 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Analysis of Attention via the Lens of Exchangeability and Latent Variable Models
Dec 30, 2022



With the attention mechanism, transformers achieve significant empirical successes. Despite the intuitive understanding that transformers perform relational inference over long sequences to produce desirable representations, we lack a rigorous theory on how the attention mechanism achieves it. In particular, several intriguing questions remain open: (a) What makes a desirable representation? (b) How does the attention mechanism infer the desirable representation within the forward pass? (c) How does a pretraining procedure learn to infer the desirable representation through the backward pass? We observe that, as is the case in BERT and ViT, input tokens are often exchangeable since they already include positional encodings. The notion of exchangeability induces a latent variable model that is invariant to input sizes, which enables our theoretical analysis. - To answer (a) on representation, we establish the existence of a sufficient and minimal representation of input tokens. In particular, such a representation instantiates the posterior distribution of the latent variable given input tokens, which plays a central role in predicting output labels and solving downstream tasks. - To answer (b) on inference, we prove that attention with the desired parameter infers the latent posterior up to an approximation error, which is decreasing in input sizes. In detail, we quantify how attention approximates the conditional mean of the value given the key, which characterizes how it performs relational inference over long sequences. - To answer (c) on learning, we prove that both supervised and self-supervised objectives allow empirical risk minimization to learn the desired parameter up to a generalization error, which is independent of input sizes. Particularly, in the self-supervised setting, we identify a condition number that is pivotal to solving downstream tasks.
Image-Text Retrieval with Binary and Continuous Label Supervision
Oct 20, 2022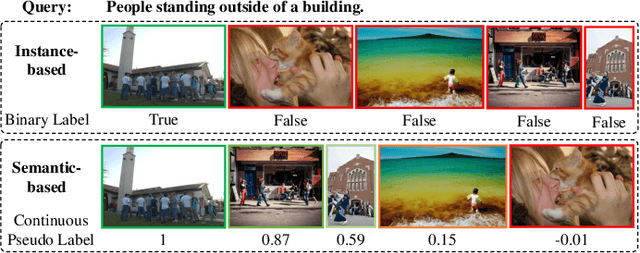
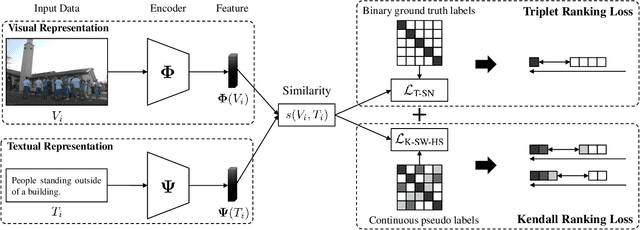
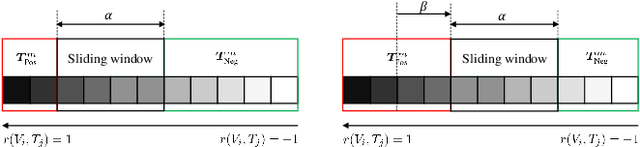
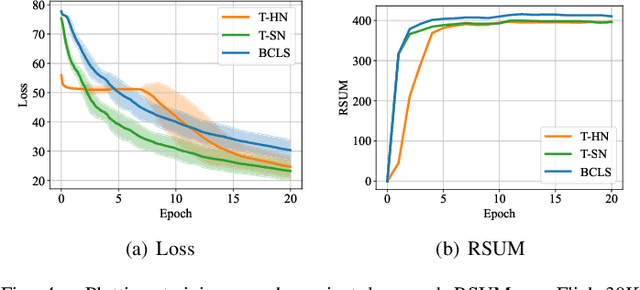
Most image-text retrieval work adopts binary labels indicating whether a pair of image and text matches or not. Such a binary indicator covers only a limited subset of image-text semantic relations, which is insufficient to represent relevance degrees between images and texts described by continuous labels such as image captions. The visual-semantic embedding space obtained by learning binary labels is incoherent and cannot fully characterize the relevance degrees. In addition to the use of binary labels, this paper further incorporates continuous pseudo labels (generally approximated by text similarity between captions) to indicate the relevance degrees. To learn a coherent embedding space, we propose an image-text retrieval framework with Binary and Continuous Label Supervision (BCLS), where binary labels are used to guide the retrieval model to learn limited binary correlations, and continuous labels are complementary to the learning of image-text semantic relations. For the learning of binary labels, we improve the common Triplet ranking loss with Soft Negative mining (Triplet-SN) to improve convergence. For the learning of continuous labels, we design Kendall ranking loss inspired by Kendall rank correlation coefficient (Kendall), which improves the correlation between the similarity scores predicted by the retrieval model and the continuous labels. To mitigate the noise introduced by the continuous pseudo labels, we further design Sliding Window sampling and Hard Sample mining strategy (SW-HS) to alleviate the impact of noise and reduce the complexity of our framework to the same order of magnitude as the triplet ranking loss. Extensive experiments on two image-text retrieval benchmarks demonstrate that our method can improve the performance of state-of-the-art image-text retrieval models.
Disconnected Emerging Knowledge Graph Oriented Inductive Link Prediction
Sep 03, 2022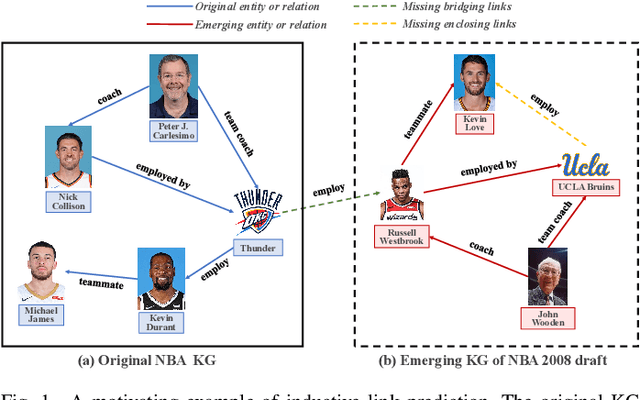
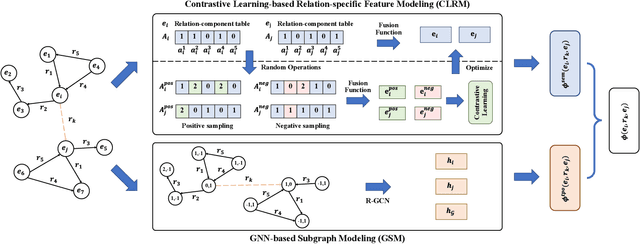
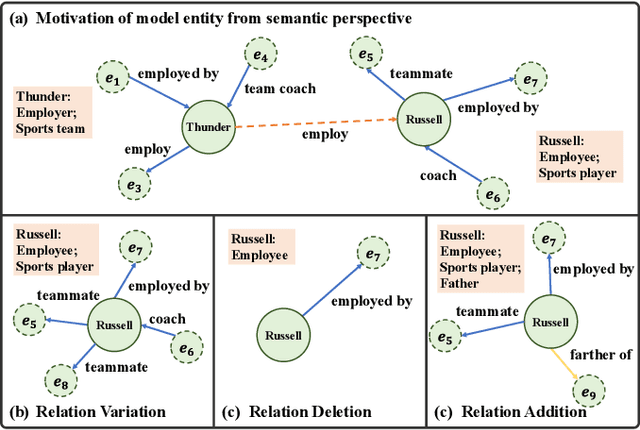
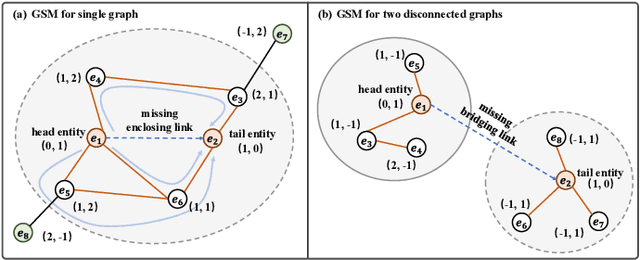
Inductive link prediction (ILP) is to predict links for unseen entities in emerging knowledge graphs (KGs), considering the evolving nature of KGs. A more challenging scenario is that emerging KGs consist of only unseen entities, called as disconnected emerging KGs (DEKGs). Existing studies for DEKGs only focus on predicting enclosing links, i.e., predicting links inside the emerging KG. The bridging links, which carry the evolutionary information from the original KG to DEKG, have not been investigated by previous work so far. To fill in the gap, we propose a novel model entitled DEKG-ILP (Disconnected Emerging Knowledge Graph Oriented Inductive Link Prediction) that consists of the following two components. (1) The module CLRM (Contrastive Learning-based Relation-specific Feature Modeling) is developed to extract global relation-based semantic features that are shared between original KGs and DEKGs with a novel sampling strategy. (2) The module GSM (GNN-based Subgraph Modeling) is proposed to extract the local subgraph topological information around each link in KGs. The extensive experiments conducted on several benchmark datasets demonstrate that DEKG-ILP has obvious performance improvements compared with state-of-the-art methods for both enclosing and bridging link prediction. The source code is available online.
Federated Offline Reinforcement Learning
Jun 11, 2022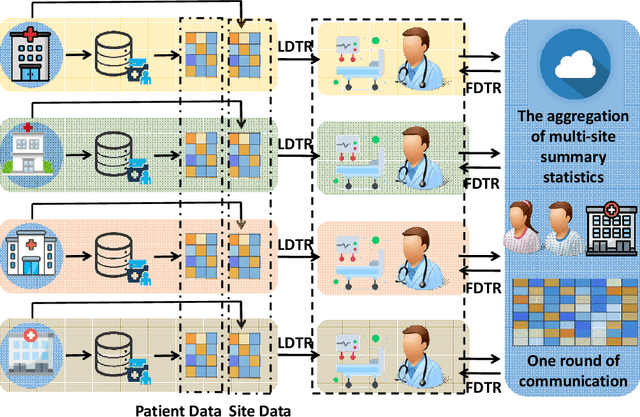
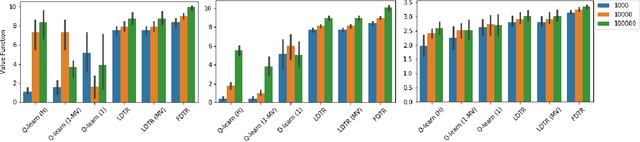
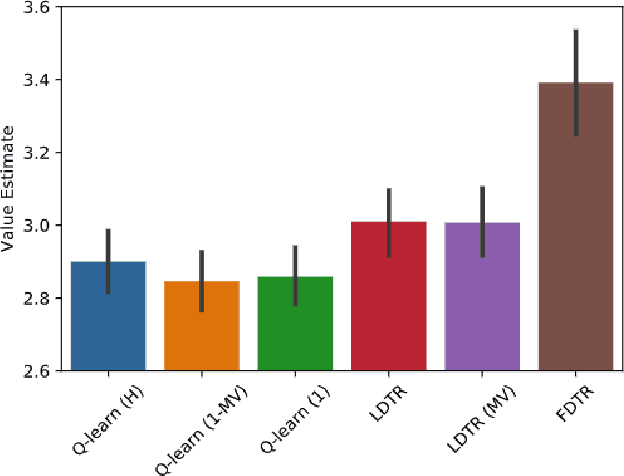
Evidence-based or data-driven dynamic treatment regimes are essential for personalized medicine, which can benefit from offline reinforcement learning (RL). Although massive healthcare data are available across medical institutions, they are prohibited from sharing due to privacy constraints. Besides, heterogeneity exists in different sites. As a result, federated offline RL algorithms are necessary and promising to deal with the problems. In this paper, we propose a multi-site Markov decision process model which allows both homogeneous and heterogeneous effects across sites. The proposed model makes the analysis of the site-level features possible. We design the first federated policy optimization algorithm for offline RL with sample complexity. The proposed algorithm is communication-efficient and privacy-preserving, which requires only a single round of communication interaction by exchanging summary statistics. We give a theoretical guarantee for the proposed algorithm without the assumption of sufficient action coverage, where the suboptimality for the learned policies is comparable to the rate as if data is not distributed. Extensive simulations demonstrate the effectiveness of the proposed algorithm. The method is applied to a sepsis data set in multiple sites to illustrate its use in clinical settings.
Wasserstein Flow Meets Replicator Dynamics: A Mean-Field Analysis of Representation Learning in Actor-Critic
Dec 27, 2021Actor-critic (AC) algorithms, empowered by neural networks, have had significant empirical success in recent years. However, most of the existing theoretical support for AC algorithms focuses on the case of linear function approximations, or linearized neural networks, where the feature representation is fixed throughout training. Such a limitation fails to capture the key aspect of representation learning in neural AC, which is pivotal in practical problems. In this work, we take a mean-field perspective on the evolution and convergence of feature-based neural AC. Specifically, we consider a version of AC where the actor and critic are represented by overparameterized two-layer neural networks and are updated with two-timescale learning rates. The critic is updated by temporal-difference (TD) learning with a larger stepsize while the actor is updated via proximal policy optimization (PPO) with a smaller stepsize. In the continuous-time and infinite-width limiting regime, when the timescales are properly separated, we prove that neural AC finds the globally optimal policy at a sublinear rate. Additionally, we prove that the feature representation induced by the critic network is allowed to evolve within a neighborhood of the initial one.
Relation-aware Heterogeneous Graph for User Profiling
Oct 14, 2021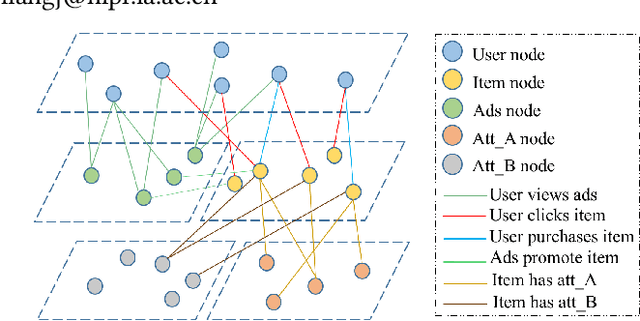
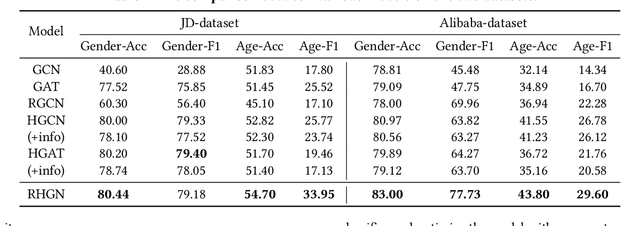
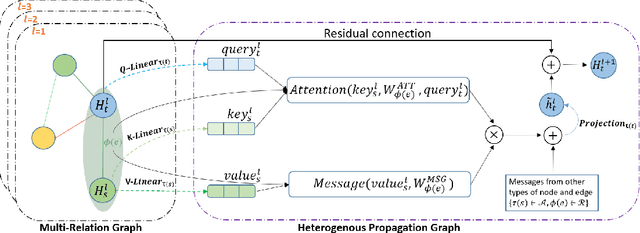
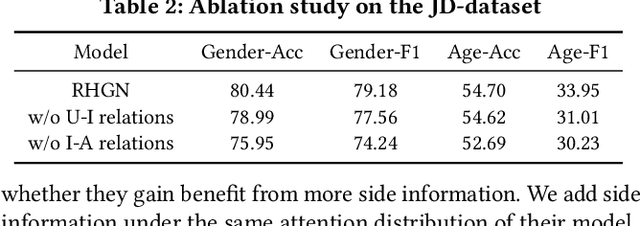
User profiling has long been an important problem that investigates user interests in many real applications. Some recent works regard users and their interacted objects as entities of a graph and turn the problem into a node classification task. However, they neglect the difference of distinct interaction types, e.g. user clicks an item v.s.user purchases an item, and thus cannot incorporate such information well. To solve these issues, we propose to leverage the relation-aware heterogeneous graph method for user profiling, which also allows capturing significant meta relations. We adopt the query, key, and value mechanism in a transformer fashion for heterogeneous message passing so that entities can effectively interact with each other. Via such interactions on different relation types, our model can generate representations with rich information for the user profile prediction. We conduct experiments on two real-world e-commerce datasets and observe a significant performance boost of our approach.
Shaping Individualized Impedance Landscapes for Gait Training via Reinforcement Learning
Sep 05, 2021



Assist-as-needed (AAN) control aims at promoting therapeutic outcomes in robot-assisted rehabilitation by encouraging patients' active participation. Impedance control is used by most AAN controllers to create a compliant force field around a target motion to ensure tracking accuracy while allowing moderate kinematic errors. However, since the parameters governing the shape of the force field are often tuned manually or adapted online based on simplistic assumptions about subjects' learning abilities, the effectiveness of conventional AAN controllers may be limited. In this work, we propose a novel adaptive AAN controller that is capable of autonomously reshaping the force field in a phase-dependent manner according to each individual's motor abilities and task requirements. The proposed controller consists of a modified Policy Improvement with Path Integral algorithm, a model-free, sampling-based reinforcement learning method that learns a subject-specific impedance landscape in real-time, and a hierarchical policy parameter evaluation structure that embeds the AAN paradigm by specifying performance-driven learning goals. The adaptability of the proposed control strategy to subjects' motor responses and its ability to promote short-term motor adaptations are experimentally validated through treadmill training sessions with able-bodied subjects who learned altered gait patterns with the assistance of a powered ankle-foot orthosis.
Provably Efficient Generative Adversarial Imitation Learning for Online and Offline Setting with Linear Function Approximation
Aug 19, 2021In generative adversarial imitation learning (GAIL), the agent aims to learn a policy from an expert demonstration so that its performance cannot be discriminated from the expert policy on a certain predefined reward set. In this paper, we study GAIL in both online and offline settings with linear function approximation, where both the transition and reward function are linear in the feature maps. Besides the expert demonstration, in the online setting the agent can interact with the environment, while in the offline setting the agent only accesses an additional dataset collected by a prior. For online GAIL, we propose an optimistic generative adversarial policy optimization algorithm (OGAP) and prove that OGAP achieves $\widetilde{\mathcal{O}}(H^2 d^{3/2}K^{1/2}+KH^{3/2}dN_1^{-1/2})$ regret. Here $N_1$ represents the number of trajectories of the expert demonstration, $d$ is the feature dimension, and $K$ is the number of episodes. For offline GAIL, we propose a pessimistic generative adversarial policy optimization algorithm (PGAP). For an arbitrary additional dataset, we obtain the optimality gap of PGAP, achieving the minimax lower bound in the utilization of the additional dataset. Assuming sufficient coverage on the additional dataset, we show that PGAP achieves $\widetilde{\mathcal{O}}(H^{2}dK^{-1/2} +H^2d^{3/2}N_2^{-1/2}+H^{3/2}dN_1^{-1/2} \ )$ optimality gap. Here $N_2$ represents the number of trajectories of the additional dataset with sufficient coverage.
Deep Active Learning for Text Classification with Diverse Interpretations
Aug 15, 2021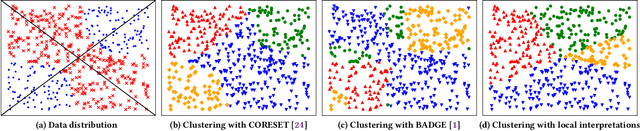
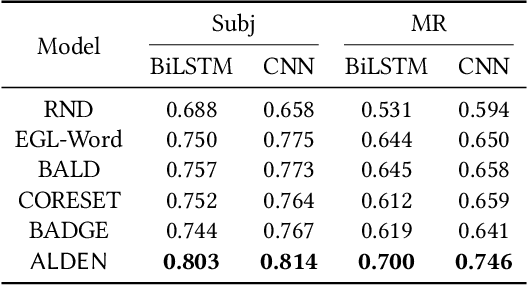
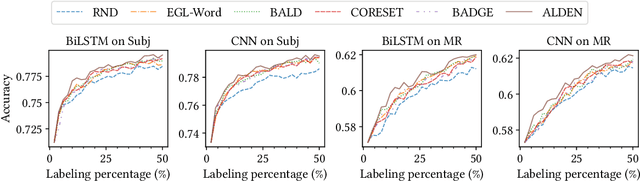
Recently, Deep Neural Networks (DNNs) have made remarkable progress for text classification, which, however, still require a large number of labeled data. To train high-performing models with the minimal annotation cost, active learning is proposed to select and label the most informative samples, yet it is still challenging to measure informativeness of samples used in DNNs. In this paper, inspired by piece-wise linear interpretability of DNNs, we propose a novel Active Learning with DivErse iNterpretations (ALDEN) approach. With local interpretations in DNNs, ALDEN identifies linearly separable regions of samples. Then, it selects samples according to their diversity of local interpretations and queries their labels. To tackle the text classification problem, we choose the word with the most diverse interpretations to represent the whole sentence. Extensive experiments demonstrate that ALDEN consistently outperforms several state-of-the-art deep active learning methods.
On the Properties of Kullback-Leibler Divergence Between Gaussians
Feb 24, 2021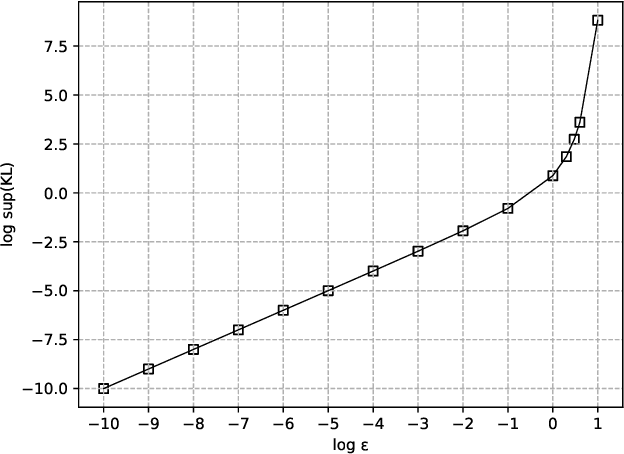
Kullback-Leibler (KL) divergence is one of the most important divergence measures between probability distributions. In this paper, we investigate the properties of KL divergence between Gaussians. Firstly, for any two $n$-dimensional Gaussians $\mathcal{N}_1$ and $\mathcal{N}_2$, we find the supremum of $KL(\mathcal{N}_1||\mathcal{N}_2)$ when $KL(\mathcal{N}_2||\mathcal{N}_1)\leq \epsilon$ for $\epsilon>0$. This reveals the approximate symmetry of small KL divergence between Gaussians. We also find the infimum of $KL(\mathcal{N}_1||\mathcal{N}_2)$ when $KL(\mathcal{N}_2||\mathcal{N}_1)\geq M$ for $M>0$. Secondly, for any three $n$-dimensional Gaussians $\mathcal{N}_1, \mathcal{N}_2$ and $\mathcal{N}_3$, we find a bound of $KL(\mathcal{N}_1||\mathcal{N}_3)$ if $KL(\mathcal{N}_1||\mathcal{N}_2)$ and $KL(\mathcal{N}_2||\mathcal{N}_3)$ are bounded. This reveals that the KL divergence between Gaussians follows a relaxed triangle inequality. Importantly, all the bounds in the theorems presented in this paper are independent of the dimension $n$.