 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAscendCraft: Automatic Ascend NPU Kernel Generation via DSL-Guided Transcompilation
Jan 30, 2026The performance of deep learning models critically depends on efficient kernel implementations, yet developing high-performance kernels for specialized accelerators remains time-consuming and expertise-intensive. While recent work demonstrates that large language models (LLMs) can generate correct and performant GPU kernels, kernel generation for neural processing units (NPUs) remains largely underexplored due to domain-specific programming models, limited public examples, and sparse documentation. Consequently, directly generating AscendC kernels with LLMs yields extremely low correctness, highlighting a substantial gap between GPU and NPU kernel generation. We present AscendCraft, a DSL-guided approach for automatic AscendC kernel generation. AscendCraft introduces a lightweight DSL that abstracts non-essential complexity while explicitly modeling Ascend-specific execution semantics. Kernels are first generated in the DSL using category-specific expert examples and then transcompiled into AscendC through structured, constraint-driven LLM lowering passes. Evaluated on MultiKernelBench across seven operator categories, AscendCraft achieves 98.1% compilation success and 90.4% functional correctness. Moreover, 46.2% of generated kernels match or exceed PyTorch eager execution performance, demonstrating that DSL-guided transcompilation can enable LLMs to generate both correct and competitive NPU kernels. Beyond benchmarks, AscendCraft further demonstrates its generality by successfully generating two correct kernels for newly proposed mHC architecture, achieving performance that substantially surpasses PyTorch eager execution.
Every Document Owns Its Structure: Inductive Text Classification via Graph Neural Networks
May 12, 2020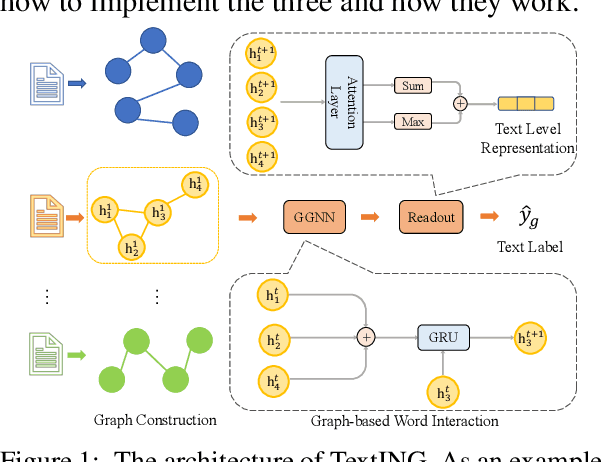
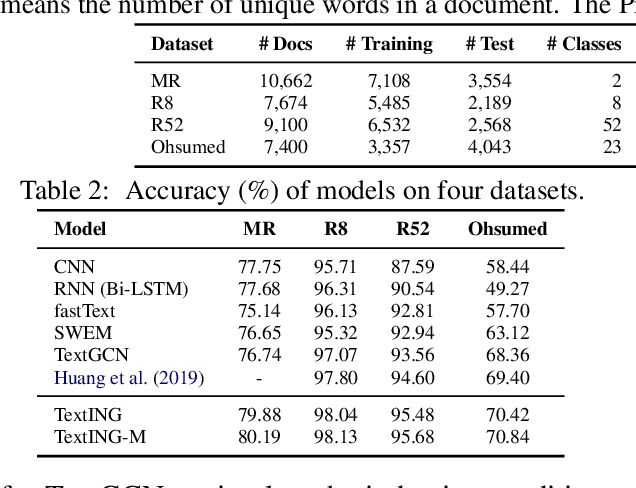
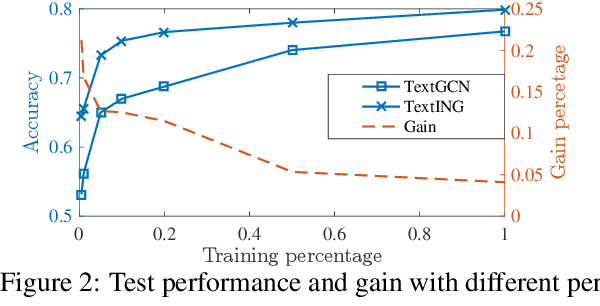
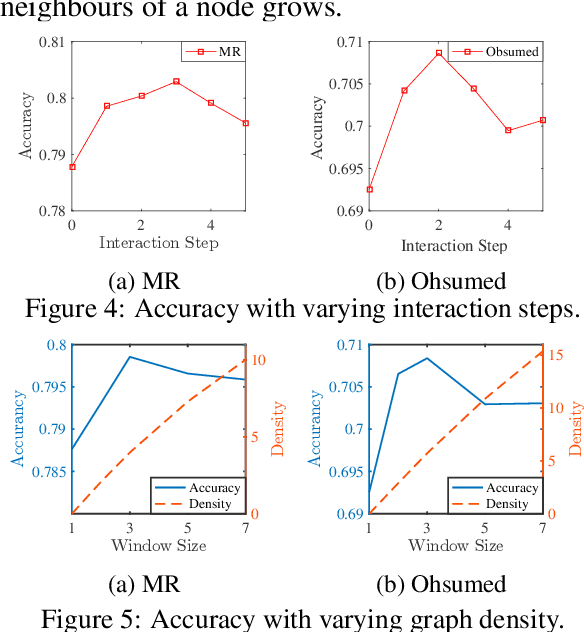
Text classification is fundamental in natural language processing (NLP), and Graph Neural Networks (GNN) are recently applied in this task. However, the existing graph-based works can neither capture the contextual word relationships within each document nor fulfil the inductive learning of new words. In this work, to overcome such problems, we propose TextING for inductive text classification via GNN. We first build individual graphs for each document and then use GNN to learn the fine-grained word representations based on their local structures, which can also effectively produce embeddings for unseen words in the new document. Finally, the word nodes are aggregated as the document embedding. Extensive experiments on four benchmark datasets show that our method outperforms state-of-the-art text classification methods.