 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEccentricity Confound in EEG-based Visual Attention Decoding from Gaze-Fixated Neural Tracking of Motion in Natural Videos
Apr 16, 2026Objective. Decoding visual attention from brain signals during naturalistic video viewing has emerged as a new direction in brain-computer interface research. Current methods assume that stronger coupling between object motion and neural activity indicates higher attention, but this can be confounded by eye movement artifacts and stimulus properties. This study investigates how visual eccentricity (the distance between a visual object and the fixation point) affects neural responses when eye movement artifacts are controlled. Approach. EEG signals were recorded across three tasks that manipulated object eccentricity and attention conditions while participants maintained gaze fixation. Correlation analysis and match-mismatch decoding were performed to quantify the neural tracking of object motion. Main results. The analysis supports three conclusions: (1) neural tracking of object motion in natural videos works under gaze fixation; (2) the strength of neural tracking under gaze fixation is predictive of attention; and (3) there exists a significant eccentricity confound in the EEG responses, with poorer neural tracking of motion at larger eccentricities. Significance. These results provide critical evidence that findings from previous free-viewing studies reflect genuine neural processing rather than mere oculomotor artifacts. However, the identified eccentricity effect highlights a major limitation for current decoding approaches that assume coupling strength reflects attention levels alone.
Sample-level EEG-based Selective Auditory Attention Decoding with Markov Switching Models
Feb 13, 2026Selective auditory attention decoding aims to identify the speaker of interest from listeners' neural signals, such as electroencephalography (EEG), in the presence of multiple concurrent speakers. Most existing methods operate at the window level, facing a trade-off between temporal resolution and decoding accuracy. Recent work has shown that hidden Markov model (HMM)-based post-processing can smooth window-level decoder outputs to improve this trade-off. Instead of using a separate smoothing step, we propose to integrate the decoding and smoothing components into a single probabilistic framework using a Markov switching model (MSM). It directly models the relationship between the EEG and speech envelopes under each attention state while incorporating the temporal dynamics of attention. This formulation enables sample-level attention decoding, with model parameters and attention states jointly estimated via the expectation-maximization algorithm. Experimental results demonstrate that this integrated MSM formulation achieves comparable decoding accuracy to HMM post-processing while providing faster attention switch detection. The code for the proposed method is available at https://github.com/YYao-42/MSM.
Efficient Solutions for Mitigating Initialization Bias in Unsupervised Self-Adaptive Auditory Attention Decoding
Sep 18, 2025Decoding the attended speaker in a multi-speaker environment from electroencephalography (EEG) has attracted growing interest in recent years, with neuro-steered hearing devices as a driver application. Current approaches typically rely on ground-truth labels of the attended speaker during training, necessitating calibration sessions for each user and each EEG set-up to achieve optimal performance. While unsupervised self-adaptive auditory attention decoding (AAD) for stimulus reconstruction has been developed to eliminate the need for labeled data, it suffers from an initialization bias that can compromise performance. Although an unbiased variant has been proposed to address this limitation, it introduces substantial computational complexity that scales with data size. This paper presents three computationally efficient alternatives that achieve comparable performance, but with a significantly lower and constant computational cost. The code for the proposed algorithms is available at https://github.com/YYao-42/Unsupervised_AAD.
Unsupervised EEG-based decoding of absolute auditory attention with canonical correlation analysis
Apr 24, 2025



We propose a fully unsupervised algorithm that detects from encephalography (EEG) recordings when a subject actively listens to sound, versus when the sound is ignored. This problem is known as absolute auditory attention decoding (aAAD). We propose an unsupervised discriminative CCA model for feature extraction and combine it with an unsupervised classifier called minimally informed linear discriminant analysis (MILDA) for aAAD classification. Remarkably, the proposed unsupervised algorithm performs significantly better than a state-of-the-art supervised model. A key reason is that the unsupervised algorithm can successfully adapt to the non-stationary test data at a low computational cost. This opens the door to the analysis of the auditory attention of a subject using EEG signals with a model that automatically tunes itself to the subject without requiring an arduous supervised training session beforehand.
Performance Modeling for Correlation-based Neural Decoding of Auditory Attention to Speech
Mar 12, 2025

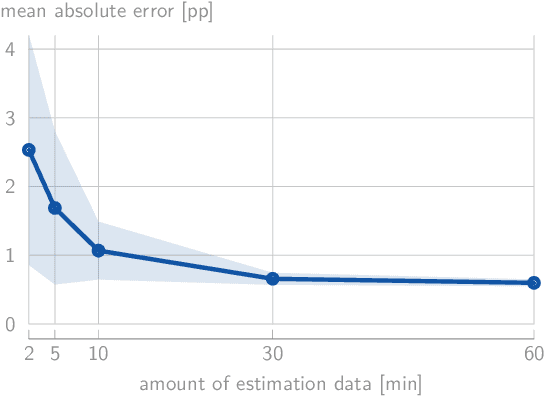

Correlation-based auditory attention decoding (AAD) algorithms exploit neural tracking mechanisms to determine listener attention among competing speech sources via, e.g., electroencephalography signals. The correlation coefficients between the decoded neural responses and encoded speech stimuli of the different speakers then serve as AAD decision variables. A critical trade-off exists between the temporal resolution (the decision window length used to compute these correlations) and the AAD accuracy. This trade-off is typically characterized by evaluating AAD accuracy across multiple window lengths, leading to the performance curve. We propose a novel method to model this trade-off curve using labeled correlations from only a single decision window length. Our approach models the (un)attended correlations with a normal distribution after applying the Fisher transformation, enabling accurate AAD accuracy prediction across different window lengths. We validate the method on two distinct AAD implementations: a linear decoder and the non-linear VLAAI deep neural network, evaluated on separate datasets. Results show consistently low modeling errors of approximately 2 percent points, with 94% of true accuracies falling within estimated 95%-confidence intervals. The proposed method enables efficient performance curve modeling without extensive multi-window length evaluation, facilitating practical applications in, e.g., performance tracking in neuro-steered hearing devices to continuously adapt the system parameters over time.
Linear stimulus reconstruction works on the KU Leuven audiovisual, gaze-controlled auditory attention decoding dataset
Dec 02, 2024



In a recent paper, we presented the KU Leuven audiovisual, gaze-controlled auditory attention decoding (AV-GC-AAD) dataset, in which we recorded electroencephalography (EEG) signals of participants attending to one out of two competing speakers under various audiovisual conditions. The main goal of this dataset was to disentangle the direction of gaze from the direction of auditory attention, in order to reveal gaze-related shortcuts in existing spatial AAD algorithms that aim to decode the (direction of) auditory attention directly from the EEG. Various methods based on spatial AAD do not achieve significant above-chance performances on our AV-GC-AAD dataset, indicating that previously reported results were mainly driven by eye gaze confounds in existing datasets. Still, these adverse outcomes are often discarded for reasons that are attributed to the limitations of the AV-GC-AAD dataset, such as the limited amount of data to train a working model, too much data heterogeneity due to different audiovisual conditions, or participants allegedly being unable to focus their auditory attention under the complex instructions. In this paper, we present the results of the linear stimulus reconstruction AAD algorithm and show that high AAD accuracy can be obtained within each individual condition and that the model generalizes across conditions, across new subjects, and even across datasets. Therefore, we eliminate any doubts that the inadequacy of the AV-GC-AAD dataset is the primary reason for the (spatial) AAD algorithms failing to achieve above-chance performance when compared to other datasets. Furthermore, this report provides a simple baseline evaluation procedure (including source code) that can serve as the minimal benchmark for all future AAD algorithms evaluated on this dataset.
Distributed Blind Source Separation based on FastICA
Oct 24, 2024

With the emergence of wireless sensor networks (WSNs), many traditional signal processing tasks are required to be computed in a distributed fashion, without transmissions of the raw data to a centralized processing unit, due to the limited energy and bandwidth resources available to the sensors. In this paper, we propose a distributed independent component analysis (ICA) algorithm, which aims at identifying the original signal sources based on observations of their mixtures measured at various sensor nodes. One of the most commonly used ICA algorithms is known as FastICA, which requires a spatial pre-whitening operation in the first step of the algorithm. Such a pre-whitening across all nodes of a WSN is impossible in a bandwidth-constrained distributed setting as it requires to correlate each channel with each other channel in the WSN. We show that an explicit network-wide pre-whitening step can be circumvented by leveraging the properties of the so-called Distributed Adaptive Signal Fusion (DASF) framework. Despite the lack of such a network-wide pre-whitening, we can still obtain the $Q$ least Gaussian independent components of the centralized ICA solution, where $Q$ scales linearly with the required communication load.
Conditional Gumbel-Softmax for constrained feature selection with application to node selection in wireless sensor networks
Jun 03, 2024



In this paper, we introduce Conditional Gumbel-Softmax as a method to perform end-to-end learning of the optimal feature subset for a given task and deep neural network (DNN) model, while adhering to certain pairwise constraints between the features. We do this by conditioning the selection of each feature in the subset on another feature. We demonstrate how this approach can be used to select the task-optimal nodes composing a wireless sensor network (WSN) while ensuring that none of the nodes that require communication between one another have too large of a distance between them, limiting the required power spent on this communication. We validate this approach on an emulated Wireless Electroencephalography (EEG) Sensor Network (WESN) solving a motor execution task. We analyze how the performance of the WESN varies as the constraints are made more stringent and how well the Conditional Gumbel-Softmax performs in comparison with a heuristic, greedy selection method. While the application focus of this paper is on wearable brain-computer interfaces, the proposed methodology is generic and can readily be applied to node deployment in wireless sensor networks and constrained feature selection in other applications as well.
Distributed Adaptive Spatial Filtering with Inexact Local Solvers
May 06, 2024The Distributed Adaptive Signal Fusion (DASF) framework is a meta-algorithm for computing data-driven spatial filters in a distributed sensing platform with limited bandwidth and computational resources, such as a wireless sensor network. The convergence and optimality of the DASF algorithm has been extensively studied under the assumption that an exact, but possibly impractical solver for the local optimization problem at each updating node is available. In this work, we provide convergence and optimality results for the DASF framework when used with an inexact, finite-time solver such as (proximal) gradient descent or Newton's method. We provide sufficient conditions that the solver should satisfy in order to guarantee convergence of the resulting algorithm, and a lower bound for the convergence rate. We also provide numerical simulations to validate these theoretical results.
A Distributed Adaptive Algorithm for Non-Smooth Spatial Filtering Problems in Wireless Sensor Networks
Mar 13, 2024A wireless sensor network often relies on a fusion center to process the data collected by each of its sensing nodes. Such an approach relies on the continuous transmission of raw data to the fusion center, which typically has a major impact on the sensors' battery life. To address this issue in the particular context of spatial filtering and signal fusion problems, we recently proposed the Distributed Adaptive Signal Fusion (DASF) algorithm, which distributively computes a spatial filter expressed as the solution of a smooth optimization problem involving the network-wide sensor signal statistics. In this work, we show that the DASF algorithm can be extended to compute the filters associated with a certain class of non-smooth optimization problems. This extension makes the addition of sparsity-inducing norms to the problem's cost function possible, allowing sensor selection to be performed in a distributed fashion, alongside the filtering task of interest, thereby further reducing the network's energy consumption. We provide a description of the algorithm, prove its convergence, and validate its performance and solution tracking capabilities with numerical experiments.