 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLIP Meets Video Captioners: Attribute-Aware Representation Learning Promotes Accurate Captioning
Nov 30, 2021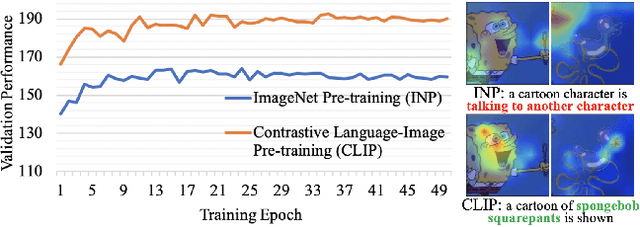
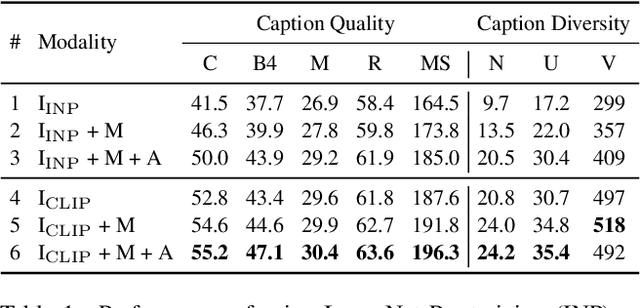
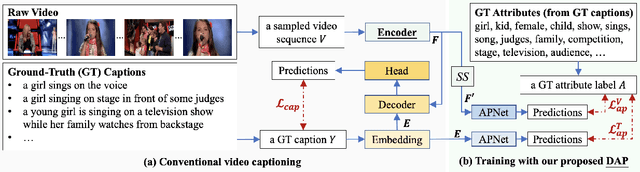

For video captioning, "pre-training and fine-tuning" has become a de facto paradigm, where ImageNet Pre-training (INP) is usually used to help encode the video content, and a task-oriented network is fine-tuned from scratch to cope with caption generation. Comparing INP with the recently proposed CLIP (Contrastive Language-Image Pre-training), this paper investigates the potential deficiencies of INP for video captioning and explores the key to generating accurate descriptions. Specifically, our empirical study on INP vs. CLIP shows that INP makes video caption models tricky to capture attributes' semantics and sensitive to irrelevant background information. By contrast, CLIP's significant boost in caption quality highlights the importance of attribute-aware representation learning. We are thus motivated to introduce Dual Attribute Prediction, an auxiliary task requiring a video caption model to learn the correspondence between video content and attributes and the co-occurrence relations between attributes. Extensive experiments on benchmark datasets demonstrate that our approach enables better learning of attribute-aware representations, bringing consistent improvements on models with different architectures and decoding algorithms.
Improving the Performance of Automated Audio Captioning via Integrating the Acoustic and Semantic Information
Oct 12, 2021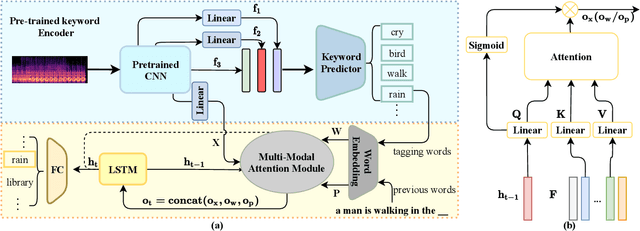
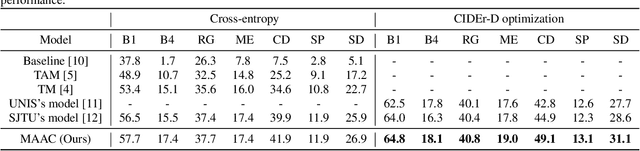
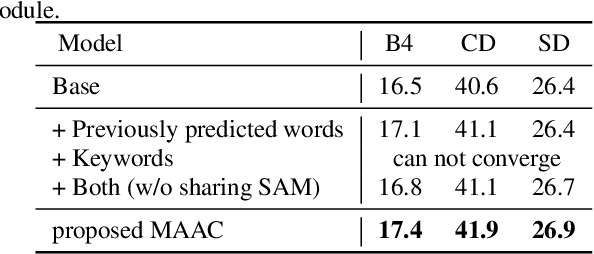
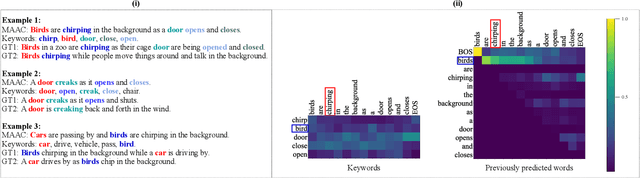
Automated audio captioning (AAC) has developed rapidly in recent years, involving acoustic signal processing and natural language processing to generate human-readable sentences for audio clips. The current models are generally based on the neural encoder-decoder architecture, and their decoder mainly uses acoustic information that is extracted from the CNN-based encoder. However, they have ignored semantic information that could help the AAC model to generate meaningful descriptions. This paper proposes a novel approach for automated audio captioning based on incorporating semantic and acoustic information. Specifically, our audio captioning model consists of two sub-modules. (1) The pre-trained keyword encoder utilizes pre-trained ResNet38 to initialize its parameters, and then it is trained by extracted keywords as labels. (2) The multi-modal attention decoder adopts an LSTM-based decoder that contains semantic and acoustic attention modules. Experiments demonstrate that our proposed model achieves state-of-the-art performance on the Clotho dataset. Our code can be found at https://github.com/WangHelin1997/DCASE2021_Task6_PKU
A Mutual learning framework for Few-shot Sound Event Detection
Oct 09, 2021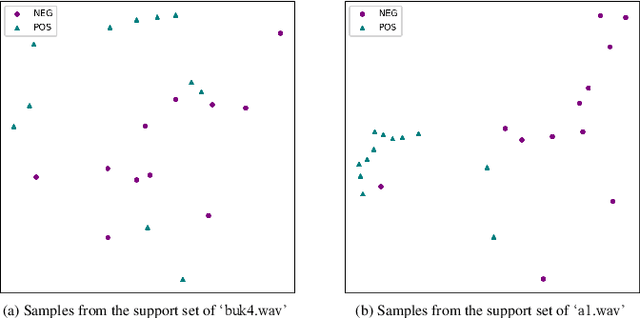
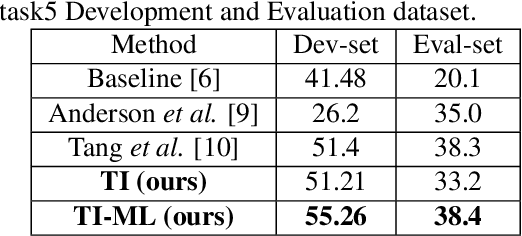
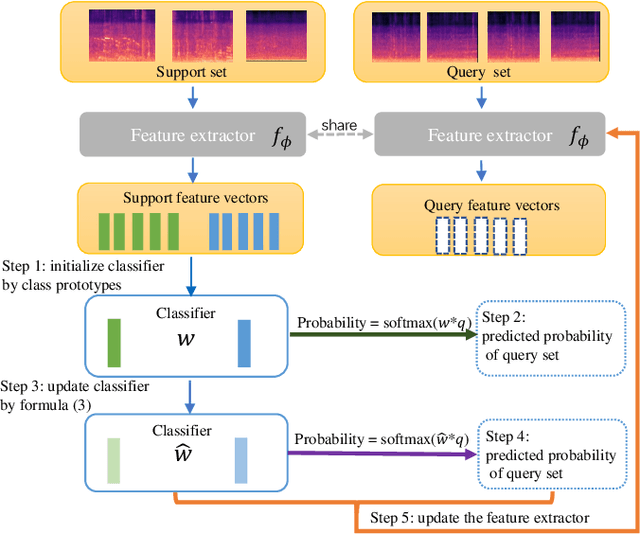
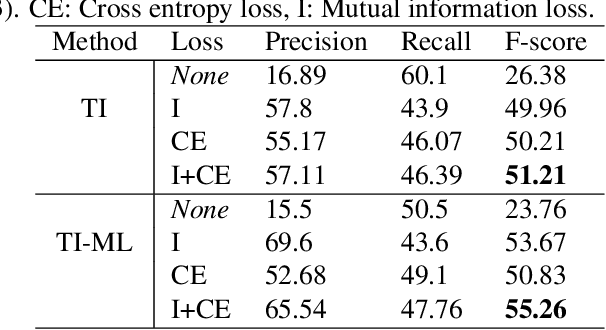
Although prototypical network (ProtoNet) has proved to be an effective method for few-shot sound event detection, two problems still exist. Firstly, the small-scaled support set is insufficient so that the class prototypes may not represent the class center accurately. Secondly, the feature extractor is task-agnostic (or class-agnostic): the feature extractor is trained with base-class data and directly applied to unseen-class data. To address these issues, we present a novel mutual learning framework with transductive learning, which aims at iteratively updating the class prototypes and feature extractor. More specifically, we propose to update class prototypes with transductive inference to make the class prototypes as close to the true class center as possible. To make the feature extractor to be task-specific, we propose to use the updated class prototypes to fine-tune the feature extractor. After that, a fine-tuned feature extractor further helps produce better class prototypes. Our method achieves the F-score of 38.4$\%$ on the DCASE 2021 Task 5 evaluation set, which won the first place in the few-shot bioacoustic event detection task of Detection and Classification of Acoustic Scenes and Events (DCASE) 2021 Challenge.
Towards Joint Intent Detection and Slot Filling via Higher-order Attention
Sep 22, 2021
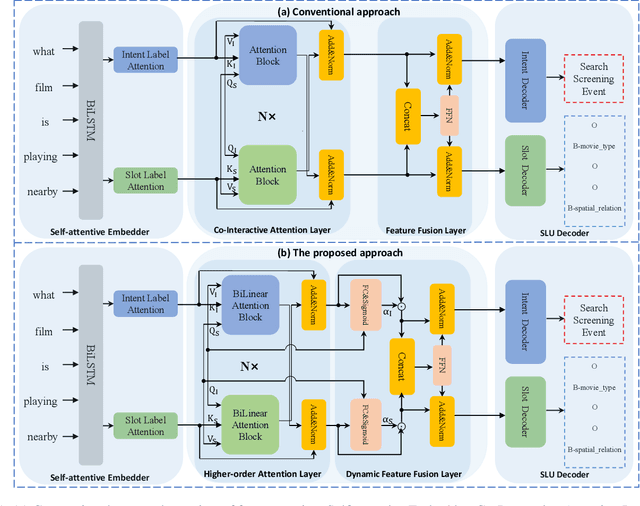
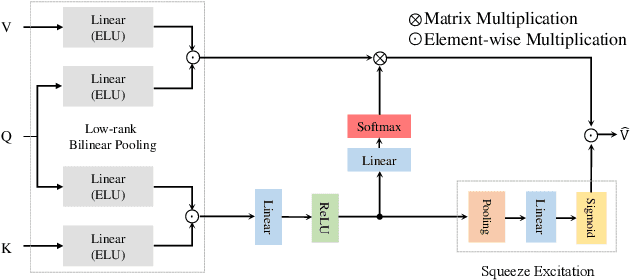
Intent detection (ID) and Slot filling (SF) are two major tasks in spoken language understanding (SLU). Recently, attention mechanism has been shown to be effective in jointly optimizing these two tasks in an interactive manner. However, latest attention-based works concentrated only on the first-order attention design, while ignoring the exploration of higher-order attention mechanisms. In this paper, we propose a BiLinear attention block, which leverages bilinear pooling to simultaneously exploit both the contextual and channel-wise bilinear attention distributions to capture the second-order interactions between the input intent or slot features. Higher and even infinity order interactions are built by stacking numerous blocks and assigning Exponential Linear Unit (ELU) to blocks. Before the decoding stage, we introduce the Dynamic Feature Fusion Layer to implicitly fuse intent and slot information in a more effective way. Technically, instead of simply concatenating intent and slot features, we first compute two correlation matrices to weight on two features. Furthermore, we present Higher-order Attention Network for the SLU tasks. Experiments on two benchmark datasets show that our approach yields improvements compared with the state-of-the-art approach. We also provide discussion to demonstrate the effectiveness of the proposed approach.
On Pursuit of Designing Multi-modal Transformer for Video Grounding
Sep 13, 2021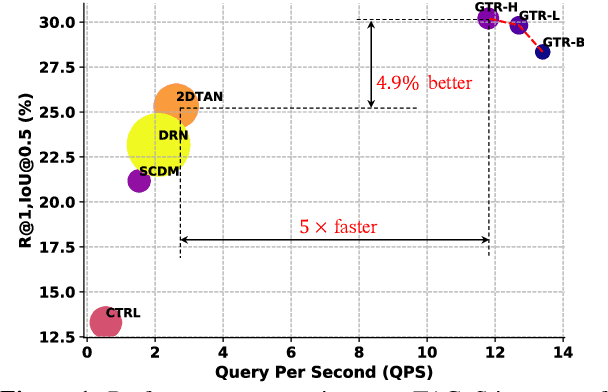

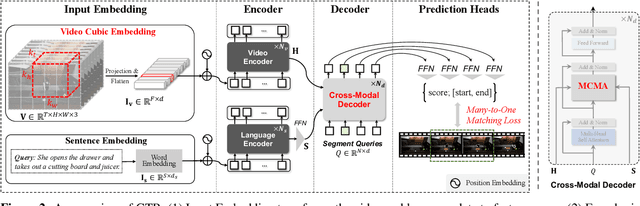
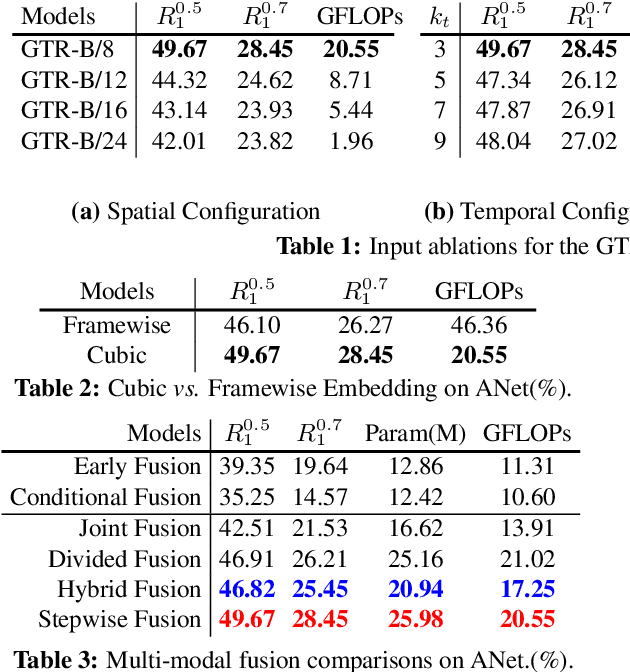
Video grounding aims to localize the temporal segment corresponding to a sentence query from an untrimmed video. Almost all existing video grounding methods fall into two frameworks: 1) Top-down model: It predefines a set of segment candidates and then conducts segment classification and regression. 2) Bottom-up model: It directly predicts frame-wise probabilities of the referential segment boundaries. However, all these methods are not end-to-end, \ie, they always rely on some time-consuming post-processing steps to refine predictions. To this end, we reformulate video grounding as a set prediction task and propose a novel end-to-end multi-modal Transformer model, dubbed as \textbf{GTR}. Specifically, GTR has two encoders for video and language encoding, and a cross-modal decoder for grounding prediction. To facilitate the end-to-end training, we use a Cubic Embedding layer to transform the raw videos into a set of visual tokens. To better fuse these two modalities in the decoder, we design a new Multi-head Cross-Modal Attention. The whole GTR is optimized via a Many-to-One matching loss. Furthermore, we conduct comprehensive studies to investigate different model design choices. Extensive results on three benchmarks have validated the superiority of GTR. All three typical GTR variants achieve record-breaking performance on all datasets and metrics, with several times faster inference speed.
Self-supervised Contrastive Cross-Modality Representation Learning for Spoken Question Answering
Sep 08, 2021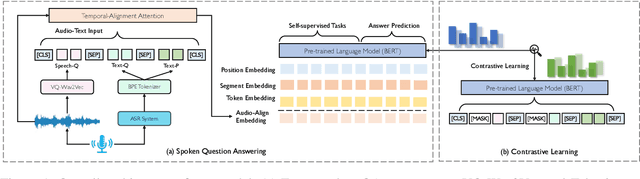


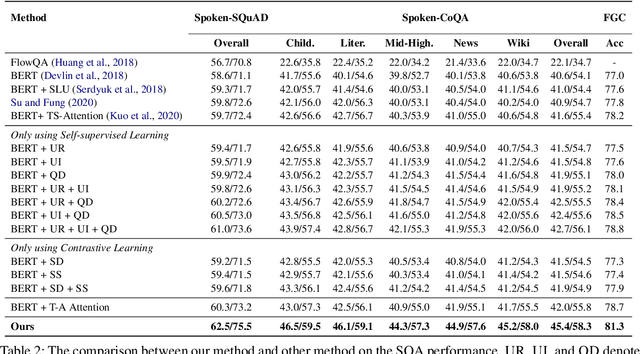
Spoken question answering (SQA) requires fine-grained understanding of both spoken documents and questions for the optimal answer prediction. In this paper, we propose novel training schemes for spoken question answering with a self-supervised training stage and a contrastive representation learning stage. In the self-supervised stage, we propose three auxiliary self-supervised tasks, including utterance restoration, utterance insertion, and question discrimination, and jointly train the model to capture consistency and coherence among speech documents without any additional data or annotations. We then propose to learn noise-invariant utterance representations in a contrastive objective by adopting multiple augmentation strategies, including span deletion and span substitution. Besides, we design a Temporal-Alignment attention to semantically align the speech-text clues in the learned common space and benefit the SQA tasks. By this means, the training schemes can more effectively guide the generation model to predict more proper answers. Experimental results show that our model achieves state-of-the-art results on three SQA benchmarks.
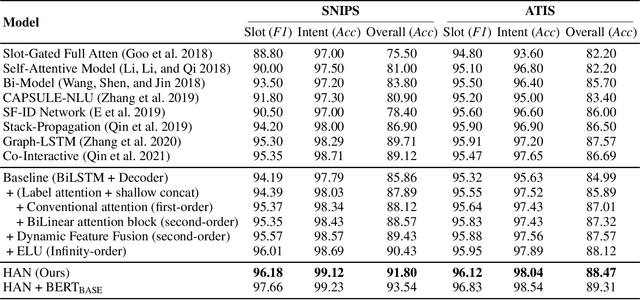
HAN: Higher-order Attention Network for Spoken Language Understanding
Aug 26, 2021
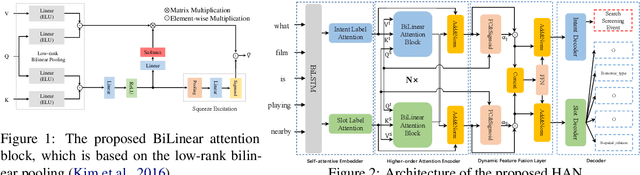
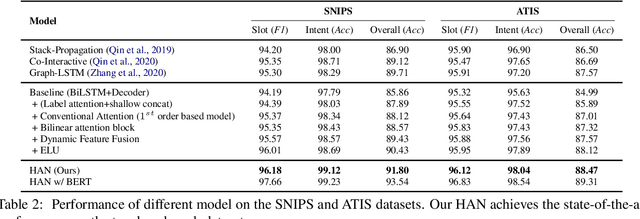
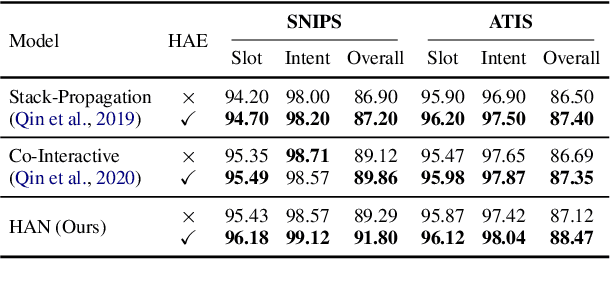
Spoken Language Understanding (SLU), including intent detection and slot filling, is a core component in human-computer interaction. The natural attributes of the relationship among the two subtasks make higher requirements on fine-grained feature interaction, i.e., the token-level intent features and slot features. Previous works mainly focus on jointly modeling the relationship between the two subtasks with attention-based models, while ignoring the exploration of attention order. In this paper, we propose to replace the conventional attention with our proposed Bilinear attention block and show that the introduced Higher-order Attention Network (HAN) brings improvement for the SLU task. Importantly, we conduct wide analysis to explore the effectiveness brought from the higher-order attention.
Fully Non-Homogeneous Atmospheric Scattering Modeling with Convolutional Neural Networks for Single Image Dehazing
Aug 25, 2021
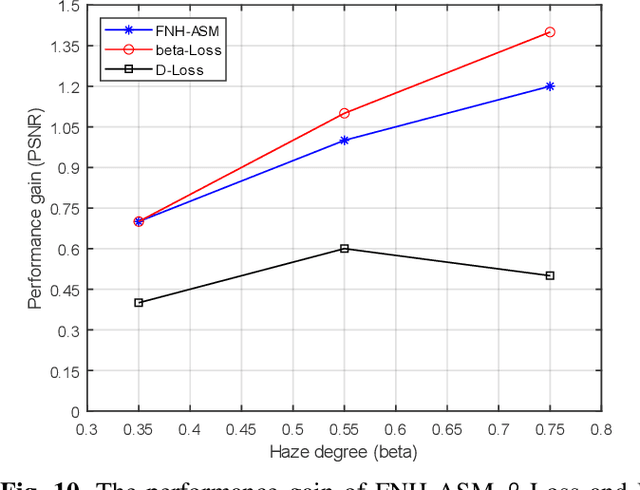


In recent years, single image dehazing models (SIDM) based on atmospheric scattering model (ASM) have achieved remarkable results. However, it is noted that ASM-based SIDM degrades its performance in dehazing real world hazy images due to the limited modelling ability of ASM where the atmospheric light factor (ALF) and the angular scattering coefficient (ASC) are assumed as constants for one image. Obviously, the hazy images taken in real world cannot always satisfy this assumption. Such generating modelling mismatch between the real-world images and ASM sets up the upper bound of trained ASM-based SIDM for dehazing. Bearing this in mind, in this study, a new fully non-homogeneous atmospheric scattering model (FNH-ASM) is proposed for well modeling the hazy images under complex conditions where ALF and ASC are pixel dependent. However, FNH-ASM brings difficulty in practical application. In FNH-ASM based SIDM, the estimation bias of parameters at different positions lead to different distortion of dehazing result. Hence, in order to reduce the influence of parameter estimation bias on dehazing results, two new cost sensitive loss functions, beta-Loss and D-Loss, are innovatively developed for limiting the parameter bias of sensitive positions that have a greater impact on the dehazing result. In the end, based on FNH-ASM, an end-to-end CNN-based dehazing network, FNHD-Net, is developed, which applies beta-Loss and D-Loss. Experimental results demonstrate the effectiveness and superiority of our proposed FNHD-Net for dehazing on both synthetic and real-world images. And the performance improvement of our method increases more obviously in dense and heterogeneous haze scenes.
Joint Multiple Intent Detection and Slot Filling via Self-distillation
Aug 18, 2021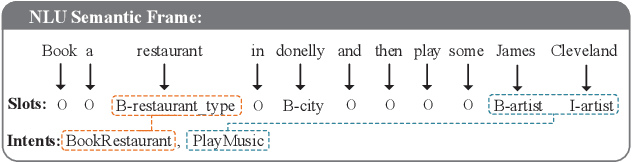
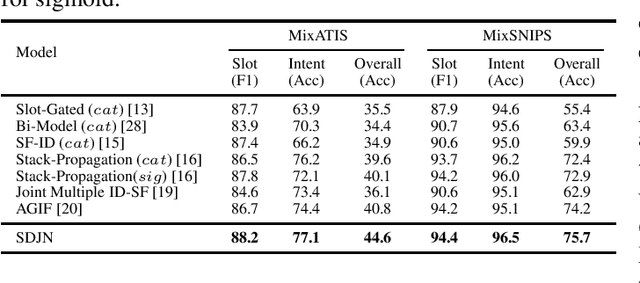
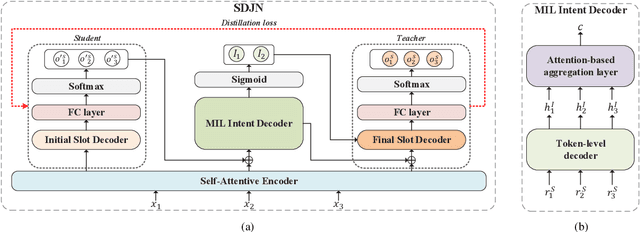
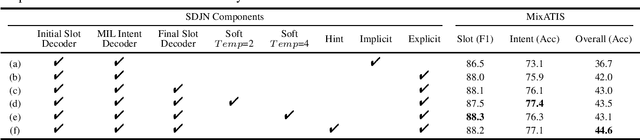
Intent detection and slot filling are two main tasks in natural language understanding (NLU) for identifying users' needs from their utterances. These two tasks are highly related and often trained jointly. However, most previous works assume that each utterance only corresponds to one intent, ignoring the fact that a user utterance in many cases could include multiple intents. In this paper, we propose a novel Self-Distillation Joint NLU model (SDJN) for multi-intent NLU. First, we formulate multiple intent detection as a weakly supervised problem and approach with multiple instance learning (MIL). Then, we design an auxiliary loop via self-distillation with three orderly arranged decoders: Initial Slot Decoder, MIL Intent Decoder, and Final Slot Decoder. The output of each decoder will serve as auxiliary information for the next decoder. With the auxiliary knowledge provided by the MIL Intent Decoder, we set Final Slot Decoder as the teacher model that imparts knowledge back to Initial Slot Decoder to complete the loop. The auxiliary loop enables intents and slots to guide mutually in-depth and further boost the overall NLU performance. Experimental results on two public multi-intent datasets indicate that our model achieves strong performance compared to others.
Deep Motion Prior for Weakly-Supervised Temporal Action Localization
Aug 12, 2021
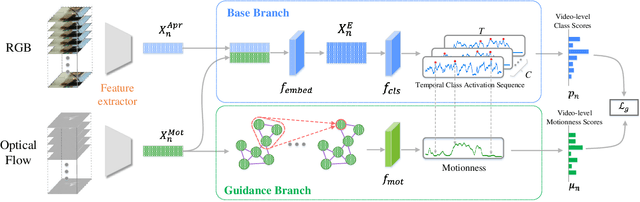
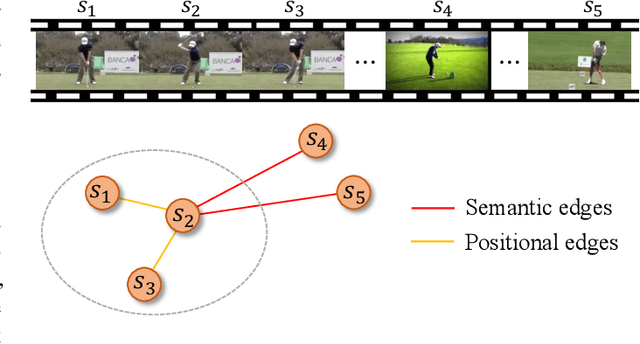
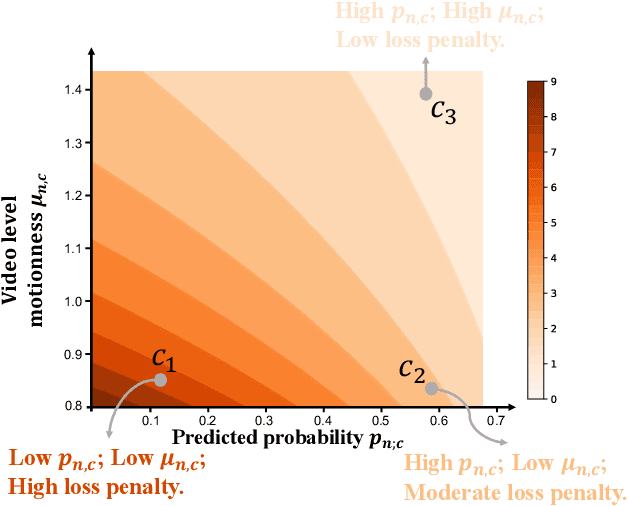
Weakly-Supervised Temporal Action Localization (WSTAL) aims to localize actions in untrimmed videos with only video-level labels. Currently, most state-of-the-art WSTAL methods follow a Multi-Instance Learning (MIL) pipeline: producing snippet-level predictions first and then aggregating to the video-level prediction. However, we argue that existing methods have overlooked two important drawbacks: 1) inadequate use of motion information and 2) the incompatibility of prevailing cross-entropy training loss. In this paper, we analyze that the motion cues behind the optical flow features are complementary informative. Inspired by this, we propose to build a context-dependent motion prior, termed as motionness. Specifically, a motion graph is introduced to model motionness based on the local motion carrier (e.g., optical flow). In addition, to highlight more informative video snippets, a motion-guided loss is proposed to modulate the network training conditioned on motionness scores. Extensive ablation studies confirm that motionness efficaciously models action-of-interest, and the motion-guided loss leads to more accurate results. Besides, our motion-guided loss is a plug-and-play loss function and is applicable with existing WSTAL methods. Without loss of generality, based on the standard MIL pipeline, our method achieves new state-of-the-art performance on three challenging benchmarks, including THUMOS'14, ActivityNet v1.2 and v1.3.