 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiMBERT: Learning Vision-Language Grounded Representations with Disentangled Multimodal-Attention
Oct 28, 2022



Vision-and-language (V-L) tasks require the system to understand both vision content and natural language, thus learning fine-grained joint representations of vision and language (a.k.a. V-L representations) is of paramount importance. Recently, various pre-trained V-L models are proposed to learn V-L representations and achieve improved results in many tasks. However, the mainstream models process both vision and language inputs with the same set of attention matrices. As a result, the generated V-L representations are entangled in one common latent space. To tackle this problem, we propose DiMBERT (short for Disentangled Multimodal-Attention BERT), which is a novel framework that applies separated attention spaces for vision and language, and the representations of multi-modalities can thus be disentangled explicitly. To enhance the correlation between vision and language in disentangled spaces, we introduce the visual concepts to DiMBERT which represent visual information in textual format. In this manner, visual concepts help to bridge the gap between the two modalities. We pre-train DiMBERT on a large amount of image-sentence pairs on two tasks: bidirectional language modeling and sequence-to-sequence language modeling. After pre-train, DiMBERT is further fine-tuned for the downstream tasks. Experiments show that DiMBERT sets new state-of-the-art performance on three tasks (over four datasets), including both generation tasks (image captioning and visual storytelling) and classification tasks (referring expressions). The proposed DiM (short for Disentangled Multimodal-Attention) module can be easily incorporated into existing pre-trained V-L models to boost their performance, up to a 5% increase on the representative task. Finally, we conduct a systematic analysis and demonstrate the effectiveness of our DiM and the introduced visual concepts.
Video Referring Expression Comprehension via Transformer with Content-aware Query
Oct 06, 2022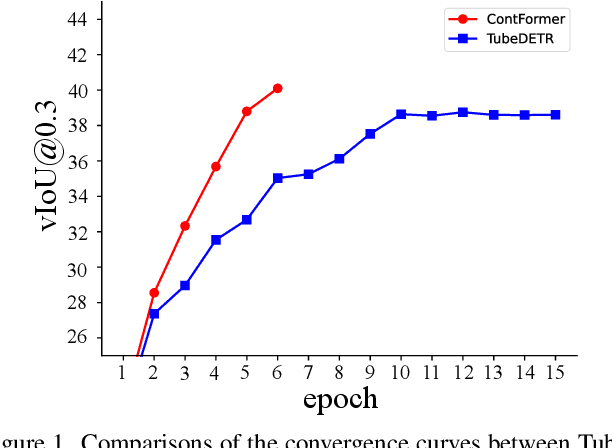
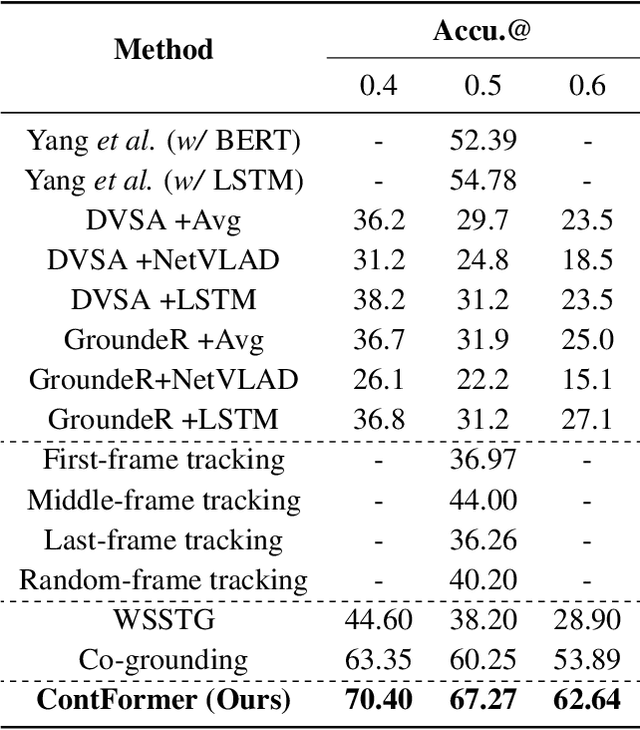

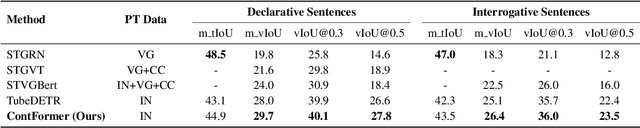
Video Referring Expression Comprehension (REC) aims to localize a target object in video frames referred by the natural language expression. Recently, the Transformerbased methods have greatly boosted the performance limit. However, we argue that the current query design is suboptima and suffers from two drawbacks: 1) the slow training convergence process; 2) the lack of fine-grained alignment. To alleviate this, we aim to couple the pure learnable queries with the content information. Specifically, we set up a fixed number of learnable bounding boxes across the frame and the aligned region features are employed to provide fruitful clues. Besides, we explicitly link certain phrases in the sentence to the semantically relevant visual areas. To this end, we introduce two new datasets (i.e., VID-Entity and VidSTG-Entity) by augmenting the VIDSentence and VidSTG datasets with the explicitly referred words in the whole sentence, respectively. Benefiting from this, we conduct the fine-grained cross-modal alignment at the region-phrase level, which ensures more detailed feature representations. Incorporating these two designs, our proposed model (dubbed as ContFormer) achieves the state-of-the-art performance on widely benchmarked datasets. For example on VID-Entity dataset, compared to the previous SOTA, ContFormer achieves 8.75% absolute improvement on Accu.@0.6.
Correspondence Matters for Video Referring Expression Comprehension
Jul 21, 2022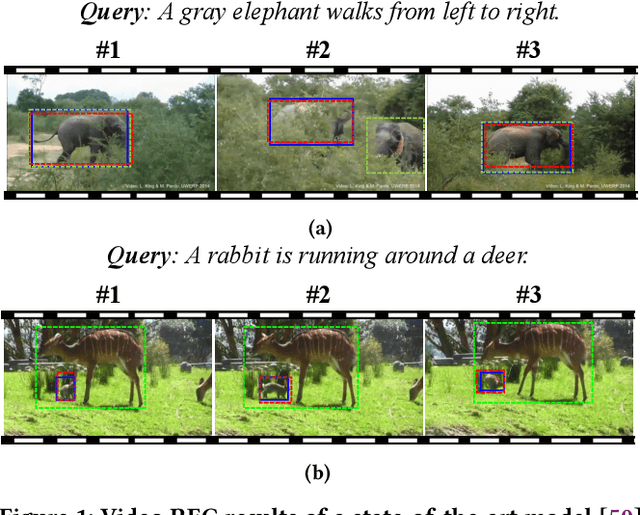
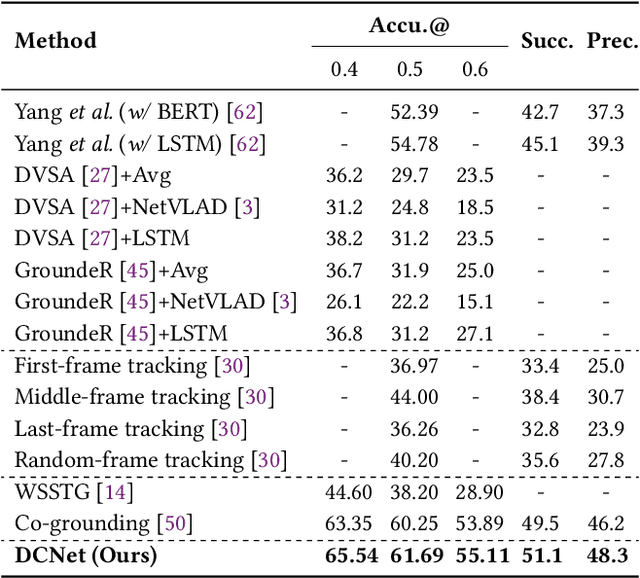

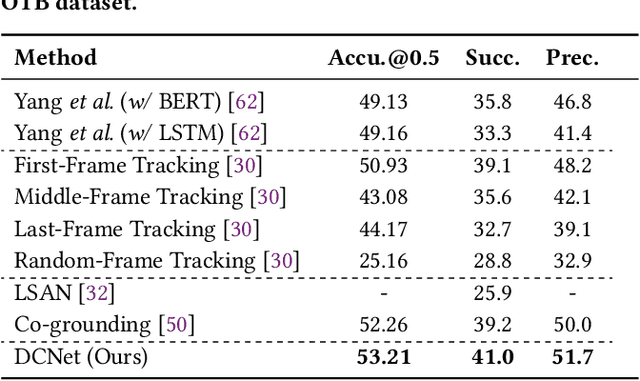
We investigate the problem of video Referring Expression Comprehension (REC), which aims to localize the referent objects described in the sentence to visual regions in the video frames. Despite the recent progress, existing methods suffer from two problems: 1) inconsistent localization results across video frames; 2) confusion between the referent and contextual objects. To this end, we propose a novel Dual Correspondence Network (dubbed as DCNet) which explicitly enhances the dense associations in both the inter-frame and cross-modal manners. Firstly, we aim to build the inter-frame correlations for all existing instances within the frames. Specifically, we compute the inter-frame patch-wise cosine similarity to estimate the dense alignment and then perform the inter-frame contrastive learning to map them close in feature space. Secondly, we propose to build the fine-grained patch-word alignment to associate each patch with certain words. Due to the lack of this kind of detailed annotations, we also predict the patch-word correspondence through the cosine similarity. Extensive experiments demonstrate that our DCNet achieves state-of-the-art performance on both video and image REC benchmarks. Furthermore, we conduct comprehensive ablation studies and thorough analyses to explore the optimal model designs. Notably, our inter-frame and cross-modal contrastive losses are plug-and-play functions and are applicable to any video REC architectures. For example, by building on top of Co-grounding, we boost the performance by 1.48% absolute improvement on Accu.@0.5 for VID-Sentence dataset.
LocVTP: Video-Text Pre-training for Temporal Localization
Jul 21, 2022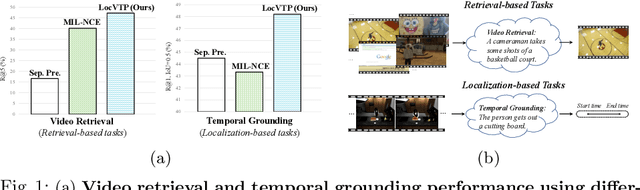
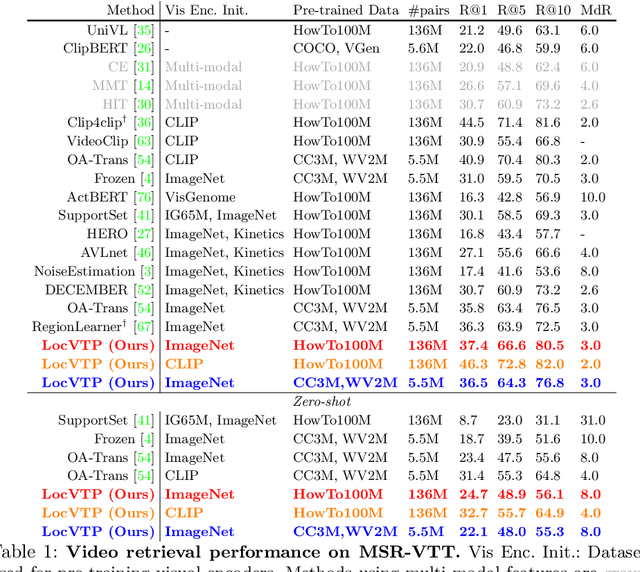
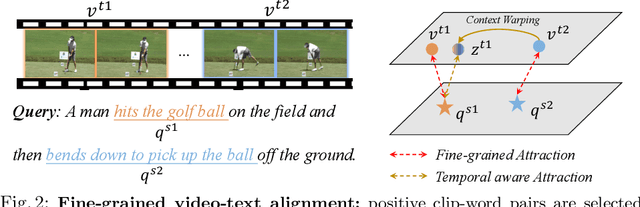
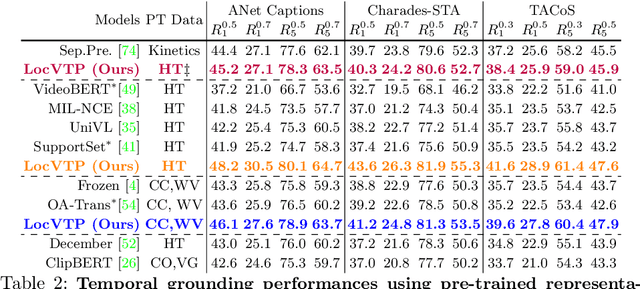
Video-Text Pre-training (VTP) aims to learn transferable representations for various downstream tasks from large-scale web videos. To date, almost all existing VTP methods are limited to retrieval-based downstream tasks, e.g., video retrieval, whereas their transfer potentials on localization-based tasks, e.g., temporal grounding, are under-explored. In this paper, we experimentally analyze and demonstrate the incompatibility of current VTP methods with localization tasks, and propose a novel Localization-oriented Video-Text Pre-training framework, dubbed as LocVTP. Specifically, we perform the fine-grained contrastive alignment as a complement to the coarse-grained one by a clip-word correspondence discovery scheme. To further enhance the temporal reasoning ability of the learned feature, we propose a context projection head and a temporal aware contrastive loss to perceive the contextual relationships. Extensive experiments on four downstream tasks across six datasets demonstrate that our LocVTP achieves state-of-the-art performance on both retrieval-based and localization-based tasks. Furthermore, we conduct comprehensive ablation studies and thorough analyses to explore the optimum model designs and training strategies.
Diffsound: Discrete Diffusion Model for Text-to-sound Generation
Jul 20, 2022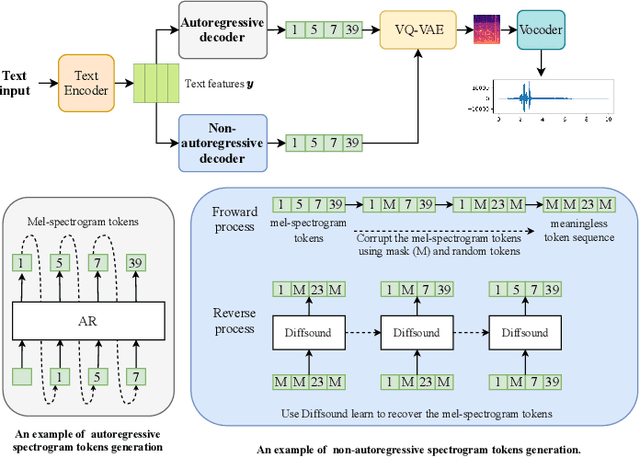
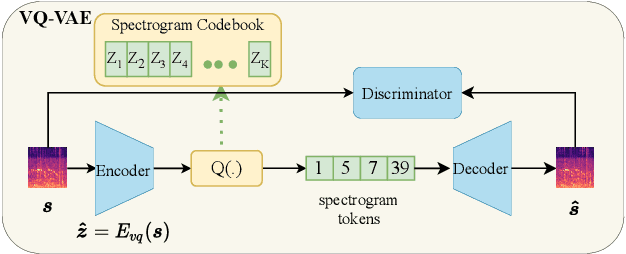
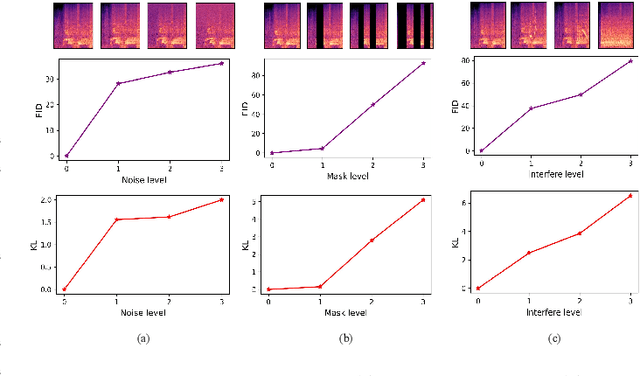

Generating sound effects that humans want is an important topic. However, there are few studies in this area for sound generation. In this study, we investigate generating sound conditioned on a text prompt and propose a novel text-to-sound generation framework that consists of a text encoder, a Vector Quantized Variational Autoencoder (VQ-VAE), a decoder, and a vocoder. The framework first uses the decoder to transfer the text features extracted from the text encoder to a mel-spectrogram with the help of VQ-VAE, and then the vocoder is used to transform the generated mel-spectrogram into a waveform. We found that the decoder significantly influences the generation performance. Thus, we focus on designing a good decoder in this study. We begin with the traditional autoregressive decoder, which has been proved as a state-of-the-art method in previous sound generation works. However, the AR decoder always predicts the mel-spectrogram tokens one by one in order, which introduces the unidirectional bias and accumulation of errors problems. Moreover, with the AR decoder, the sound generation time increases linearly with the sound duration. To overcome the shortcomings introduced by AR decoders, we propose a non-autoregressive decoder based on the discrete diffusion model, named Diffsound. Specifically, the Diffsound predicts all of the mel-spectrogram tokens in one step and then refines the predicted tokens in the next step, so the best-predicted results can be obtained after several steps. Our experiments show that our proposed Diffsound not only produces better text-to-sound generation results when compared with the AR decoder but also has a faster generation speed, e.g., MOS: 3.56 \textit{v.s} 2.786, and the generation speed is five times faster than the AR decoder.
LAE: Language-Aware Encoder for Monolingual and Multilingual ASR
Jun 05, 2022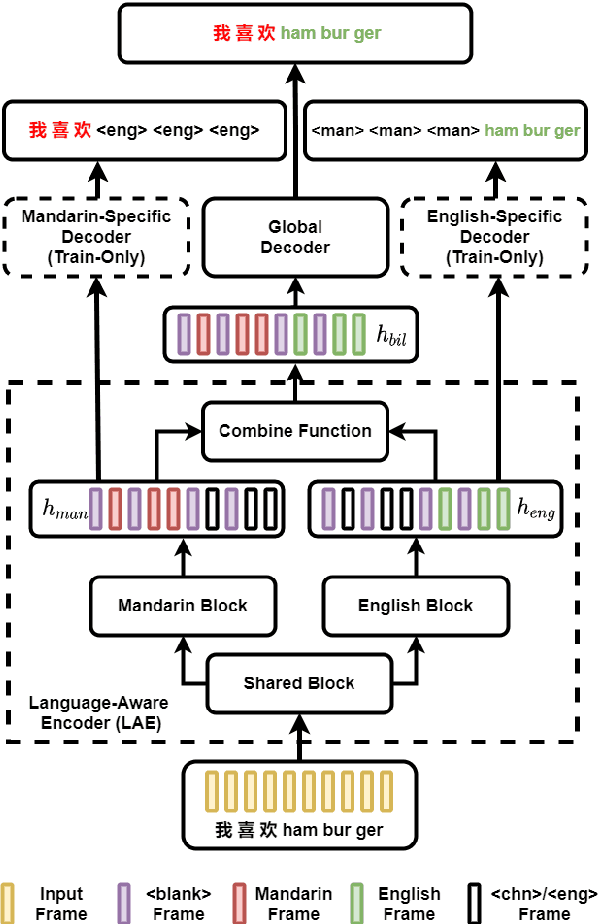
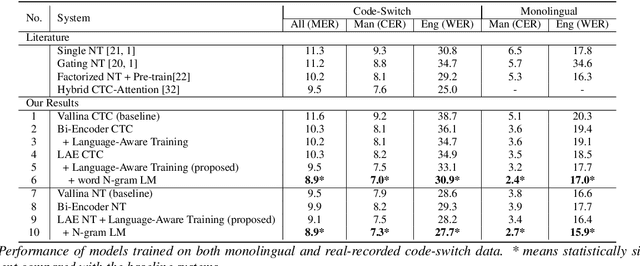
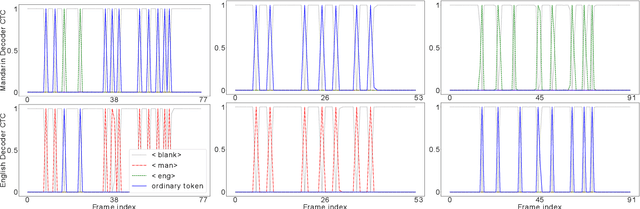
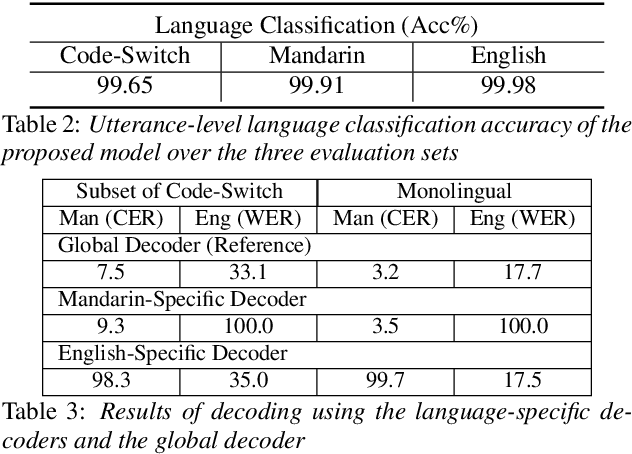
Despite the rapid progress in automatic speech recognition (ASR) research, recognizing multilingual speech using a unified ASR system remains highly challenging. Previous works on multilingual speech recognition mainly focus on two directions: recognizing multiple monolingual speech or recognizing code-switched speech that uses different languages interchangeably within a single utterance. However, a pragmatic multilingual recognizer is expected to be compatible with both directions. In this work, a novel language-aware encoder (LAE) architecture is proposed to handle both situations by disentangling language-specific information and generating frame-level language-aware representations during encoding. In the LAE, the primary encoding is implemented by the shared block while the language-specific blocks are used to extract specific representations for each language. To learn language-specific information discriminatively, a language-aware training method is proposed to optimize the language-specific blocks in LAE. Experiments conducted on Mandarin-English code-switched speech suggest that the proposed LAE is capable of discriminating different languages in frame-level and shows superior performance on both monolingual and multilingual ASR tasks. With either a real-recorded or simulated code-switched dataset, the proposed LAE achieves statistically significant improvements on both CTC and neural transducer systems. Code is released
Improving Dual-Microphone Speech Enhancement by Learning Cross-Channel Features with Multi-Head Attention
May 03, 2022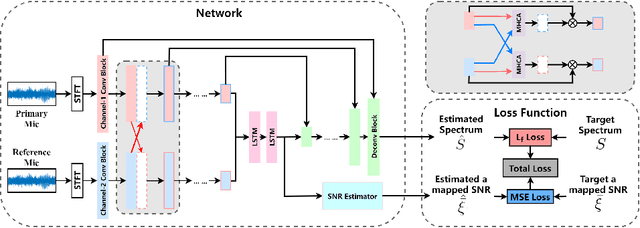
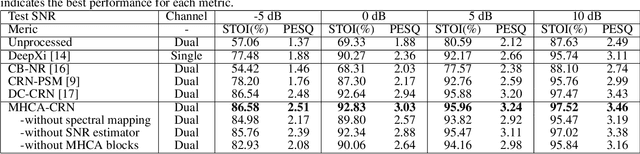
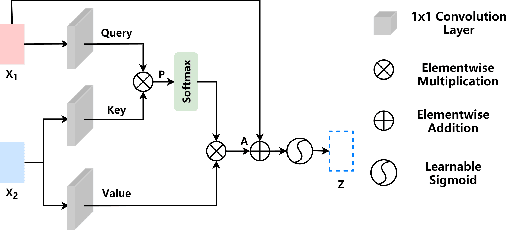
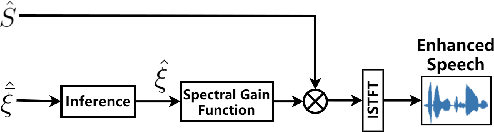
Hand-crafted spatial features, such as inter-channel intensity difference (IID) and inter-channel phase difference (IPD), play a fundamental role in recent deep learning based dual-microphone speech enhancement (DMSE) systems. However, learning the mutual relationship between artificially designed spatial and spectral features is hard in the end-to-end DMSE. In this work, a novel architecture for DMSE using a multi-head cross-attention based convolutional recurrent network (MHCA-CRN) is presented. The proposed MHCA-CRN model includes a channel-wise encoding structure for preserving intra-channel features and a multi-head cross-attention mechanism for fully exploiting cross-channel features. In addition, the proposed approach specifically formulates the decoder with an extra SNR estimator to estimate frame-level SNR under a multi-task learning framework, which is expected to avoid speech distortion led by end-to-end DMSE module. Finally, a spectral gain function is adopted to further suppress the unnatural residual noise. Experiment results demonstrated superior performance of the proposed model against several state-of-the-art models.
End-to-end Spoken Conversational Question Answering: Task, Dataset and Model
Apr 29, 2022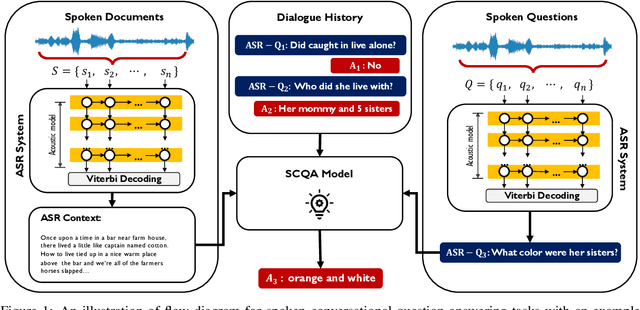

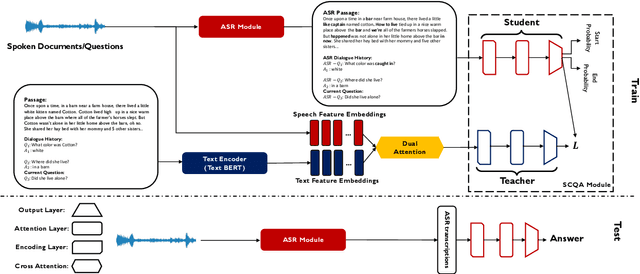

In spoken question answering, the systems are designed to answer questions from contiguous text spans within the related speech transcripts. However, the most natural way that human seek or test their knowledge is via human conversations. Therefore, we propose a new Spoken Conversational Question Answering task (SCQA), aiming at enabling the systems to model complex dialogue flows given the speech documents. In this task, our main objective is to build the system to deal with conversational questions based on the audio recordings, and to explore the plausibility of providing more cues from different modalities with systems in information gathering. To this end, instead of directly adopting automatically generated speech transcripts with highly noisy data, we propose a novel unified data distillation approach, DDNet, which effectively ingests cross-modal information to achieve fine-grained representations of the speech and language modalities. Moreover, we propose a simple and novel mechanism, termed Dual Attention, by encouraging better alignments between audio and text to ease the process of knowledge transfer. To evaluate the capacity of SCQA systems in a dialogue-style interaction, we assemble a Spoken Conversational Question Answering (Spoken-CoQA) dataset with more than 40k question-answer pairs from 4k conversations. The performance of the existing state-of-the-art methods significantly degrade on our dataset, hence demonstrating the necessity of cross-modal information integration. Our experimental results demonstrate that our proposed method achieves superior performance in spoken conversational question answering tasks.
Speaker-Aware Mixture of Mixtures Training for Weakly Supervised Speaker Extraction
Apr 15, 2022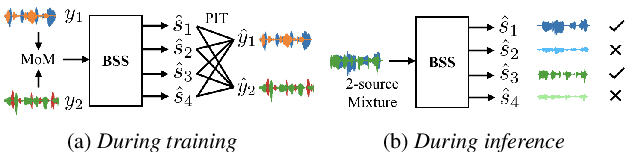

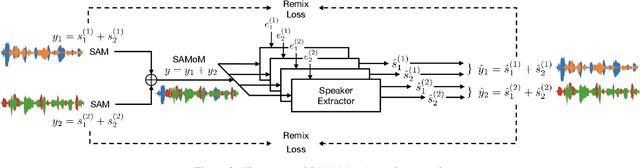
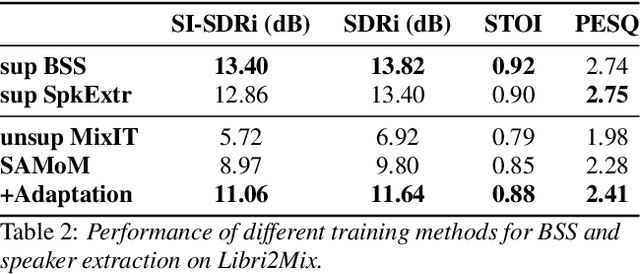
Dominant researches adopt supervised training for speaker extraction, while the scarcity of ideally clean corpus and channel mismatch problem are rarely considered. To this end, we propose speaker-aware mixture of mixtures training (SAMoM), utilizing the consistency of speaker identity among target source, enrollment utterance and target estimate to weakly supervise the training of a deep speaker extractor. In SAMoM, the input is constructed by mixing up different speaker-aware mixtures (SAMs), each contains multiple speakers with their identities known and enrollment utterances available. Informed by enrollment utterances, target speech is extracted from the input one by one, such that the estimated targets can approximate the original SAMs after a remix in accordance with the identity consistency. Moreover, using SAMoM in a semi-supervised setting with a certain amount of clean sources enables application in noisy scenarios. Extensive experiments on Libri2Mix show that the proposed method achieves promising results without access to any clean sources (11.06dB SI-SDRi). With a domain adaptation, our approach even outperformed supervised framework in a cross-domain evaluation on AISHELL-1.
RaDur: A Reference-aware and Duration-robust Network for Target Sound Detection
Apr 05, 2022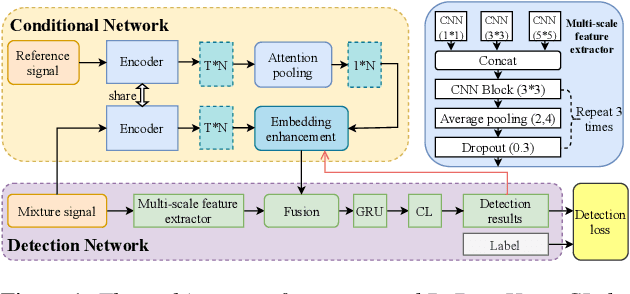
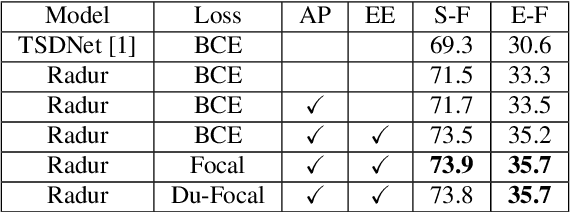
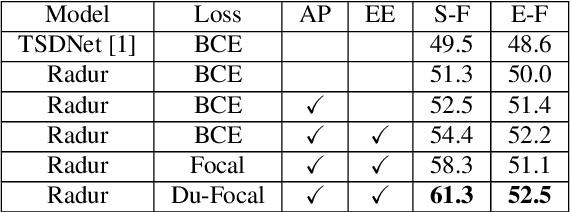
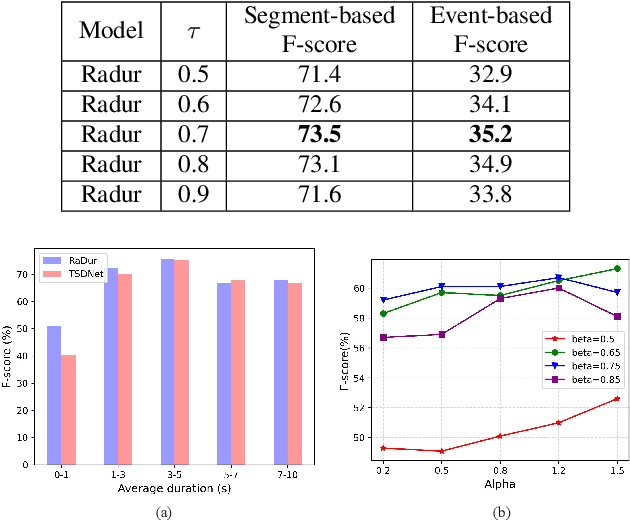
Target sound detection (TSD) aims to detect the target sound from a mixture audio given the reference information. Previous methods use a conditional network to extract a sound-discriminative embedding from the reference audio, and then use it to detect the target sound from the mixture audio. However, the network performs much differently when using different reference audios (e.g. performs poorly for noisy and short-duration reference audios), and tends to make wrong decisions for transient events (i.e. shorter than $1$ second). To overcome these problems, in this paper, we present a reference-aware and duration-robust network (RaDur) for TSD. More specifically, in order to make the network more aware of the reference information, we propose an embedding enhancement module to take into account the mixture audio while generating the embedding, and apply the attention pooling to enhance the features of target sound-related frames and weaken the features of noisy frames. In addition, a duration-robust focal loss is proposed to help model different-duration events. To evaluate our method, we build two TSD datasets based on UrbanSound and Audioset. Extensive experiments show the effectiveness of our methods.