 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTracking Listener Attention: Gaze-Guided Audio-Visual Speech Enhancement Framework
Apr 09, 2026This paper presents a Gaze-Guided Audio-Visual Speech Enhancement (GG-AVSE) framework to address the cocktail party problem. A major challenge in conventional AVSE is identifying the listener's intended speaker in multi-talker environments. GG-AVSE addresses this issue by exploiting gaze direction as a supervisory cue for target-speaker selection. Specifically, we propose the GG-VM module, which combines gaze signals with a YOLO5Face detector to extract the target speaker's facial features and integrates them with the pretrained AVSEMamba model through two strategies: zero-shot merging and partial visual fine-tuning. For evaluation, we introduce the AVSEC2-Gaze dataset. Experimental results show that GG-AVSE achieves substantial performance gains over gaze-free baselines: a 10.08% improvement in PESQ (2.370 to 2.609), a 5.18% improvement in STOI (0.8802 to 0.9258), and a 23.69% improvement in SI-SDR (9.16 to 11.33). These results confirm that gaze provides an effective cue for resolving target-speaker ambiguity and highlight the scalability of GG-AVSE for real-world applications.
Leveraging Joint Spectral and Spatial Learning with MAMBA for Multichannel Speech Enhancement
Sep 16, 2024



In multichannel speech enhancement, effectively capturing spatial and spectral information across different microphones is crucial for noise reduction. Traditional methods, such as CNN or LSTM, attempt to model the temporal dynamics of full-band and sub-band spectral and spatial features. However, these approaches face limitations in fully modeling complex temporal dependencies, especially in dynamic acoustic environments. To overcome these challenges, we modify the current advanced model McNet by introducing an improved version of Mamba, a state-space model, and further propose MCMamba. MCMamba has been completely reengineered to integrate full-band and narrow-band spatial information with sub-band and full-band spectral features, providing a more comprehensive approach to modeling spatial and spectral information. Our experimental results demonstrate that MCMamba significantly improves the modeling of spatial and spectral features in multichannel speech enhancement, outperforming McNet and achieving state-of-the-art performance on the CHiME-3 dataset. Additionally, we find that Mamba performs exceptionally well in modeling spectral information.
Bridging the Gap: Integrating Pre-trained Speech Enhancement and Recognition Models for Robust Speech Recognition
Jun 18, 2024Noise robustness is critical when applying automatic speech recognition (ASR) in real-world scenarios. One solution involves the used of speech enhancement (SE) models as the front end of ASR. However, neural network-based (NN-based) SE often introduces artifacts into the enhanced signals and harms ASR performance, particularly when SE and ASR are independently trained. Therefore, this study introduces a simple yet effective SE post-processing technique to address the gap between various pre-trained SE and ASR models. A bridge module, which is a lightweight NN, is proposed to evaluate the signal-level information of the speech signal. Subsequently, using the signal-level information, the observation addition technique is applied to effectively reduce the shortcomings of SE. The experimental results demonstrate the success of our method in integrating diverse pre-trained SE and ASR models, considerably boosting the ASR robustness. Crucially, no prior knowledge of the ASR or speech contents is required during the training or inference stages. Moreover, the effectiveness of this approach extends to different datasets without necessitating the fine-tuning of the bridge module, ensuring efficiency and improved generalization.
CITISEN: A Deep Learning-Based Speech Signal-Processing Mobile Application
Aug 21, 2020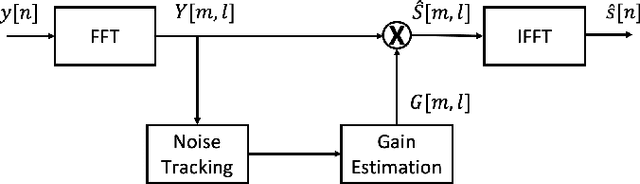
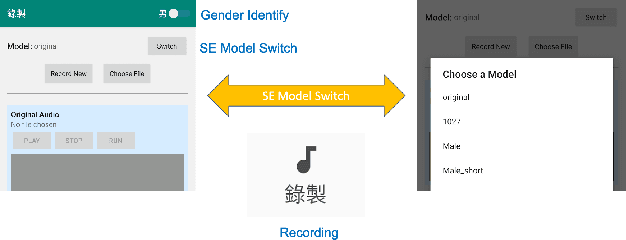
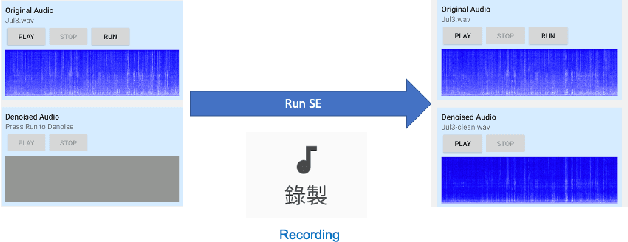
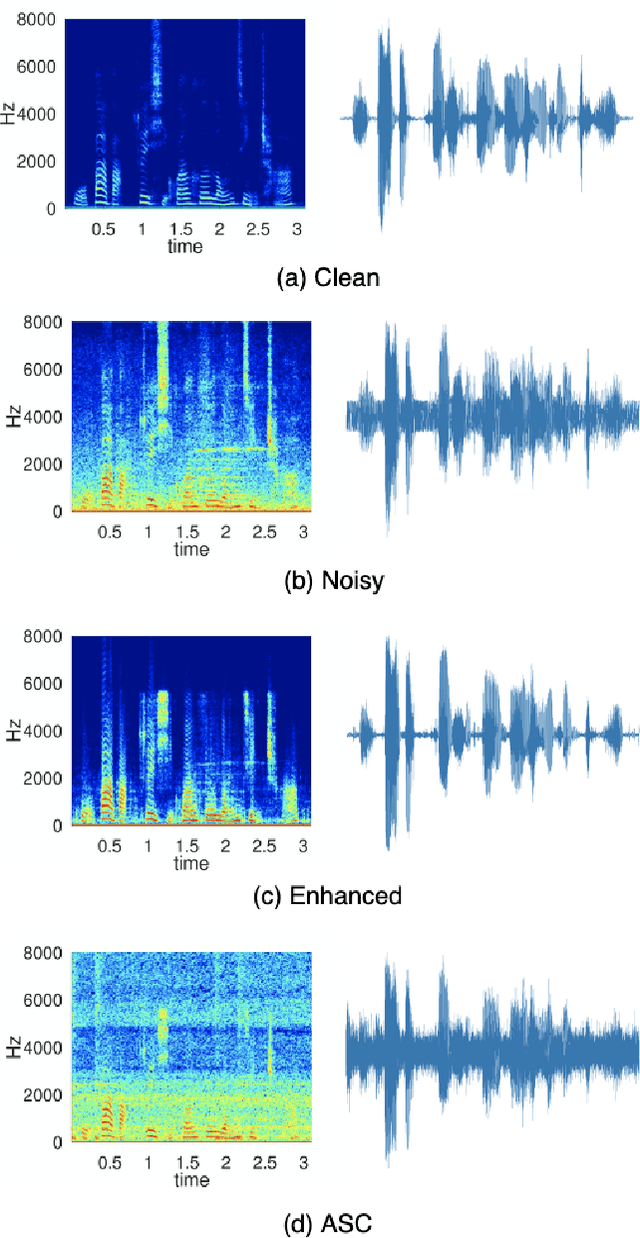
In this paper, we present a deep learning-based speech signal-processing mobile application, CITISEN, which can perform three functions: speech enhancement (SE), acoustic scene conversion (ASC), and model adaptation (MA). For SE, CITISEN can effectively reduce noise components from speech signals and accordingly enhance their clarity and intelligibility. For ASC, CITISEN can convert the current background sound to a different background sound. Finally, for MA, CITISEN can effectively adapt an SE model, with a few audio files, when it encounters unknown speakers or noise types; the adapted SE model is used to enhance the upcoming noisy utterances. Experimental results confirmed the effectiveness of CITISEN in performing these three functions via objective evaluation and subjective listening tests. The promising results reveal that the developed CITISEN mobile application can potentially be used as a front-end processor for various speech-related services such as voice communication, assistive hearing devices, and virtual reality headsets.
Boosting Objective Scores of Speech Enhancement Model through MetricGAN Post-Processing
Jun 18, 2020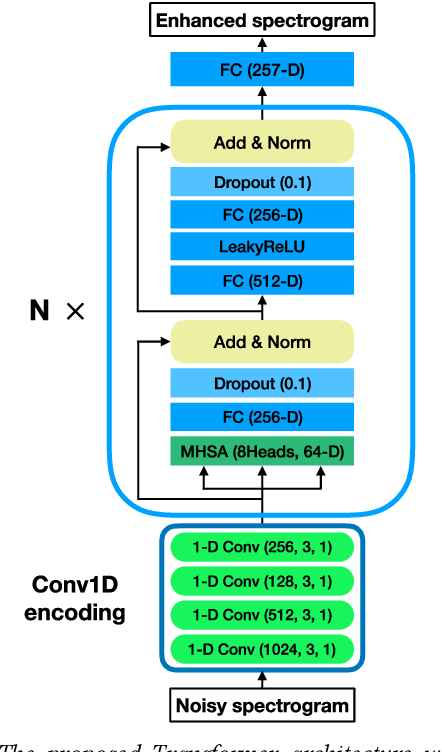
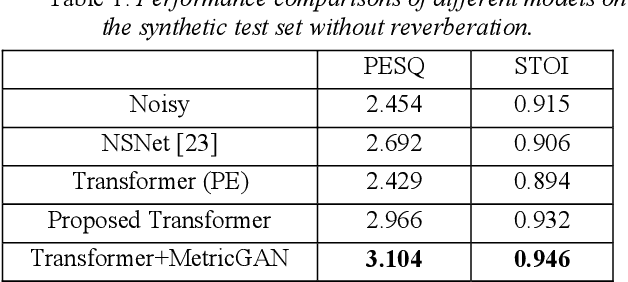
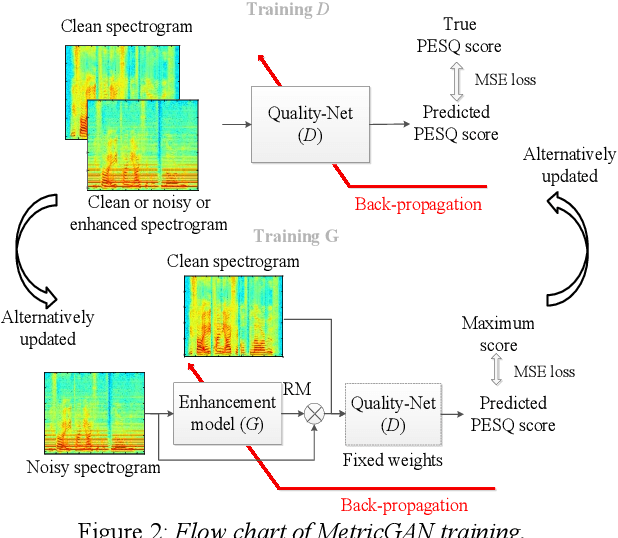

The Transformer architecture has shown its superior ability than recurrent neural networks on many different natural language processing applications. Therefore, this study applies a modified Transformer on the speech enhancement task. Specifically, the positional encoding may not be necessary and hence is replaced by convolutional layers. To further improve PESQ scores of enhanced speech, the L_1 pre-trained Transformer is fine-tuned by MetricGAN framework. The proposed MetricGAN can be treated as a general post-processing module to further boost interested objective scores. The experiments are conducted using the data sets provided by the organizer of the Deep Noise Suppression (DNS) challenge. Experimental results demonstrate that the proposed system outperforms the challenge baseline in both subjective and objective evaluation with a large margin.