 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Generalizable Dexterous Manipulation from Human Grasp Affordance
Apr 05, 2022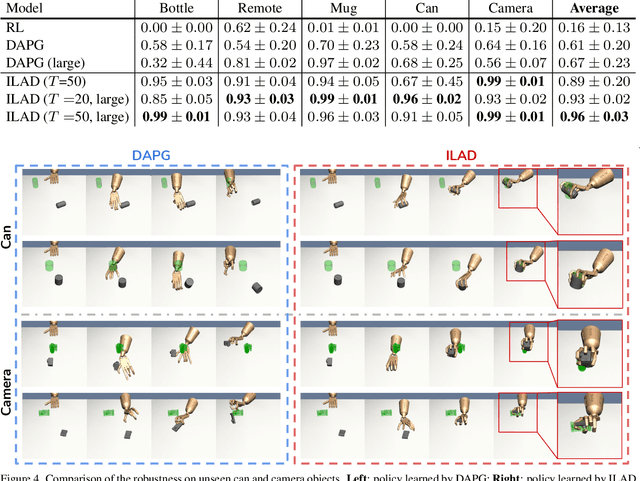
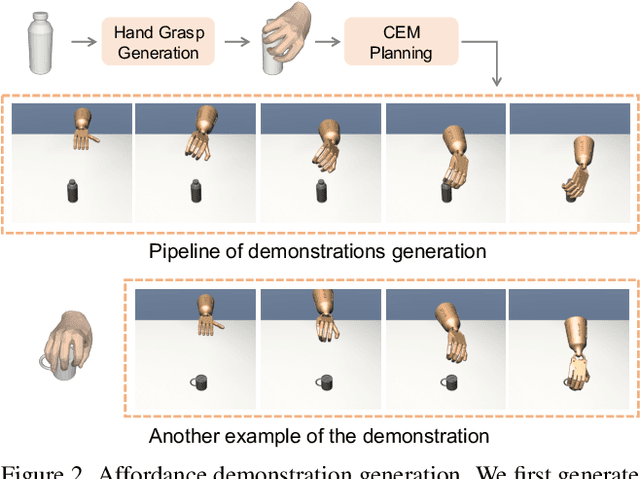

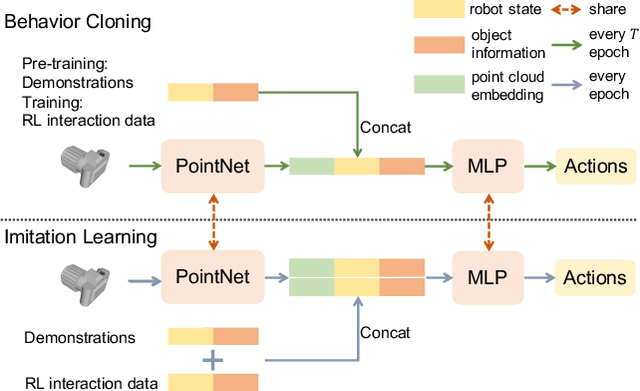
Dexterous manipulation with a multi-finger hand is one of the most challenging problems in robotics. While recent progress in imitation learning has largely improved the sample efficiency compared to Reinforcement Learning, the learned policy can hardly generalize to manipulate novel objects, given limited expert demonstrations. In this paper, we propose to learn dexterous manipulation using large-scale demonstrations with diverse 3D objects in a category, which are generated from a human grasp affordance model. This generalizes the policy to novel object instances within the same category. To train the policy, we propose a novel imitation learning objective jointly with a geometric representation learning objective using our demonstrations. By experimenting with relocating diverse objects in simulation, we show that our approach outperforms baselines with a large margin when manipulating novel objects. We also ablate the importance on 3D object representation learning for manipulation. We include videos, code, and additional information on the project website - https://kristery.github.io/ILAD/ .
DexMV: Imitation Learning for Dexterous Manipulation from Human Videos
Aug 27, 2021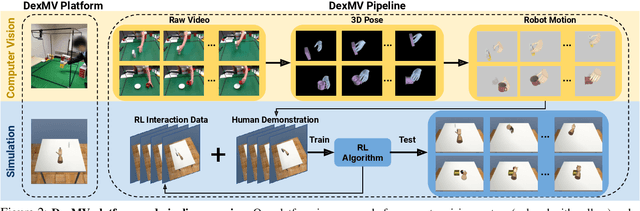
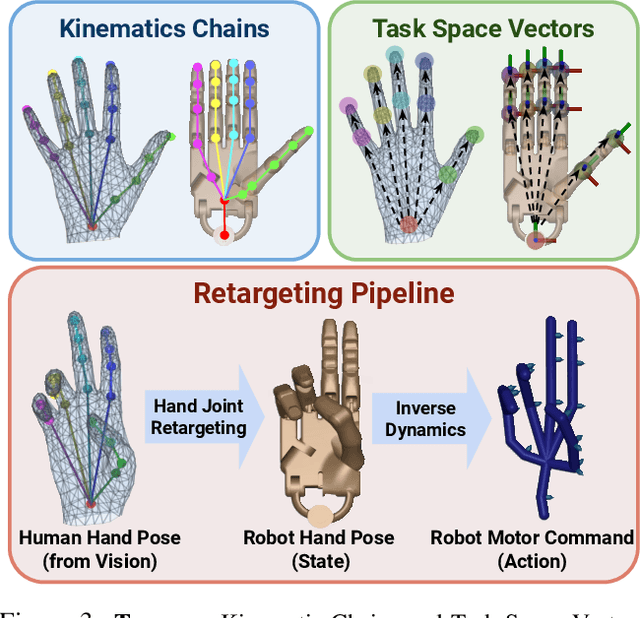
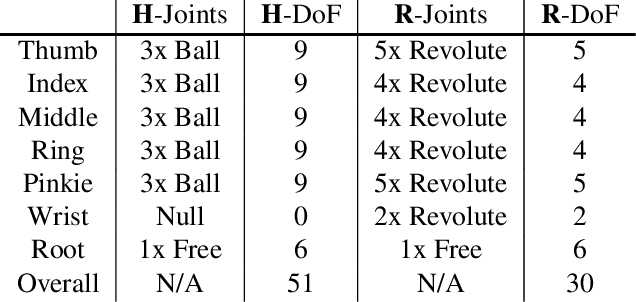

While we have made significant progress on understanding hand-object interactions in computer vision, it is still very challenging for robots to perform complex dexterous manipulation. In this paper, we propose a new platform and pipeline, DexMV (Dexterous Manipulation from Videos), for imitation learning to bridge the gap between computer vision and robot learning. We design a platform with: (i) a simulation system for complex dexterous manipulation tasks with a multi-finger robot hand and (ii) a computer vision system to record large-scale demonstrations of a human hand conducting the same tasks. In our new pipeline, we extract 3D hand and object poses from the videos, and convert them to robot demonstrations via motion retargeting. We then apply and compare multiple imitation learning algorithms with the demonstrations. We show that the demonstrations can indeed improve robot learning by a large margin and solve the complex tasks which reinforcement learning alone cannot solve. Project page with video: https://yzqin.github.io/dexmv
Batch-Augmented Multi-Agent Reinforcement Learning for Efficient Traffic Signal Optimization
May 19, 2020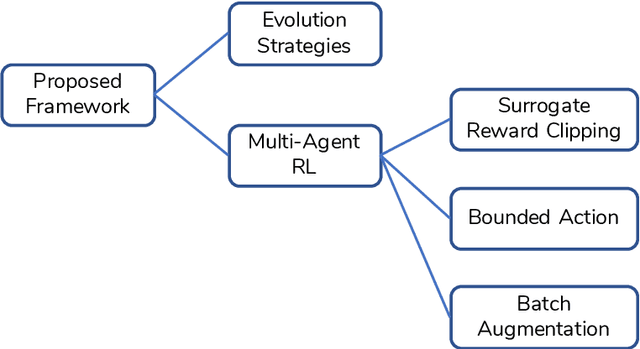
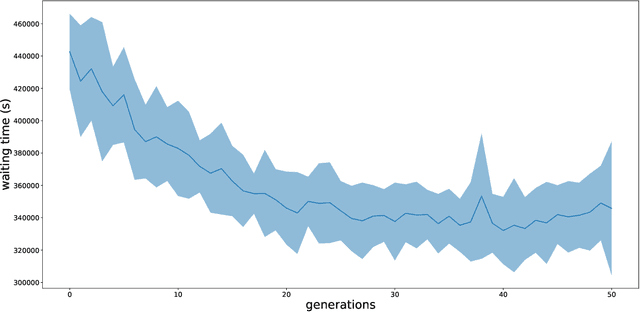
The goal of this work is to provide a viable solution based on reinforcement learning for traffic signal control problems. Although the state-of-the-art reinforcement learning approaches have yielded great success in a variety of domains, directly applying it to alleviate traffic congestion can be challenging, considering the requirement of high sample efficiency and how training data is gathered. In this work, we address several challenges that we encountered when we attempted to mitigate serious traffic congestion occurring in a metropolitan area. Specifically, we are required to provide a solution that is able to (1) handle the traffic signal control when certain surveillance cameras that retrieve information for reinforcement learning are down, (2) learn from batch data without a traffic simulator, and (3) make control decisions without shared information across intersections. We present a two-stage framework to deal with the above-mentioned situations. The framework can be decomposed into an Evolution Strategies approach that gives a fixed-time traffic signal control schedule and a multi-agent off-policy reinforcement learning that is capable of learning from batch data with the aid of three proposed components, bounded action, batch augmentation, and surrogate reward clipping. Our experiments show that the proposed framework reduces traffic congestion by 36% in terms of waiting time compared with the currently used fixed-time traffic signal plan. Furthermore, the framework requires only 600 queries to a simulator to achieve the result.
CSPNet: A New Backbone that can Enhance Learning Capability of CNN
Nov 27, 2019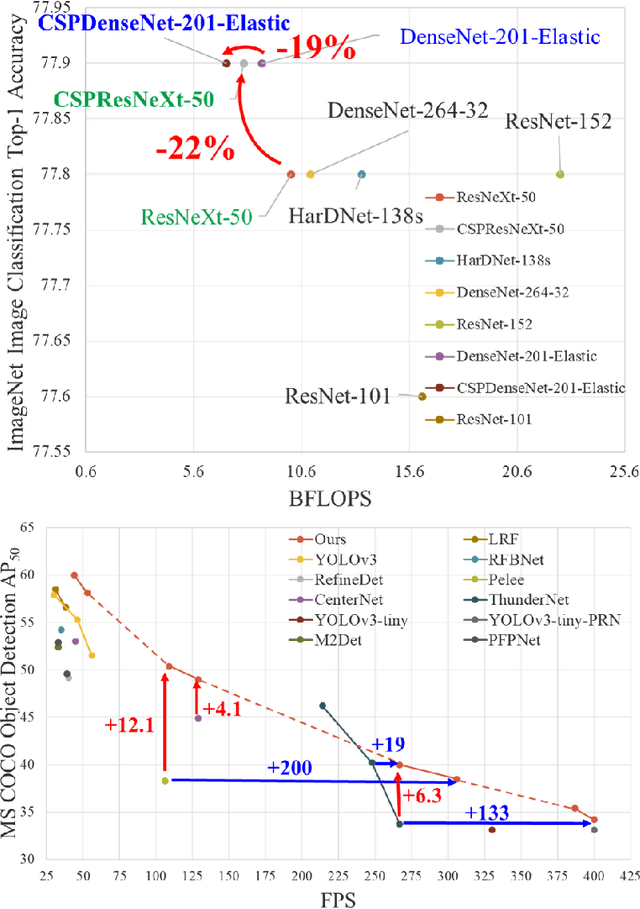
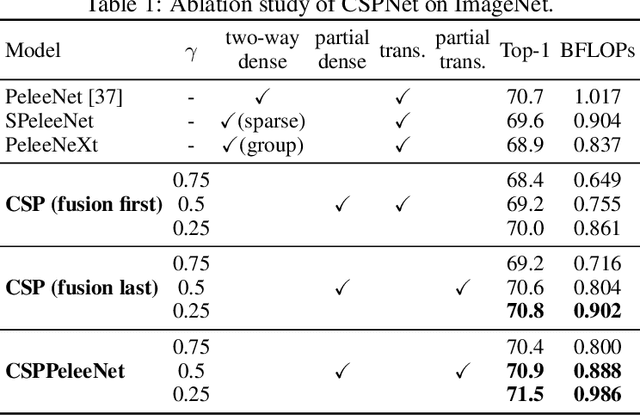

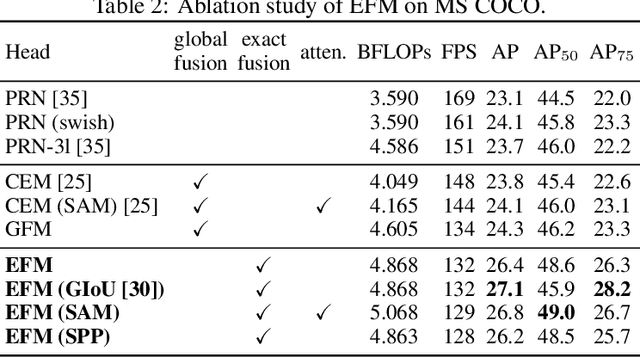
Neural networks have enabled state-of-the-art approaches to achieve incredible results on computer vision tasks such as object detection. However, such success greatly relies on costly computation resources, which hinders people with cheap devices from appreciating the advanced technology. In this paper, we propose Cross Stage Partial Network (CSPNet) to mitigate the problem that previous works require heavy inference computations from the network architecture perspective. We attribute the problem to the duplicate gradient information within network optimization. The proposed networks respect the variability of the gradients by integrating feature maps from the beginning and the end of a network stage, which, in our experiments, reduces computations by 20% with equivalent or even superior accuracy on the ImageNet dataset, and significantly outperforms state-of-the-art approaches in terms of AP50 on the MS COCO object detection dataset. The CSPNet is easy to implement and general enough to cope with architectures based on ResNet, ResNeXt, and DenseNet. Source code is at https://github.com/WongKinYiu/CrossStagePartialNetworks.
Model Imitation for Model-Based Reinforcement Learning
Oct 02, 2019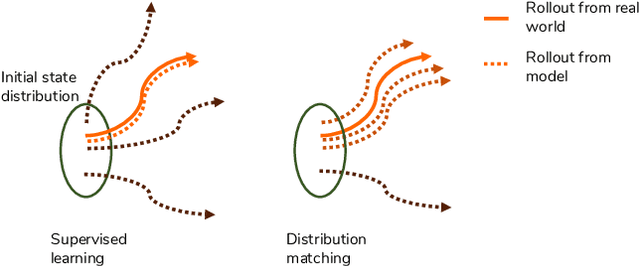

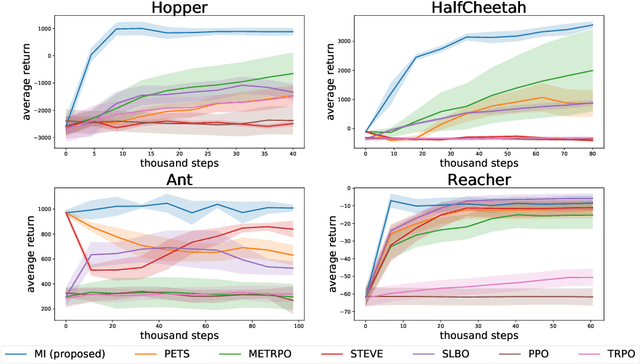
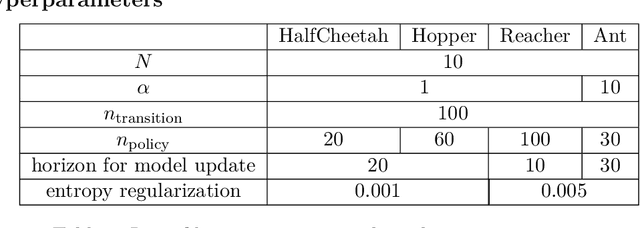
Model-based reinforcement learning (MBRL) aims to learn a dynamic model to reduce the number of interactions with real-world environments. However, due to estimation error, rollouts in the learned model, especially those of long horizon, fail to match the ones in real-world environments. This mismatching has seriously impacted the sample complexity of MBRL. The phenomenon can be attributed to the fact that previous works employ supervised learning to learn the one-step transition models, which has inherent difficulty ensuring the matching of distributions from multi-step rollouts. Based on the claim, we propose to learn the synthesized model by matching the distributions of multi-step rollouts sampled from the synthesized model and the real ones via WGAN. We theoretically show that matching the two can minimize the difference of cumulative rewards between the real transition and the learned one. Our experiments also show that the proposed model imitation method outperforms the state-of-the-art in terms of sample complexity and average return.
Imitation Learning from Imperfect Demonstration
Jan 30, 2019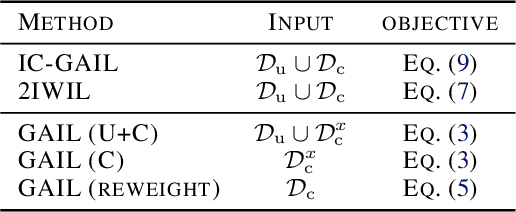
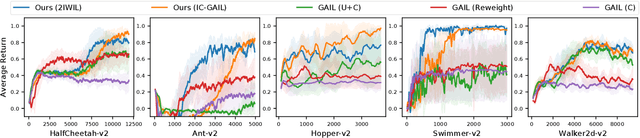
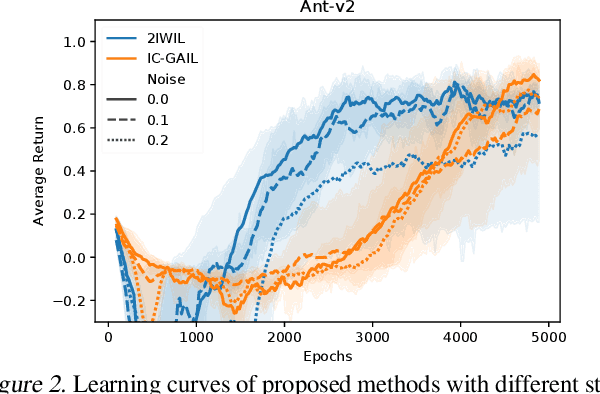
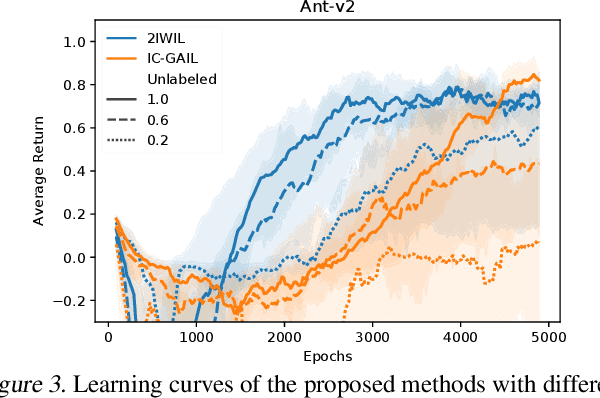
Imitation learning (IL) aims to learn an optimal policy from demonstrations. However, such demonstrations are often imperfect since collecting optimal ones is costly. To effectively learn from imperfect demonstrations, we propose a novel approach that utilizes confidence scores, which describe the quality of demonstrations. More specifically, we propose two confidence-based IL methods, namely two-step importance weighting IL (2IWIL) and generative adversarial IL with imperfect demonstration and confidence (IC-GAIL). We show that confidence scores given only to a small portion of sub-optimal demonstrations significantly improve the performance of IL both theoretically and empirically.
A Regulation Enforcement Solution for Multi-agent Reinforcement Learning
Jan 29, 2019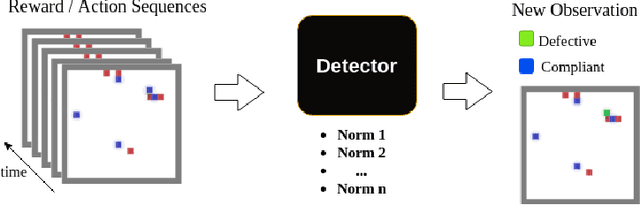
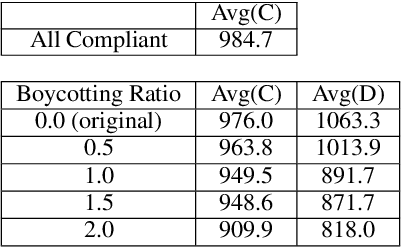
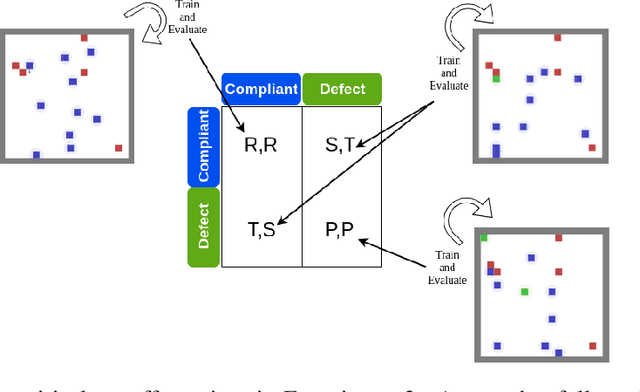
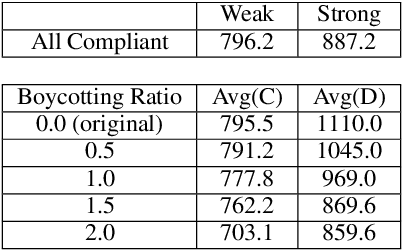
Human behaviors are regularized by a variety of norms or regulations, either to maintain orders or to enhance social welfare. If artificial intelligent (AI) agents make decisions on behalf of human beings, we would hope they can also follow established regulations while interacting with humans or other AI agents. However, it is possible that an AI agent can opt to disobey the regulations for self-interests. This paper attempts to design a mechanism that discourages the agents from not obeying the global regulation setup for every agent. We first introduce the problem Regulation Enforcement and formulate it using reinforcement learning and game theory under the scenario where agents make decisions in complete isolation of other agents. The key idea is that, although we could not alter how defective agents choose to behave, we can, however, leverage the aggregated power of compliant agents to boycott the defective ones. Based on the idea, we proposed a solution to the problem and conducted simulated experiments on two scenarios: Replenishing Resource Management Dilemma and Diminishing Reward Shaping Enforcement, using deep multi-agent reinforcement learning algorithms. We further use empirical game-theoretic analysis to show that how the method alters the resulting empirical payoff matrices in a way that promotes compliance (making mutual compliant a Nash Equilibrium).
ANS: Adaptive Network Scaling for Deep Rectifier Reinforcement Learning Models
Oct 31, 2018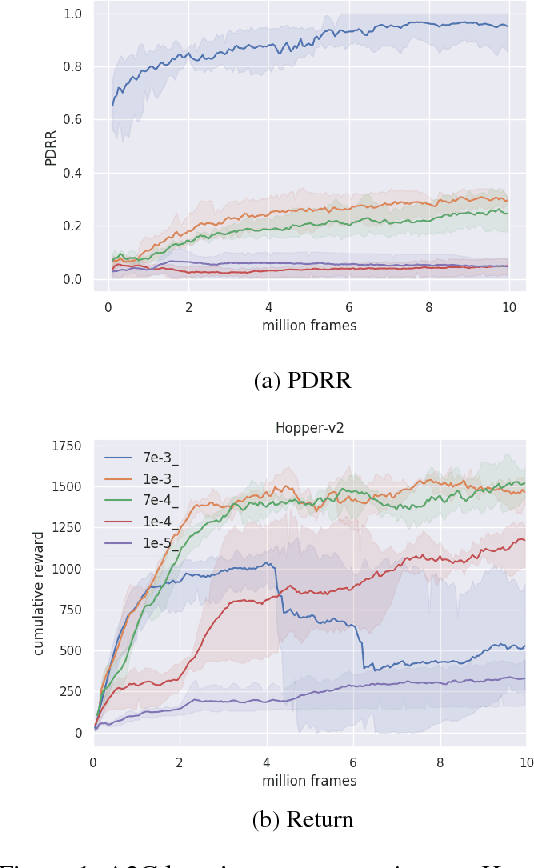
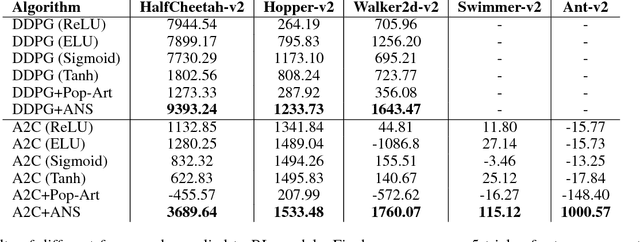
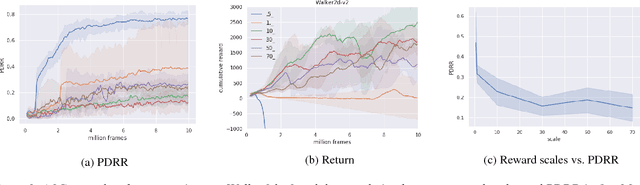
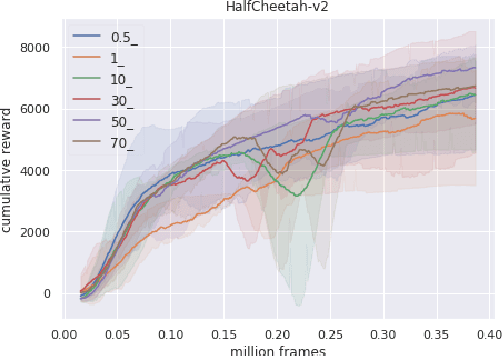
This work provides a thorough study on how reward scaling can affect performance of deep reinforcement learning agents. In particular, we would like to answer the question that how does reward scaling affect non-saturating ReLU networks in RL? This question matters because ReLU is one of the most effective activation functions for deep learning models. We also propose an Adaptive Network Scaling framework to find a suitable scale of the rewards during learning for better performance. We conducted empirical studies to justify the solution.
A Low-Cost Ethics Shaping Approach for Designing Reinforcement Learning Agents
Sep 10, 2018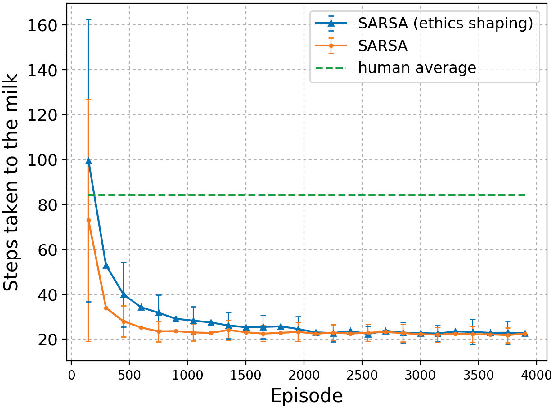
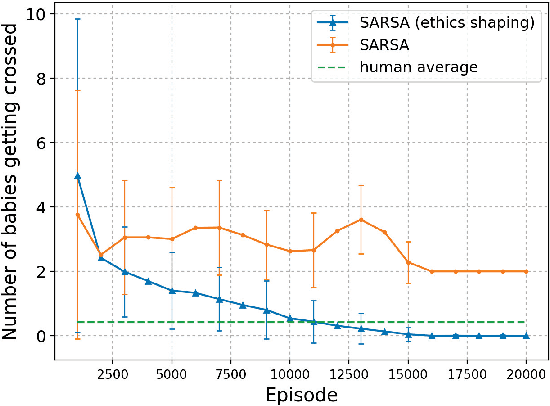
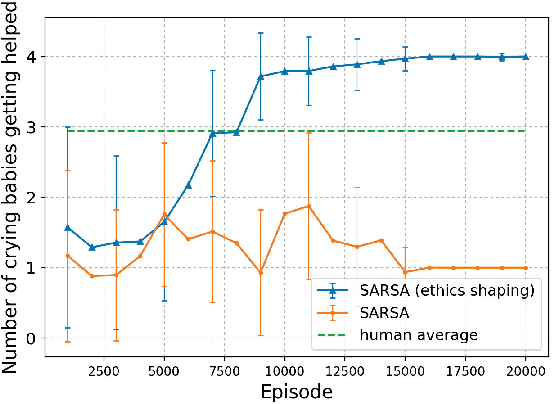
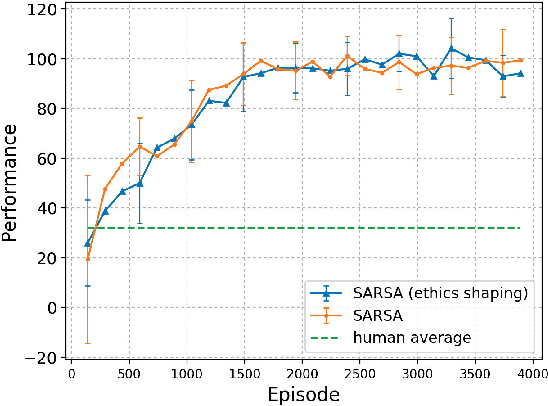
This paper proposes a low-cost, easily realizable strategy to equip a reinforcement learning (RL) agent the capability of behaving ethically. Our model allows the designers of RL agents to solely focus on the task to achieve, without having to worry about the implementation of multiple trivial ethical patterns to follow. Based on the assumption that the majority of human behavior, regardless which goals they are achieving, is ethical, our design integrates human policy with the RL policy to achieve the target objective with less chance of violating the ethical code that human beings normally obey.
A Memory-Network Based Solution for Multivariate Time-Series Forecasting
Sep 06, 2018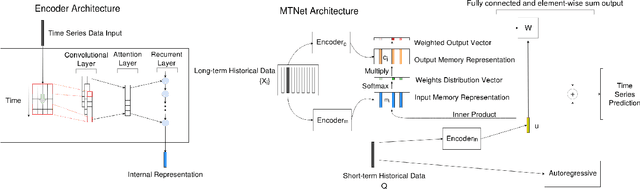
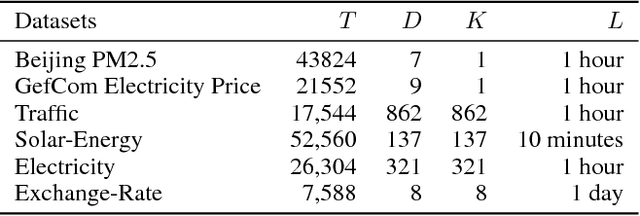
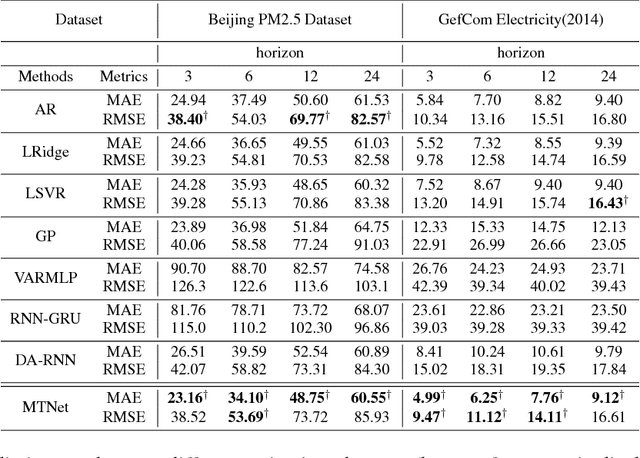
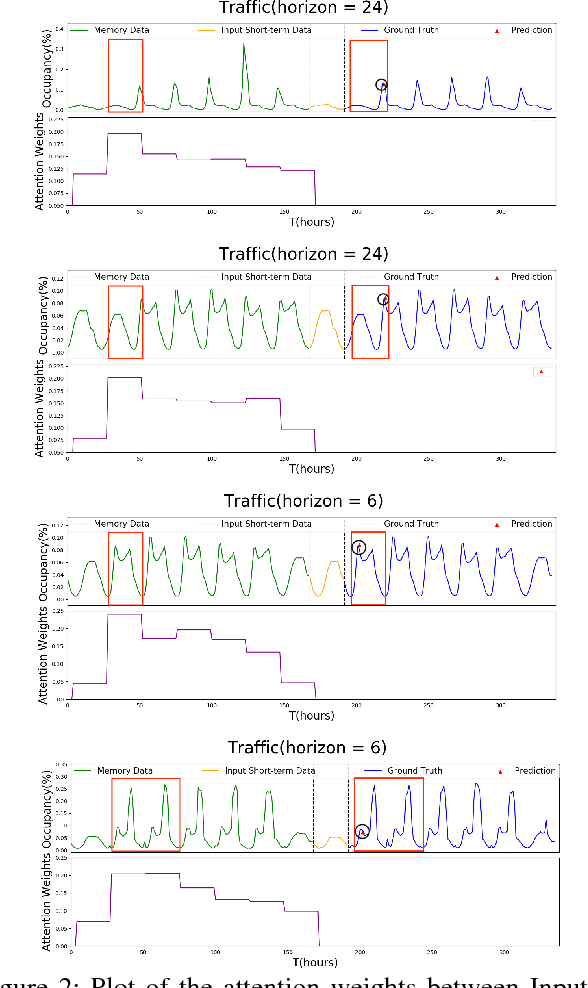
Multivariate time series forecasting is extensively studied throughout the years with ubiquitous applications in areas such as finance, traffic, environment, etc. Still, concerns have been raised on traditional methods for incapable of modeling complex patterns or dependencies lying in real word data. To address such concerns, various deep learning models, mainly Recurrent Neural Network (RNN) based methods, are proposed. Nevertheless, capturing extremely long-term patterns while effectively incorporating information from other variables remains a challenge for time-series forecasting. Furthermore, lack-of-explainability remains one serious drawback for deep neural network models. Inspired by Memory Network proposed for solving the question-answering task, we propose a deep learning based model named Memory Time-series network (MTNet) for time series forecasting. MTNet consists of a large memory component, three separate encoders, and an autoregressive component to train jointly. Additionally, the attention mechanism designed enable MTNet to be highly interpretable. We can easily tell which part of the historic data is referenced the most.