 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInflated 3D Convolution-Transformer for Weakly-supervised Carotid Stenosis Grading with Ultrasound Videos
Jun 12, 2023



Localization of the narrowest position of the vessel and corresponding vessel and remnant vessel delineation in carotid ultrasound (US) are essential for carotid stenosis grading (CSG) in clinical practice. However, the pipeline is time-consuming and tough due to the ambiguous boundaries of plaque and temporal variation. To automatize this procedure, a large number of manual delineations are usually required, which is not only laborious but also not reliable given the annotation difficulty. In this study, we present the first video classification framework for automatic CSG. Our contribution is three-fold. First, to avoid the requirement of laborious and unreliable annotation, we propose a novel and effective video classification network for weakly-supervised CSG. Second, to ease the model training, we adopt an inflation strategy for the network, where pre-trained 2D convolution weights can be adapted into the 3D counterpart in our network for an effective warm start. Third, to enhance the feature discrimination of the video, we propose a novel attention-guided multi-dimension fusion (AMDF) transformer encoder to model and integrate global dependencies within and across spatial and temporal dimensions, where two lightweight cross-dimensional attention mechanisms are designed. Our approach is extensively validated on a large clinically collected carotid US video dataset, demonstrating state-of-the-art performance compared with strong competitors.
Agent with Tangent-based Formulation and Anatomical Perception for Standard Plane Localization in 3D Ultrasound
Jul 01, 2022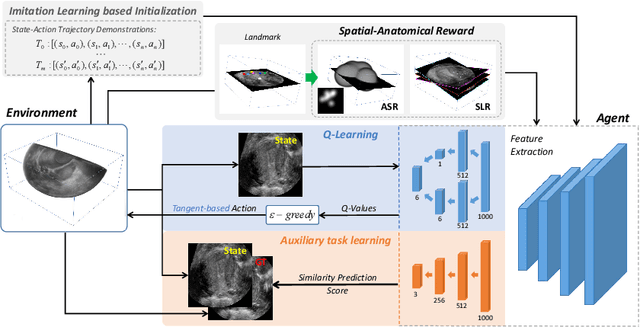
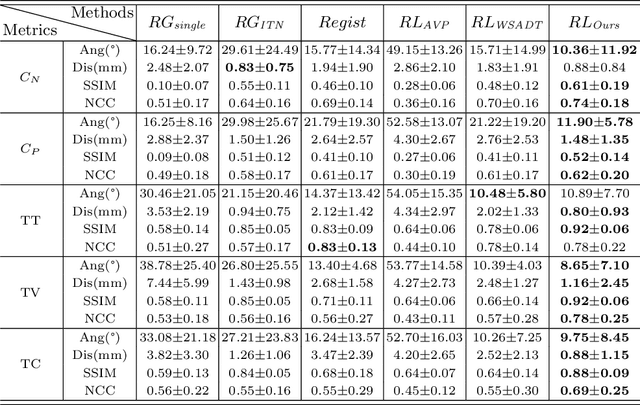
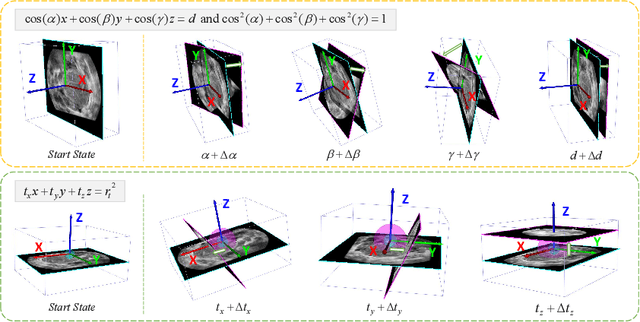
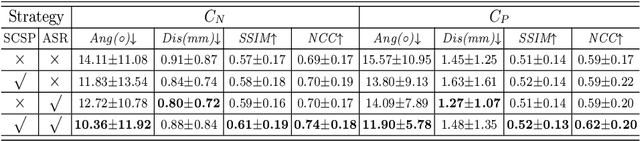
Standard plane (SP) localization is essential in routine clinical ultrasound (US) diagnosis. Compared to 2D US, 3D US can acquire multiple view planes in one scan and provide complete anatomy with the addition of coronal plane. However, manually navigating SPs in 3D US is laborious and biased due to the orientation variability and huge search space. In this study, we introduce a novel reinforcement learning (RL) framework for automatic SP localization in 3D US. Our contribution is three-fold. First, we formulate SP localization in 3D US as a tangent-point-based problem in RL to restructure the action space and significantly reduce the search space. Second, we design an auxiliary task learning strategy to enhance the model's ability to recognize subtle differences crossing Non-SPs and SPs in plane search. Finally, we propose a spatial-anatomical reward to effectively guide learning trajectories by exploiting spatial and anatomical information simultaneously. We explore the efficacy of our approach on localizing four SPs on uterus and fetal brain datasets. The experiments indicate that our approach achieves a high localization accuracy as well as robust performance.
Ultra Light OCR Competition Technical Report
Oct 25, 2021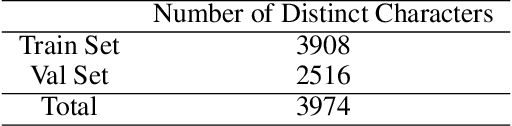
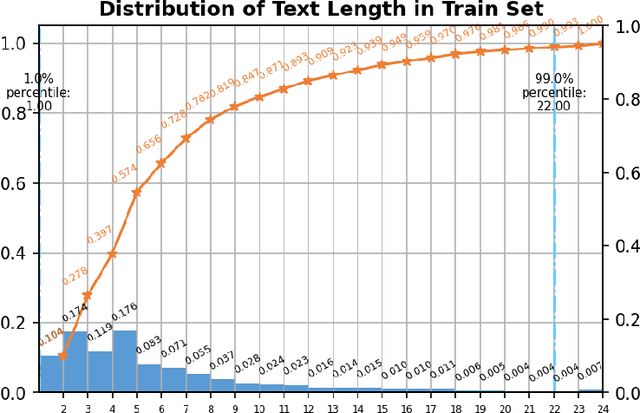

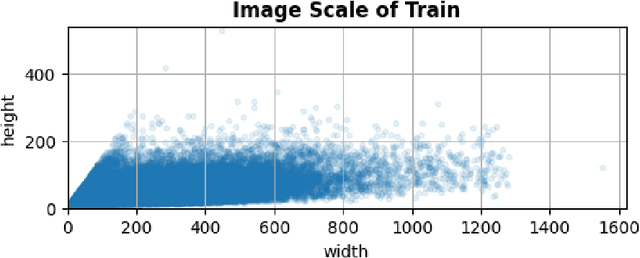
Ultra Light OCR Competition is a Chinese scene text recognition competition jointly organized by CSIG (China Society of Image and Graphics) and Baidu, Inc. In addition to focusing on common problems in Chinese scene text recognition, such as long text length and massive characters, we need to balance the trade-off of model scale and accuracy since the model size limitation in the competition is 10M. From experiments in aspects of data, model, training, etc, we proposed a general and effective method for Chinese scene text recognition, which got us second place among over 100 teams with accuracy 0.817 in TestB dataset. The code is available at https://aistudio.baidu.com/aistudio/projectdetail/2159102.
Self Context and Shape Prior for Sensorless Freehand 3D Ultrasound Reconstruction
Aug 18, 2021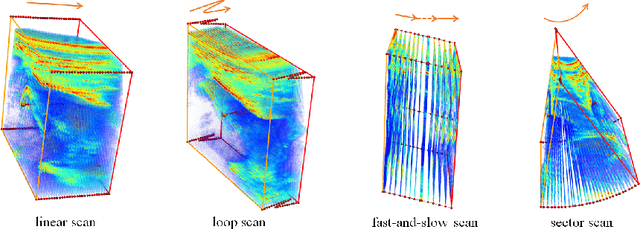
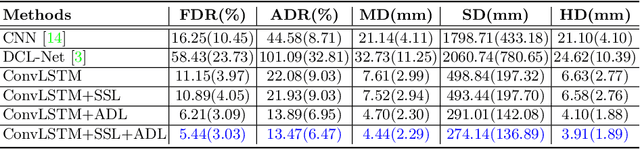
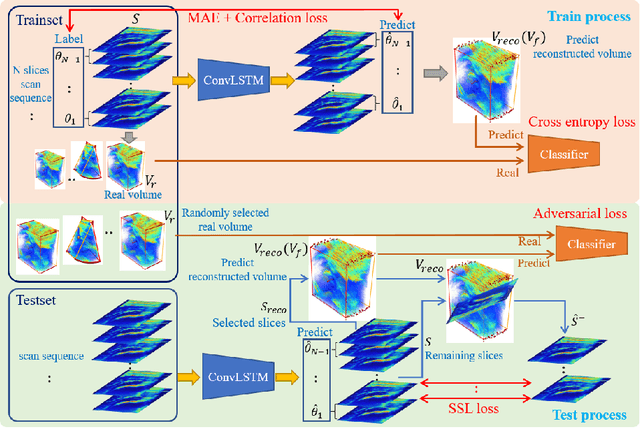
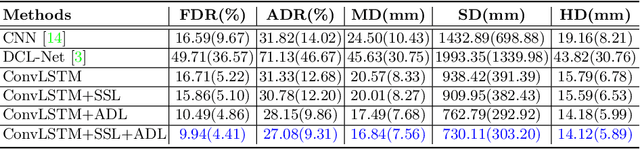
3D ultrasound (US) is widely used for its rich diagnostic information. However, it is criticized for its limited field of view. 3D freehand US reconstruction is promising in addressing the problem by providing broad range and freeform scan. The existing deep learning based methods only focus on the basic cases of skill sequences, and the model relies on the training data heavily. The sequences in real clinical practice are a mix of diverse skills and have complex scanning paths. Besides, deep models should adapt themselves to the testing cases with prior knowledge for better robustness, rather than only fit to the training cases. In this paper, we propose a novel approach to sensorless freehand 3D US reconstruction considering the complex skill sequences. Our contribution is three-fold. First, we advance a novel online learning framework by designing a differentiable reconstruction algorithm. It realizes an end-to-end optimization from section sequences to the reconstructed volume. Second, a self-supervised learning method is developed to explore the context information that reconstructed by the testing data itself, promoting the perception of the model. Third, inspired by the effectiveness of shape prior, we also introduce adversarial training to strengthen the learning of anatomical shape prior in the reconstructed volume. By mining the context and structural cues of the testing data, our online learning methods can drive the model to handle complex skill sequences. Experimental results on developmental dysplasia of the hip US and fetal US datasets show that, our proposed method can outperform the start-of-the-art methods regarding the shift errors and path similarities.
Flip Learning: Erase to Segment
Aug 02, 2021
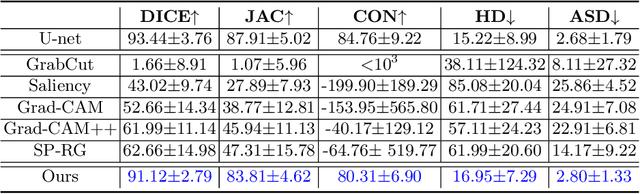
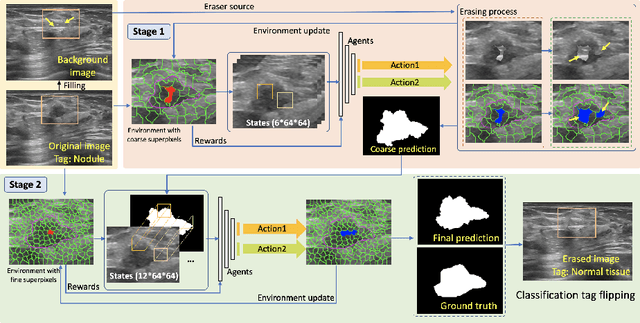
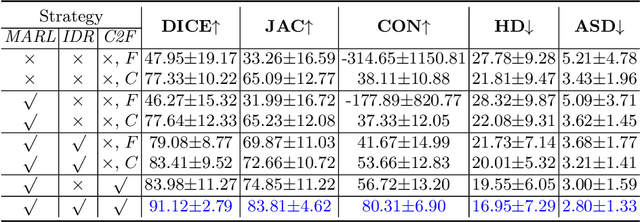
Nodule segmentation from breast ultrasound images is challenging yet essential for the diagnosis. Weakly-supervised segmentation (WSS) can help reduce time-consuming and cumbersome manual annotation. Unlike existing weakly-supervised approaches, in this study, we propose a novel and general WSS framework called Flip Learning, which only needs the box annotation. Specifically, the target in the label box will be erased gradually to flip the classification tag, and the erased region will be considered as the segmentation result finally. Our contribution is three-fold. First, our proposed approach erases on superpixel level using a Multi-agent Reinforcement Learning framework to exploit the prior boundary knowledge and accelerate the learning process. Second, we design two rewards: classification score and intensity distribution reward, to avoid under- and over-segmentation, respectively. Third, we adopt a coarse-to-fine learning strategy to reduce the residual errors and improve the segmentation performance. Extensively validated on a large dataset, our proposed approach achieves competitive performance and shows great potential to narrow the gap between fully-supervised and weakly-supervised learning.
RGB Stream Is Enough for Temporal Action Detection
Jul 09, 2021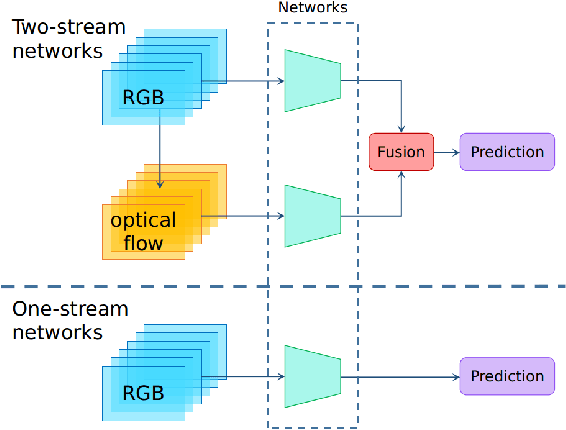
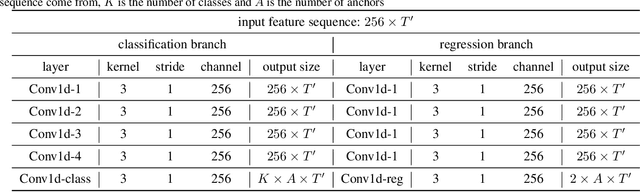
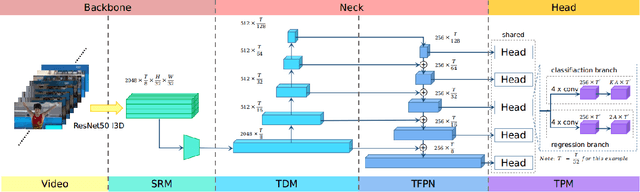
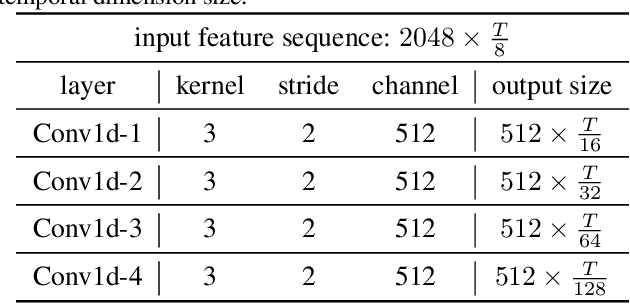
State-of-the-art temporal action detectors to date are based on two-stream input including RGB frames and optical flow. Although combining RGB frames and optical flow boosts performance significantly, optical flow is a hand-designed representation which not only requires heavy computation, but also makes it methodologically unsatisfactory that two-stream methods are often not learned end-to-end jointly with the flow. In this paper, we argue that optical flow is dispensable in high-accuracy temporal action detection and image level data augmentation (ILDA) is the key solution to avoid performance degradation when optical flow is removed. To evaluate the effectiveness of ILDA, we design a simple yet efficient one-stage temporal action detector based on single RGB stream named DaoTAD. Our results show that when trained with ILDA, DaoTAD has comparable accuracy with all existing state-of-the-art two-stream detectors while surpassing the inference speed of previous methods by a large margin and the inference speed is astounding 6668 fps on GeForce GTX 1080 Ti. Code is available at \url{https://github.com/Media-Smart/vedatad}.
Style-invariant Cardiac Image Segmentation with Test-time Augmentation
Sep 24, 2020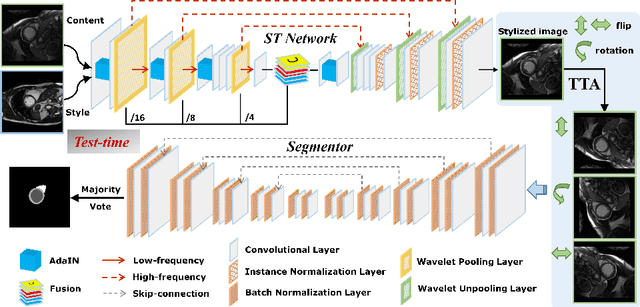
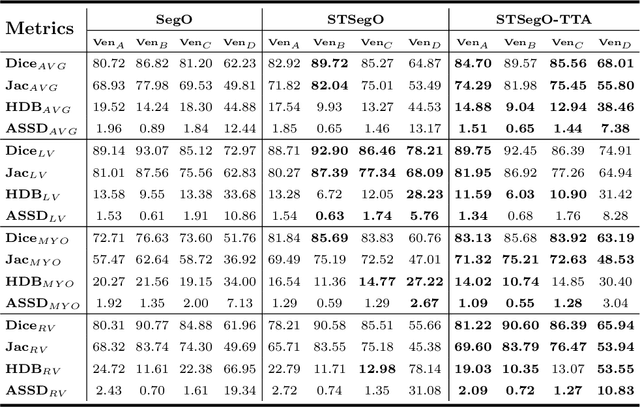
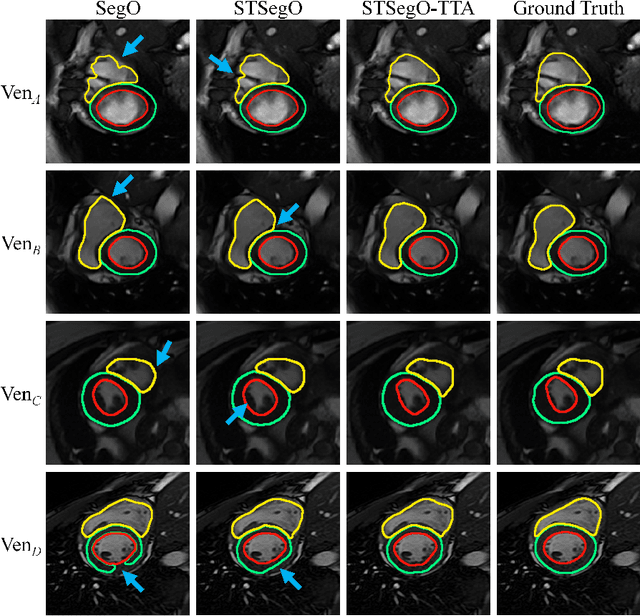
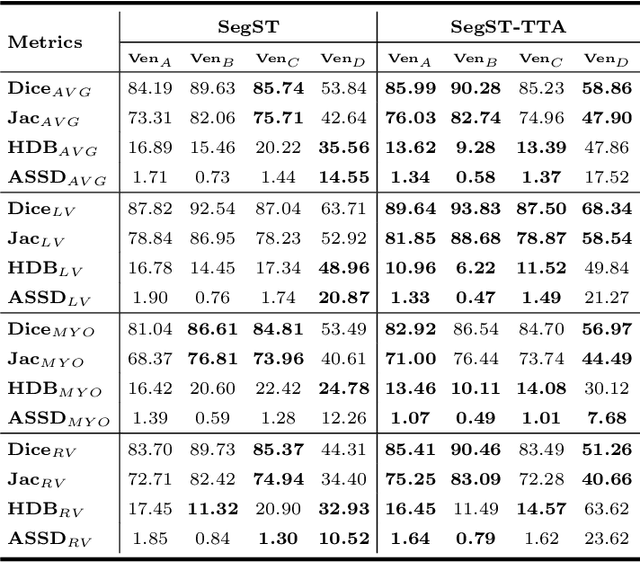
Deep models often suffer from severe performance drop due to the appearance shift in the real clinical setting. Most of the existing learning-based methods rely on images from multiple sites/vendors or even corresponding labels. However, collecting enough unknown data to robustly model segmentation cannot always hold since the complex appearance shift caused by imaging factors in daily application. In this paper, we propose a novel style-invariant method for cardiac image segmentation. Based on the zero-shot style transfer to remove appearance shift and test-time augmentation to explore diverse underlying anatomy, our proposed method is effective in combating the appearance shift. Our contribution is three-fold. First, inspired by the spirit of universal style transfer, we develop a zero-shot stylization for content images to generate stylized images that appearance similarity to the style images. Second, we build up a robust cardiac segmentation model based on the U-Net structure. Our framework mainly consists of two networks during testing: the ST network for removing appearance shift and the segmentation network. Third, we investigate test-time augmentation to explore transformed versions of the stylized image for prediction and the results are merged. Notably, our proposed framework is fully test-time adaptation. Experiment results demonstrate that our methods are promising and generic for generalizing deep segmentation models.