 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText Anchor Based Metric Learning for Small-footprint Keyword Spotting
Aug 12, 2021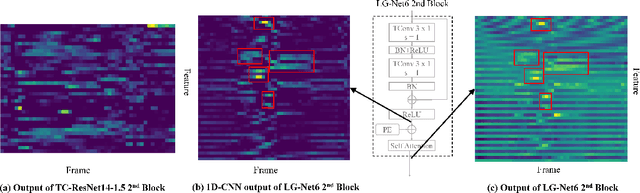

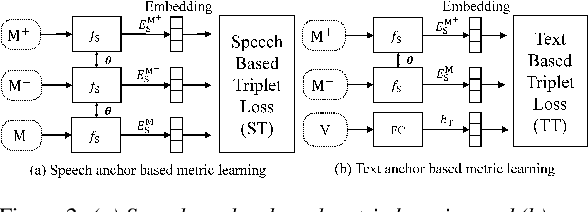
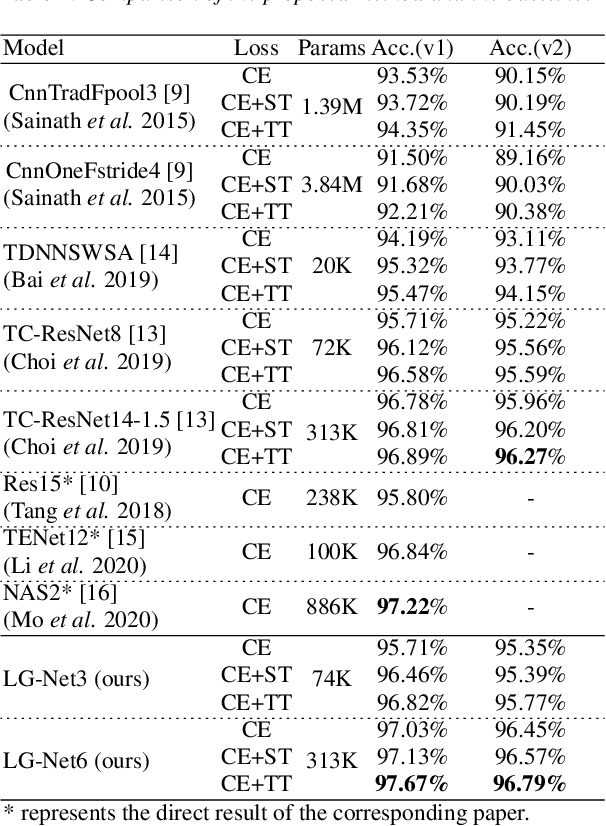
Keyword Spotting (KWS) remains challenging to achieve the trade-off between small footprint and high accuracy. Recently proposed metric learning approaches improved the generalizability of models for the KWS task, and 1D-CNN based KWS models have achieved the state-of-the-arts (SOTA) in terms of model size. However, for metric learning, due to data limitations, the speech anchor is highly susceptible to the acoustic environment and speakers. Also, we note that the 1D-CNN models have limited capability to capture long-term temporal acoustic features. To address the above problems, we propose to utilize text anchors to improve the stability of anchors. Furthermore, a new type of model (LG-Net) is exquisitely designed to promote long-short term acoustic feature modeling based on 1D-CNN and self-attention. Experiments are conducted on Google Speech Commands Dataset version 1 (GSCDv1) and 2 (GSCDv2). The results demonstrate that the proposed text anchor based metric learning method shows consistent improvements over speech anchor on representative CNN-based models. Moreover, our LG-Net model achieves SOTA accuracy of 97.67% and 96.79% on two datasets, respectively. It is encouraged to see that our lighter LG-Net with only 74k parameters obtains 96.82% KWS accuracy on the GSCDv1 and 95.77% KWS accuracy on the GSCDv2.
Audio-Oriented Multimodal Machine Comprehension: Task, Dataset and Model
Jul 04, 2021
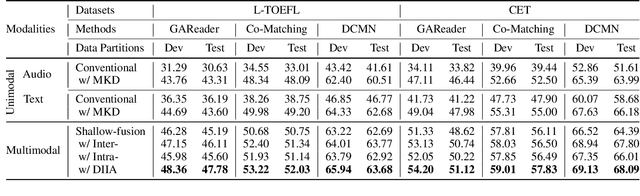
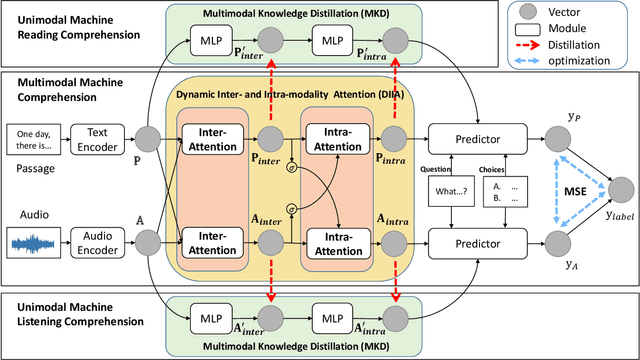
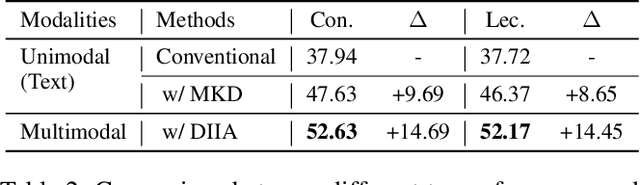
While Machine Comprehension (MC) has attracted extensive research interests in recent years, existing approaches mainly belong to the category of Machine Reading Comprehension task which mines textual inputs (paragraphs and questions) to predict the answers (choices or text spans). However, there are a lot of MC tasks that accept audio input in addition to the textual input, e.g. English listening comprehension test. In this paper, we target the problem of Audio-Oriented Multimodal Machine Comprehension, and its goal is to answer questions based on the given audio and textual information. To solve this problem, we propose a Dynamic Inter- and Intra-modality Attention (DIIA) model to effectively fuse the two modalities (audio and textual). DIIA can work as an independent component and thus be easily integrated into existing MC models. Moreover, we further develop a Multimodal Knowledge Distillation (MKD) module to enable our multimodal MC model to accurately predict the answers based only on either the text or the audio. As a result, the proposed approach can handle various tasks including: Audio-Oriented Multimodal Machine Comprehension, Machine Reading Comprehension and Machine Listening Comprehension, in a single model, making fair comparisons possible between our model and the existing unimodal MC models. Experimental results and analysis prove the effectiveness of the proposed approaches. First, the proposed DIIA boosts the baseline models by up to 21.08% in terms of accuracy; Second, under the unimodal scenarios, the MKD module allows our multimodal MC model to significantly outperform the unimodal models by up to 18.87%, which are trained and tested with only audio or textual data.
Long-Short Temporal Modeling for Efficient Action Recognition
Jun 30, 2021
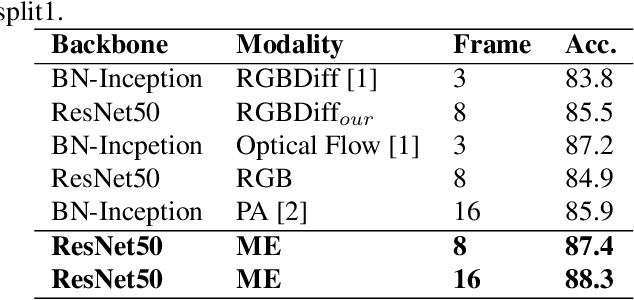
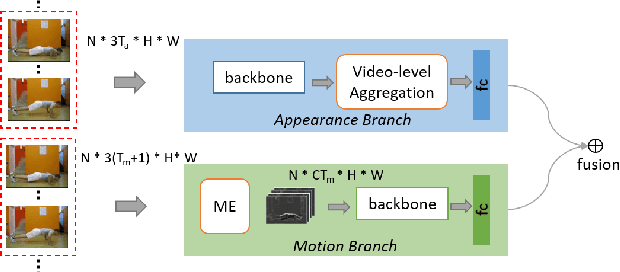
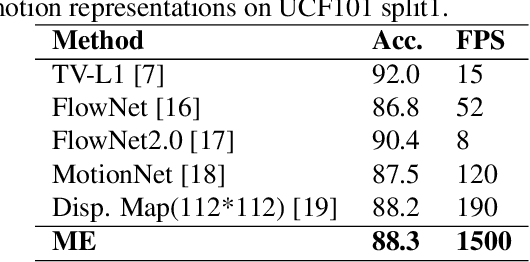
Efficient long-short temporal modeling is key for enhancing the performance of action recognition task. In this paper, we propose a new two-stream action recognition network, termed as MENet, consisting of a Motion Enhancement (ME) module and a Video-level Aggregation (VLA) module to achieve long-short temporal modeling. Specifically, motion representations have been proved effective in capturing short-term and high-frequency action. However, current motion representations are calculated from adjacent frames, which may have poor interpretation and bring useless information (noisy or blank). Thus, for short-term motions, we design an efficient ME module to enhance the short-term motions by mingling the motion saliency among neighboring segments. As for long-term aggregations, VLA is adopted at the top of the appearance branch to integrate the long-term dependencies across all segments. The two components of MENet are complementary in temporal modeling. Extensive experiments are conducted on UCF101 and HMDB51 benchmarks, which verify the effectiveness and efficiency of our proposed MENet.
SRF-Net: Selective Receptive Field Network for Anchor-Free Temporal Action Detection
Jun 29, 2021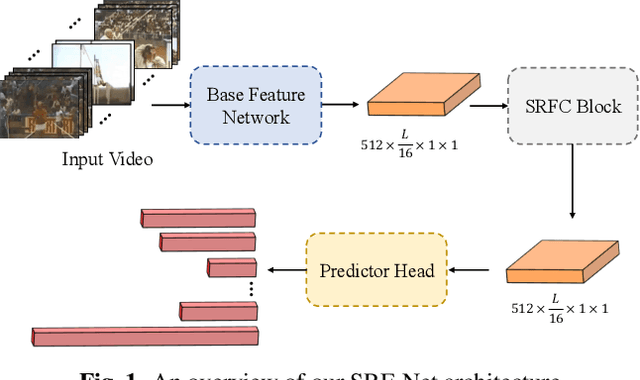
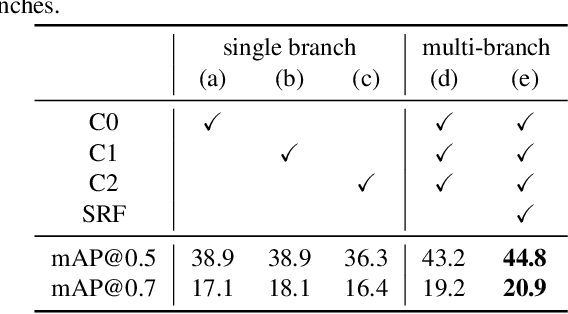
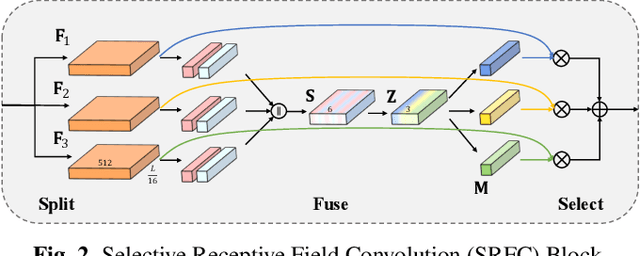
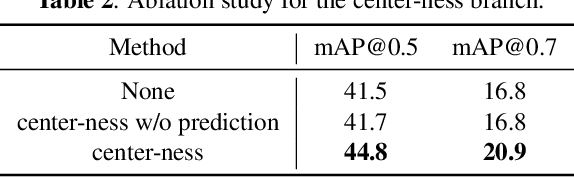
Temporal action detection (TAD) is a challenging task which aims to temporally localize and recognize the human action in untrimmed videos. Current mainstream one-stage TAD approaches localize and classify action proposals relying on pre-defined anchors, where the location and scale for action instances are set by designers. Obviously, such an anchor-based TAD method limits its generalization capability and will lead to performance degradation when videos contain rich action variation. In this study, we explore to remove the requirement of pre-defined anchors for TAD methods. A novel TAD model termed as Selective Receptive Field Network (SRF-Net) is developed, in which the location offsets and classification scores at each temporal location can be directly estimated in the feature map and SRF-Net is trained in an end-to-end manner. Innovatively, a building block called Selective Receptive Field Convolution (SRFC) is dedicatedly designed which is able to adaptively adjust its receptive field size according to multiple scales of input information at each temporal location in the feature map. Extensive experiments are conducted on the THUMOS14 dataset, and superior results are reported comparing to state-of-the-art TAD approaches.
Exploring and Distilling Posterior and Prior Knowledge for Radiology Report Generation
Jun 26, 2021
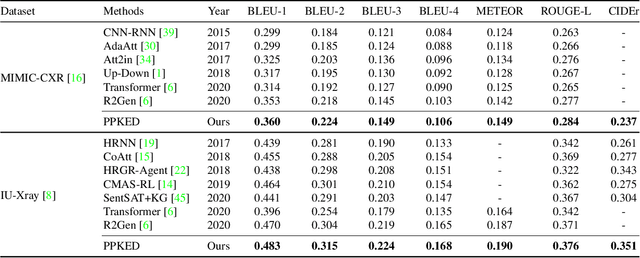
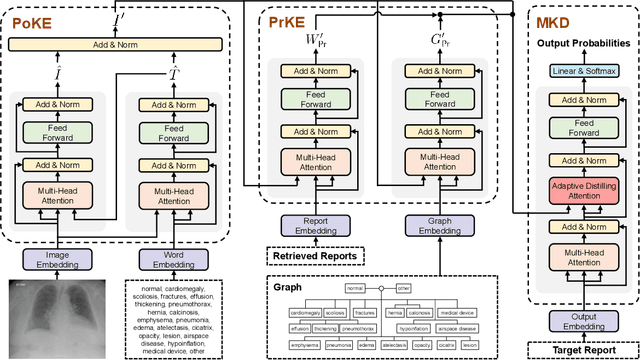
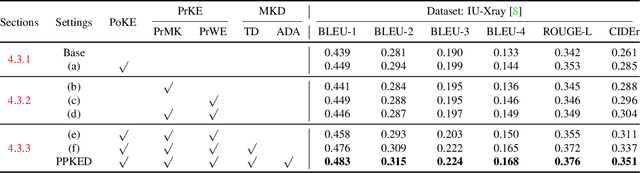
Automatically generating radiology reports can improve current clinical practice in diagnostic radiology. On one hand, it can relieve radiologists from the heavy burden of report writing; On the other hand, it can remind radiologists of abnormalities and avoid the misdiagnosis and missed diagnosis. Yet, this task remains a challenging job for data-driven neural networks, due to the serious visual and textual data biases. To this end, we propose a Posterior-and-Prior Knowledge Exploring-and-Distilling approach (PPKED) to imitate the working patterns of radiologists, who will first examine the abnormal regions and assign the disease topic tags to the abnormal regions, and then rely on the years of prior medical knowledge and prior working experience accumulations to write reports. Thus, the PPKED includes three modules: Posterior Knowledge Explorer (PoKE), Prior Knowledge Explorer (PrKE) and Multi-domain Knowledge Distiller (MKD). In detail, PoKE explores the posterior knowledge, which provides explicit abnormal visual regions to alleviate visual data bias; PrKE explores the prior knowledge from the prior medical knowledge graph (medical knowledge) and prior radiology reports (working experience) to alleviate textual data bias. The explored knowledge is distilled by the MKD to generate the final reports. Evaluated on MIMIC-CXR and IU-Xray datasets, our method is able to outperform previous state-of-the-art models on these two datasets.
Self-supervised Dialogue Learning for Spoken Conversational Question Answering
Jun 24, 2021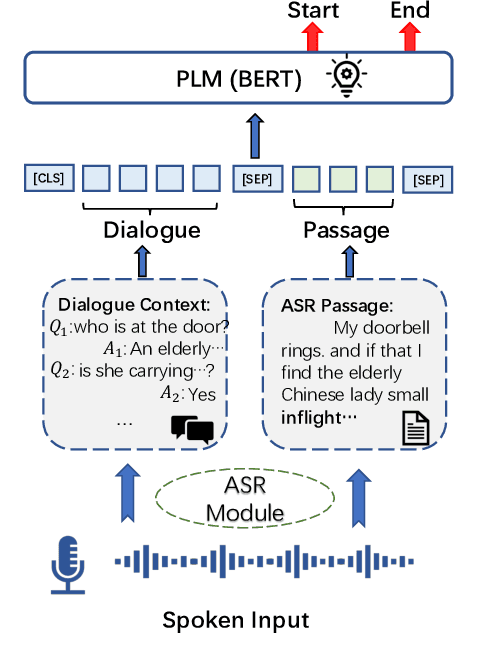
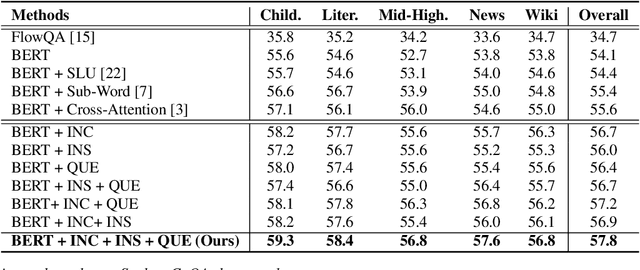
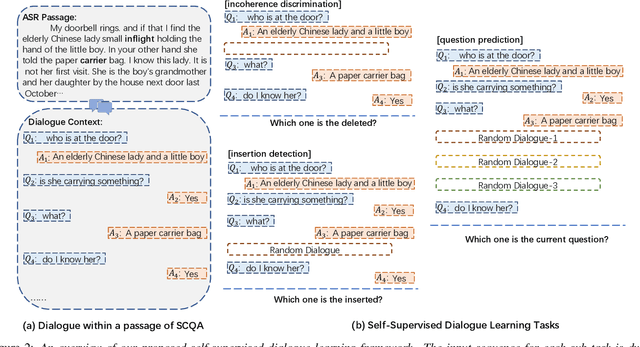
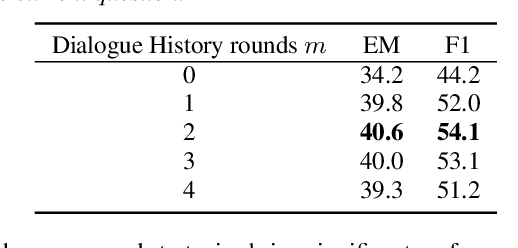
In spoken conversational question answering (SCQA), the answer to the corresponding question is generated by retrieving and then analyzing a fixed spoken document, including multi-part conversations. Most SCQA systems have considered only retrieving information from ordered utterances. However, the sequential order of dialogue is important to build a robust spoken conversational question answering system, and the changes of utterances order may severely result in low-quality and incoherent corpora. To this end, we introduce a self-supervised learning approach, including incoherence discrimination, insertion detection, and question prediction, to explicitly capture the coreference resolution and dialogue coherence among spoken documents. Specifically, we design a joint learning framework where the auxiliary self-supervised tasks can enable the pre-trained SCQA systems towards more coherent and meaningful spoken dialogue learning. We also utilize the proposed self-supervised learning tasks to capture intra-sentence coherence. Experimental results demonstrate that our proposed method provides more coherent, meaningful, and appropriate responses, yielding superior performance gains compared to the original pre-trained language models. Our method achieves state-of-the-art results on the Spoken-CoQA dataset.
All You Need is a Second Look: Towards Arbitrary-Shaped Text Detection
Jun 24, 2021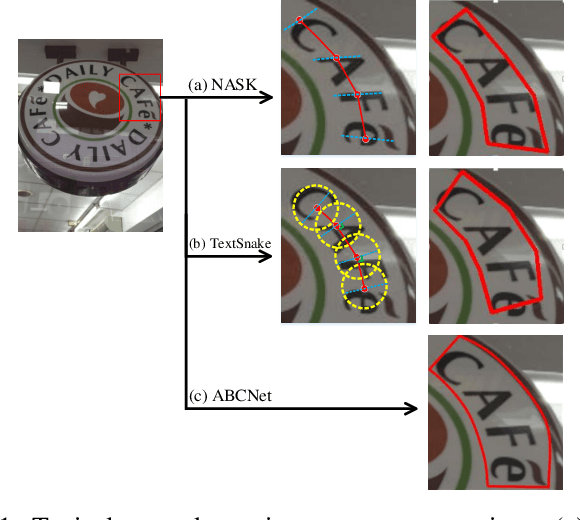
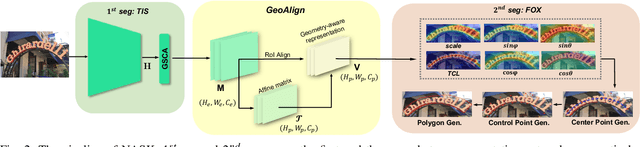
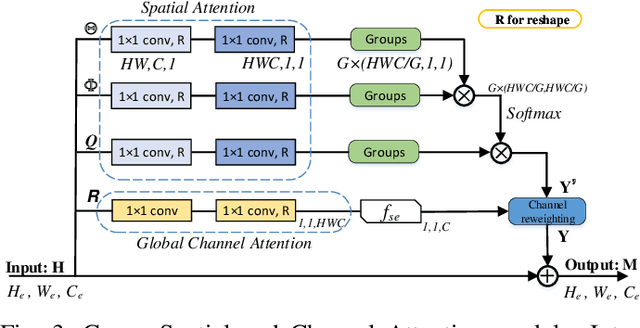

Arbitrary-shaped text detection is a challenging task since curved texts in the wild are of the complex geometric layouts. Existing mainstream methods follow the instance segmentation pipeline to obtain the text regions. However, arbitraryshaped texts are difficult to be depicted through one single segmentation network because of the varying scales. In this paper, we propose a two-stage segmentation-based detector, termed as NASK (Need A Second looK), for arbitrary-shaped text detection. Compared to the traditional single-stage segmentation network, our NASK conducts the detection in a coarse-to-fine manner with the first stage segmentation spotting the rectangle text proposals and the second one retrieving compact representations. Specifically, NASK is composed of a Text Instance Segmentation (TIS) network (1st stage), a Geometry-aware Text RoI Alignment (GeoAlign) module, and a Fiducial pOint eXpression (FOX) module (2nd stage). Firstly, TIS extracts the augmented features with a novel Group Spatial and Channel Attention (GSCA) module and conducts instance segmentation to obtain rectangle proposals. Then, GeoAlign converts these rectangles into the fixed size and encodes RoI-wise feature representation. Finally, FOX disintegrates the text instance into serval pivotal geometrical attributes to refine the detection results. Extensive experimental results on three public benchmarks including Total-Text, SCUTCTW1500, and ICDAR 2015 verify that our NASK outperforms recent state-of-the-art methods.
Exploring Semantic Relationships for Unpaired Image Captioning
Jun 20, 2021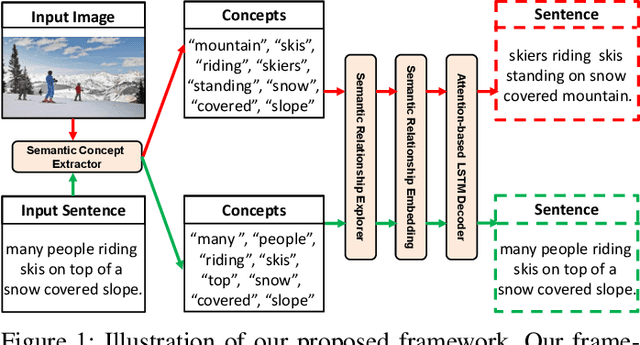
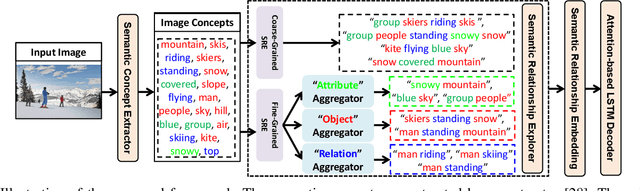
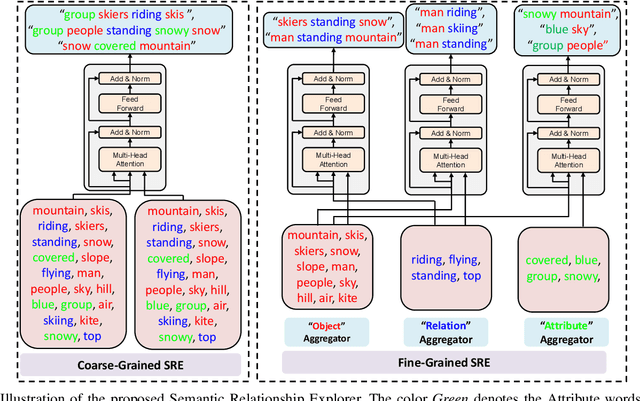

Recently, image captioning has aroused great interest in both academic and industrial worlds. Most existing systems are built upon large-scale datasets consisting of image-sentence pairs, which, however, are time-consuming to construct. In addition, even for the most advanced image captioning systems, it is still difficult to realize deep image understanding. In this work, we achieve unpaired image captioning by bridging the vision and the language domains with high-level semantic information. The motivation stems from the fact that the semantic concepts with the same modality can be extracted from both images and descriptions. To further improve the quality of captions generated by the model, we propose the Semantic Relationship Explorer, which explores the relationships between semantic concepts for better understanding of the image. Extensive experiments on MSCOCO dataset show that we can generate desirable captions without paired datasets. Furthermore, the proposed approach boosts five strong baselines under the paired setting, where the most significant improvement in CIDEr score reaches 8%, demonstrating that it is effective and generalizes well to a wide range of models.
Unsupervised Multi-Target Domain Adaptation for Acoustic Scene Classification
May 21, 2021
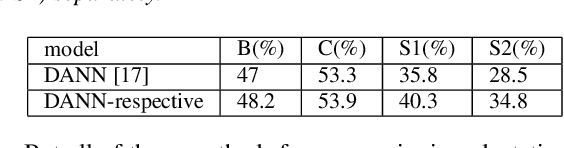
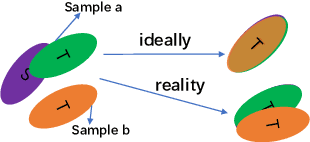
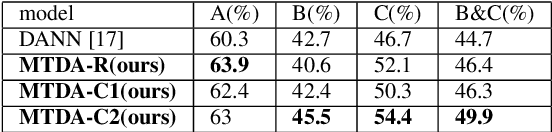
It is well known that the mismatch between training (source) and test (target) data distribution will significantly decrease the performance of acoustic scene classification (ASC) systems. To address this issue, domain adaptation (DA) is one solution and many unsupervised DA methods have been proposed. These methods focus on a scenario of single source domain to single target domain. However, we will face such problem that test data comes from multiple target domains. This problem can be addressed by producing one model per target domain, but this solution is too costly. In this paper, we propose a novel unsupervised multi-target domain adaption (MTDA) method for ASC, which can adapt to multiple target domains simultaneously and make use of the underlying relation among multiple domains. Specifically, our approach combines traditional adversarial adaptation with two novel discriminator tasks that learns a common subspace shared by all domains. Furthermore, we propose to divide the target domain into the easy-to-adapt and hard-to-adapt domain, which enables the system to pay more attention to hard-to-adapt domain in training. The experimental results on the DCASE 2020 Task 1-A dataset and the DCASE 2019 Task 1-B dataset show that our proposed method significantly outperforms the previous unsupervised DA methods.
Rethinking Skip Connection with Layer Normalization in Transformers and ResNets
May 15, 2021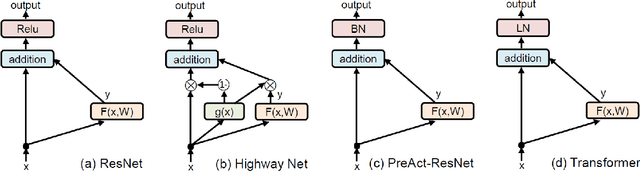
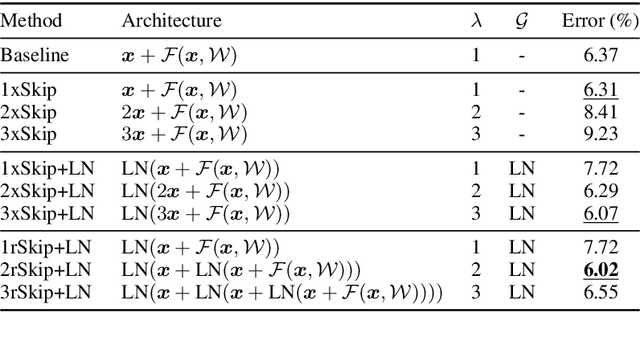
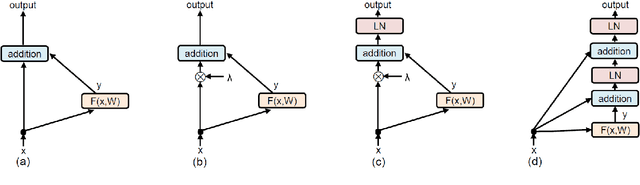

Skip connection, is a widely-used technique to improve the performance and the convergence of deep neural networks, which is believed to relieve the difficulty in optimization due to non-linearity by propagating a linear component through the neural network layers. However, from another point of view, it can also be seen as a modulating mechanism between the input and the output, with the input scaled by a pre-defined value one. In this work, we investigate how the scale factors in the effectiveness of the skip connection and reveal that a trivial adjustment of the scale will lead to spurious gradient exploding or vanishing in line with the deepness of the models, which could be addressed by normalization, in particular, layer normalization, which induces consistent improvements over the plain skip connection. Inspired by the findings, we further propose to adaptively adjust the scale of the input by recursively applying skip connection with layer normalization, which promotes the performance substantially and generalizes well across diverse tasks including both machine translation and image classification datasets.