 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainty-aware Attention Graph Neural Network for Defending Adversarial Attacks
Sep 22, 2020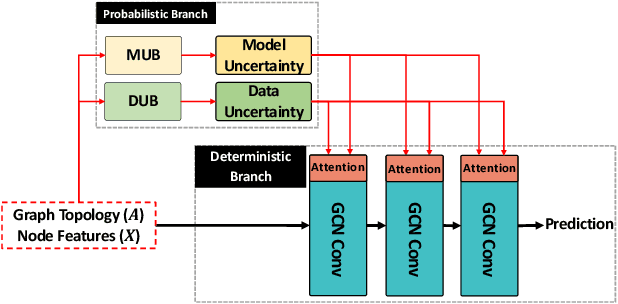
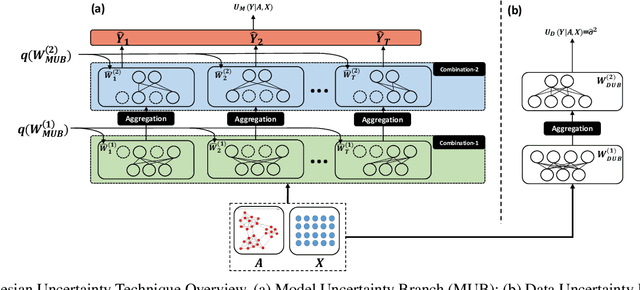
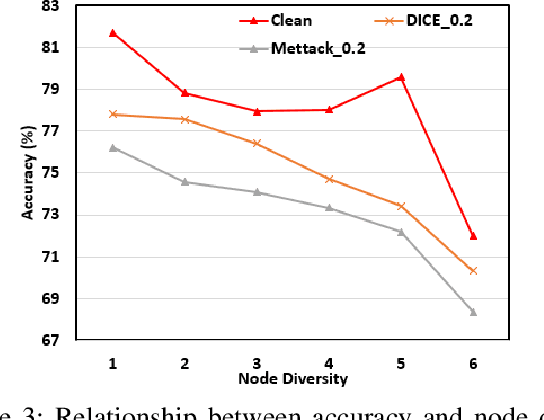
With the increasing popularity of graph-based learning, graph neural networks (GNNs) emerge as the essential tool for gaining insights from graphs. However, unlike the conventional CNNs that have been extensively explored and exhaustively tested, people are still worrying about the GNNs' robustness under the critical settings, such as financial services. The main reason is that existing GNNs usually serve as a black-box in predicting and do not provide the uncertainty on the predictions. On the other side, the recent advancement of Bayesian deep learning on CNNs has demonstrated its success of quantifying and explaining such uncertainties to fortify CNN models. Motivated by these observations, we propose UAG, the first systematic solution to defend adversarial attacks on GNNs through identifying and exploiting hierarchical uncertainties in GNNs. UAG develops a Bayesian Uncertainty Technique (BUT) to explicitly capture uncertainties in GNNs and further employs an Uncertainty-aware Attention Technique (UAT) to defend adversarial attacks on GNNs. Intensive experiments show that our proposed defense approach outperforms the state-of-the-art solutions by a significant margin.
Scalable Adversarial Attack on Graph Neural Networks with Alternating Direction Method of Multipliers
Sep 22, 2020
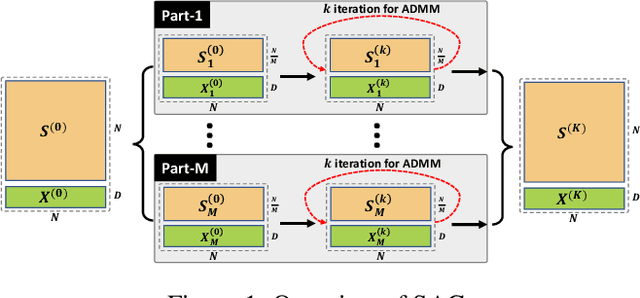

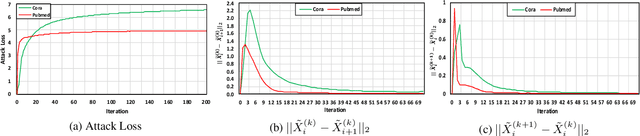
Graph neural networks (GNNs) have achieved high performance in analyzing graph-structured data and have been widely deployed in safety-critical areas, such as finance and autonomous driving. However, only a few works have explored GNNs' robustness to adversarial attacks, and their designs are usually limited by the scale of input datasets (i.e., focusing on small graphs with only thousands of nodes). In this work, we propose, SAG, the first scalable adversarial attack method with Alternating Direction Method of Multipliers (ADMM). We first decouple the large-scale graph into several smaller graph partitions and cast the original problem into several subproblems. Then, we propose to solve these subproblems using projected gradient descent on both the graph topology and the node features that lead to considerably lower memory consumption compared to the conventional attack methods. Rigorous experiments further demonstrate that SAG can significantly reduce the computation and memory overhead compared with the state-of-the-art approach, making SAG applicable towards graphs with large size of nodes and edges.
Optimizing Convolutional Neural Network Architecture via Information Field
Sep 11, 2020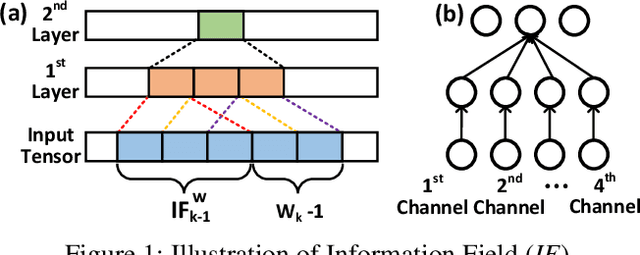
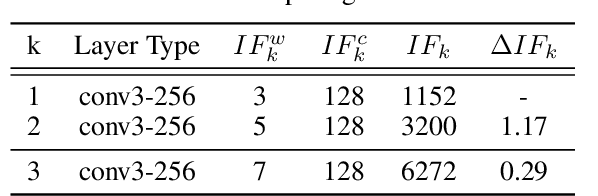
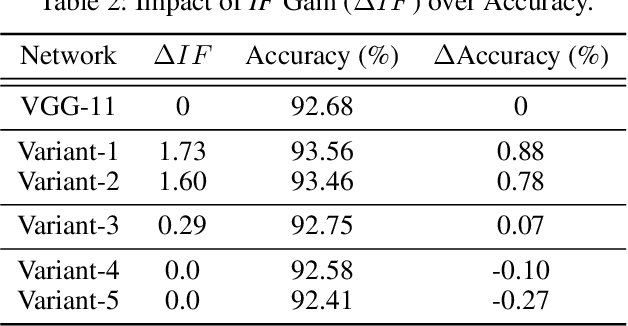
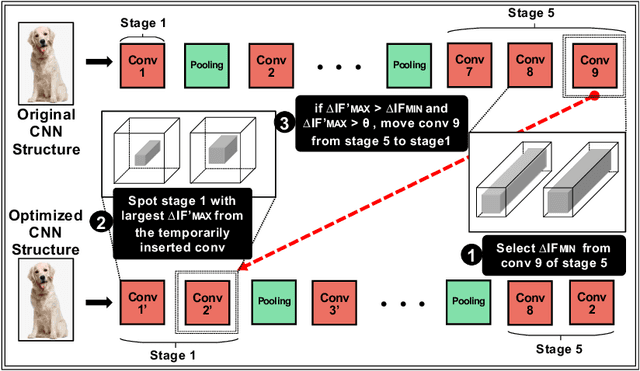
CNN architecture design has attracted tremendous attention of improving model accuracy or reducing model complexity. However, existing works either introduce repeated training overhead in the search process or lack an interpretable metric to guide the design. To clear the hurdles, we propose Information Field (IF), an explainable and easy-to-compute metric, to estimate the quality of a CNN architecture and guide the search process of designs. To validate the effectiveness of IF, we build a static optimizer to improve the CNN architectures at both the stage level and the kernel level. Our optimizer not only provides a clear and reproducible procedure but also mitigates unnecessary training efforts in the architecture search process. Experiments show that the models generated by our optimizer can achieve up to 5.47% accuracy improvement and up to 65.38% parameters deduction, compared with state-of-the-art CNN structures like MobileNet and ResNet.
SGQuant: Squeezing the Last Bit on Graph Neural Networks with Specialized Quantization
Jul 09, 2020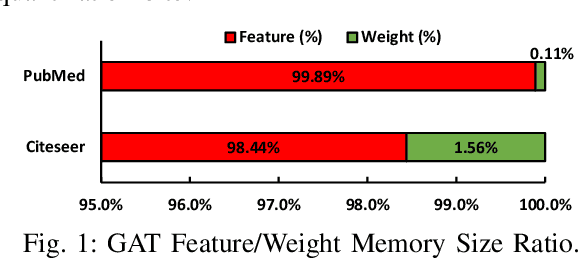
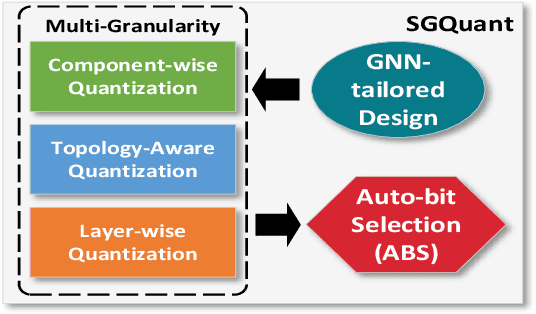
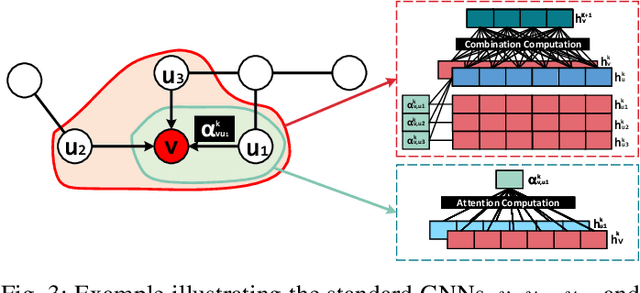
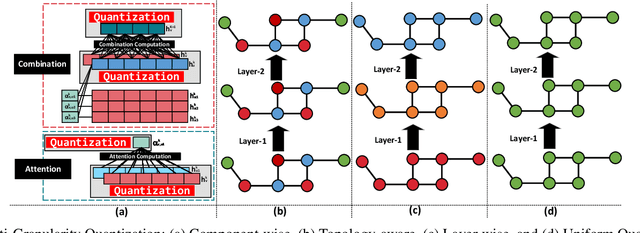
With the increasing popularity of graph-based learning, Graph Neural Networks (GNNs) win lots of attention from the research and industry field because of their high accuracy. However, existing GNNs suffer from high memory footprints (e.g., node embedding features). This high memory footprint hurdles the potential applications towards memory-constrained devices, such as the widely-deployed IoT devices. To this end, we propose a specialized GNN quantization scheme, SGQuant, to systematically reduce the GNN memory consumption. Specifically, we first propose a GNN-tailored quantization algorithm design and a GNN quantization fine-tuning scheme to reduce memory consumption while maintaining accuracy. Then, we investigate the multi-granularity quantization strategy that operates at different levels (components, graph topology, and layers) of GNN computation. Moreover, we offer an automatic bit-selecting (ABS) to pinpoint the most appropriate quantization bits for the above multi-granularity quantizations. Intensive experiments show that SGQuant can effectively reduce the memory footprint from 4.25x to 31.9x compared with the original full-precision GNNs while limiting the accuracy drop to 0.4% on average.
Exploring Adversarial Attack in Spiking Neural Networks with Spike-Compatible Gradient
Jan 01, 2020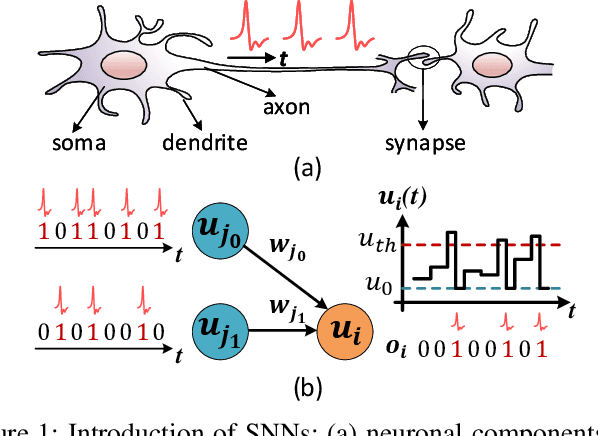
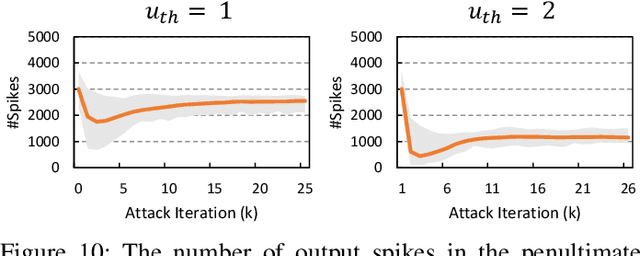
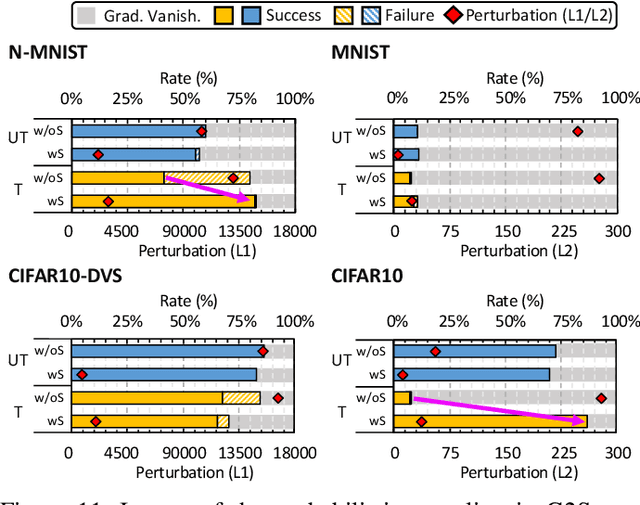
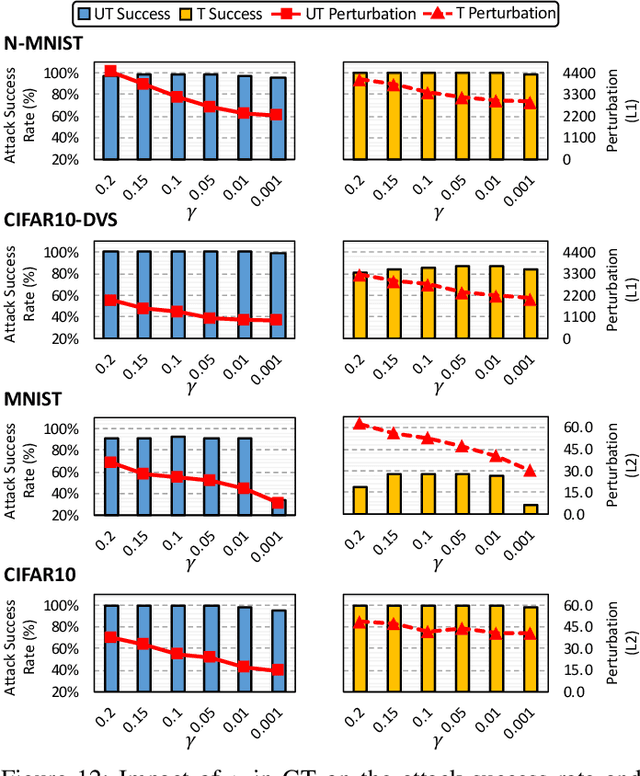
Recently, backpropagation through time inspired learning algorithms are widely introduced into SNNs to improve the performance, which brings the possibility to attack the models accurately given Spatio-temporal gradient maps. We propose two approaches to address the challenges of gradient input incompatibility and gradient vanishing. Specifically, we design a gradient to spike converter to convert continuous gradients to ternary ones compatible with spike inputs. Then, we design a gradient trigger to construct ternary gradients that can randomly flip the spike inputs with a controllable turnover rate, when meeting all zero gradients. Putting these methods together, we build an adversarial attack methodology for SNNs trained by supervised algorithms. Moreover, we analyze the influence of the training loss function and the firing threshold of the penultimate layer, which indicates a "trap" region under the cross-entropy loss that can be escaped by threshold tuning. Extensive experiments are conducted to validate the effectiveness of our solution. Besides the quantitative analysis of the influence factors, we evidence that SNNs are more robust against adversarial attack than ANNs. This work can help reveal what happens in SNN attack and might stimulate more research on the security of SNN models and neuromorphic devices.
Poq: Projection-based Runtime Assertions for Debugging on a Quantum Computer
Nov 28, 2019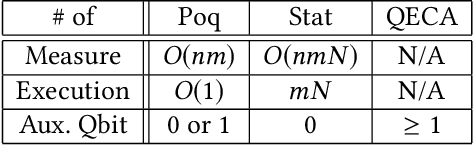
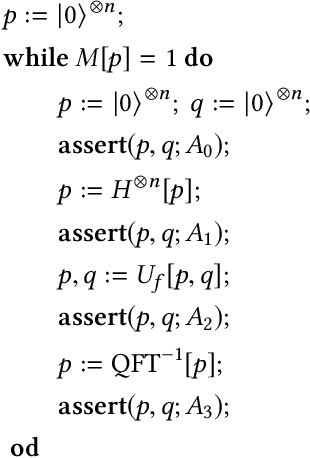
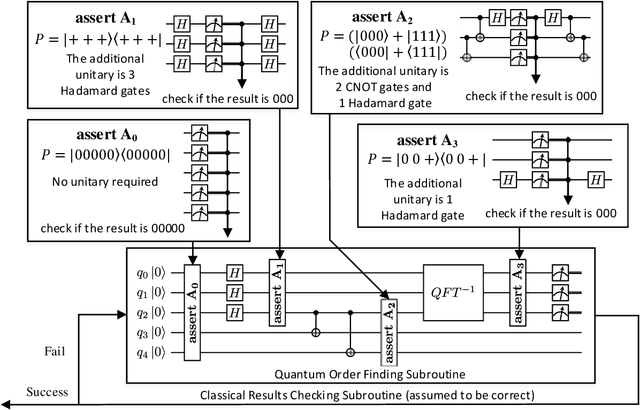
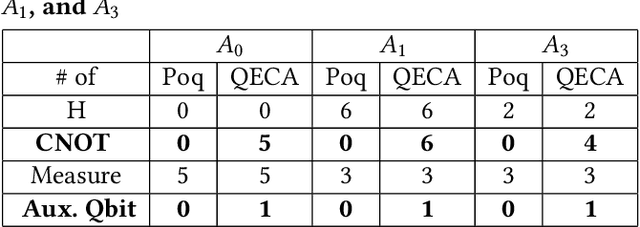
In this paper, we propose Poq, a runtime assertion scheme for debugging on a quantum computer. The predicates in the assertions are represented by projections (or equivalently, closed subspaces of the state space), following Birkhoff-von Neumann quantum logic. The satisfaction of a projection by a quantum state can be directly checked upon a small number of projective measurements rather than a large number of repeated executions. Several techniques are introduced to rotate the predicates to the computational basis, on which a realistic quantum computer usually supports its measurements, so that a satisfying tested state will not be destroyed when an assertion is checked and multi-assertion per testing execution is enabled. We compare Poq with existing quantum program assertions and demonstrate the effectiveness and efficiency of Poq by its applications to assert two sophisticated quantum algorithms.
Comprehensive SNN Compression Using ADMM Optimization and Activity Regularization
Nov 03, 2019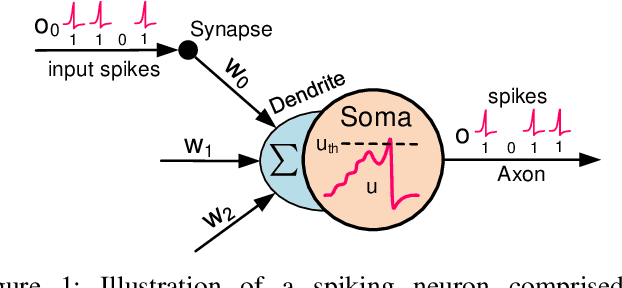
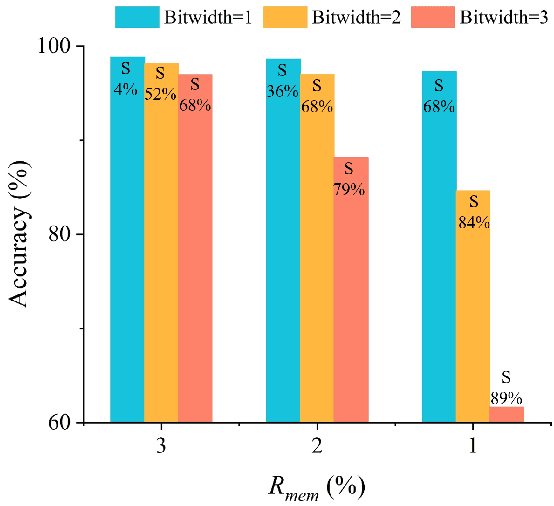
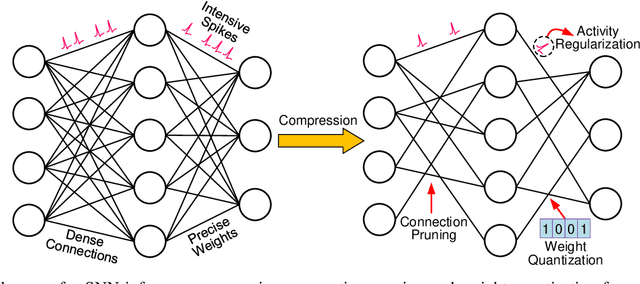
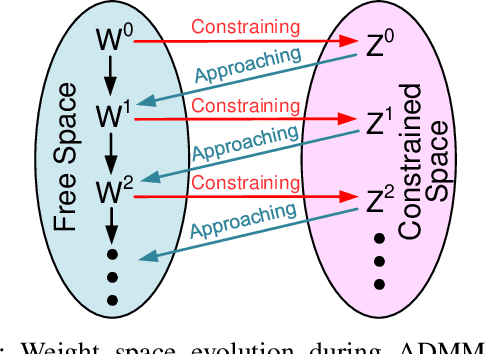
Spiking neural network is an important family of models to emulate the brain, which has been widely adopted by neuromorphic platforms. In the meantime, it is well-known that the huge memory and compute costs of neural networks greatly hinder the execution with high efficiency, especially on edge devices. To this end, model compression is proposed as a promising technique to improve the running efficiency via parameter and operation reduction. Therefore, it is interesting to investigate how much an SNN model can be compressed without compromising much functionality. However, this is quite challenging because SNNs usually behave distinctly from deep learning models. Specifically, i) the accuracy of spike-coded SNNs is usually sensitive to any network change; ii) the computation of SNNs is event-driven rather than static. Here we present a comprehensive SNN compression through three steps. First, we formulate the connection pruning and the weight quantization as a supervised learning-based constrained optimization problem. Second, we combine the emerging spatio-temporal backpropagation and the powerful alternating direction method of multipliers to solve the problem with minimum accuracy loss. Third, we further propose an activity regularization to reduce the spike events for fewer active operations. We define several quantitative metrics to evaluation the compression performance for SNNs and validate our methodology in pattern recognition tasks over MNIST, N-MNIST, and CIFAR10 datasets. Extensive comparisons between different compression strategies, the corresponding result analysis, and some interesting insights are provided. To our best knowledge, this is the first work that studies SNN compression in a comprehensive manner by exploiting all possible compression ways and achieves better results. Our work offers a promising solution to pursue ultra-efficient neuromorphic systems.
Penetrating the Fog: the Path to Efficient CNN Models
Oct 11, 2018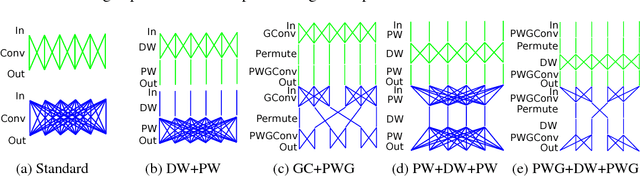
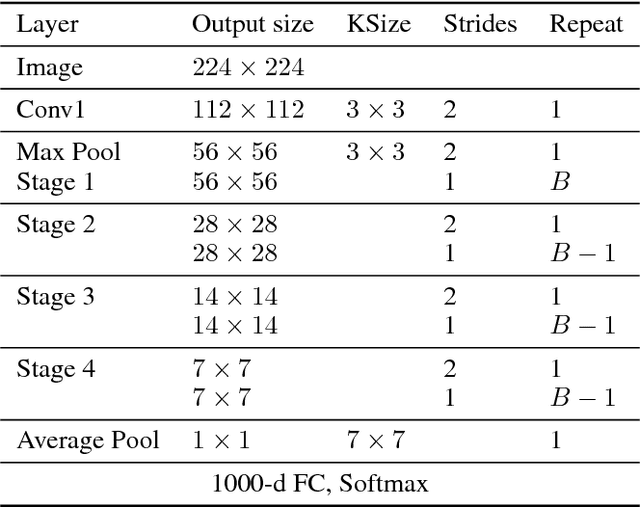
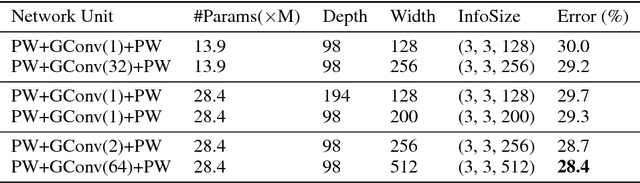
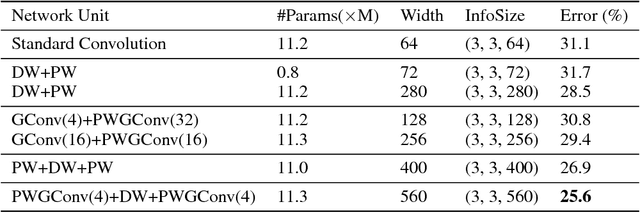
With the increasing demand to deploy convolutional neural networks (CNNs) on mobile platforms, the sparse kernel approach was proposed, which could save more parameters than the standard convolution while maintaining accuracy. However, despite the great potential, no prior research has pointed out how to craft an sparse kernel design with such potential (i.e., effective design), and all prior works just adopt simple combinations of existing sparse kernels such as group convolution. Meanwhile due to the large design space it is also impossible to try all combinations of existing sparse kernels. In this paper, we are the first in the field to consider how to craft an effective sparse kernel design by eliminating the large design space. Specifically, we present a sparse kernel scheme to illustrate how to reduce the space from three aspects. First, in terms of composition we remove designs composed of repeated layers. Second, to remove designs with large accuracy degradation, we find an unified property named information field behind various sparse kernel designs, which could directly indicate the final accuracy. Last, we remove designs in two cases where a better parameter efficiency could be achieved. Additionally, we provide detailed efficiency analysis on the final four designs in our scheme. Experimental results validate the idea of our scheme by showing that our scheme is able to find designs which are more efficient in using parameters and computation with similar or higher accuracy.
Dynamic Sparse Graph for Efficient Deep Learning
Oct 01, 2018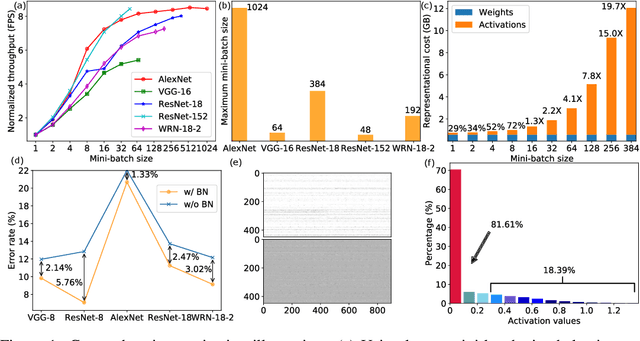
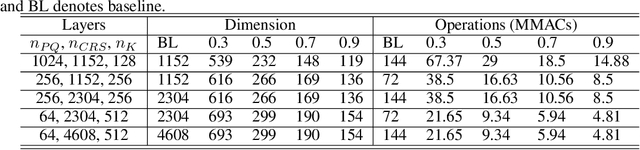
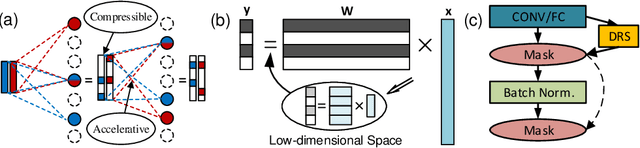
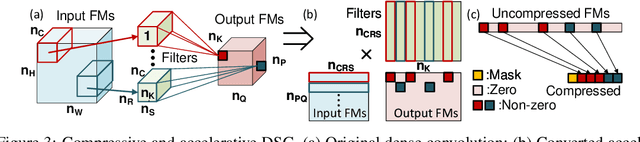
We propose to execute deep neural networks (DNNs) with dynamic and sparse graph (DSG) structure for compressive memory and accelerative execution during both training and inference. The great success of DNNs motivates the pursuing of lightweight models for the deployment onto embedded devices. However, most of the previous studies optimize for inference while neglect training or even complicate it. Training is far more intractable, since (i) the neurons dominate the memory cost rather than the weights in inference; (ii) the dynamic activation makes previous sparse acceleration via one-off optimization on fixed weight invalid; (iii) batch normalization (BN) is critical for maintaining accuracy while its activation reorganization damages the sparsity. To address these issues, DSG activates only a small amount of neurons with high selectivity at each iteration via a dimension-reduction search (DRS) and obtains the BN compatibility via a double-mask selection (DMS). Experiments show significant memory saving (1.7-4.5x) and operation reduction (2.3-4.4x) with little accuracy loss on various benchmarks.
Domain-Adversarial Multi-Task Framework for Novel Therapeutic Property Prediction of Compounds
Sep 28, 2018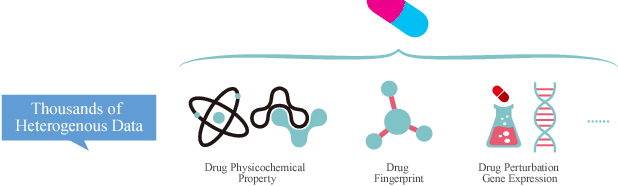

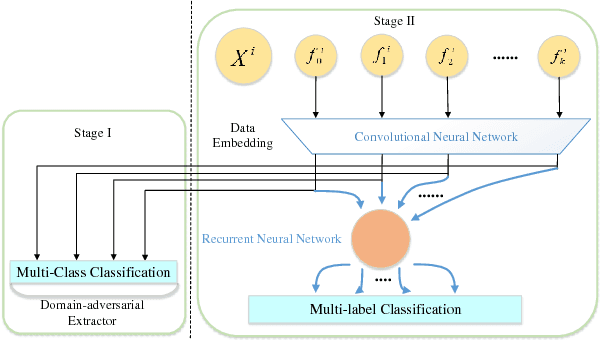
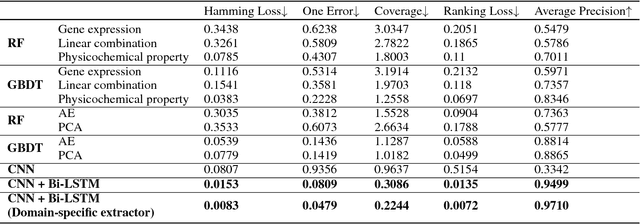
With the rapid development of high-throughput technologies, parallel acquisition of large-scale drug-informatics data provides huge opportunities to improve pharmaceutical research and development. One significant application is the purpose prediction of small molecule compounds, aiming to specify therapeutic properties of extensive purpose-unknown compounds and to repurpose novel therapeutic properties of FDA-approved drugs. Such problem is very challenging since compound attributes contain heterogeneous data with various feature patterns such as drug fingerprint, drug physicochemical property, drug perturbation gene expression. Moreover, there is complex nonlinear dependency among heterogeneous data. In this paper, we propose a novel domain-adversarial multi-task framework for integrating shared knowledge from multiple domains. The framework utilizes the adversarial strategy to effectively learn target representations and models their nonlinear dependency. Experiments on two real-world datasets illustrate that the performance of our approach obtains an obvious improvement over competitive baselines. The novel therapeutic properties of purpose-unknown compounds we predicted are mostly reported or brought to the clinics. Furthermore, our framework can integrate various attributes beyond the three domains examined here and can be applied in the industry for screening the purpose of huge amounts of as yet unidentified compounds. Source codes of this paper are available on Github.