 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrivacy-Preserving Technology to Help Millions of People: Federated Prediction Model for Stroke Prevention
Paper and Code
Jun 15, 2020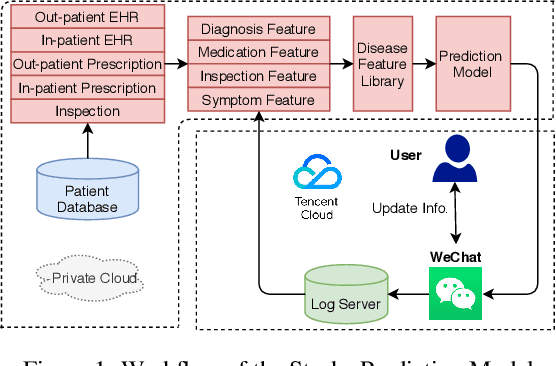
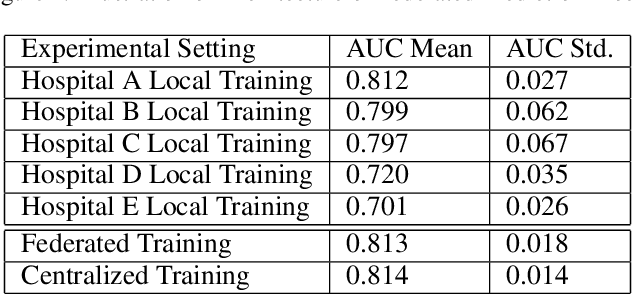
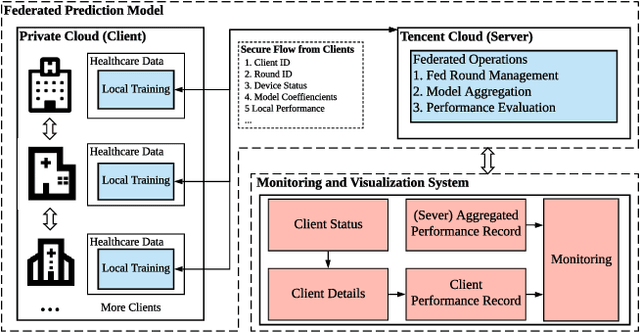
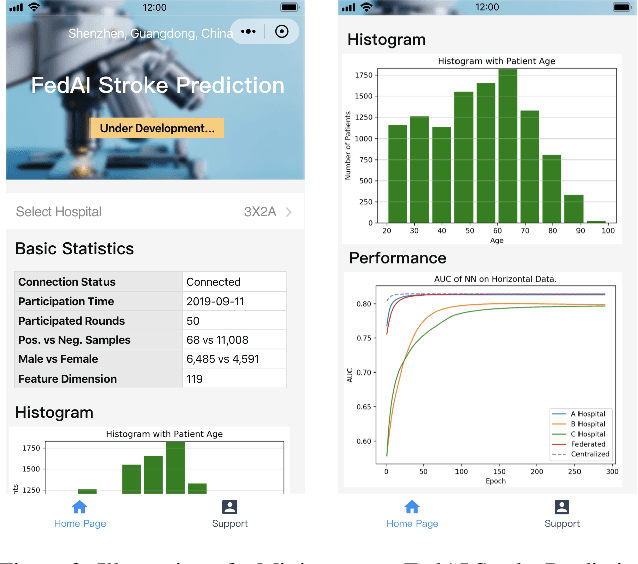
prevention of stroke with its associated risk factors has been one of the public health priorities worldwide. Emerging artificial intelligence technology is being increasingly adopted to predict stroke. Because of privacy concerns, patient data are stored in distributed electronic health record (EHR) databases, voluminous clinical datasets, which prevent patient data from being aggregated and restrains AI technology to boost the accuracy of stroke prediction with centralized training data. In this work, our scientists and engineers propose a privacy-preserving scheme to predict the risk of stroke and deploy our federated prediction model on cloud servers. Our system of federated prediction model asynchronously supports any number of client connections and arbitrary local gradient iterations in each communication round. It adopts federated averaging during the model training process, without patient data being taken out of the hospitals during the whole process of model training and forecasting. With the privacy-preserving mechanism, our federated prediction model trains over all the healthcare data from hospitals in a certain city without actual data sharing among them. Therefore, it is not only secure but also more accurate than any single prediction model that trains over the data only from one single hospital. Especially for small hospitals with few confirmed stroke cases, our federated model boosts model performance by 10%~20% in several machine learning metrics. To help stroke experts comprehend the advantage of our prediction system more intuitively, we developed a mobile app that collects the key information of patients' statistics and demonstrates performance comparisons between the federated prediction model and the single prediction model during the federated training process.