 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated cINN Clustering for Accurate Clustered Federated Learning
Sep 04, 2023Federated Learning (FL) presents an innovative approach to privacy-preserving distributed machine learning and enables efficient crowd intelligence on a large scale. However, a significant challenge arises when coordinating FL with crowd intelligence which diverse client groups possess disparate objectives due to data heterogeneity or distinct tasks. To address this challenge, we propose the Federated cINN Clustering Algorithm (FCCA) to robustly cluster clients into different groups, avoiding mutual interference between clients with data heterogeneity, and thereby enhancing the performance of the global model. Specifically, FCCA utilizes a global encoder to transform each client's private data into multivariate Gaussian distributions. It then employs a generative model to learn encoded latent features through maximum likelihood estimation, which eases optimization and avoids mode collapse. Finally, the central server collects converged local models to approximate similarities between clients and thus partition them into distinct clusters. Extensive experimental results demonstrate FCCA's superiority over other state-of-the-art clustered federated learning algorithms, evaluated on various models and datasets. These results suggest that our approach has substantial potential to enhance the efficiency and accuracy of real-world federated learning tasks.
TSGCNeXt: Dynamic-Static Multi-Graph Convolution for Efficient Skeleton-Based Action Recognition with Long-term Learning Potential
Apr 23, 2023



Skeleton-based action recognition has achieved remarkable results in human action recognition with the development of graph convolutional networks (GCNs). However, the recent works tend to construct complex learning mechanisms with redundant training and exist a bottleneck for long time-series. To solve these problems, we propose the Temporal-Spatio Graph ConvNeXt (TSGCNeXt) to explore efficient learning mechanism of long temporal skeleton sequences. Firstly, a new graph learning mechanism with simple structure, Dynamic-Static Separate Multi-graph Convolution (DS-SMG) is proposed to aggregate features of multiple independent topological graphs and avoid the node information being ignored during dynamic convolution. Next, we construct a graph convolution training acceleration mechanism to optimize the back-propagation computing of dynamic graph learning with 55.08\% speed-up. Finally, the TSGCNeXt restructure the overall structure of GCN with three Spatio-temporal learning modules,efficiently modeling long temporal features. In comparison with existing previous methods on large-scale datasets NTU RGB+D 60 and 120, TSGCNeXt outperforms on single-stream networks. In addition, with the ema model introduced into the multi-stream fusion, TSGCNeXt achieves SOTA levels. On the cross-subject and cross-set of the NTU 120, accuracies reach 90.22% and 91.74%.
Que2Engage: Embedding-based Retrieval for Relevant and Engaging Products at Facebook Marketplace
Feb 21, 2023Embedding-based Retrieval (EBR) in e-commerce search is a powerful search retrieval technique to address semantic matches between search queries and products. However, commercial search engines like Facebook Marketplace Search are complex multi-stage systems optimized for multiple business objectives. At Facebook Marketplace, search retrieval focuses on matching search queries with relevant products, while search ranking puts more emphasis on contextual signals to up-rank the more engaging products. As a result, the end-to-end searcher experience is a function of both relevance and engagement, and the interaction between different stages of the system. This presents challenges to EBR systems in order to optimize for better searcher experiences. In this paper we presents Que2Engage, a search EBR system built towards bridging the gap between retrieval and ranking for end-to-end optimizations. Que2Engage takes a multimodal & multitask approach to infuse contextual information into the retrieval stage and to balance different business objectives. We show the effectiveness of our approach via a multitask evaluation framework and thorough baseline comparisons and ablation studies. Que2Engage is deployed on Facebook Marketplace Search and shows significant improvements in searcher engagement in two weeks of A/B testing.
DeFTA: A Plug-and-Play Decentralized Replacement for FedAvg
Apr 06, 2022
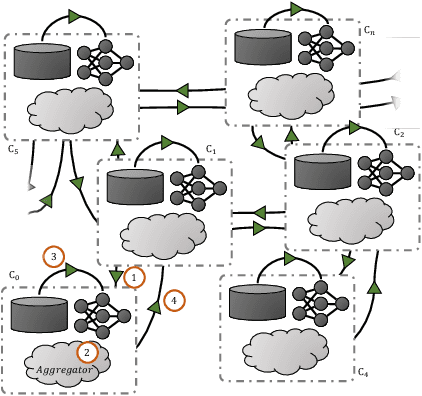
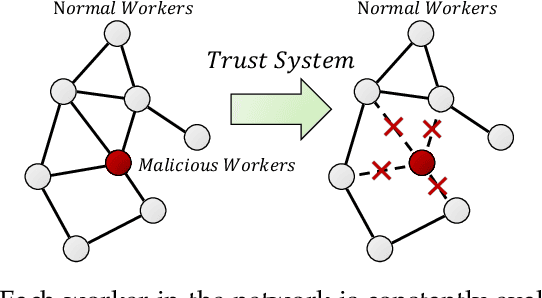
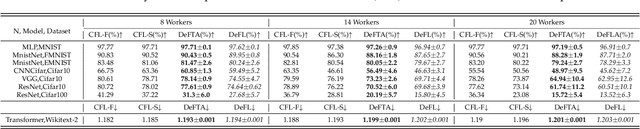
Federated learning (FL) is identified as a crucial enabler for large-scale distributed machine learning (ML) without the need for local raw dataset sharing, substantially reducing privacy concerns and alleviating the isolated data problem. In reality, the prosperity of FL is largely due to a centralized framework called FedAvg, in which workers are in charge of model training and servers are in control of model aggregation. However, FedAvg's centralized worker-server architecture has raised new concerns, be it the low scalability of the cluster, the risk of data leakage, and the failure or even defection of the central server. To overcome these problems, we propose Decentralized Federated Trusted Averaging (DeFTA), a decentralized FL framework that serves as a plug-and-play replacement for FedAvg, instantly bringing better security, scalability, and fault-tolerance to the federated learning process after installation. In principle, it fundamentally resolves the above-mentioned issues from an architectural perspective without compromises or tradeoffs, primarily consisting of a new model aggregating formula with theoretical performance analysis, and a decentralized trust system (DTS) to greatly improve system robustness. Note that since DeFTA is an alternative to FedAvg at the framework level, \textit{prevalent algorithms published for FedAvg can be also utilized in DeFTA with ease}. Extensive experiments on six datasets and six basic models suggest that DeFTA not only has comparable performance with FedAvg in a more realistic setting, but also achieves great resilience even when 66% of workers are malicious. Furthermore, we also present an asynchronous variant of DeFTA to endow it with more powerful usability.
Image Search with Text Feedback by Additive Attention Compositional Learning
Mar 08, 2022
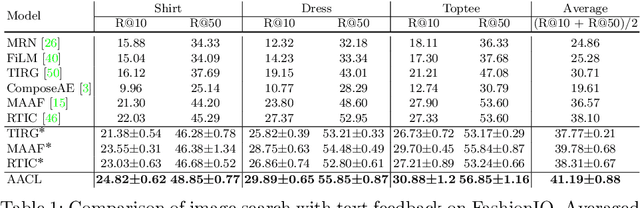
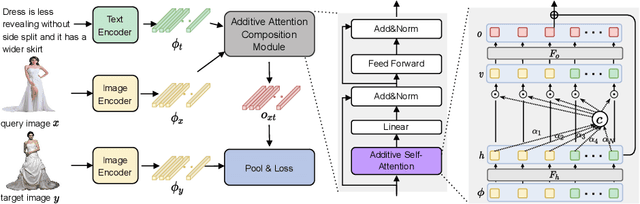
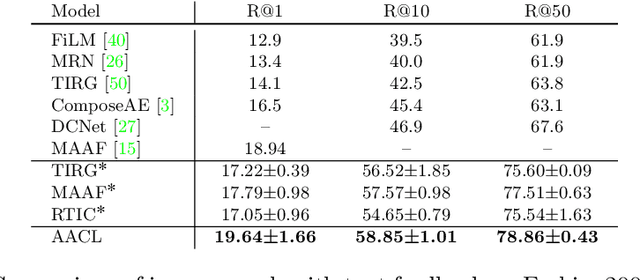
Effective image retrieval with text feedback stands to impact a range of real-world applications, such as e-commerce. Given a source image and text feedback that describes the desired modifications to that image, the goal is to retrieve the target images that resemble the source yet satisfy the given modifications by composing a multi-modal (image-text) query. We propose a novel solution to this problem, Additive Attention Compositional Learning (AACL), that uses a multi-modal transformer-based architecture and effectively models the image-text contexts. Specifically, we propose a novel image-text composition module based on additive attention that can be seamlessly plugged into deep neural networks. We also introduce a new challenging benchmark derived from the Shopping100k dataset. AACL is evaluated on three large-scale datasets (FashionIQ, Fashion200k, and Shopping100k), each with strong baselines. Extensive experiments show that AACL achieves new state-of-the-art results on all three datasets.
Hierarchical Segment-based Optimization for SLAM
Nov 07, 2021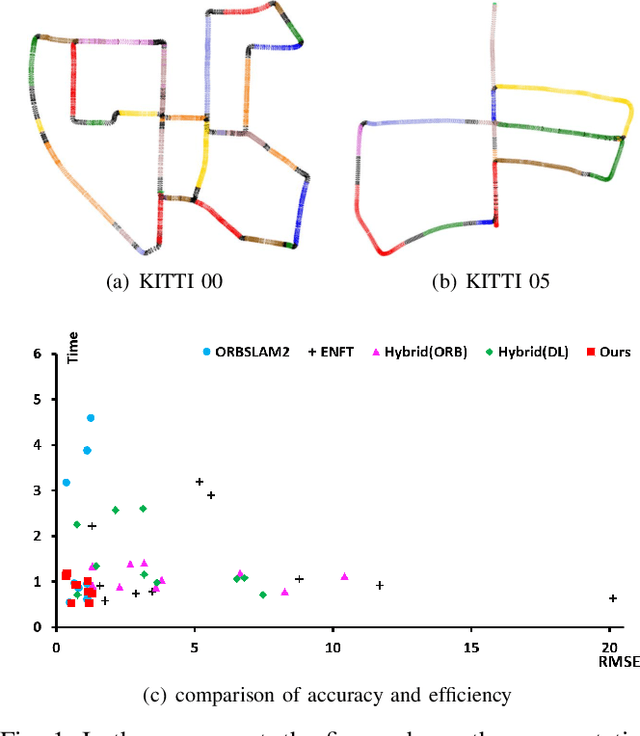
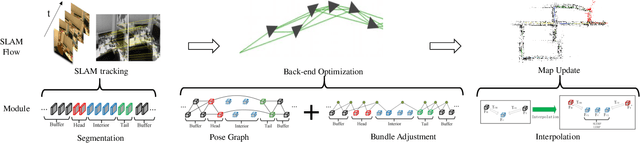
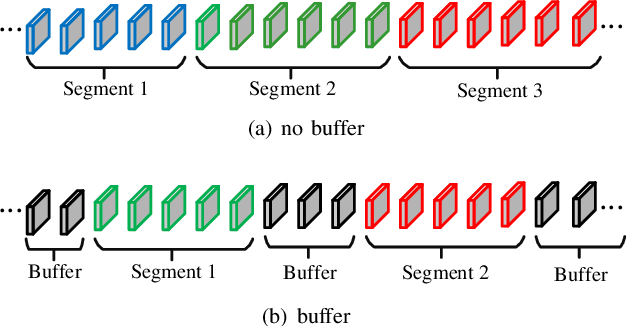
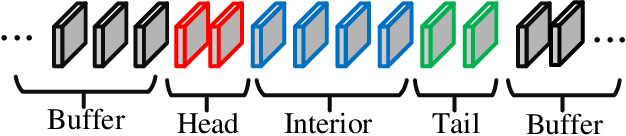
This paper presents a hierarchical segment-based optimization method for Simultaneous Localization and Mapping (SLAM) system. First we propose a reliable trajectory segmentation method that can be used to increase efficiency in the back-end optimization. Then we propose a buffer mechanism for the first time to improve the robustness of the segmentation. During the optimization, we use global information to optimize the frames with large error, and interpolation instead of optimization to update well-estimated frames to hierarchically allocate the amount of computation according to error of each frame. Comparative experiments on the benchmark show that our method greatly improves the efficiency of optimization with almost no drop in accuracy, and outperforms existing high-efficiency optimization method by a large margin.
Continual Neural Mapping: Learning An Implicit Scene Representation from Sequential Observations
Aug 12, 2021
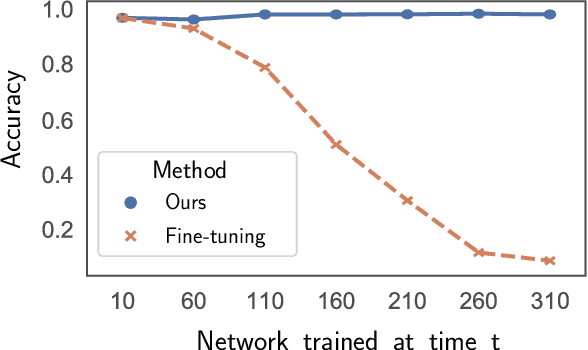
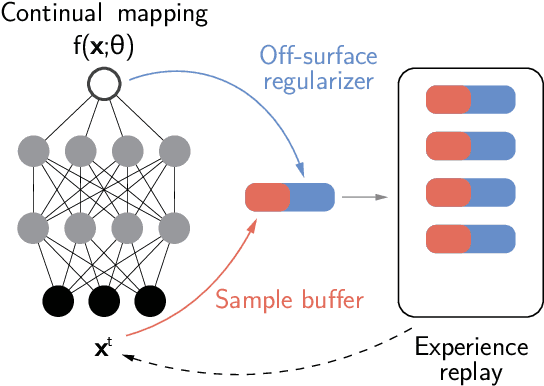
Recent advances have enabled a single neural network to serve as an implicit scene representation, establishing the mapping function between spatial coordinates and scene properties. In this paper, we make a further step towards continual learning of the implicit scene representation directly from sequential observations, namely Continual Neural Mapping. The proposed problem setting bridges the gap between batch-trained implicit neural representations and commonly used streaming data in robotics and vision communities. We introduce an experience replay approach to tackle an exemplary task of continual neural mapping: approximating a continuous signed distance function (SDF) from sequential depth images as a scene geometry representation. We show for the first time that a single network can represent scene geometry over time continually without catastrophic forgetting, while achieving promising trade-offs between accuracy and efficiency.
AutoAdapt: Automated Segmentation Network Search for Unsupervised Domain Adaptation
Jun 24, 2021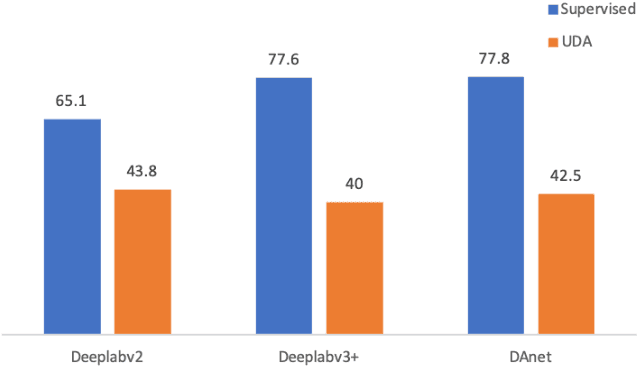
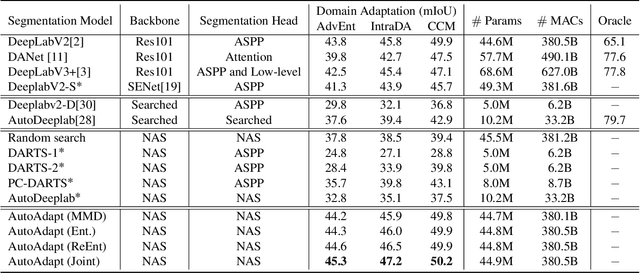
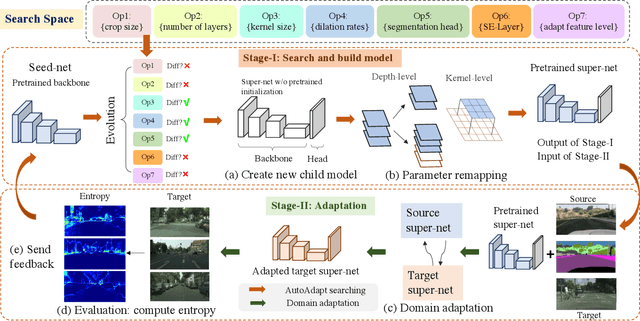
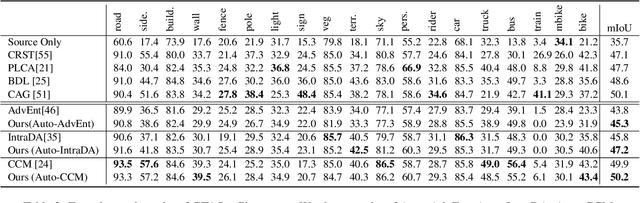
Neural network-based semantic segmentation has achieved remarkable results when large amounts of annotated data are available, that is, in the supervised case. However, such data is expensive to collect and so methods have been developed to adapt models trained on related, often synthetic data for which labels are readily available. Current adaptation approaches do not consider the dependence of the generalization/transferability of these models on network architecture. In this paper, we perform neural architecture search (NAS) to provide architecture-level perspective and analysis for domain adaptation. We identify the optimization gap that exists when searching architectures for unsupervised domain adaptation which makes this NAS problem uniquely difficult. We propose bridging this gap by using maximum mean discrepancy and regional weighted entropy to estimate the accuracy metric. Experimental results on several widely adopted benchmarks show that our proposed AutoAdapt framework indeed discovers architectures that improve the performance of a number of existing adaptation techniques.
Discriminative and Semantic Feature Selection for Place Recognition towards Dynamic Environments
Mar 21, 2021
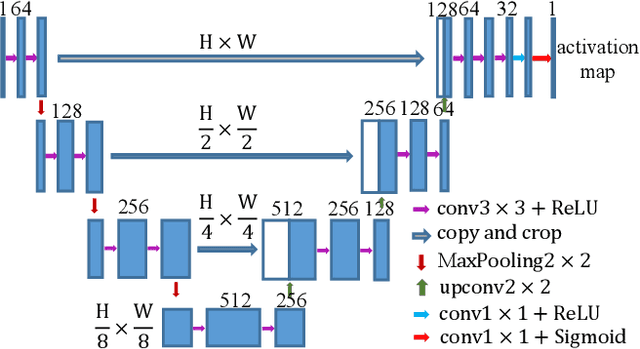
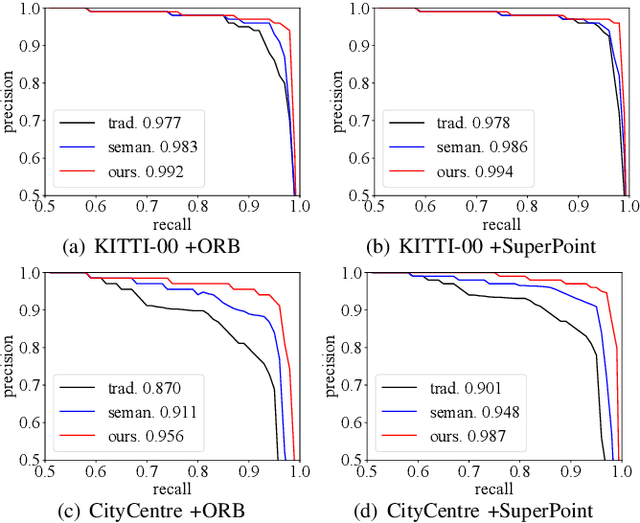
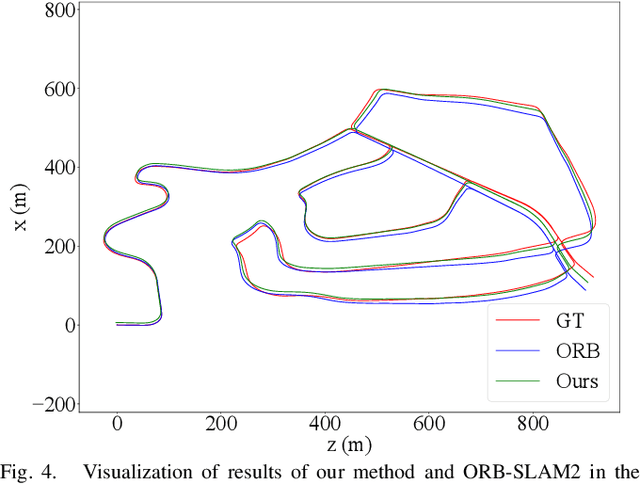
Features play an important role in various visual tasks, especially in visual place recognition applied in perceptual changing environments. In this paper, we address the challenges of place recognition due to dynamics and confusable patterns by proposing a discriminative and semantic feature selection network, dubbed as DSFeat. Supervised by both semantic information and attention mechanism, we can estimate pixel-wise stability of features, indicating the probability of a static and stable region from which features are extracted, and then select features that are insensitive to dynamic interference and distinguishable to be correctly matched. The designed feature selection model is evaluated in place recognition and SLAM system in several public datasets with varying appearances and viewpoints. Experimental results conclude that the effectiveness of the proposed method. It should be noticed that our proposal can be readily pluggable into any feature-based SLAM system.
A Collaborative Visual SLAM Framework for Service Robots
Feb 05, 2021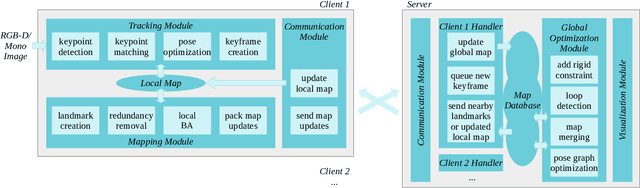
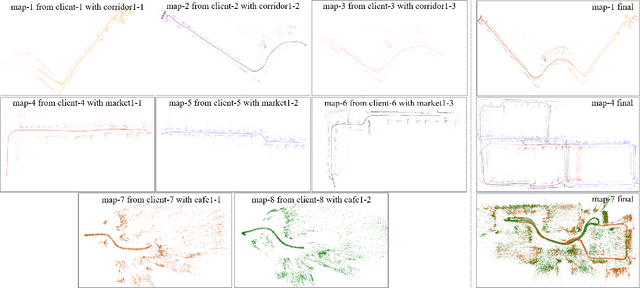
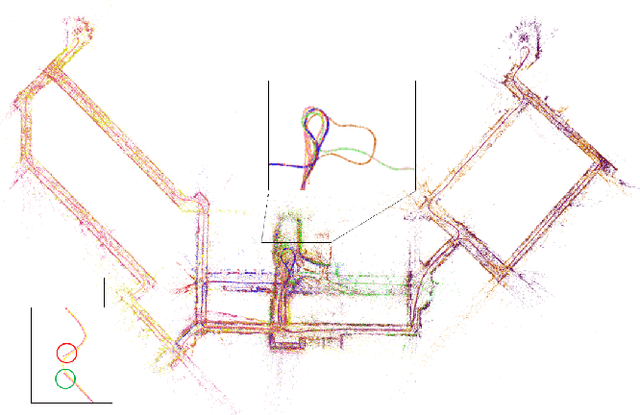
With the rapid deployment of service robots, a method should be established to allow multiple robots to work in the same place to collaborate and share the spatial information. To this end, we present a collaborative visual simultaneous localization and mapping (SLAM) framework particularly designed for service robot scenarios. With an edge server maintaining a map database and performing global optimization, each robot can register to an existing map, update the map, or build new maps, all with a unified interface and low computation and memory cost. To enable real-time information sharing, an efficient landmark retrieval method is proposed to allow each robot to get nearby landmarks observed by others. The framework is general enough to support both RGB-D and monocular cameras, as well as robots with multiple cameras, taking the rigid constraints between cameras into consideration. The proposed framework has been fully implemented and verified with public datasets and live experiments.