 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Continual Relation Extraction via Classifier Decomposition
May 08, 2023Continual relation extraction (CRE) models aim at handling emerging new relations while avoiding catastrophically forgetting old ones in the streaming data. Though improvements have been shown by previous CRE studies, most of them only adopt a vanilla strategy when models first learn representations of new relations. In this work, we point out that there exist two typical biases after training of this vanilla strategy: classifier bias and representation bias, which causes the previous knowledge that the model learned to be shaded. To alleviate those biases, we propose a simple yet effective classifier decomposition framework that splits the last FFN layer into separated previous and current classifiers, so as to maintain previous knowledge and encourage the model to learn more robust representations at this training stage. Experimental results on two standard benchmarks show that our proposed framework consistently outperforms the state-of-the-art CRE models, which indicates that the importance of the first training stage to CRE models may be underestimated. Our code is available at https://github.com/hemingkx/CDec.
Finding Similar Exercises in Retrieval Manner
Mar 15, 2023



When students make a mistake in an exercise, they can consolidate it by ``similar exercises'' which have the same concepts, purposes and methods. Commonly, for a certain subject and study stage, the size of the exercise bank is in the range of millions to even tens of millions, how to find similar exercises for a given exercise becomes a crucial technical problem. Generally, we can assign a variety of explicit labels to the exercise, and then query through the labels, but the label annotation is time-consuming, laborious and costly, with limited precision and granularity, so it is not feasible. In practice, we define ``similar exercises'' as a retrieval process of finding a set of similar exercises based on recall, ranking and re-rank procedures, called the \textbf{FSE} problem (Finding similar exercises). Furthermore, comprehensive representation of the semantic information of exercises was obtained through representation learning. In addition to the reasonable architecture, we also explore what kind of tasks are more conducive to the learning of exercise semantic information from pre-training and supervised learning. It is difficult to annotate similar exercises and the annotation consistency among experts is low. Therefore this paper also provides solutions to solve the problem of low-quality annotated data. Compared with other methods, this paper has obvious advantages in both architecture rationality and algorithm precision, which now serves the daily teaching of hundreds of schools.
* 37th Conference on AAAI 2023 Artificial Intelligence for Education(AI4Edu)
TQ-Net: Mixed Contrastive Representation Learning For Heterogeneous Test Questions
Mar 09, 2023



Recently, more and more people study online for the convenience of access to massive learning materials (e.g. test questions/notes), thus accurately understanding learning materials became a crucial issue, which is essential for many educational applications. Previous studies focus on using language models to represent the question data. However, test questions (TQ) are usually heterogeneous and multi-modal, e.g., some of them may only contain text, while others half contain images with information beyond their literal description. In this context, both supervised and unsupervised methods are difficult to learn a fused representation of questions. Meanwhile, this problem cannot be solved by conventional methods such as image caption, as the images may contain information complementary rather than duplicate to the text. In this paper, we first improve previous text-only representation with a two-stage unsupervised instance level contrastive based pre-training method (MCL: Mixture Unsupervised Contrastive Learning). Then, TQ-Net was proposed to fuse the content of images to the representation of heterogeneous data. Finally, supervised contrastive learning was conducted on relevance prediction-related downstream tasks, which helped the model to learn the representation of questions effectively. We conducted extensive experiments on question-based tasks on large-scale, real-world datasets, which demonstrated the effectiveness of TQ-Net and improve the precision of downstream applications (e.g. similar questions +2.02% and knowledge point prediction +7.20%). Our code will be available, and we will open-source a subset of our data to promote the development of relative studies.
DialogQAE: N-to-N Question Answer Pair Extraction from Customer Service Chatlog
Dec 14, 2022



Harvesting question-answer (QA) pairs from customer service chatlog in the wild is an efficient way to enrich the knowledge base for customer service chatbots in the cold start or continuous integration scenarios. Prior work attempts to obtain 1-to-1 QA pairs from growing customer service chatlog, which fails to integrate the incomplete utterances from the dialog context for composite QA retrieval. In this paper, we propose N-to-N QA extraction task in which the derived questions and corresponding answers might be separated across different utterances. We introduce a suite of generative/discriminative tagging based methods with end-to-end and two-stage variants that perform well on 5 customer service datasets and for the first time setup a benchmark for N-to-N DialogQAE with utterance and session level evaluation metrics. With a deep dive into extracted QA pairs, we find that the relations between and inside the QA pairs can be indicators to analyze the dialogue structure, e.g. information seeking, clarification, barge-in and elaboration. We also show that the proposed models can adapt to different domains and languages, and reduce the labor cost of knowledge accumulation in the real-world product dialogue platform.
DualNER: A Dual-Teaching framework for Zero-shot Cross-lingual Named Entity Recognition
Nov 15, 2022



We present DualNER, a simple and effective framework to make full use of both annotated source language corpus and unlabeled target language text for zero-shot cross-lingual named entity recognition (NER). In particular, we combine two complementary learning paradigms of NER, i.e., sequence labeling and span prediction, into a unified multi-task framework. After obtaining a sufficient NER model trained on the source data, we further train it on the target data in a {\it dual-teaching} manner, in which the pseudo-labels for one task are constructed from the prediction of the other task. Moreover, based on the span prediction, an entity-aware regularization is proposed to enhance the intrinsic cross-lingual alignment between the same entities in different languages. Experiments and analysis demonstrate the effectiveness of our DualNER. Code is available at https://github.com/lemon0830/dualNER.
Contrastive Learning with Prompt-derived Virtual Semantic Prototypes for Unsupervised Sentence Embedding
Nov 07, 2022



Contrastive learning has become a new paradigm for unsupervised sentence embeddings. Previous studies focus on instance-wise contrastive learning, attempting to construct positive pairs with textual data augmentation. In this paper, we propose a novel Contrastive learning method with Prompt-derived Virtual semantic Prototypes (ConPVP). Specifically, with the help of prompts, we construct virtual semantic prototypes to each instance, and derive negative prototypes by using the negative form of the prompts. Using a prototypical contrastive loss, we enforce the anchor sentence embedding to be close to its corresponding semantic prototypes, and far apart from the negative prototypes as well as the prototypes of other sentences. Extensive experimental results on semantic textual similarity, transfer, and clustering tasks demonstrate the effectiveness of our proposed model compared to strong baselines. Code is available at https://github.com/lemon0830/promptCSE.
Instance Segmentation for Chinese Character Stroke Extraction, Datasets and Benchmarks
Oct 25, 2022



Stroke is the basic element of Chinese character and stroke extraction has been an important and long-standing endeavor. Existing stroke extraction methods are often handcrafted and highly depend on domain expertise due to the limited training data. Moreover, there are no standardized benchmarks to provide a fair comparison between different stroke extraction methods, which, we believe, is a major impediment to the development of Chinese character stroke understanding and related tasks. In this work, we present the first public available Chinese Character Stroke Extraction (CCSE) benchmark, with two new large-scale datasets: Kaiti CCSE (CCSE-Kai) and Handwritten CCSE (CCSE-HW). With the large-scale datasets, we hope to leverage the representation power of deep models such as CNNs to solve the stroke extraction task, which, however, remains an open question. To this end, we turn the stroke extraction problem into a stroke instance segmentation problem. Using the proposed datasets to train a stroke instance segmentation model, we surpass previous methods by a large margin. Moreover, the models trained with the proposed datasets benefit the downstream font generation and handwritten aesthetic assessment tasks. We hope these benchmark results can facilitate further research. The source code and datasets are publicly available at: https://github.com/lizhaoliu-Lec/CCSE.
DialogUSR: Complex Dialogue Utterance Splitting and Reformulation for Multiple Intent Detection
Oct 20, 2022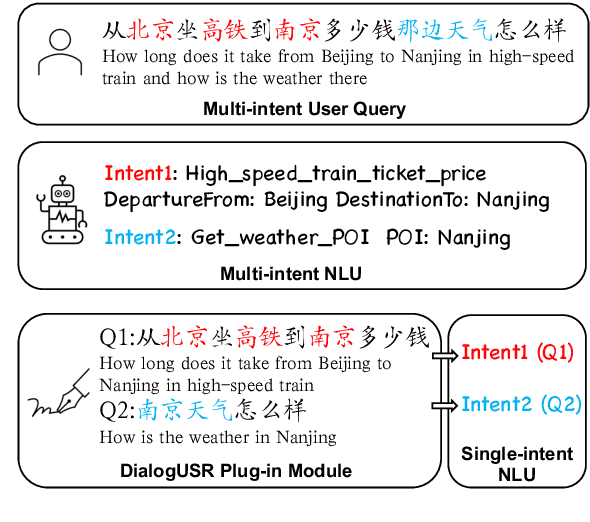
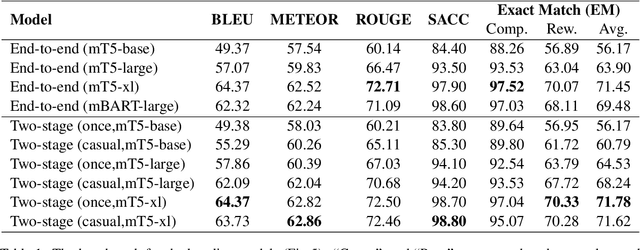

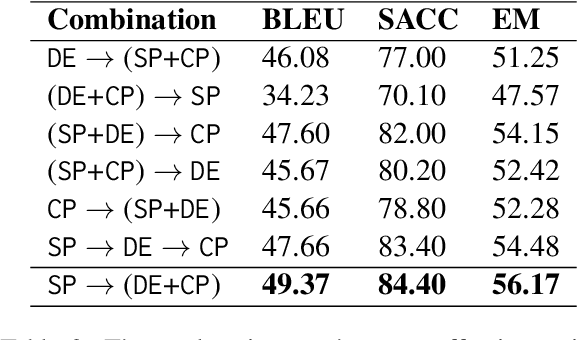
While interacting with chatbots, users may elicit multiple intents in a single dialogue utterance. Instead of training a dedicated multi-intent detection model, we propose DialogUSR, a dialogue utterance splitting and reformulation task that first splits multi-intent user query into several single-intent sub-queries and then recovers all the coreferred and omitted information in the sub-queries. DialogUSR can serve as a plug-in and domain-agnostic module that empowers the multi-intent detection for the deployed chatbots with minimal efforts. We collect a high-quality naturally occurring dataset that covers 23 domains with a multi-step crowd-souring procedure. To benchmark the proposed dataset, we propose multiple action-based generative models that involve end-to-end and two-stage training, and conduct in-depth analyses on the pros and cons of the proposed baselines.
Linguistic Rules-Based Corpus Generation for Native Chinese Grammatical Error Correction
Oct 19, 2022
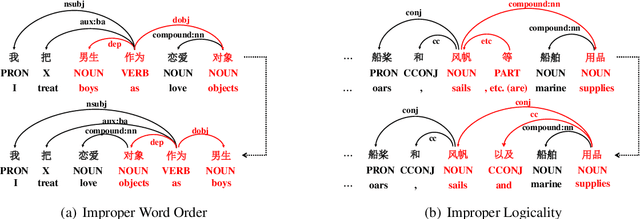
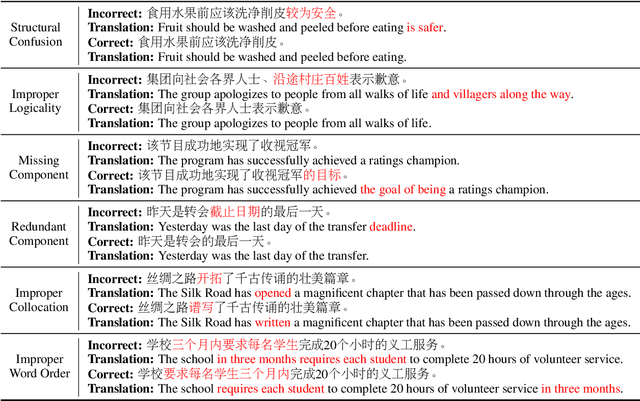
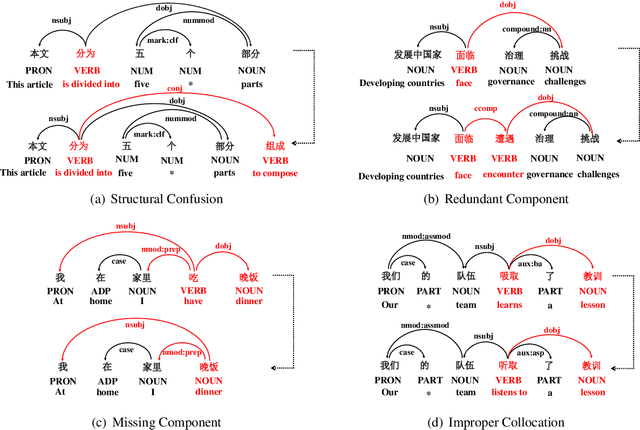
Chinese Grammatical Error Correction (CGEC) is both a challenging NLP task and a common application in human daily life. Recently, many data-driven approaches are proposed for the development of CGEC research. However, there are two major limitations in the CGEC field: First, the lack of high-quality annotated training corpora prevents the performance of existing CGEC models from being significantly improved. Second, the grammatical errors in widely used test sets are not made by native Chinese speakers, resulting in a significant gap between the CGEC models and the real application. In this paper, we propose a linguistic rules-based approach to construct large-scale CGEC training corpora with automatically generated grammatical errors. Additionally, we present a challenging CGEC benchmark derived entirely from errors made by native Chinese speakers in real-world scenarios. Extensive experiments and detailed analyses not only demonstrate that the training data constructed by our method effectively improves the performance of CGEC models, but also reflect that our benchmark is an excellent resource for further development of the CGEC field.
Learning from the Dictionary: Heterogeneous Knowledge Guided Fine-tuning for Chinese Spell Checking
Oct 19, 2022
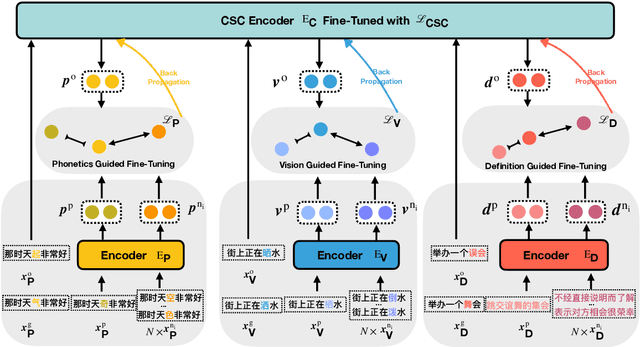
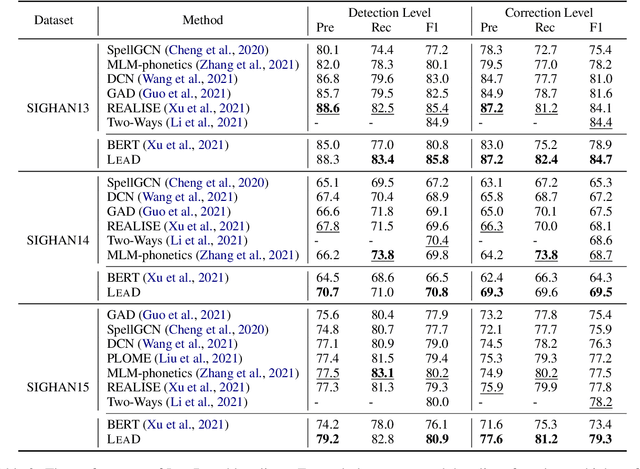

Chinese Spell Checking (CSC) aims to detect and correct Chinese spelling errors. Recent researches start from the pretrained knowledge of language models and take multimodal information into CSC models to improve the performance. However, they overlook the rich knowledge in the dictionary, the reference book where one can learn how one character should be pronounced, written, and used. In this paper, we propose the LEAD framework, which renders the CSC model to learn heterogeneous knowledge from the dictionary in terms of phonetics, vision, and meaning. LEAD first constructs positive and negative samples according to the knowledge of character phonetics, glyphs, and definitions in the dictionary. Then a unified contrastive learning-based training scheme is employed to refine the representations of the CSC models. Extensive experiments and detailed analyses on the SIGHAN benchmark datasets demonstrate the effectiveness of our proposed methods.