 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Textual Knowledge for Enhanced Image Clustering
Apr 13, 2026Image clustering aims to group images in an unsupervised fashion. Traditional methods focus on knowledge from visual space, making it difficult to distinguish between visually similar but semantically different classes. Recent advances in vision-language models enable the use of textual knowledge to enhance image clustering. However, most existing methods rely on coarse class labels or simple nouns, overlooking the rich conceptual and attribute-level semantics embedded in textual space. In this paper, we propose a knowledge-enhanced clustering (KEC) method that constructs a hierarchical concept-attribute structured knowledge with the help of large language models (LLMs) to guide clustering. Specifically, we first condense redundant textual labels into abstract concepts and then automatically extract discriminative attributes for each single concept and similar concept pairs, via structured prompts to LLMs. This knowledge is instantiated for each input image to achieve the knowledge-enhanced features. The knowledge-enhanced features with original visual features are adapted to various downstream clustering algorithms. We evaluate KEC on 20 diverse datasets, showing consistent improvements across existing methods using additional textual knowledge. KEC without training outperforms zero-shot CLIP on 14 out of 20 datasets. Furthermore, the naive use of textual knowledge may harm clustering performance, while KEC provides both accuracy and robustness.
HingeMem: Boundary Guided Long-Term Memory with Query Adaptive Retrieval for Scalable Dialogues
Apr 08, 2026Long-term memory is critical for dialogue systems that support continuous, sustainable, and personalized interactions. However, existing methods rely on continuous summarization or OpenIE-based graph construction paired with fixed Top-\textit{k} retrieval, leading to limited adaptability across query categories and high computational overhead. In this paper, we propose HingeMem, a boundary-guided long-term memory that operationalizes event segmentation theory to build an interpretable indexing interface via boundary-triggered hyperedges over four elements: person, time, location, and topic. When any such element changes, HingeMem draws a boundary and writes the current segment, thereby reducing redundant operations and preserving salient context. To enable robust and efficient retrieval under diverse information needs, HingeMem introduces query-adaptive retrieval mechanisms that jointly decide (a) \textit{what to retrieve}: determine the query-conditioned routing over the element-indexed memory; (b) \textit{how much to retrieve}: control the retrieval depth based on the estimated query type. Extensive experiments across LLM scales (from 0.6B to production-tier models; \textit{e.g.}, Qwen3-0.6B to Qwen-Flash) on LOCOMO show that HingeMem achieves approximately $20\%$ relative improvement over strong baselines without query categories specification, while reducing computational cost (68\%$\downarrow$ question answering token cost compared to HippoRAG2). Beyond advancing memory modeling, HingeMem's adaptive retrieval makes it a strong fit for web applications requiring efficient and trustworthy memory over extended interactions.
Embodied Science: Closing the Discovery Loop with Agentic Embodied AI
Mar 20, 2026Artificial intelligence has demonstrated remarkable capability in predicting scientific properties, yet scientific discovery remains an inherently physical, long-horizon pursuit governed by experimental cycles. Most current computational approaches are misaligned with this reality, framing discovery as isolated, task-specific predictions rather than continuous interaction with the physical world. Here, we argue for embodied science, a paradigm that reframes scientific discovery as a closed loop tightly coupling agentic reasoning with physical execution. We propose a unified Perception-Language-Action-Discovery (PLAD) framework, wherein embodied agents perceive experimental environments, reason over scientific knowledge, execute physical interventions, and internalize outcomes to drive subsequent exploration. By grounding computational reasoning in robust physical feedback, this approach bridges the gap between digital prediction and empirical validation, offering a roadmap for autonomous discovery systems in the life and chemical sciences.
AnimeAgent: Is the Multi-Agent via Image-to-Video models a Good Disney Storytelling Artist?
Feb 24, 2026Custom Storyboard Generation (CSG) aims to produce high-quality, multi-character consistent storytelling. Current approaches based on static diffusion models, whether used in a one-shot manner or within multi-agent frameworks, face three key limitations: (1) Static models lack dynamic expressiveness and often resort to "copy-paste" pattern. (2) One-shot inference cannot iteratively correct missing attributes or poor prompt adherence. (3) Multi-agents rely on non-robust evaluators, ill-suited for assessing stylized, non-realistic animation. To address these, we propose AnimeAgent, the first Image-to-Video (I2V)-based multi-agent framework for CSG. Inspired by Disney's "Combination of Straight Ahead and Pose to Pose" workflow, AnimeAgent leverages I2V's implicit motion prior to enhance consistency and expressiveness, while a mixed subjective-objective reviewer enables reliable iterative refinement. We also collect a human-annotated CSG benchmark with ground-truth. Experiments show AnimeAgent achieves SOTA performance in consistency, prompt fidelity, and stylization.
Scene-Aware Memory Discrimination: Deciding Which Personal Knowledge Stays
Feb 12, 2026Intelligent devices have become deeply integrated into everyday life, generating vast amounts of user interactions that form valuable personal knowledge. Efficient organization of this knowledge in user memory is essential for enabling personalized applications. However, current research on memory writing, management, and reading using large language models (LLMs) faces challenges in filtering irrelevant information and in dealing with rising computational costs. Inspired by the concept of selective attention in the human brain, we introduce a memory discrimination task. To address large-scale interactions and diverse memory standards in this task, we propose a Scene-Aware Memory Discrimination method (SAMD), which comprises two key components: the Gating Unit Module (GUM) and the Cluster Prompting Module (CPM). GUM enhances processing efficiency by filtering out non-memorable interactions and focusing on the salient content most relevant to application demands. CPM establishes adaptive memory standards, guiding LLMs to discern what information should be remembered or discarded. It also analyzes the relationship between user intents and memory contexts to build effective clustering prompts. Comprehensive direct and indirect evaluations demonstrate the effectiveness and generalization of our approach. We independently assess the performance of memory discrimination, showing that SAMD successfully recalls the majority of memorable data and remains robust in dynamic scenarios. Furthermore, when integrated into personalized applications, SAMD significantly enhances both the efficiency and quality of memory construction, leading to better organization of personal knowledge.
Synergizing RAG and Reasoning: A Systematic Review
Apr 22, 2025



Recent breakthroughs in large language models (LLMs), particularly in reasoning capabilities, have propelled Retrieval-Augmented Generation (RAG) to unprecedented levels. By synergizing retrieval mechanisms with advanced reasoning, LLMs can now tackle increasingly complex problems. This paper presents a systematic review of the collaborative interplay between RAG and reasoning, clearly defining "reasoning" within the RAG context. It construct a comprehensive taxonomy encompassing multi-dimensional collaborative objectives, representative paradigms, and technical implementations, and analyze the bidirectional synergy methods. Additionally, we critically evaluate current limitations in RAG assessment, including the absence of intermediate supervision for multi-step reasoning and practical challenges related to cost-risk trade-offs. To bridge theory and practice, we provide practical guidelines tailored to diverse real-world applications. Finally, we identify promising research directions, such as graph-based knowledge integration, hybrid model collaboration, and RL-driven optimization. Overall, this work presents a theoretical framework and practical foundation to advance RAG systems in academia and industry, fostering the next generation of RAG solutions.
Highly Efficient Natural Image Matting
Oct 25, 2021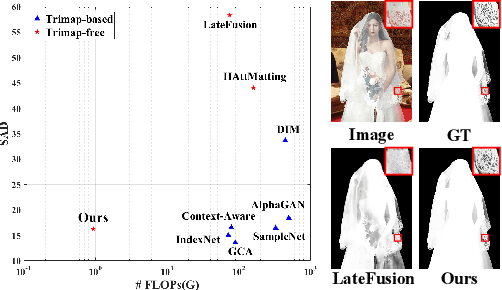
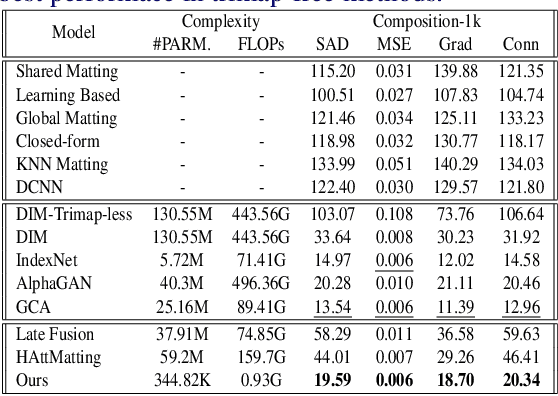
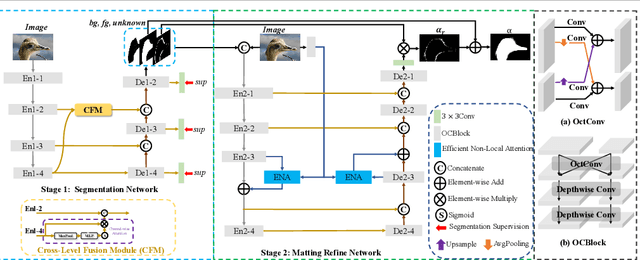
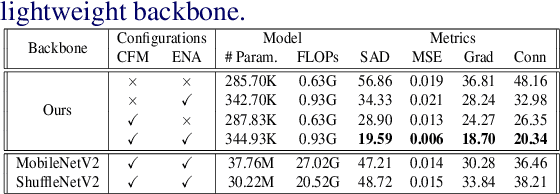
Over the last few years, deep learning based approaches have achieved outstanding improvements in natural image matting. However, there are still two drawbacks that impede the widespread application of image matting: the reliance on user-provided trimaps and the heavy model sizes. In this paper, we propose a trimap-free natural image matting method with a lightweight model. With a lightweight basic convolution block, we build a two-stages framework: Segmentation Network (SN) is designed to capture sufficient semantics and classify the pixels into unknown, foreground and background regions; Matting Refine Network (MRN) aims at capturing detailed texture information and regressing accurate alpha values. With the proposed cross-level fusion Module (CFM), SN can efficiently utilize multi-scale features with less computational cost. Efficient non-local attention module (ENA) in MRN can efficiently model the relevance between different pixels and help regress high-quality alpha values. Utilizing these techniques, we construct an extremely light-weighted model, which achieves comparable performance with ~1\% parameters (344k) of large models on popular natural image matting benchmarks.