 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYuefeng Chen
Spatial-Phase Shallow Learning: Rethinking Face Forgery Detection in Frequency Domain
Mar 05, 2021
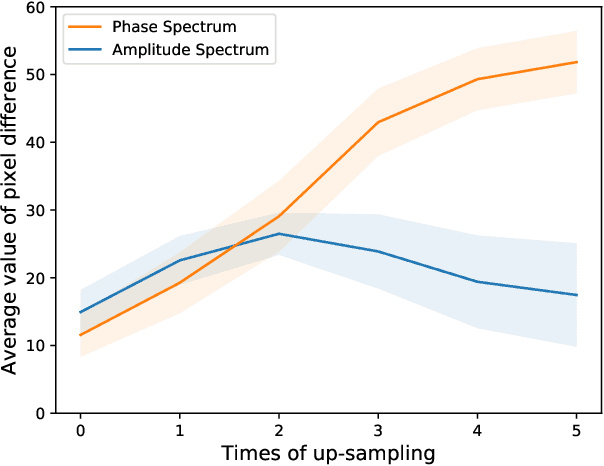
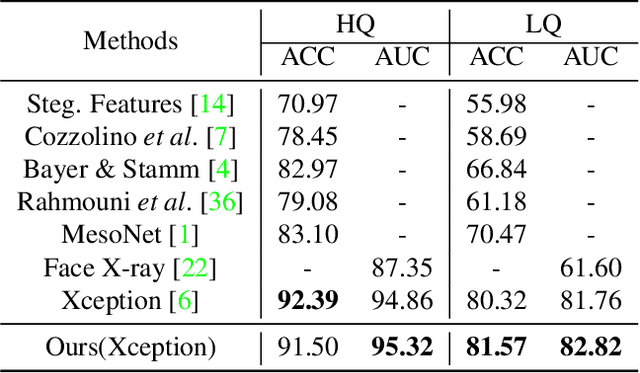
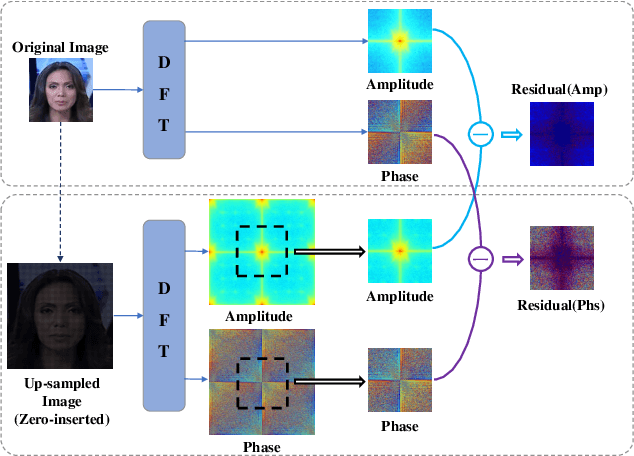
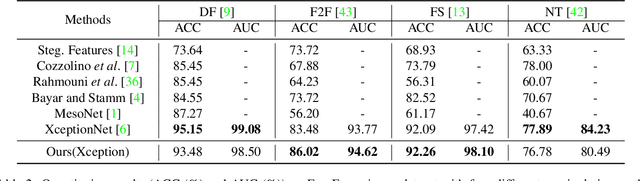
The remarkable success in face forgery techniques has received considerable attention in computer vision due to security concerns. We observe that up-sampling is a necessary step of most face forgery techniques, and cumulative up-sampling will result in obvious changes in the frequency domain, especially in the phase spectrum. According to the property of natural images, the phase spectrum preserves abundant frequency components that provide extra information and complement the loss of the amplitude spectrum. To this end, we present a novel Spatial-Phase Shallow Learning (SPSL) method, which combines spatial image and phase spectrum to capture the up-sampling artifacts of face forgery to improve the transferability, for face forgery detection. And we also theoretically analyze the validity of utilizing the phase spectrum. Moreover, we notice that local texture information is more crucial than high-level semantic information for the face forgery detection task. So we reduce the receptive fields by shallowing the network to suppress high-level features and focus on the local region. Extensive experiments show that SPSL can achieve the state-of-the-art performance on cross-datasets evaluation as well as multi-class classification and obtain comparable results on single dataset evaluation.
QAIR: Practical Query-efficient Black-Box Attacks for Image Retrieval
Mar 04, 2021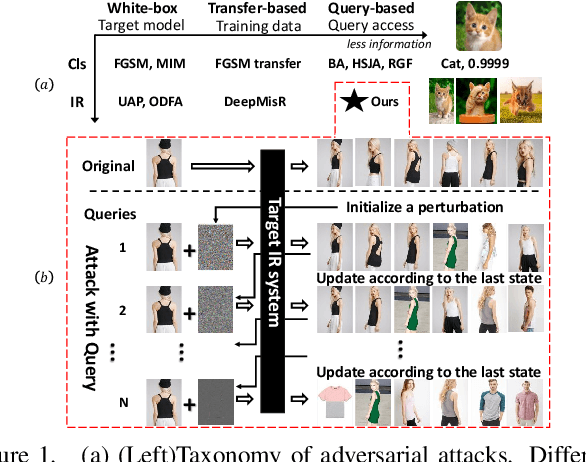
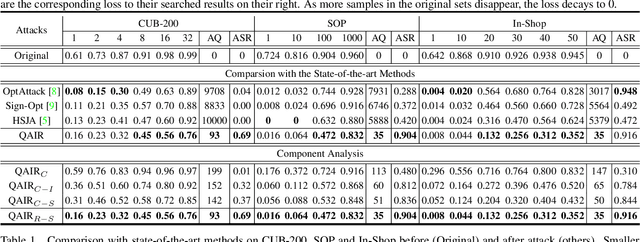
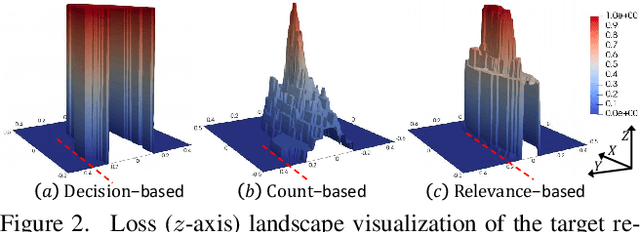
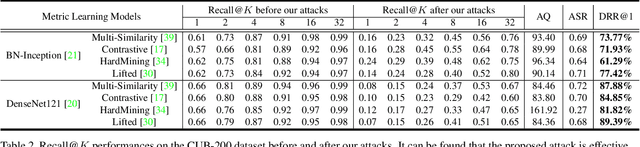
We study the query-based attack against image retrieval to evaluate its robustness against adversarial examples under the black-box setting, where the adversary only has query access to the top-k ranked unlabeled images from the database. Compared with query attacks in image classification, which produce adversaries according to the returned labels or confidence score, the challenge becomes even more prominent due to the difficulty in quantifying the attack effectiveness on the partial retrieved list. In this paper, we make the first attempt in Query-based Attack against Image Retrieval (QAIR), to completely subvert the top-k retrieval results. Specifically, a new relevance-based loss is designed to quantify the attack effects by measuring the set similarity on the top-k retrieval results before and after attacks and guide the gradient optimization. To further boost the attack efficiency, a recursive model stealing method is proposed to acquire transferable priors on the target model and generate the prior-guided gradients. Comprehensive experiments show that the proposed attack achieves a high attack success rate with few queries against the image retrieval systems under the black-box setting. The attack evaluations on the real-world visual search engine show that it successfully deceives a commercial system such as Bing Visual Search with 98% attack success rate by only 33 queries on average.
Adversarial Examples Detection beyond Image Space
Feb 23, 2021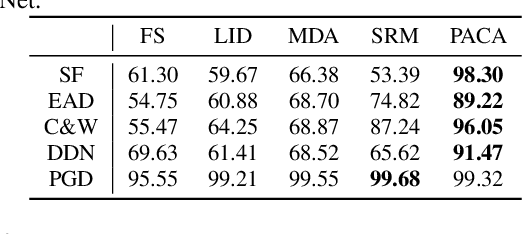

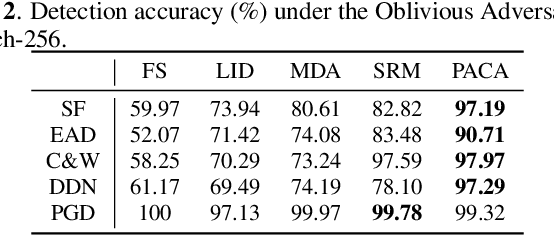
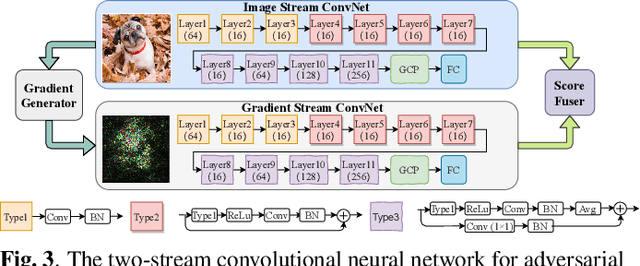
Deep neural networks have been proved that they are vulnerable to adversarial examples, which are generated by adding human-imperceptible perturbations to images. To defend these adversarial examples, various detection based methods have been proposed. However, most of them perform poorly on detecting adversarial examples with extremely slight perturbations. By exploring these adversarial examples, we find that there exists compliance between perturbations and prediction confidence, which guides us to detect few-perturbation attacks from the aspect of prediction confidence. To detect both few-perturbation attacks and large-perturbation attacks, we propose a method beyond image space by a two-stream architecture, in which the image stream focuses on the pixel artifacts and the gradient stream copes with the confidence artifacts. The experimental results show that the proposed method outperforms the existing methods under oblivious attacks and is verified effective to defend omniscient attacks as well.
Composite Adversarial Attacks
Dec 10, 2020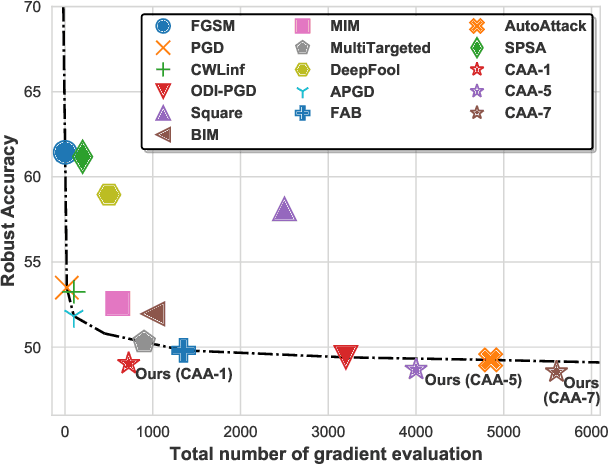

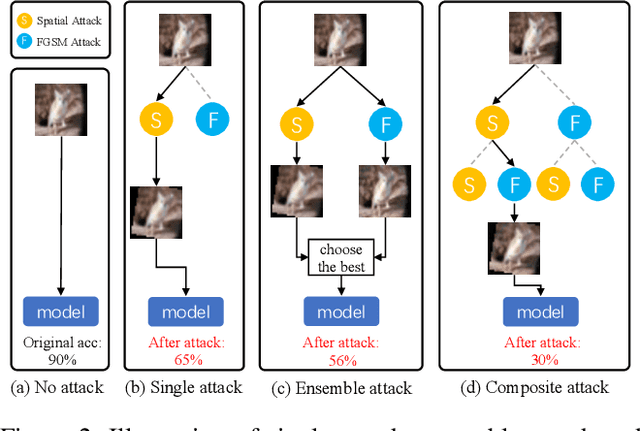
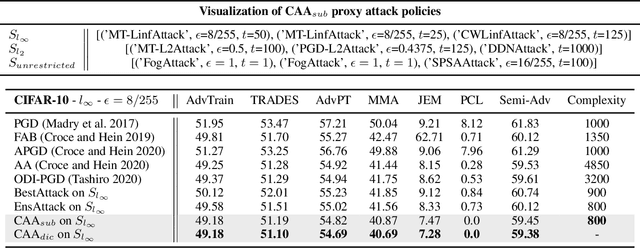
Adversarial attack is a technique for deceiving Machine Learning (ML) models, which provides a way to evaluate the adversarial robustness. In practice, attack algorithms are artificially selected and tuned by human experts to break a ML system. However, manual selection of attackers tends to be sub-optimal, leading to a mistakenly assessment of model security. In this paper, a new procedure called Composite Adversarial Attack (CAA) is proposed for automatically searching the best combination of attack algorithms and their hyper-parameters from a candidate pool of \textbf{32 base attackers}. We design a search space where attack policy is represented as an attacking sequence, i.e., the output of the previous attacker is used as the initialization input for successors. Multi-objective NSGA-II genetic algorithm is adopted for finding the strongest attack policy with minimum complexity. The experimental result shows CAA beats 10 top attackers on 11 diverse defenses with less elapsed time (\textbf{6 $\times$ faster than AutoAttack}), and achieves the new state-of-the-art on $l_{\infty}$, $l_{2}$ and unrestricted adversarial attacks.
Sharp Multiple Instance Learning for DeepFake Video Detection
Aug 11, 2020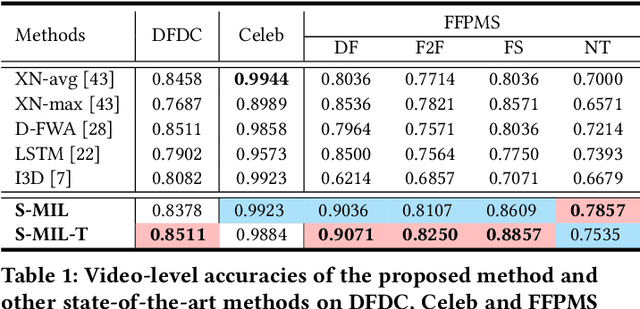
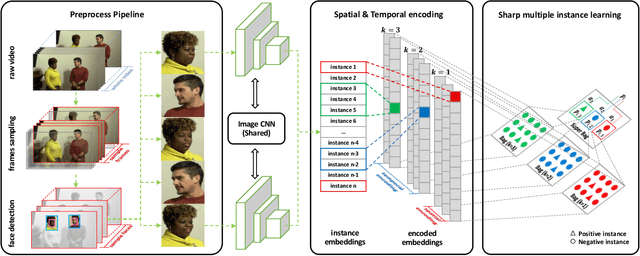
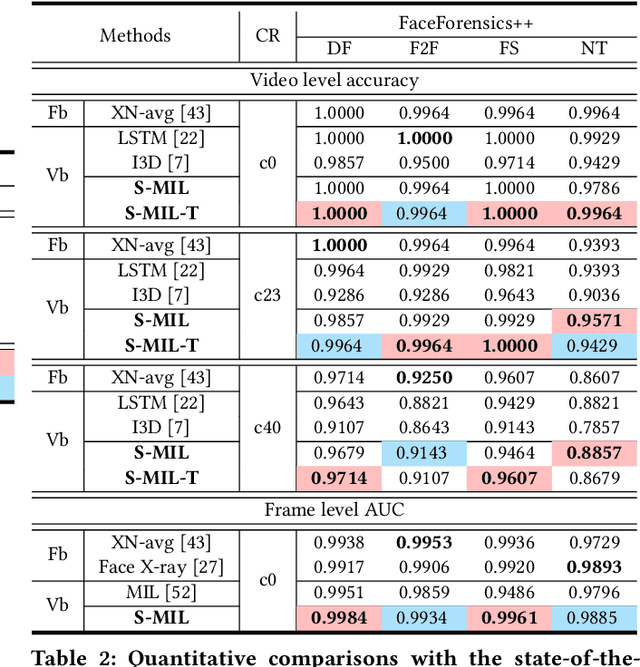

With the rapid development of facial manipulation techniques, face forgery has received considerable attention in multimedia and computer vision community due to security concerns. Existing methods are mostly designed for single-frame detection trained with precise image-level labels or for video-level prediction by only modeling the inter-frame inconsistency, leaving potential high risks for DeepFake attackers. In this paper, we introduce a new problem of partial face attack in DeepFake video, where only video-level labels are provided but not all the faces in the fake videos are manipulated. We address this problem by multiple instance learning framework, treating faces and input video as instances and bag respectively. A sharp MIL (S-MIL) is proposed which builds direct mapping from instance embeddings to bag prediction, rather than from instance embeddings to instance prediction and then to bag prediction in traditional MIL. Theoretical analysis proves that the gradient vanishing in traditional MIL is relieved in S-MIL. To generate instances that can accurately incorporate the partially manipulated faces, spatial-temporal encoded instance is designed to fully model the intra-frame and inter-frame inconsistency, which further helps to promote the detection performance. We also construct a new dataset FFPMS for partially attacked DeepFake video detection, which can benefit the evaluation of different methods at both frame and video levels. Experiments on FFPMS and the widely used DFDC dataset verify that S-MIL is superior to other counterparts for partially attacked DeepFake video detection. In addition, S-MIL can also be adapted to traditional DeepFake image detection tasks and achieve state-of-the-art performance on single-frame datasets.
* Accepted at ACM MM 2020. 11 pages, 8 figures, with appendix
GAP++: Learning to generate target-conditioned adversarial examples
Jun 09, 2020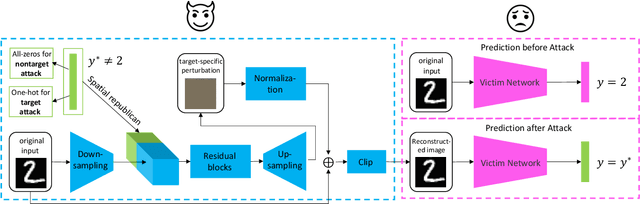
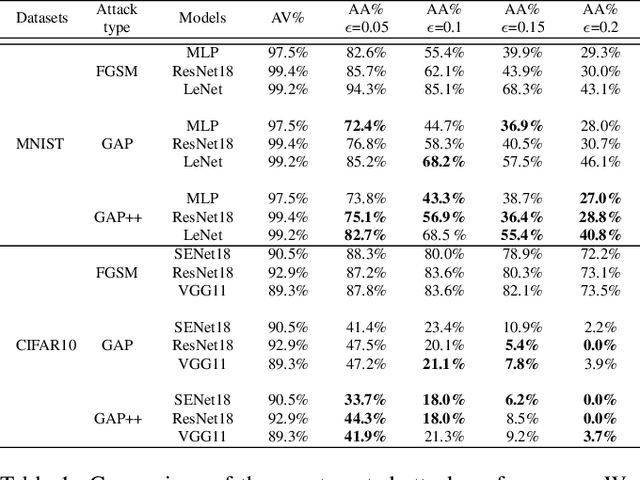
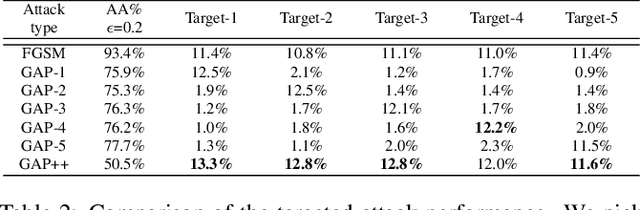
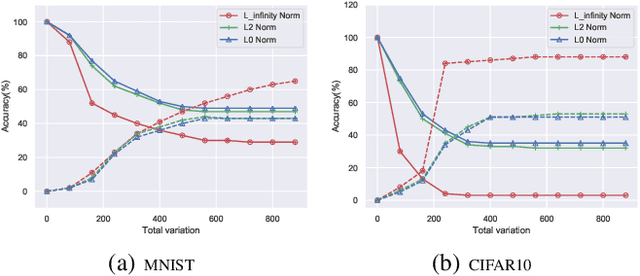
Adversarial examples are perturbed inputs which can cause a serious threat for machine learning models. Finding these perturbations is such a hard task that we can only use the iterative methods to traverse. For computational efficiency, recent works use adversarial generative networks to model the distribution of both the universal or image-dependent perturbations directly. However, these methods generate perturbations only rely on input images. In this work, we propose a more general-purpose framework which infers target-conditioned perturbations dependent on both input image and target label. Different from previous single-target attack models, our model can conduct target-conditioned attacks by learning the relations of attack target and the semantics in image. Using extensive experiments on the datasets of MNIST and CIFAR10, we show that our method achieves superior performance with single target attack models and obtains high fooling rates with small perturbation norms.
AdvKnn: Adversarial Attacks On K-Nearest Neighbor Classifiers With Approximate Gradients
Nov 29, 2019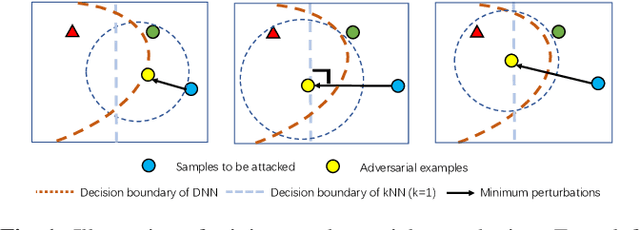
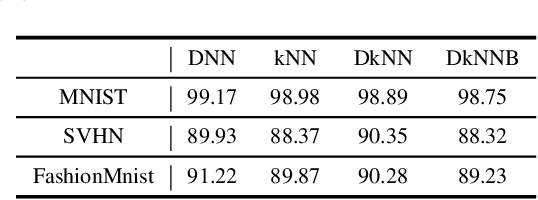
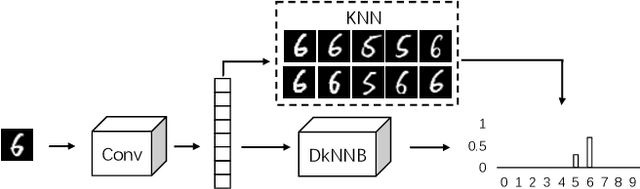
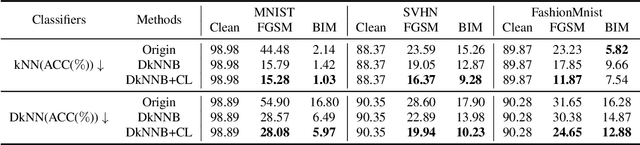
Deep neural networks have been shown to be vulnerable to adversarial examples---maliciously crafted examples that can trigger the target model to misbehave by adding imperceptible perturbations. Existing attack methods for k-nearest neighbor~(kNN) based algorithms either require large perturbations or are not applicable for large k. To handle this problem, this paper proposes a new method called AdvKNN for evaluating the adversarial robustness of kNN-based models. Firstly, we propose a deep kNN block to approximate the output of kNN methods, which is differentiable thus can provide gradients for attacks to cross the decision boundary with small distortions. Second, a new consistency learning for distribution instead of classification is proposed for the effectiveness in distribution based methods. Extensive experimental results indicate that the proposed method significantly outperforms state of the art in terms of attack success rate and the added perturbations.
Learning To Characterize Adversarial Subspaces
Nov 15, 2019
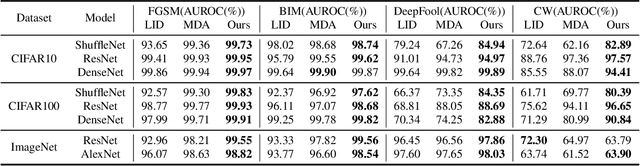
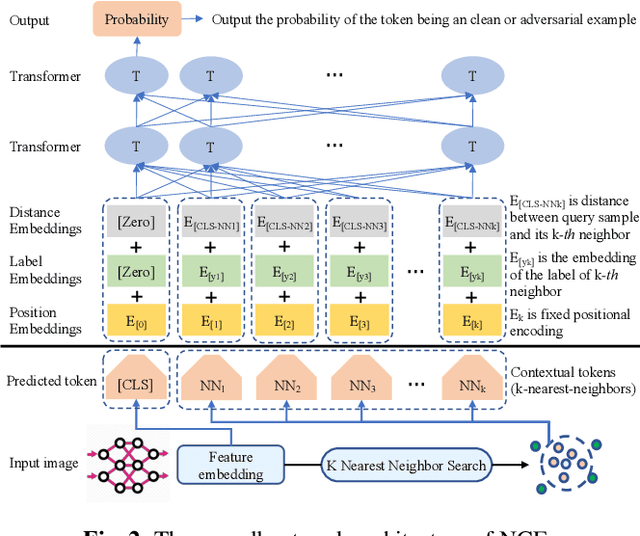

Deep Neural Networks (DNNs) are known to be vulnerable to the maliciously generated adversarial examples. To detect these adversarial examples, previous methods use artificially designed metrics to characterize the properties of \textit{adversarial subspaces} where adversarial examples lie. However, we find these methods are not working in practical attack detection scenarios. Because the artificially defined features are lack of robustness and show limitation in discriminative power to detect strong attacks. To solve this problem, we propose a novel adversarial detection method which identifies adversaries by adaptively learning reasonable metrics to characterize adversarial subspaces. As auxiliary context information, \textit{k} nearest neighbors are used to represent the surrounded subspace of the detected sample. We propose an innovative model called Neighbor Context Encoder (NCE) to learn from \textit{k} neighbors context and infer if the detected sample is normal or adversarial. We conduct thorough experiment on CIFAR-10, CIFAR-100 and ImageNet dataset. The results demonstrate that our approach surpasses all existing methods under three settings: \textit{attack-aware black-box detection}, \textit{attack-unaware black-box detection} and \textit{white-box detection}.