-specific semantic dimensions by constructing text-dependent joint semantic set and computes similarity over this shared dimensional subset. Extensive experiments across various LLMs show that our method consistently outperforms recent baselines while maintaining lower dimensions for similarity calculation. The code is released at https://github.com/szu-tera/DySem.
SemPA: Improving Sentence Embeddings of Large Language Models through Semantic Preference Alignment
Jan 08, 2026Traditional sentence embedding methods employ token-level contrastive learning on non-generative pre-trained models. Recently, there have emerged embedding methods based on generative large language models (LLMs). These methods either rely on fixed prompt templates or involve modifications to the model architecture. The former lacks further optimization of the model and results in limited performance, while the latter alters the internal computational mechanisms of the model, thereby compromising its generative capabilities. We propose SemPA, a novel approach that boosts the sentence representations while preserving the generative ability of LLMs via semantic preference alignment. We leverage sentence-level Direct Preference Optimization (DPO) to efficiently optimize LLMs on a paraphrase generation task, where the model learns to discriminate semantically equivalent sentences while preserving inherent generative capacity. Theoretically, we establish a formal connection between DPO and contrastive learning under the Plackett-Luce model framework. Empirically, experimental results on both semantic textual similarity tasks and various benchmarks for LLMs show that SemPA achieves better semantic representations without sacrificing the inherent generation capability of LLMs.
Beyond Majority Voting: Towards Fine-grained and More Reliable Reward Signal for Test-Time Reinforcement Learning
Dec 18, 2025



Test-time reinforcement learning mitigates the reliance on annotated data by using majority voting results as pseudo-labels, emerging as a complementary direction to reinforcement learning with verifiable rewards (RLVR) for improving reasoning ability of large language models (LLMs). However, this voting strategy often induces confirmation bias and suffers from sparse rewards, limiting the overall performance. In this work, we propose subgroup-specific step-wise confidence-weighted pseudo-label estimation (SCOPE), a framework integrating model confidence and dynamic subgroup partitioning to address these issues. Specifically, SCOPE integrates the proposed step-wise confidence into pseudo label deduction, prioritizing high-quality reasoning paths over simple frequency count. Furthermore, it dynamically partitions the candidate outputs pool into independent subgroups by balancing reasoning quality against exploration diversity. By deriving local consensus via repeat sampling for each sub group, SCOPE provides diverse supervision targets to encourage broader exploration. We conduct experiments across various models and benchmarks, experimental results show that SCOPE consistently outperforms recent baselines. Notably, SCOPE achieving relative improvements of 13.1% on challenging AIME 2025 and 8.1% on AMC. The code is released at https://github.com/szu-tera/SCOPE.
Ranked Voting based Self-Consistency of Large Language Models
May 16, 2025Majority voting is considered an effective method to enhance chain-of-thought reasoning, as it selects the answer with the highest "self-consistency" among different reasoning paths (Wang et al., 2023). However, previous chain-of-thought reasoning methods typically generate only a single answer in each trial, thereby ignoring the possibility of other potential answers. As a result, these alternative answers are often overlooked in subsequent voting processes. In this work, we propose to generate ranked answers in each reasoning process and conduct ranked voting among multiple ranked answers from different responses, thereby making the overall self-consistency more reliable. Specifically, we use three ranked voting methods: Instant-runoff voting, Borda count voting, and mean reciprocal rank voting. We validate our methods on six datasets, including three multiple-choice and three open-ended question-answering tasks, using both advanced open-source and closed-source large language models. Extensive experimental results indicate that our proposed method outperforms the baselines, showcasing the potential of leveraging the information of ranked answers and using ranked voting to improve reasoning performance. The code is available at https://github.com/szu-tera/RankedVotingSC.
SkiM: Skipping Memory LSTM for Low-Latency Real-Time Continuous Speech Separation
Feb 10, 2022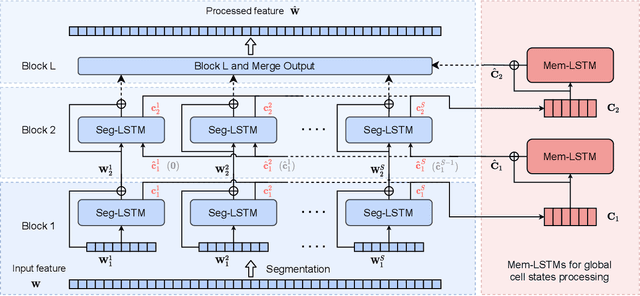
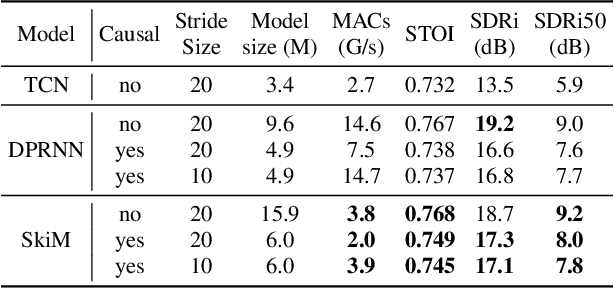
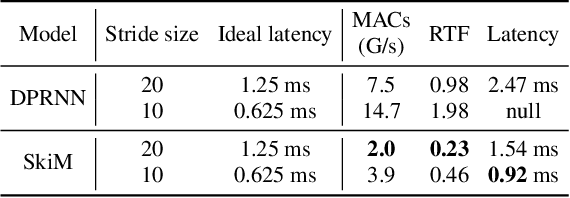
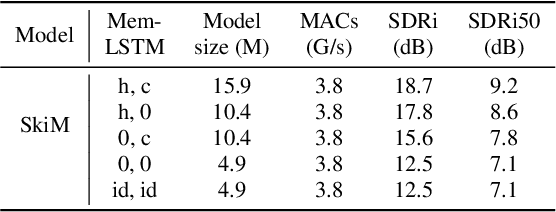
Continuous speech separation for meeting pre-processing has recently become a focused research topic. Compared to the data in utterance-level speech separation, the meeting-style audio stream lasts longer, has an uncertain number of speakers. We adopt the time-domain speech separation method and the recently proposed Graph-PIT to build a super low-latency online speech separation model, which is very important for the real application. The low-latency time-domain encoder with a small stride leads to an extremely long feature sequence. We proposed a simple yet efficient model named Skipping Memory (SkiM) for the long sequence modeling. Experimental results show that SkiM achieves on par or even better separation performance than DPRNN. Meanwhile, the computational cost of SkiM is reduced by 75% compared to DPRNN. The strong long sequence modeling capability and low computational cost make SkiM a suitable model for online CSS applications. Our fastest real-time model gets 17.1 dB signal-to-distortion (SDR) improvement with less than 1-millisecond latency in the simulated meeting-style evaluation.
Practical Benefits of Feature Feedback Under Distribution Shift
Oct 14, 2021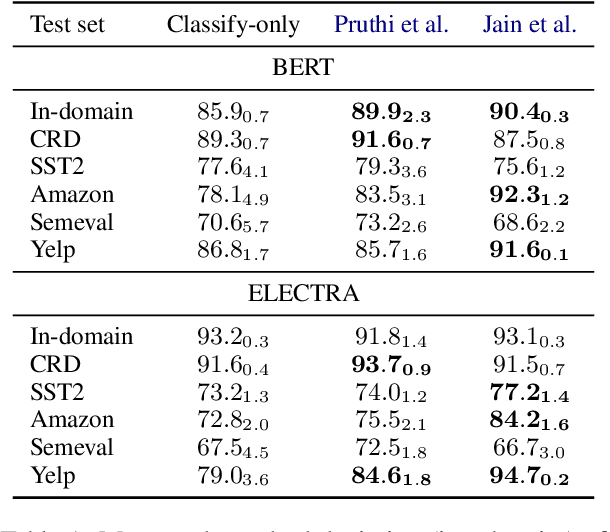
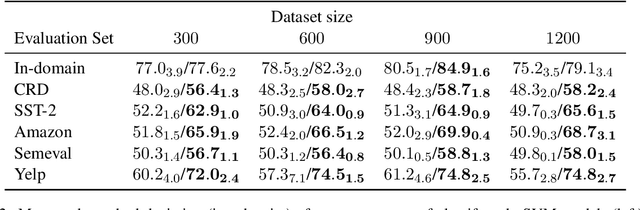
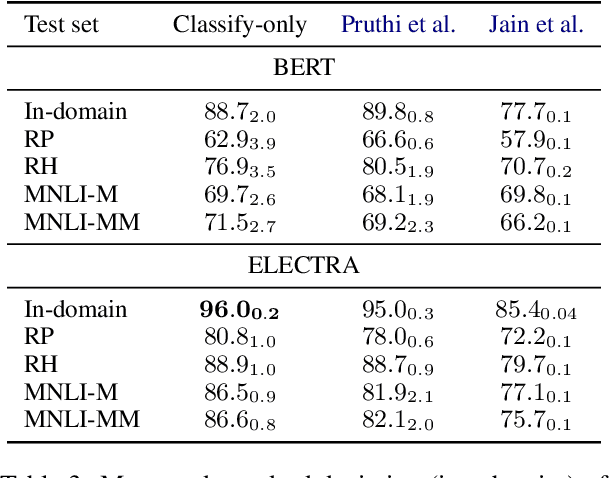
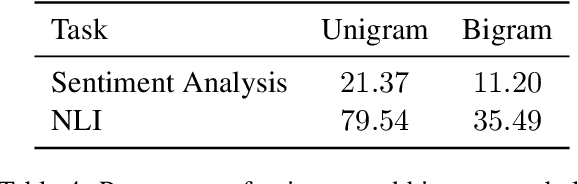
In attempts to develop sample-efficient algorithms, researcher have explored myriad mechanisms for collecting and exploiting feature feedback, auxiliary annotations provided for training (but not test) instances that highlight salient evidence. Examples include bounding boxes around objects and salient spans in text. Despite its intuitive appeal, feature feedback has not delivered significant gains in practical problems as assessed on iid holdout sets. However, recent works on counterfactually augmented data suggest an alternative benefit of supplemental annotations: lessening sensitivity to spurious patterns and consequently delivering gains in out-of-domain evaluations. Inspired by these findings, we hypothesize that while the numerous existing methods for incorporating feature feedback have delivered negligible in-sample gains, they may nevertheless generalize better out-of-domain. In experiments addressing sentiment analysis, we show that feature feedback methods perform significantly better on various natural out-of-domain datasets even absent differences on in-domain evaluation. By contrast, on natural language inference tasks, performance remains comparable. Finally, we compare those tasks where feature feedback does (and does not) help.