 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQ-DiT4SR: Exploration of Detail-Preserving Diffusion Transformer Quantization for Real-World Image Super-Resolution
Feb 01, 2026Recently, Diffusion Transformers (DiTs) have emerged in Real-World Image Super-Resolution (Real-ISR) to generate high-quality textures, yet their heavy inference burden hinders real-world deployment. While Post-Training Quantization (PTQ) is a promising solution for acceleration, existing methods in super-resolution mostly focus on U-Net architectures, whereas generic DiT quantization is typically designed for text-to-image tasks. Directly applying these methods to DiT-based super-resolution models leads to severe degradation of local textures. Therefore, we propose Q-DiT4SR, the first PTQ framework specifically tailored for DiT-based Real-ISR. We propose H-SVD, a hierarchical SVD that integrates a global low-rank branch with a local block-wise rank-1 branch under a matched parameter budget. We further propose Variance-aware Spatio-Temporal Mixed Precision: VaSMP allocates cross-layer weight bit-widths in a data-free manner based on rate-distortion theory, while VaTMP schedules intra-layer activation precision across diffusion timesteps via dynamic programming (DP) with minimal calibration. Experiments on multiple real-world datasets demonstrate that our Q-DiT4SR achieves SOTA performance under both W4A6 and W4A4 settings. Notably, the W4A4 quantization configuration reduces model size by 5.8$\times$ and computational operations by over 60$\times$. Our code and models will be available at https://github.com/xunzhang1128/Q-DiT4SR.
D$^2$Quant: Accurate Low-bit Post-Training Weight Quantization for LLMs
Jan 30, 2026Large language models (LLMs) deliver strong performance, but their high compute and memory costs make deployment difficult in resource-constrained scenarios. Weight-only post-training quantization (PTQ) is appealing, as it reduces memory usage and enables practical speedup without low-bit operators or specialized hardware. However, accuracy often degrades significantly in weight-only PTQ at sub-4-bit precision, and our analysis identifies two main causes: (1) down-projection matrices are a well-known quantization bottleneck, but maintaining their fidelity often requires extra bit-width; (2) weight quantization induces activation deviations, but effective correction strategies remain underexplored. To address these issues, we propose D$^2$Quant, a novel weight-only PTQ framework that improves quantization from both the weight and activation perspectives. On the weight side, we design a Dual-Scale Quantizer (DSQ) tailored to down-projection matrices, with an absorbable scaling factor that significantly improves accuracy without increasing the bit budget. On the activation side, we propose Deviation-Aware Correction (DAC), which incorporates a mean-shift correction within LayerNorm to mitigate quantization-induced activation distribution shifts. Extensive experiments across multiple LLM families and evaluation metrics show that D$^2$Quant delivers superior performance for weight-only PTQ at sub-4-bit precision. The code and models will be available at https://github.com/XIANGLONGYAN/D2Quant.
Fose: Fusion of One-Step Diffusion and End-to-End Network for Pansharpening
Dec 19, 2025Pansharpening is a significant image fusion task that fuses low-resolution multispectral images (LRMSI) and high-resolution panchromatic images (PAN) to obtain high-resolution multispectral images (HRMSI). The development of the diffusion models (DM) and the end-to-end models (E2E model) has greatly improved the frontier of pansharping. DM takes the multi-step diffusion to obtain an accurate estimation of the residual between LRMSI and HRMSI. However, the multi-step process takes large computational power and is time-consuming. As for E2E models, their performance is still limited by the lack of prior and simple structure. In this paper, we propose a novel four-stage training strategy to obtain a lightweight network Fose, which fuses one-step DM and an E2E model. We perform one-step distillation on an enhanced SOTA DM for pansharping to compress the inference process from 50 steps to only 1 step. Then we fuse the E2E model with one-step DM with lightweight ensemble blocks. Comprehensive experiments are conducted to demonstrate the significant improvement of the proposed Fose on three commonly used benchmarks. Moreover, we achieve a 7.42 speedup ratio compared to the baseline DM while achieving much better performance. The code and model are released at https://github.com/Kai-Liu001/Fose.
UmniBench: Unified Understand and Generation Model Oriented Omni-dimensional Benchmark
Dec 19, 2025Unifying multimodal understanding and generation has shown impressive capabilities in cutting-edge proprietary systems. However, evaluations of unified multimodal models (UMMs) remain decoupled, assessing their understanding and generation abilities separately with corresponding datasets. To address this, we propose UmniBench, a benchmark tailored for UMMs with omni-dimensional evaluation. First, UmniBench can assess the understanding, generation, and editing ability within a single evaluation process. Based on human-examined prompts and QA pairs, UmniBench leverages UMM itself to evaluate its generation and editing ability with its understanding ability. This simple but effective paradigm allows comprehensive evaluation of UMMs. Second, UmniBench covers 13 major domains and more than 200 concepts, ensuring a thorough inspection of UMMs. Moreover, UmniBench can also decouple and separately evaluate understanding, generation, and editing abilities, providing a fine-grained assessment. Based on UmniBench, we benchmark 24 popular models, including both UMMs and single-ability large models. We hope this benchmark provides a more comprehensive and objective view of unified models and logistical support for improving the performance of the community model.
Measurement-Constrained Sampling for Text-Prompted Blind Face Restoration
Nov 18, 2025



Blind face restoration (BFR) may correspond to multiple plausible high-quality (HQ) reconstructions under extremely low-quality (LQ) inputs. However, existing methods typically produce deterministic results, struggling to capture this one-to-many nature. In this paper, we propose a Measurement-Constrained Sampling (MCS) approach that enables diverse LQ face reconstructions conditioned on different textual prompts. Specifically, we formulate BFR as a measurement-constrained generative task by constructing an inverse problem through controlled degradations of coarse restorations, which allows posterior-guided sampling within text-to-image diffusion. Measurement constraints include both Forward Measurement, which ensures results align with input structures, and Reverse Measurement, which produces projection spaces, ensuring that the solution can align with various prompts. Experiments show that our MCS can generate prompt-aligned results and outperforms existing BFR methods. Codes will be released after acceptance.
Flow-Matching Guided Deep Unfolding for Hyperspectral Image Reconstruction
Oct 02, 2025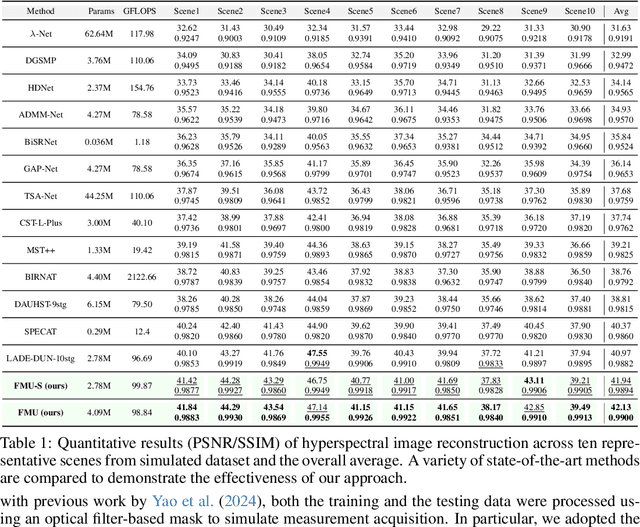

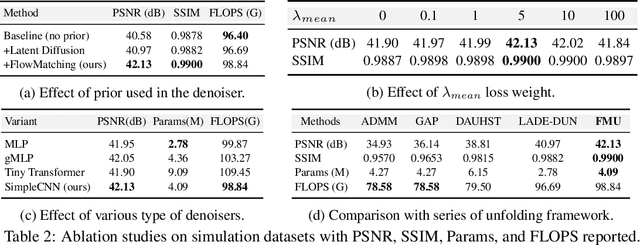
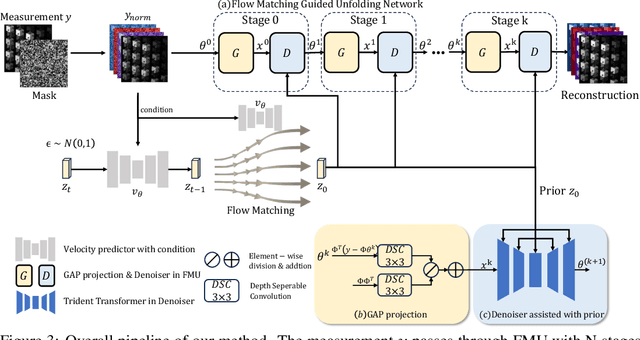
Hyperspectral imaging (HSI) provides rich spatial-spectral information but remains costly to acquire due to hardware limitations and the difficulty of reconstructing three-dimensional data from compressed measurements. Although compressive sensing systems such as CASSI improve efficiency, accurate reconstruction is still challenged by severe degradation and loss of fine spectral details. We propose the Flow-Matching-guided Unfolding network (FMU), which, to our knowledge, is the first to integrate flow matching into HSI reconstruction by embedding its generative prior within a deep unfolding framework. To further strengthen the learned dynamics, we introduce a mean velocity loss that enforces global consistency of the flow, leading to a more robust and accurate reconstruction. This hybrid design leverages the interpretability of optimization-based methods and the generative capacity of flow matching. Extensive experiments on both simulated and real datasets show that FMU significantly outperforms existing approaches in reconstruction quality. Code and models will be available at https://github.com/YiAi03/FMU.
FideDiff: Efficient Diffusion Model for High-Fidelity Image Motion Deblurring
Oct 02, 2025



Recent advancements in image motion deblurring, driven by CNNs and transformers, have made significant progress. Large-scale pre-trained diffusion models, which are rich in true-world modeling, have shown great promise for high-quality image restoration tasks such as deblurring, demonstrating stronger generative capabilities than CNN and transformer-based methods. However, challenges such as unbearable inference time and compromised fidelity still limit the full potential of the diffusion models. To address this, we introduce FideDiff, a novel single-step diffusion model designed for high-fidelity deblurring. We reformulate motion deblurring as a diffusion-like process where each timestep represents a progressively blurred image, and we train a consistency model that aligns all timesteps to the same clean image. By reconstructing training data with matched blur trajectories, the model learns temporal consistency, enabling accurate one-step deblurring. We further enhance model performance by integrating Kernel ControlNet for blur kernel estimation and introducing adaptive timestep prediction. Our model achieves superior performance on full-reference metrics, surpassing previous diffusion-based methods and matching the performance of other state-of-the-art models. FideDiff offers a new direction for applying pre-trained diffusion models to high-fidelity image restoration tasks, establishing a robust baseline for further advancing diffusion models in real-world industrial applications. Our dataset and code will be available at https://github.com/xyLiu339/FideDiff.
FlashEdit: Decoupling Speed, Structure, and Semantics for Precise Image Editing
Sep 26, 2025Text-guided image editing with diffusion models has achieved remarkable quality but suffers from prohibitive latency, hindering real-world applications. We introduce FlashEdit, a novel framework designed to enable high-fidelity, real-time image editing. Its efficiency stems from three key innovations: (1) a One-Step Inversion-and-Editing (OSIE) pipeline that bypasses costly iterative processes; (2) a Background Shield (BG-Shield) technique that guarantees background preservation by selectively modifying features only within the edit region; and (3) a Sparsified Spatial Cross-Attention (SSCA) mechanism that ensures precise, localized edits by suppressing semantic leakage to the background. Extensive experiments demonstrate that FlashEdit maintains superior background consistency and structural integrity, while performing edits in under 0.2 seconds, which is an over 150$\times$ speedup compared to prior multi-step methods. Our code will be made publicly available at https://github.com/JunyiWuCode/FlashEdit.
SODiff: Semantic-Oriented Diffusion Model for JPEG Compression Artifacts Removal
Aug 10, 2025JPEG, as a widely used image compression standard, often introduces severe visual artifacts when achieving high compression ratios. Although existing deep learning-based restoration methods have made considerable progress, they often struggle to recover complex texture details, resulting in over-smoothed outputs. To overcome these limitations, we propose SODiff, a novel and efficient semantic-oriented one-step diffusion model for JPEG artifacts removal. Our core idea is that effective restoration hinges on providing semantic-oriented guidance to the pre-trained diffusion model, thereby fully leveraging its powerful generative prior. To this end, SODiff incorporates a semantic-aligned image prompt extractor (SAIPE). SAIPE extracts rich features from low-quality (LQ) images and projects them into an embedding space semantically aligned with that of the text encoder. Simultaneously, it preserves crucial information for faithful reconstruction. Furthermore, we propose a quality factor-aware time predictor that implicitly learns the compression quality factor (QF) of the LQ image and adaptively selects the optimal denoising start timestep for the diffusion process. Extensive experimental results show that our SODiff outperforms recent leading methods in both visual quality and quantitative metrics. Code is available at: https://github.com/frakenation/SODiff
Steering One-Step Diffusion Model with Fidelity-Rich Decoder for Fast Image Compression
Aug 07, 2025Diffusion-based image compression has demonstrated impressive perceptual performance. However, it suffers from two critical drawbacks: (1) excessive decoding latency due to multi-step sampling, and (2) poor fidelity resulting from over-reliance on generative priors. To address these issues, we propose SODEC, a novel single-step diffusion image compression model. We argue that in image compression, a sufficiently informative latent renders multi-step refinement unnecessary. Based on this insight, we leverage a pre-trained VAE-based model to produce latents with rich information, and replace the iterative denoising process with a single-step decoding. Meanwhile, to improve fidelity, we introduce the fidelity guidance module, encouraging output that is faithful to the original image. Furthermore, we design the rate annealing training strategy to enable effective training under extremely low bitrates. Extensive experiments show that SODEC significantly outperforms existing methods, achieving superior rate-distortion-perception performance. Moreover, compared to previous diffusion-based compression models, SODEC improves decoding speed by more than 20$\times$. Code is released at: https://github.com/zhengchen1999/SODEC.