 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSocAoG: Incremental Graph Parsing for Social Relation Inference in Dialogues
Jun 24, 2021
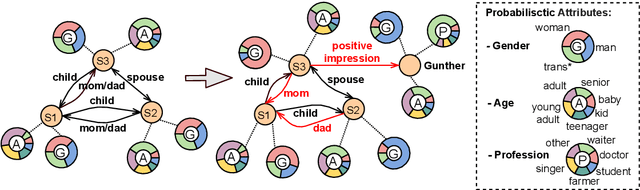
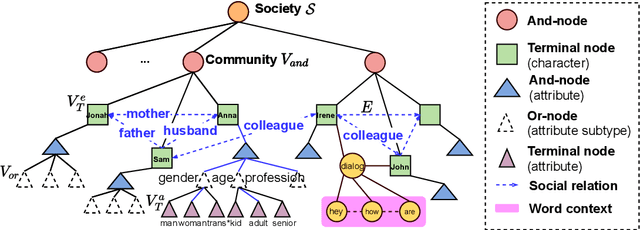
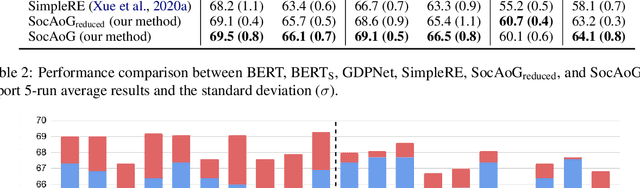
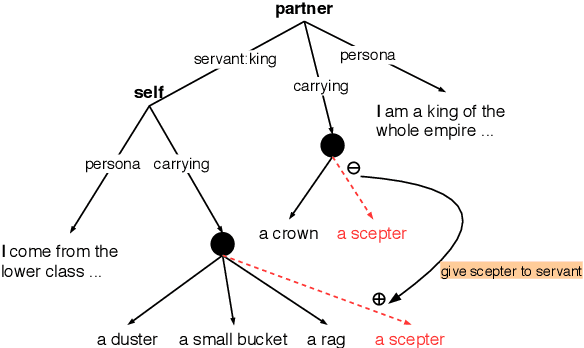
Inferring social relations from dialogues is vital for building emotionally intelligent robots to interpret human language better and act accordingly. We model the social network as an And-or Graph, named SocAoG, for the consistency of relations among a group and leveraging attributes as inference cues. Moreover, we formulate a sequential structure prediction task, and propose an $\alpha$-$\beta$-$\gamma$ strategy to incrementally parse SocAoG for the dynamic inference upon any incoming utterance: (i) an $\alpha$ process predicting attributes and relations conditioned on the semantics of dialogues, (ii) a $\beta$ process updating the social relations based on related attributes, and (iii) a $\gamma$ process updating individual's attributes based on interpersonal social relations. Empirical results on DialogRE and MovieGraph show that our model infers social relations more accurately than the state-of-the-art methods. Moreover, the ablation study shows the three processes complement each other, and the case study demonstrates the dynamic relational inference.
Towards Socially Intelligent Agents with Mental State Transition and Human Utility
Mar 12, 2021

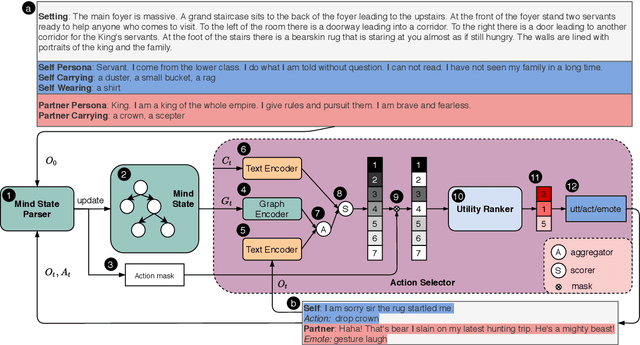
Building a socially intelligent agent involves many challenges, one of which is to track the agent's mental state transition and teach the agent to make rational decisions guided by its utility like a human. Towards this end, we propose to incorporate a mental state parser and utility model into dialogue agents. The hybrid mental state parser extracts information from both the dialogue and event observations and maintains a graphical representation of the agent's mind; Meanwhile, the utility model is a ranking model that learns human preferences from a crowd-sourced social commonsense dataset, Social IQA. Empirical results show that the proposed model attains state-of-the-art performance on the dialogue/action/emotion prediction task in the fantasy text-adventure game dataset, LIGHT. We also show example cases to demonstrate: (\textit{i}) how the proposed mental state parser can assist agent's decision by grounding on the context like locations and objects, and (\textit{ii}) how the utility model can help the agent make reasonable decisions in a dilemma. To the best of our knowledge, we are the first work that builds a socially intelligent agent by incorporating a hybrid mental state parser for both discrete events and continuous dialogues parsing and human-like utility modeling.
Atlas-aware ConvNetfor Accurate yet Robust Anatomical Segmentation
Feb 02, 2021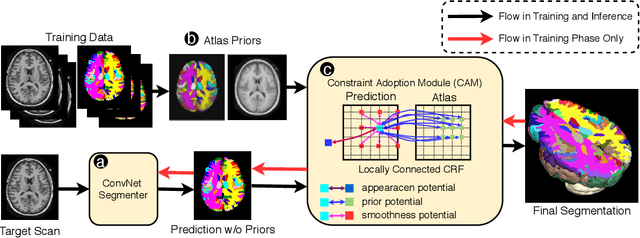
Convolutional networks (ConvNets) have achieved promising accuracy for various anatomical segmentation tasks. Despite the success, these methods can be sensitive to data appearance variations. Considering the large variability of scans caused by artifacts, pathologies, and scanning setups, robust ConvNets are vital for clinical applications, while have not been fully explored. In this paper, we propose to mitigate the challenge by enabling ConvNets' awareness of the underlying anatomical invariances among imaging scans. Specifically, we introduce a fully convolutional Constraint Adoption Module (CAM) that incorporates probabilistic atlas priors as explicit constraints for predictions over a locally connected Conditional Random Field (CFR), which effectively reinforces the anatomical consistency of the labeling outputs. We design the CAM to be flexible for boosting various ConvNet, and compact for co-optimizing with ConvNets for fusion parameters that leads to the optimal performance. We show the advantage of such atlas priors fusion is two-fold with two brain parcellation tasks. First, our models achieve state-of-the-art accuracy among ConvNet-based methods on both datasets, by significantly reducing structural abnormalities of predictions. Second, we can largely boost the robustness of existing ConvNets, proved by: (i) testing on scans with synthetic pathologies, and (ii) training and evaluation on scans of different scanning setups across datasets. Our method is proposing to be easily adopted to existing ConvNets by fine-tuning with CAM plugged in for accuracy and robustness boosts.
Exploring Instance-Level Uncertainty for Medical Detection
Jan 09, 2021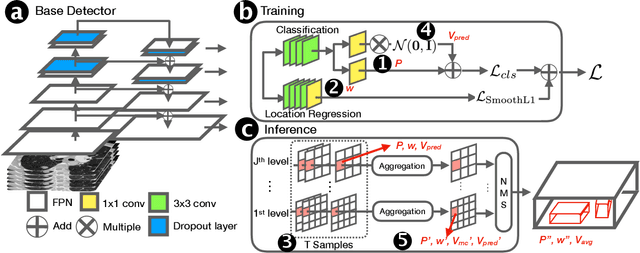
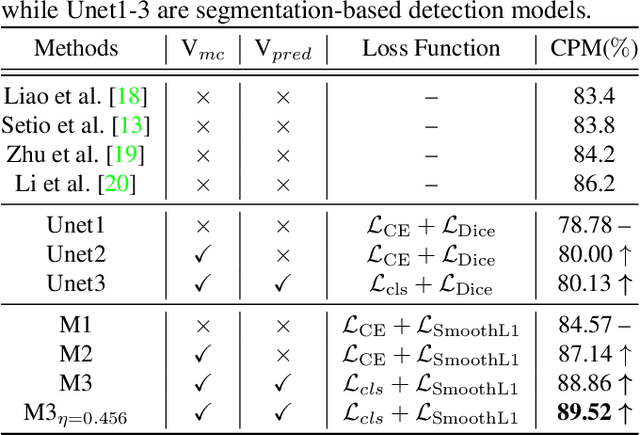
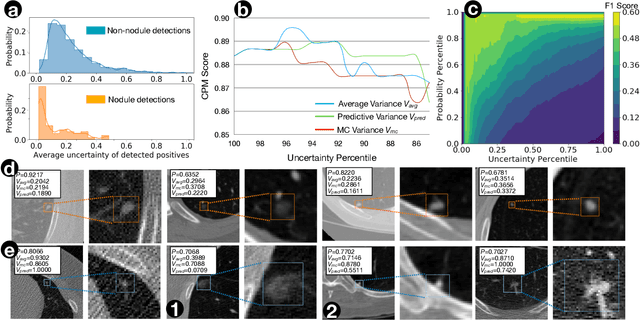
The ability of deep learning to predict with uncertainty is recognized as key for its adoption in clinical routines. Moreover, performance gain has been enabled by modelling uncertainty according to empirical evidence. While previous work has widely discussed the uncertainty estimation in segmentation and classification tasks, its application on bounding-box-based detection has been limited, mainly due to the challenge of bounding box aligning. In this work, we explore to augment a 2.5D detection CNN with two different bounding-box-level (or instance-level) uncertainty estimates, i.e., predictive variance and Monte Carlo (MC) sample variance. Experiments are conducted for lung nodule detection on LUNA16 dataset, a task where significant semantic ambiguities can exist between nodules and non-nodules. Results show that our method improves the evaluating score from 84.57% to 88.86% by utilizing a combination of both types of variances. Moreover, we show the generated uncertainty enables superior operating points compared to using the probability threshold only, and can further boost the performance to 89.52%. Example nodule detections are visualized to further illustrate the advantages of our method.
Audrey: A Personalized Open-Domain Conversational Bot
Nov 11, 2020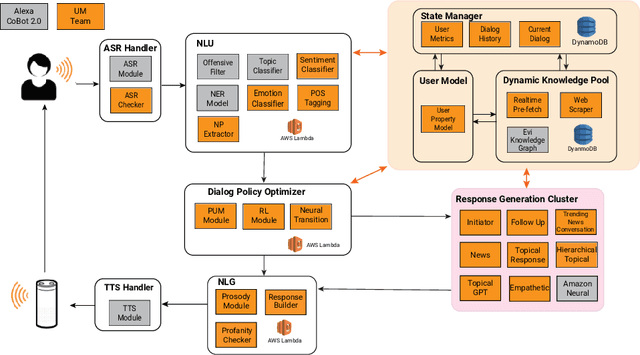


Conversational Intelligence requires that a person engage on informational, personal and relational levels. Advances in Natural Language Understanding have helped recent chatbots succeed at dialog on the informational level. However, current techniques still lag for conversing with humans on a personal level and fully relating to them. The University of Michigan's submission to the Alexa Prize Grand Challenge 3, Audrey, is an open-domain conversational chat-bot that aims to engage customers on these levels through interest driven conversations guided by customers' personalities and emotions. Audrey is built from socially-aware models such as Emotion Detection and a Personal Understanding Module to grasp a deeper understanding of users' interests and desires. Our architecture interacts with customers using a hybrid approach balanced between knowledge-driven response generators and context-driven neural response generators to cater to all three levels of conversations. During the semi-finals period, we achieved an average cumulative rating of 3.25 on a 1-5 Likert scale.
Structured Attention for Unsupervised Dialogue Structure Induction
Oct 09, 2020

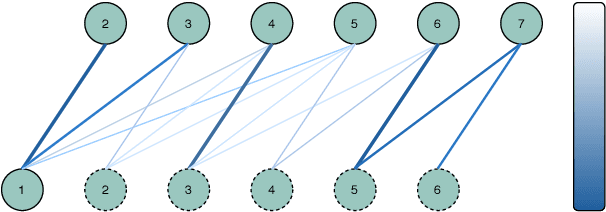
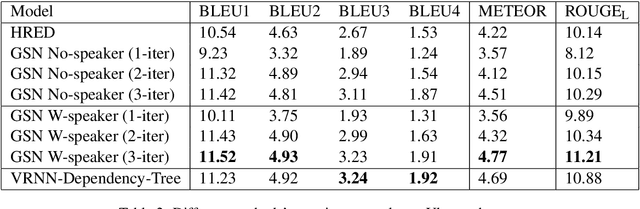
Inducing a meaningful structural representation from one or a set of dialogues is a crucial but challenging task in computational linguistics. Advancement made in this area is critical for dialogue system design and discourse analysis. It can also be extended to solve grammatical inference. In this work, we propose to incorporate structured attention layers into a Variational Recurrent Neural Network (VRNN) model with discrete latent states to learn dialogue structure in an unsupervised fashion. Compared to a vanilla VRNN, structured attention enables a model to focus on different parts of the source sentence embeddings while enforcing a structural inductive bias. Experiments show that on two-party dialogue datasets, VRNN with structured attention learns semantic structures that are similar to templates used to generate this dialogue corpus. While on multi-party dialogue datasets, our model learns an interactive structure demonstrating its capability of distinguishing speakers or addresses, automatically disentangling dialogues without explicit human annotation.
An Isolated Data Island Benchmark Suite for Federated Learning
Aug 17, 2020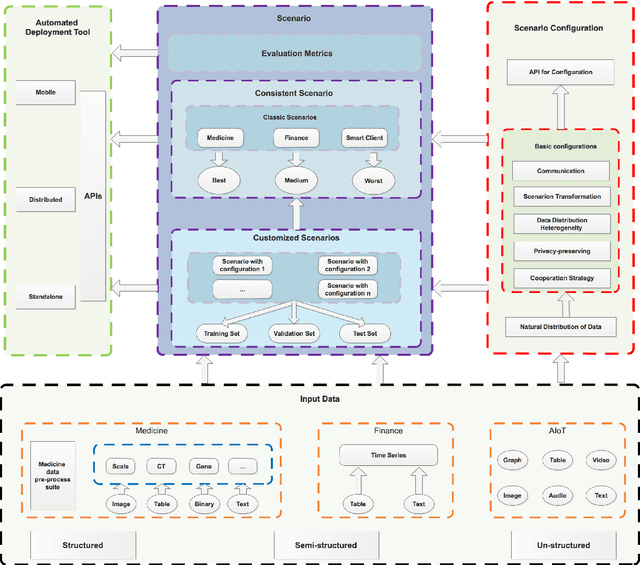
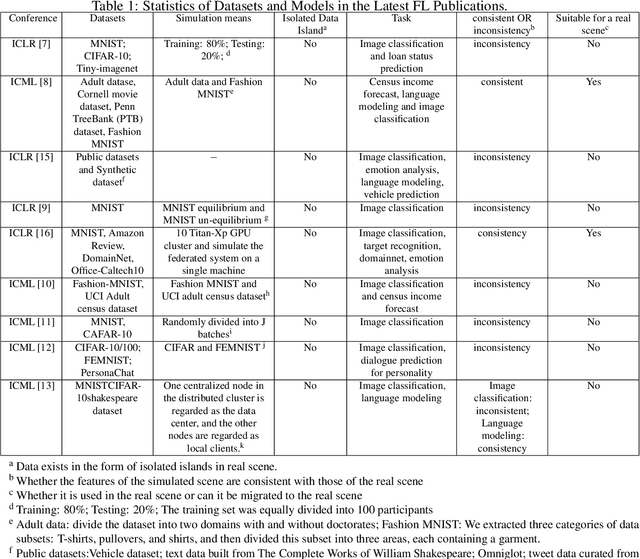
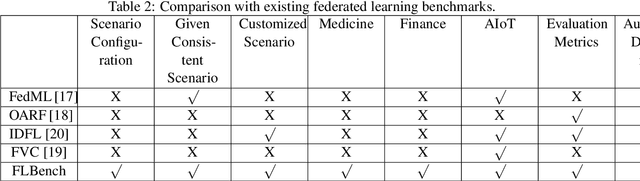
Federated learning (FL) is a new machine learning paradigm, the goal of which is to build a machine learning model based on data sets distributed on multiple devices--so called Isolated Data Island--while keeping their data secure and private. Most existing work manually splits commonly-used public datasets into partitions to simulate real-world Isolated Data Island while failing to capture the intrinsic characteristics of real-world domain data, like medicine, finance or AIoT. To bridge this huge gap, this paper presents and characterizes an Isolated Data Island benchmark suite, named FLBench, for benchmarking federated learning algorithms. FLBench contains three domains: medical, financial and AIoT. By configuring various domains, FLBench is qualified for evaluating the important research aspects of federated learning, and hence become a promising platform for developing novel federated learning algorithms. Finally, FLBench is fully open-sourced and in fast-evolution. We package it as an automated deployment tool. The benchmark suite will be publicly available from http://www.benchcouncil.org/FLBench.
Oral-3D: Reconstructing the 3D Bone Structure of Oral Cavity from 2D Panoramic X-ray
Mar 26, 2020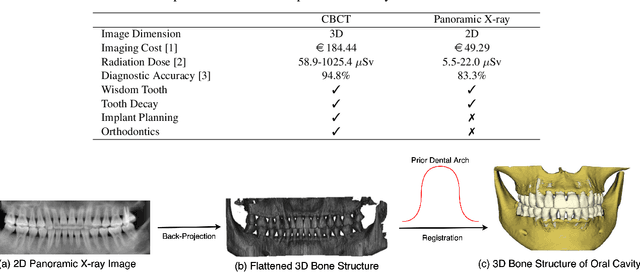

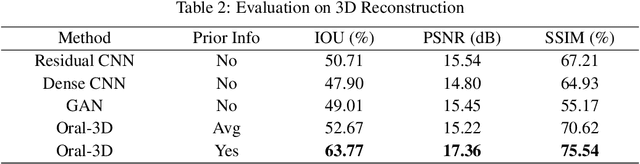
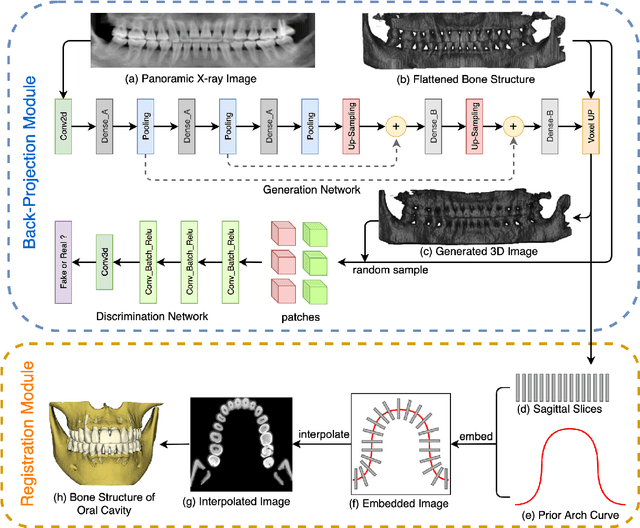
Panoramic X-ray and Cone Beam Computed Tomography (CBCT) are two of the most general imaging methods in digital dentistry. While CBCT can provide higher-dimension information, the panoramic X-ray has the advantages of lower radiation dose and cost. Consequently, generating 3D information of bony tissues from the X-ray that can reflect dental diseases is of great interest. This technique can be even more helpful for developing areas where the CBCT is not always available due to the lack of screening machines or high screening cost. In this paper, we present \textit{Oral-3D} to reconstruct the bone structure of oral cavity from a single panoramic X-ray image by taking advantage of some prior knowledge in oral structure, which conventionally can only be obtained by a 3D imaging method like CBCT. Specifically, we first train a generative network to back project the 2D X-ray image into 3D space, then restore the bone structure by registering the generated 3D image with the prior shape of the dental arch. To be noted, \textit{Oral-3D} can restore both the density of bony tissues and the curved mandible surface. Experimental results show that our framework can reconstruct the 3D structure with significantly high quality. To the best of our knowledge, this is the first work that explores 3D reconstruction from a 2D image in dental health.
T-Net: A Template-Supervised Network for Task-specific Feature Extraction in Biomedical Image Analysis
Feb 19, 2020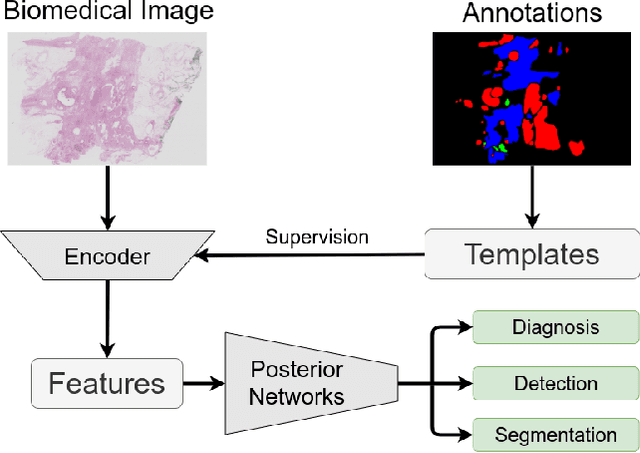

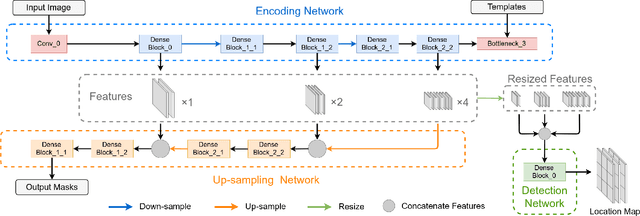
Existing deep learning methods depend on an encoder-decoder structure to learn feature representation from the segmentation annotation in biomedical image analysis. However, the effectiveness of feature extraction under this structure decreases due to the indirect optimization process, limited training data size, and simplex supervision method. In this paper, we propose a template-supervised network T-Net for task-specific feature extraction. Specifically, we first obtain templates from pixel-level annotations by down-sampling binary masks of recognition targets according to specific tasks. Then, we directly train the encoding network under the supervision of the derived task-specific templates. Finally, we combine the resulting encoding network with a posterior network for the specific task, e.g. an up-sampling network for segmentation or a region proposal network for detection. Extensive experiments on three public datasets (BraTS-17, MoNuSeg and IDRiD) show that T-Net achieves competitive results to the state-of-the-art methods and superior performance to an encoder-decoder based network. To the best of our knowledge, this is the first in-depth study to improve feature extraction by directly supervise the encoding network and by applying task-specific supervision in biomedical image analysis.
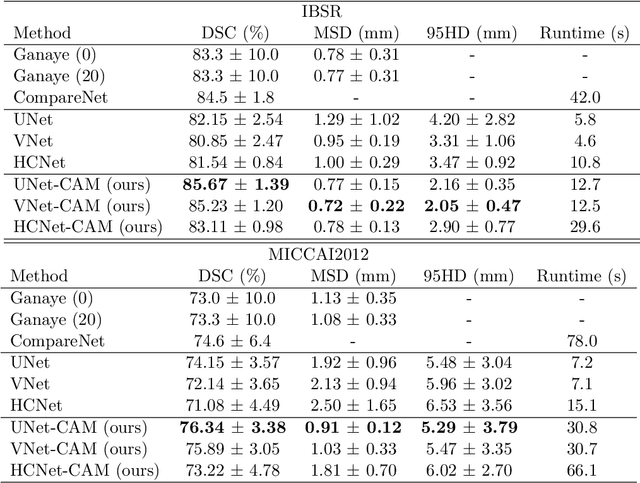
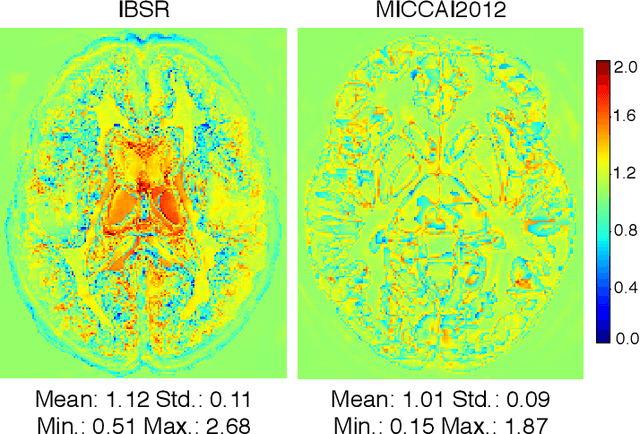
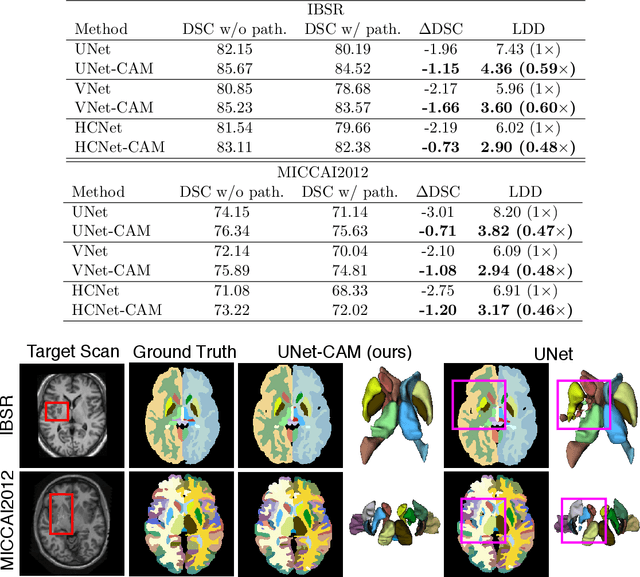
CompareNet: Anatomical Segmentation Network with Deep Non-local Label Fusion
Oct 10, 2019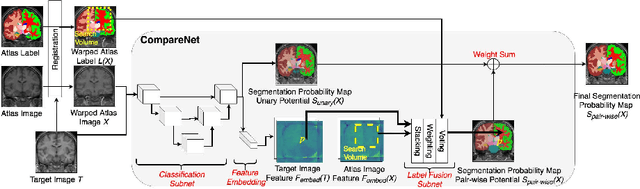
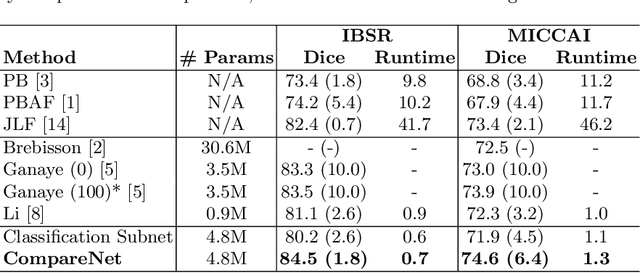
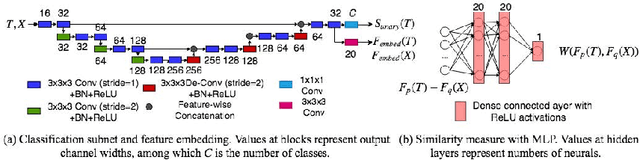

Label propagation is a popular technique for anatomical segmentation. In this work, we propose a novel deep framework for label propagation based on non-local label fusion. Our framework, named CompareNet, incorporates subnets for both extracting discriminating features, and learning the similarity measure, which lead to accurate segmentation. We also introduce the voxel-wise classification as an unary potential to the label fusion function, for alleviating the search failure issue of the existing non-local fusion strategies. Moreover, CompareNet is end-to-end trainable, and all the parameters are learnt together for the optimal performance. By evaluating CompareNet on two public datasets IBSRv2 and MICCAI 2012 for brain segmentation, we show it outperforms state-of-the-art methods in accuracy, while being robust to pathologies.