 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCo-Sight: Enhancing LLM-Based Agents via Conflict-Aware Meta-Verification and Trustworthy Reasoning with Structured Facts
Oct 24, 2025Long-horizon reasoning in LLM-based agents often fails not from generative weakness but from insufficient verification of intermediate reasoning. Co-Sight addresses this challenge by turning reasoning into a falsifiable and auditable process through two complementary mechanisms: Conflict-Aware Meta-Verification (CAMV) and Trustworthy Reasoning with Structured Facts (TRSF). CAMV reformulates verification as conflict identification and targeted falsification, allocating computation only to disagreement hotspots among expert agents rather than to full reasoning chains. This bounds verification cost to the number of inconsistencies and improves efficiency and reliability. TRSF continuously organizes, validates, and synchronizes evidence across agents through a structured facts module. By maintaining verified, traceable, and auditable knowledge, it ensures that all reasoning is grounded in consistent, source-verified information and supports transparent verification throughout the reasoning process. Together, TRSF and CAMV form a closed verification loop, where TRSF supplies structured facts and CAMV selectively falsifies or reinforces them, yielding transparent and trustworthy reasoning. Empirically, Co-Sight achieves state-of-the-art accuracy on GAIA (84.4%) and Humanity's Last Exam (35.5%), and strong results on Chinese-SimpleQA (93.8%). Ablation studies confirm that the synergy between structured factual grounding and conflict-aware verification drives these improvements. Co-Sight thus offers a scalable paradigm for reliable long-horizon reasoning in LLM-based agents. Code is available at https://github.com/ZTE-AICloud/Co-Sight/tree/cosight2.0_benchmarks.
EmbodiedBrain: Expanding Performance Boundaries of Task Planning for Embodied Intelligence
Oct 23, 2025



The realization of Artificial General Intelligence (AGI) necessitates Embodied AI agents capable of robust spatial perception, effective task planning, and adaptive execution in physical environments. However, current large language models (LLMs) and multimodal LLMs (MLLMs) for embodied tasks suffer from key limitations, including a significant gap between model design and agent requirements, an unavoidable trade-off between real-time latency and performance, and the use of unauthentic, offline evaluation metrics. To address these challenges, we propose EmbodiedBrain, a novel vision-language foundation model available in both 7B and 32B parameter sizes. Our framework features an agent-aligned data structure and employs a powerful training methodology that integrates large-scale Supervised Fine-Tuning (SFT) with Step-Augumented Group Relative Policy Optimization (Step-GRPO), which boosts long-horizon task success by integrating preceding steps as Guided Precursors. Furthermore, we incorporate a comprehensive reward system, including a Generative Reward Model (GRM) accelerated at the infrastructure level, to improve training efficiency. For enable thorough validation, we establish a three-part evaluation system encompassing General, Planning, and End-to-End Simulation Benchmarks, highlighted by the proposal and open-sourcing of a novel, challenging simulation environment. Experimental results demonstrate that EmbodiedBrain achieves superior performance across all metrics, establishing a new state-of-the-art for embodied foundation models. Towards paving the way for the next generation of generalist embodied agents, we open-source all of our data, model weight, and evaluating methods, which are available at https://zterobot.github.io/EmbodiedBrain.github.io.
Rethinking the Generation of High-Quality CoT Data from the Perspective of LLM-Adaptive Question Difficulty Grading
Apr 16, 2025



Recently, DeepSeek-R1 (671B) (DeepSeek-AIet al., 2025) has demonstrated its excellent reasoning ability in complex tasks and has publiclyshared its methodology. This provides potentially high-quality chain-of-thought (CoT) data for stimulating the reasoning abilities of small-sized large language models (LLMs). To generate high-quality CoT data for different LLMs, we seek an efficient method for generating high-quality CoT data with LLM-Adaptive questiondifficulty levels. First, we grade the difficulty of the questions according to the reasoning ability of the LLMs themselves and construct a LLM-Adaptive question database. Second, we sample the problem database based on a distribution of difficulty levels of the questions and then use DeepSeek-R1 (671B) (DeepSeek-AI et al., 2025) to generate the corresponding high-quality CoT data with correct answers. Thanks to the construction of CoT data with LLM-Adaptive difficulty levels, we have significantly reduced the cost of data generation and enhanced the efficiency of model supervised fine-tuning (SFT). Finally, we have validated the effectiveness and generalizability of the proposed method in the fields of complex mathematical competitions and code generation tasks. Notably, with only 2k high-quality mathematical CoT data, our ZMath-32B surpasses DeepSeek-Distill-32B in math reasoning task. Similarly, with only 2k high-quality code CoT data, our ZCode-32B surpasses DeepSeek-Distill-32B in code reasoning tasks.
DemosaicFormer: Coarse-to-Fine Demosaicing Network for HybridEVS Camera
Jun 12, 2024



Hybrid Event-Based Vision Sensor (HybridEVS) is a novel sensor integrating traditional frame-based and event-based sensors, offering substantial benefits for applications requiring low-light, high dynamic range, and low-latency environments, such as smartphones and wearable devices. Despite its potential, the lack of Image signal processing (ISP) pipeline specifically designed for HybridEVS poses a significant challenge. To address this challenge, in this study, we propose a coarse-to-fine framework named DemosaicFormer which comprises coarse demosaicing and pixel correction. Coarse demosaicing network is designed to produce a preliminary high-quality estimate of the RGB image from the HybridEVS raw data while the pixel correction network enhances the performance of image restoration and mitigates the impact of defective pixels. Our key innovation is the design of a Multi-Scale Gating Module (MSGM) applying the integration of cross-scale features, which allows feature information to flow between different scales. Additionally, the adoption of progressive training and data augmentation strategies further improves model's robustness and effectiveness. Experimental results show superior performance against the existing methods both qualitatively and visually, and our DemosaicFormer achieves the best performance in terms of all the evaluation metrics in the MIPI 2024 challenge on Demosaic for Hybridevs Camera. The code is available at https://github.com/QUEAHREN/DemosaicFormer.
MIPI 2024 Challenge on Demosaic for HybridEVS Camera: Methods and Results
May 08, 2024



The increasing demand for computational photography and imaging on mobile platforms has led to the widespread development and integration of advanced image sensors with novel algorithms in camera systems. However, the scarcity of high-quality data for research and the rare opportunity for in-depth exchange of views from industry and academia constrain the development of mobile intelligent photography and imaging (MIPI). Building on the achievements of the previous MIPI Workshops held at ECCV 2022 and CVPR 2023, we introduce our third MIPI challenge including three tracks focusing on novel image sensors and imaging algorithms. In this paper, we summarize and review the Nighttime Flare Removal track on MIPI 2024. In total, 170 participants were successfully registered, and 14 teams submitted results in the final testing phase. The developed solutions in this challenge achieved state-of-the-art performance on Nighttime Flare Removal. More details of this challenge and the link to the dataset can be found at https://mipi-challenge.org/MIPI2024/.
Revisiting Single Image Reflection Removal In the Wild
Nov 29, 2023This research focuses on the issue of single-image reflection removal (SIRR) in real-world conditions, examining it from two angles: the collection pipeline of real reflection pairs and the perception of real reflection locations. We devise an advanced reflection collection pipeline that is highly adaptable to a wide range of real-world reflection scenarios and incurs reduced costs in collecting large-scale aligned reflection pairs. In the process, we develop a large-scale, high-quality reflection dataset named Reflection Removal in the Wild (RRW). RRW contains over 14,950 high-resolution real-world reflection pairs, a dataset forty-five times larger than its predecessors. Regarding perception of reflection locations, we identify that numerous virtual reflection objects visible in reflection images are not present in the corresponding ground-truth images. This observation, drawn from the aligned pairs, leads us to conceive the Maximum Reflection Filter (MaxRF). The MaxRF could accurately and explicitly characterize reflection locations from pairs of images. Building upon this, we design a reflection location-aware cascaded framework, specifically tailored for SIRR. Powered by these innovative techniques, our solution achieves superior performance than current leading methods across multiple real-world benchmarks. Codes and datasets will be publicly available.
Model Generalization: A Sharpness Aware Optimization Perspective
Aug 14, 2022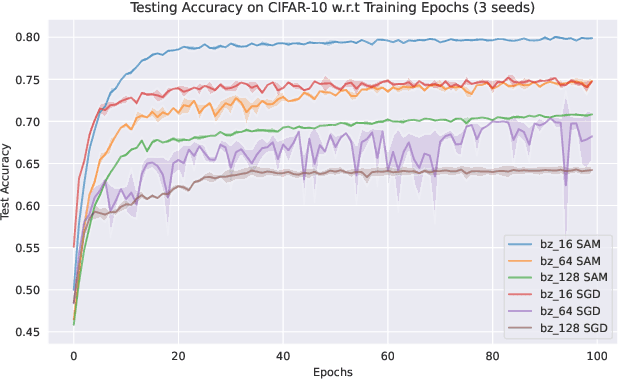
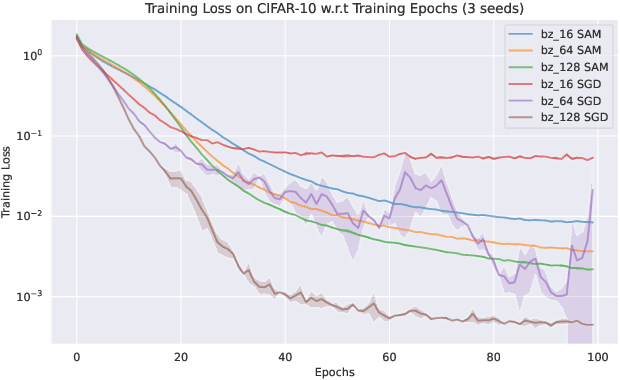
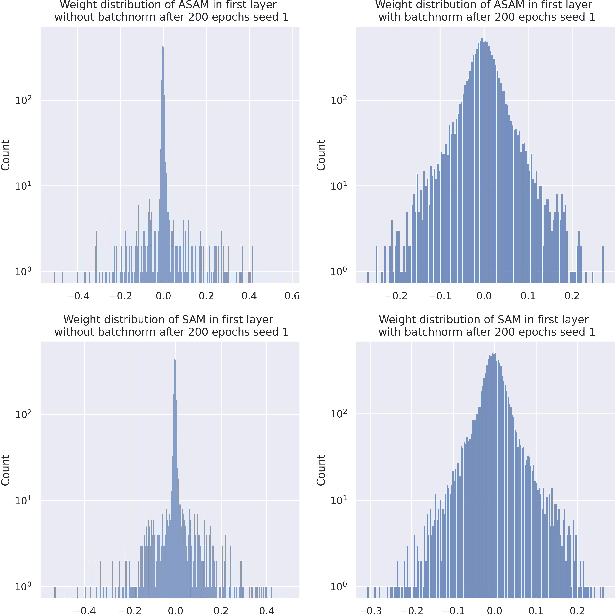
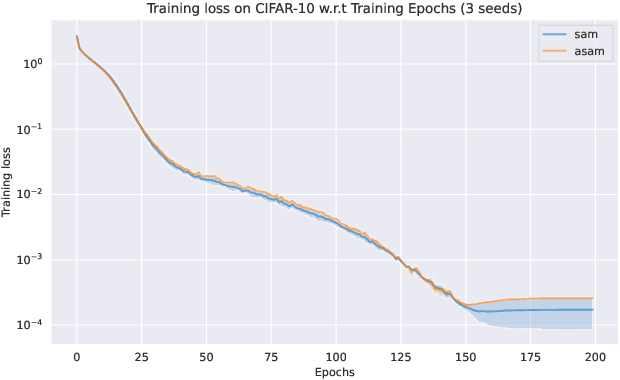
Sharpness-Aware Minimization (SAM) and adaptive sharpness-aware minimization (ASAM) aim to improve the model generalization. And in this project, we proposed three experiments to valid their generalization from the sharpness aware perspective. And our experiments show that sharpness aware-based optimization techniques could help to provide models with strong generalization ability. Our experiments also show that ASAM could improve the generalization performance on un-normalized data, but further research is needed to confirm this.