 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Information Bottleneck for Scientific Document Summarization
Oct 04, 2021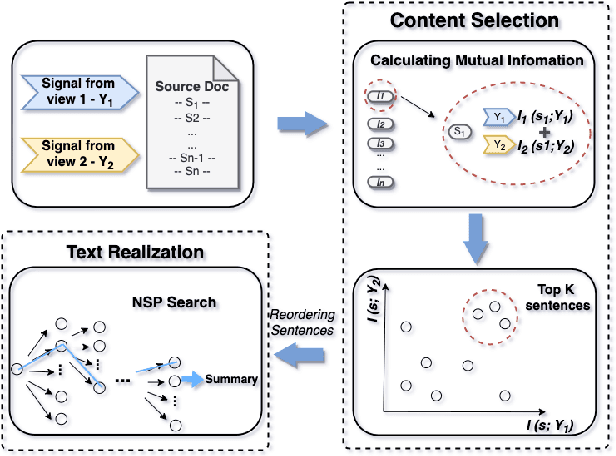
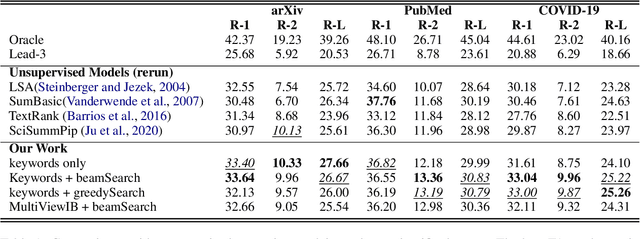
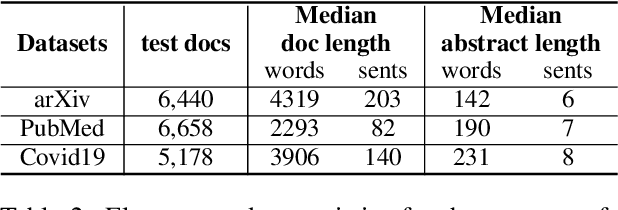
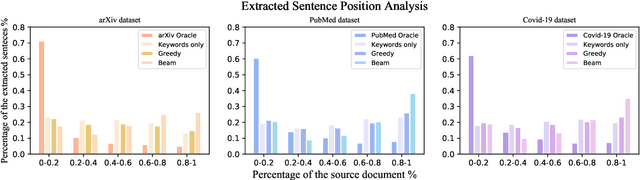
This paper presents an unsupervised extractive approach to summarize scientific long documents based on the Information Bottleneck principle. Inspired by previous work which uses the Information Bottleneck principle for sentence compression, we extend it to document level summarization with two separate steps. In the first step, we use signal(s) as queries to retrieve the key content from the source document. Then, a pre-trained language model conducts further sentence search and edit to return the final extracted summaries. Importantly, our work can be flexibly extended to a multi-view framework by different signals. Automatic evaluation on three scientific document datasets verifies the effectiveness of the proposed framework. The further human evaluation suggests that the extracted summaries cover more content aspects than previous systems.
Learning to Rearrange Voxels in Binary Segmentation Masks for Smooth Manifold Triangulation
Aug 11, 2021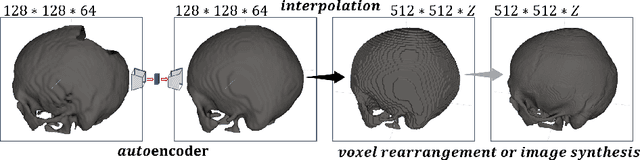
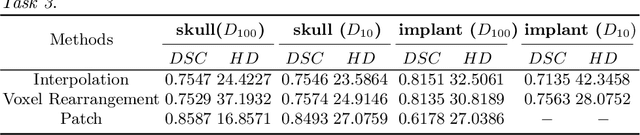
Medical images, especially volumetric images, are of high resolution and often exceed the capacity of standard desktop GPUs. As a result, most deep learning-based medical image analysis tasks require the input images to be downsampled, often substantially, before these can be fed to a neural network. However, downsampling can lead to a loss of image quality, which is undesirable especially in reconstruction tasks, where the fine geometric details need to be preserved. In this paper, we propose that high-resolution images can be reconstructed in a coarse-to-fine fashion, where a deep learning algorithm is only responsible for generating a coarse representation of the image, which consumes moderate GPU memory. For producing the high-resolution outcome, we propose two novel methods: learned voxel rearrangement of the coarse output and hierarchical image synthesis. Compared to the coarse output, the high-resolution counterpart allows for smooth surface triangulation, which can be 3D-printed in the highest possible quality. Experiments of this paper are carried out on the dataset of AutoImplant 2021 (https://autoimplant2021.grand-challenge.org/), a MICCAI challenge on cranial implant design. The dataset contains high-resolution skulls that can be viewed as 2D manifolds embedded in a 3D space. Codes associated with this study can be accessed at https://github.com/Jianningli/voxel_rearrangement.
AI-based Aortic Vessel Tree Segmentation for Cardiovascular Diseases Treatment: Status Quo
Aug 06, 2021
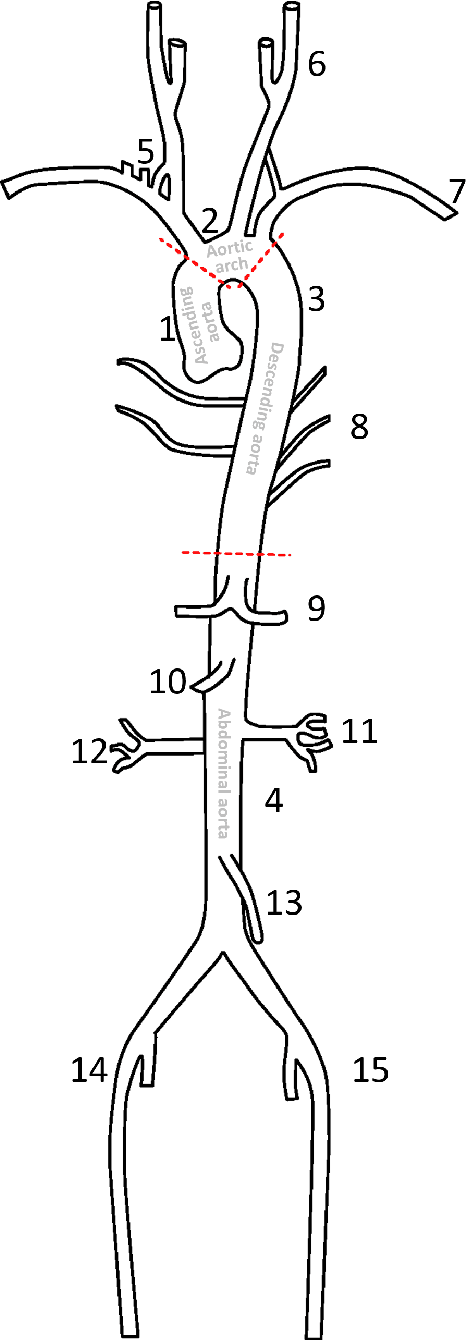
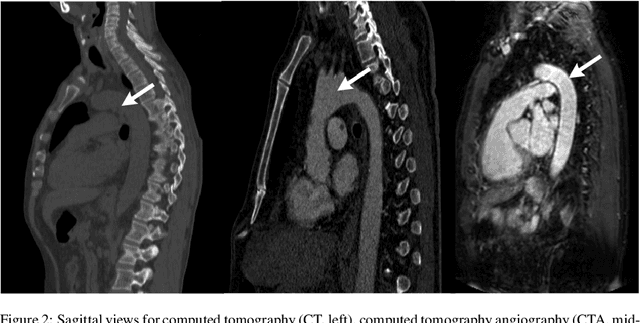
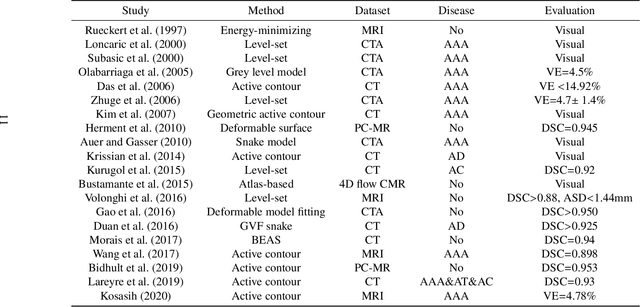
The aortic vessel tree is composed of the aorta and its branching arteries, and plays a key role in supplying the whole body with blood. Aortic diseases, like aneurysms or dissections, can lead to an aortic rupture, whose treatment with open surgery is highly risky. Therefore, patients commonly undergo drug treatment under constant monitoring, which requires regular inspections of the vessels through imaging. The standard imaging modality for diagnosis and monitoring is computed tomography (CT), which can provide a detailed picture of the aorta and its branching vessels if combined with a contrast agent, resulting in a CT angiography (CTA). Optimally, the whole aortic vessel tree geometry from consecutive CTAs, are overlaid and compared. This allows to not only detect changes in the aorta, but also more peripheral vessel tree changes, caused by the primary pathology or newly developed. When performed manually, this reconstruction requires slice by slice contouring, which could easily take a whole day for a single aortic vessel tree and, hence, is not feasible in clinical practice. Automatic or semi-automatic vessel tree segmentation algorithms, on the other hand, can complete this task in a fraction of the manual execution time and run in parallel to the clinical routine of the clinicians. In this paper, we systematically review computing techniques for the automatic and semi-automatic segmentation of the aortic vessel tree. The review concludes with an in-depth discussion on how close these state-of-the-art approaches are to an application in clinical practice and how active this research field is, taking into account the number of publications, datasets and challenges.
Federated Learning Meets Natural Language Processing: A Survey
Jul 27, 2021Federated Learning aims to learn machine learning models from multiple decentralized edge devices (e.g. mobiles) or servers without sacrificing local data privacy. Recent Natural Language Processing techniques rely on deep learning and large pre-trained language models. However, both big deep neural and language models are trained with huge amounts of data which often lies on the server side. Since text data is widely originated from end users, in this work, we look into recent NLP models and techniques which use federated learning as the learning framework. Our survey discusses major challenges in federated natural language processing, including the algorithm challenges, system challenges as well as the privacy issues. We also provide a critical review of the existing Federated NLP evaluation methods and tools. Finally, we highlight the current research gaps and future directions.
Topic Modelling Meets Deep Neural Networks: A Survey
Feb 28, 2021
Topic modelling has been a successful technique for text analysis for almost twenty years. When topic modelling met deep neural networks, there emerged a new and increasingly popular research area, neural topic models, with over a hundred models developed and a wide range of applications in neural language understanding such as text generation, summarisation and language models. There is a need to summarise research developments and discuss open problems and future directions. In this paper, we provide a focused yet comprehensive overview of neural topic models for interested researchers in the AI community, so as to facilitate them to navigate and innovate in this fast-growing research area. To the best of our knowledge, ours is the first review focusing on this specific topic.
Discriminative, Generative and Self-Supervised Approaches for Target-Agnostic Learning
Nov 12, 2020
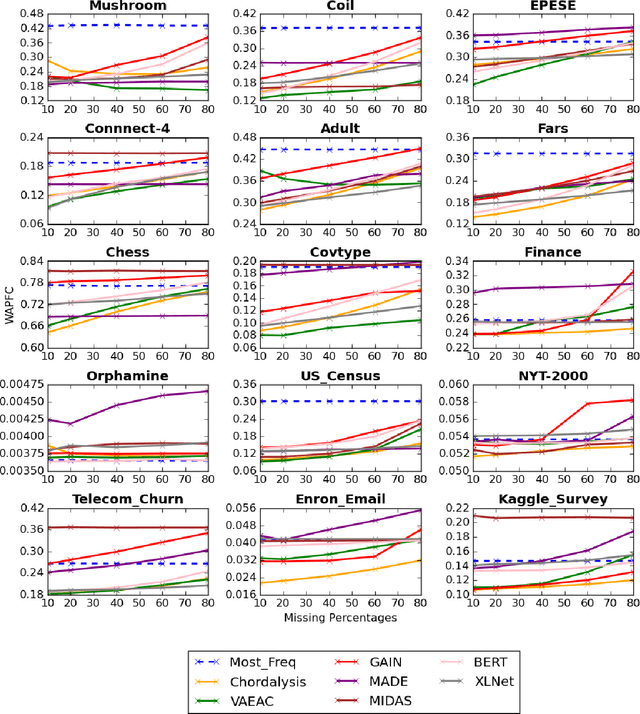
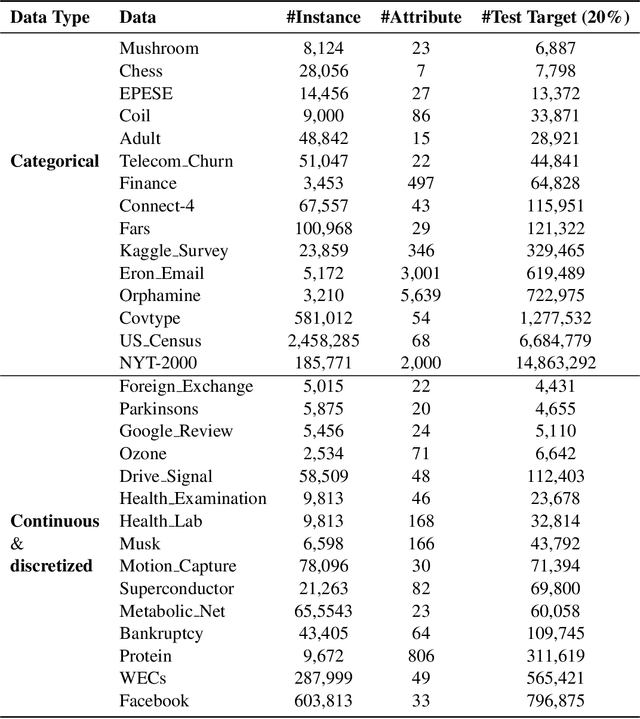
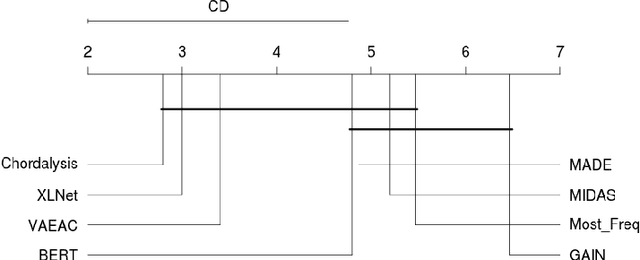
Supervised learning, characterized by both discriminative and generative learning, seeks to predict the values of single (or sometimes multiple) predefined target attributes based on a predefined set of predictor attributes. For applications where the information available and predictions to be made may vary from instance to instance, we propose the task of target-agnostic learning where arbitrary disjoint sets of attributes can be used for each of predictors and targets for each to-be-predicted instance. For this task, we survey a wide range of techniques available for handling missing values, self-supervised training and pseudo-likelihood training, and adapt them to a suite of algorithms that are suitable for the task. We conduct extensive experiments on this suite of algorithms on a large collection of categorical, continuous and discretized datasets, and report their performance in terms of both classification and regression errors. We also report the training and prediction time of these algorithms when handling large-scale datasets. Both generative and self-supervised learning models are shown to perform well at the task, although their characteristics towards the different types of data are quite different. Nevertheless, our derived theorem for the pseudo-likelihood theory also shows that they are related for inferring a joint distribution model based on the pseudo-likelihood training.
SummPip: Unsupervised Multi-Document Summarization with Sentence Graph Compression
Jul 20, 2020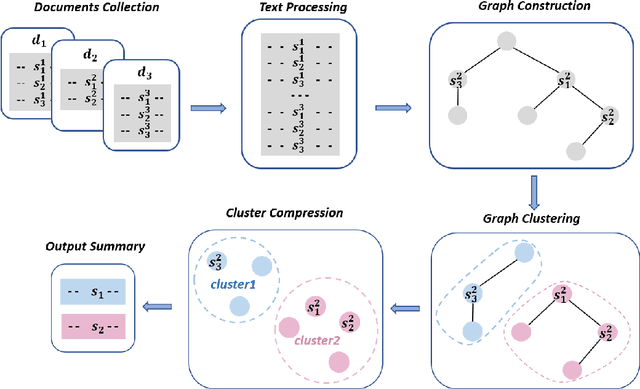
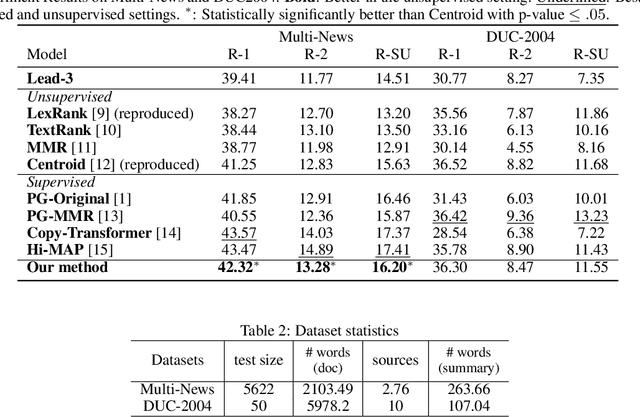
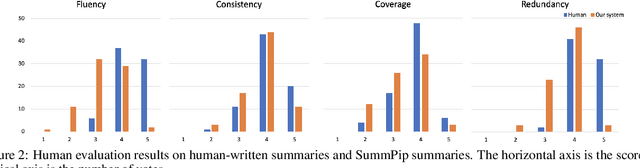
Obtaining training data for multi-document summarization (MDS) is time consuming and resource-intensive, so recent neural models can only be trained for limited domains. In this paper, we propose SummPip: an unsupervised method for multi-document summarization, in which we convert the original documents to a sentence graph, taking both linguistic and deep representation into account, then apply spectral clustering to obtain multiple clusters of sentences, and finally compress each cluster to generate the final summary. Experiments on Multi-News and DUC-2004 datasets show that our method is competitive to previous unsupervised methods and is even comparable to the neural supervised approaches. In addition, human evaluation shows our system produces consistent and complete summaries compared to human written ones.
Privacy-Preserving Technology to Help Millions of People: Federated Prediction Model for Stroke Prevention
Jun 15, 2020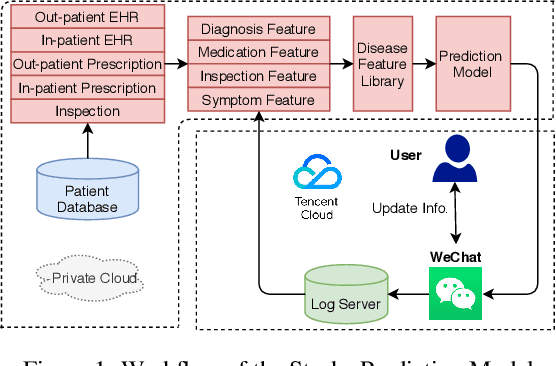
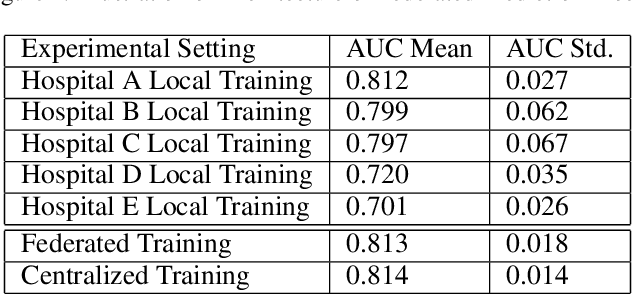
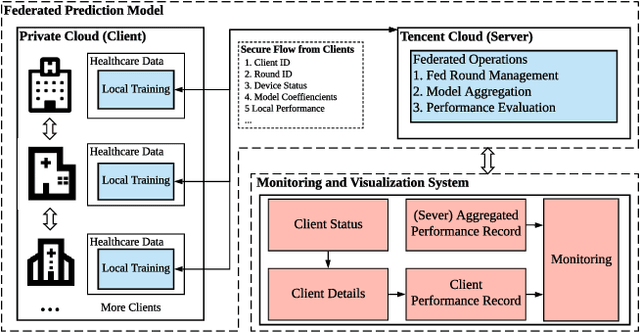
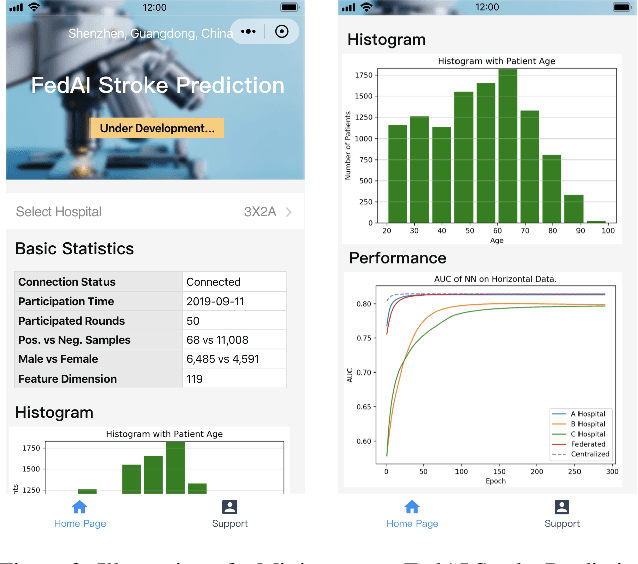
prevention of stroke with its associated risk factors has been one of the public health priorities worldwide. Emerging artificial intelligence technology is being increasingly adopted to predict stroke. Because of privacy concerns, patient data are stored in distributed electronic health record (EHR) databases, voluminous clinical datasets, which prevent patient data from being aggregated and restrains AI technology to boost the accuracy of stroke prediction with centralized training data. In this work, our scientists and engineers propose a privacy-preserving scheme to predict the risk of stroke and deploy our federated prediction model on cloud servers. Our system of federated prediction model asynchronously supports any number of client connections and arbitrary local gradient iterations in each communication round. It adopts federated averaging during the model training process, without patient data being taken out of the hospitals during the whole process of model training and forecasting. With the privacy-preserving mechanism, our federated prediction model trains over all the healthcare data from hospitals in a certain city without actual data sharing among them. Therefore, it is not only secure but also more accurate than any single prediction model that trains over the data only from one single hospital. Especially for small hospitals with few confirmed stroke cases, our federated model boosts model performance by 10%~20% in several machine learning metrics. To help stroke experts comprehend the advantage of our prediction system more intuitively, we developed a mobile app that collects the key information of patients' statistics and demonstrates performance comparisons between the federated prediction model and the single prediction model during the federated training process.
Leveraging Cross Feedback of User and Item Embeddings for Variational Autoencoder based Collaborative Filtering
Feb 21, 2020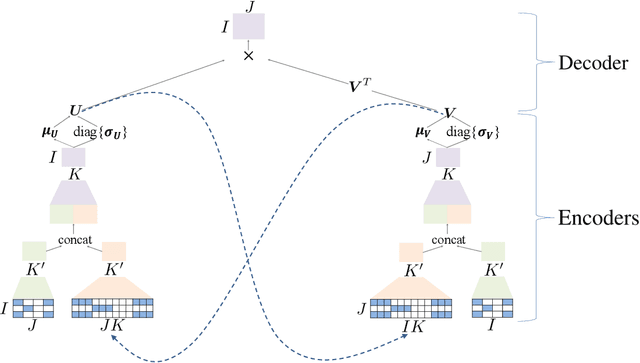

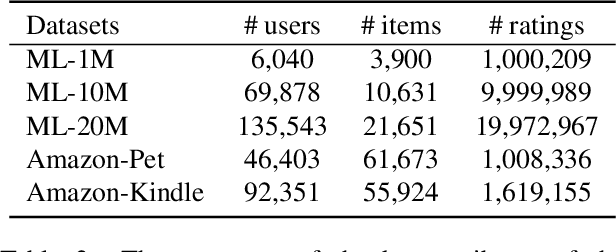
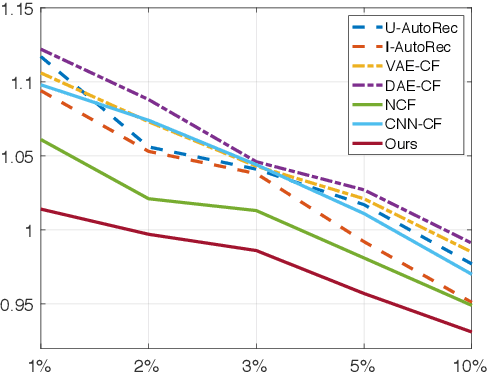
Matrix factorization (MF) has been widely applied to collaborative filtering in recommendation systems. Its Bayesian variants can derive posterior distributions of user and item embeddings, and are more robust to sparse ratings. However, the Bayesian methods are restricted by their update rules for the posterior parameters due to the conjugacy of the priors and the likelihood. Neural networks can potentially address this issue by capturing complex mappings between the posterior parameters and the data. In this paper, we propose a variational auto-encoder based Bayesian MF framework. It leverages not only the data but also the information from the embeddings to approximate their joint posterior distribution. The approximation is an iterative procedure with cross feedback of user and item embeddings to the others' encoders. More specifically, user embeddings sampled in the previous iteration, alongside their ratings, are fed back into the item-side encoders to compute the posterior parameters for the item embeddings in the current iteration, and vice versa. The decoder network then reconstructs the data using the MF with the currently re-sampled user and item embeddings. We show the effectiveness of our framework in terms of reconstruction errors across five real-world datasets. We also perform ablation studies to illustrate the importance of the cross feedback component of our framework in lowering the reconstruction errors and accelerating the convergence.
Variational Auto-encoder Based Bayesian Poisson Tensor Factorization for Sparse and Imbalanced Count Data
Oct 12, 2019


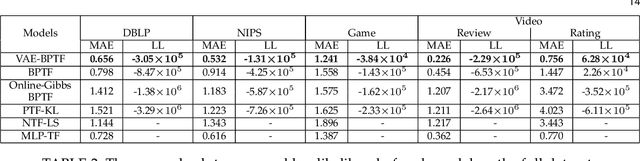
Non-negative tensor factorization models enable predictive analysis on count data. Among them, Bayesian Poisson-Gamma models are able to derive full posterior distributions of latent factors and are less sensitive to sparse count data. However, current inference methods for these Bayesian models adopt restricted update rules for the posterior parameters. They also fail to share the update information to better cope with the data sparsity. Moreover, these models are not endowed with a component that handles the imbalance in count data values. In this paper, we propose a novel variational auto-encoder framework called VAE-BPTF which addresses the above issues. It uses multi-layer perceptron networks to encode and share complex update information. The encoded information is then reweighted per data instance to penalize common data values before aggregated to compute the posterior parameters for the latent factors. Under synthetic data evaluation, VAE-BPTF tended to recover the right number of latent factors and posterior parameter values. It also outperformed current models in both reconstruction errors and latent factor (semantic) coherence across five real-world datasets. Furthermore, the latent factors inferred by VAE-BPTF are perceived to be meaningful and coherent under a qualitative analysis.