 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRouterVLA: Turning Smoke Tests into Supervision for Heterogeneous VLA Selection
Jun 25, 2026We study whether pre-deployment evaluation rollouts can be reused to supervise policy selection. Robot teams routinely smoke test candidate vision-language-action (VLA) policies, then compress those trials into a global winner. RouterVLA evaluates this idea with outcome-disjoint cross-fitting: recorded probes build a profile for each frozen expert, and a separate trial scores the selected expert without entering its profile. Across 34,752 LIBERO-Plus rollout records, a transparent probe-success rule raises held-out success from 0.4686 to 0.6149, a +14.64pp gain. Under the scalar-only profiles studied here, learned scorers are statistically indistinguishable from this rule, showing that commissioning carries the routing value while extra scalar scorer capacity does not create it. Reusing the scored trial inflates the measured gain by $1.87\times$, so credible ledger routing needs outcome separation; model scaling improves individual policies, while commissioning-aware routing improves the system built from them.
Agon: An Autonomous Large-Scale Omnidisciplinary Research System Built on Prompt Economy
Jun 23, 2026Large language models are making research production scalable, shifting the bottleneck from producing artifacts to judging claims. We present \textsc{Agon}, a research orchestrator that validates what can be checked inside the workflow and leaves the remaining judgments to human scientists. \textsc{Agon} is built on six design principles: Prompt Economy, Future-Facing, Minimal Prompts, OmniDisciplinary, Massive Parallelism, and Zero-Code. We ran \textsc{Agon} across domains for 444 iterations of Prompt Economy loops, using only small starting topics and no human-written experimental code. These deployments demonstrate scalability while exposing new classes of failure. We organize these failures into a taxonomy along severity, fixability, visibility, and capability locus. The taxonomy separates failures the loops can see and fix from those that require human judgment. Together, these results show that \textsc{Agon} is pushing research toward a new paradigm: machine scales, human steers.
PerspectiveGap: A Benchmark for Multi-Agent Orchestration Prompting
Jun 07, 2026Real-world LLM applications are moving beyond single-agent workflows toward orchestrated multi-agent systems, yet current models still struggle to determine what each sub-agent needs to know. To measure this, we introduce PerspectiveGap, a benchmark for evaluating LLMs' ability to compose orchestration prompts for multi-agent systems. PerspectiveGap contains 110 scenarios, each evaluated through two distractor-mixed task formats: role-fragment assignment and free-form prompt writing. These scenarios are organized into 10 topologies, which are distilled from the authors' real-world engineering practice and framed by the Prompt Economy principle: building loop-centered orchestrations that maximize utility with minimal role and engineering overhead. In experiments with 27 commercial models from 10 companies, GPT-5.5 substantially outperforms all competitors, whereas Opus 4.7 shows a notable weakness in orchestration prompting despite its strong coding performance. Nevertheless, PerspectiveGap remains challenging: the evaluated models achieve an average combined pass rate of only 14.9\% (GPT-5.5 62.0\%) and an average overall leakage rate of 246.5\% (a per-scenario information leak-event count, not a proportion; GPT-5.5 49.1\%). These findings suggest that multi-agent orchestration prompting is a distinct and under-evaluated capability, and PerspectiveGap provides a foundation for measuring and improving it systematically.
AutoNumerics: An Autonomous, PDE-Agnostic Multi-Agent Pipeline for Scientific Computing
Feb 19, 2026PDEs are central to scientific and engineering modeling, yet designing accurate numerical solvers typically requires substantial mathematical expertise and manual tuning. Recent neural network-based approaches improve flexibility but often demand high computational cost and suffer from limited interpretability. We introduce \texttt{AutoNumerics}, a multi-agent framework that autonomously designs, implements, debugs, and verifies numerical solvers for general PDEs directly from natural language descriptions. Unlike black-box neural solvers, our framework generates transparent solvers grounded in classical numerical analysis. We introduce a coarse-to-fine execution strategy and a residual-based self-verification mechanism. Experiments on 24 canonical and real-world PDE problems demonstrate that \texttt{AutoNumerics} achieves competitive or superior accuracy compared to existing neural and LLM-based baselines, and correctly selects numerical schemes based on PDE structural properties, suggesting its viability as an accessible paradigm for automated PDE solving.
DRIFT: Detecting Representational Inconsistencies for Factual Truthfulness
Jan 29, 2026LLMs often produce fluent but incorrect answers, yet detecting such hallucinations typically requires multiple sampling passes or post-hoc verification, adding significant latency and cost. We hypothesize that intermediate layers encode confidence signals that are lost in the final output layer, and propose a lightweight probe to read these signals directly from hidden states. The probe adds less than 0.1\% computational overhead and can run fully in parallel with generation, enabling hallucination detection before the answer is produced. Building on this, we develop an LLM router that answers confident queries immediately while delegating uncertain ones to stronger models. Despite its simplicity, our method achieves SOTA AUROC on 10 out of 12 settings across four QA benchmarks and three LLM families, with gains of up to 13 points over prior methods, and generalizes across dataset shifts without retraining.
HALT: Hallucination Assessment via Latent Testing
Jan 20, 2026Hallucination in large language models (LLMs) can be understood as a failure of faithful readout: although internal representations may encode uncertainty about a query, decoding pressures still yield a fluent answer. We propose lightweight residual probes that read hallucination risk directly from intermediate hidden states of question tokens, motivated by the hypothesis that these layers retain epistemic signals that are attenuated in the final decoding stage. The probe is a small auxiliary network whose computation is orders of magnitude cheaper than token generation and can be evaluated fully in parallel with inference, enabling near-instantaneous hallucination risk estimation with effectively zero added latency in low-risk cases. We deploy the probe as an agentic critic for fast selective generation and routing, allowing LLMs to immediately answer confident queries while delegating uncertain ones to stronger verification pipelines. Across four QA benchmarks and multiple LLM families, the method achieves strong AUROC and AURAC, generalizes under dataset shift, and reveals interpretable structure in intermediate representations, positioning fast internal uncertainty readout as a principled foundation for reliable agentic AI.
ReSearch: A Multi-Stage Machine Learning Framework for Earth Science Data Discovery
Jan 20, 2026The rapid expansion of Earth Science data from satellite observations, reanalysis products, and numerical simulations has created a critical bottleneck in scientific discovery, namely identifying relevant datasets for a given research objective. Existing discovery systems are primarily retrieval-centric and struggle to bridge the gap between high-level scientific intent and heterogeneous metadata at scale. We introduce \textbf{ReSearch}, a multi-stage, reasoning-enhanced search framework that formulates Earth Science data discovery as an iterative process of intent interpretation, high-recall retrieval, and context-aware ranking. ReSearch integrates lexical search, semantic embeddings, abbreviation expansion, and large language model reranking within a unified architecture that explicitly separates recall and precision objectives. To enable realistic evaluation, we construct a literature-grounded benchmark by aligning natural language intent with datasets cited in peer-reviewed Earth Science studies. Experiments demonstrate that ReSearch consistently improves recall and ranking performance over baseline methods, particularly for task-based queries expressing abstract scientific goals. These results underscore the importance of intent-aware, multi-stage search as a foundational capability for reproducible and scalable Earth Science research.
FrontierCS: Evolving Challenges for Evolving Intelligence
Dec 17, 2025



We introduce FrontierCS, a benchmark of 156 open-ended problems across diverse areas of computer science, designed and reviewed by experts, including CS PhDs and top-tier competitive programming participants and problem setters. Unlike existing benchmarks that focus on tasks with known optimal solutions, FrontierCS targets problems where the optimal solution is unknown, but the quality of a solution can be objectively evaluated. Models solve these tasks by implementing executable programs rather than outputting a direct answer. FrontierCS includes algorithmic problems, which are often NP-hard variants of competitive programming problems with objective partial scoring, and research problems with the same property. For each problem we provide an expert reference solution and an automatic evaluator. Combining open-ended design, measurable progress, and expert curation, FrontierCS provides a benchmark at the frontier of computer-science difficulty. Empirically, we find that frontier reasoning models still lag far behind human experts on both the algorithmic and research tracks, that increasing reasoning budgets alone does not close this gap, and that models often over-optimize for generating merely workable code instead of discovering high-quality algorithms and system designs.
Correcting Mean Bias in Text Embeddings: A Refined Renormalization with Training-Free Improvements on MMTEB
Nov 14, 2025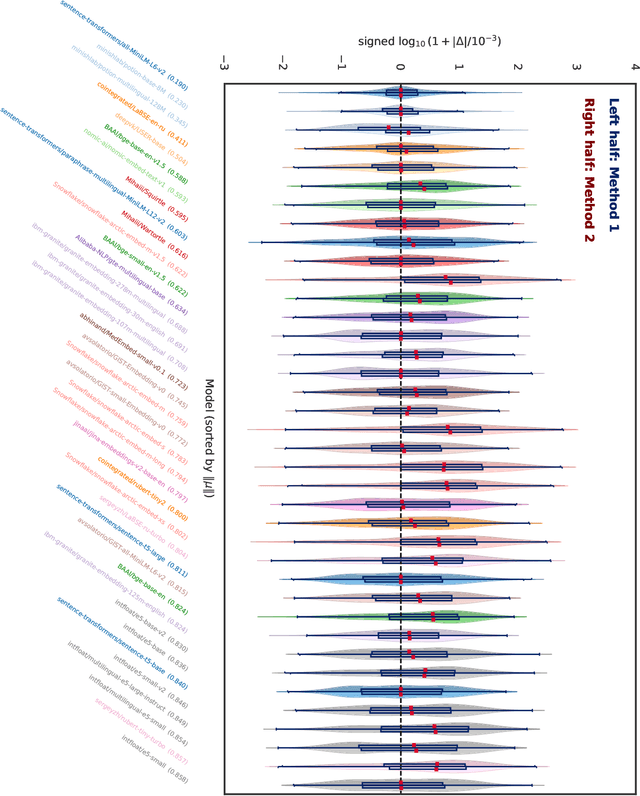
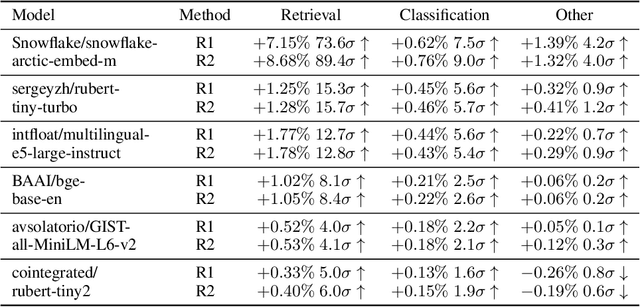
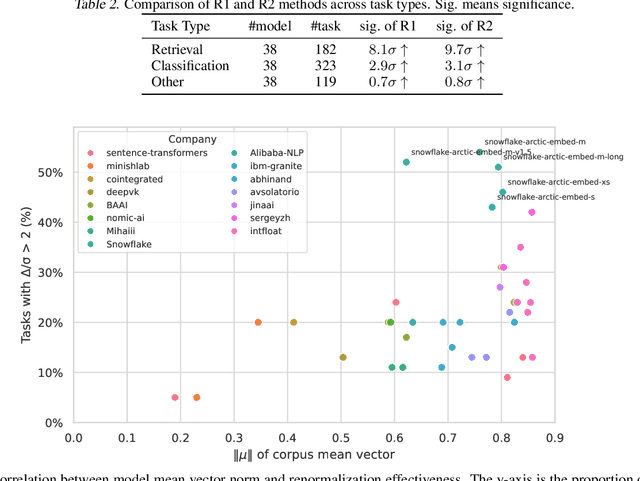
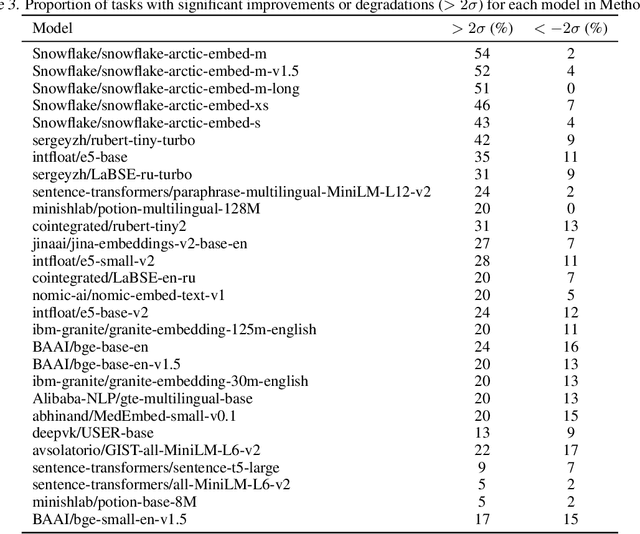
We find that current text embedding models produce outputs with a consistent bias, i.e., each embedding vector $e$ can be decomposed as $\tilde{e} + μ$, where $μ$ is almost identical across all sentences. We propose a plug-and-play, training-free and lightweight solution called Renormalization. Through extensive experiments, we show that renormalization consistently and statistically significantly improves the performance of existing models on the Massive Multilingual Text Embedding Benchmark (MMTEB). In particular, across 38 models, renormalization improves performance by 9.7 $σ$ on retrieval tasks, 3.1 $σ$ on classification tasks, and 0.8 $σ$ on other types of tasks. Renormalization has two variants: directly subtracting $μ$ from $e$, or subtracting the projection of $e$ onto $μ$. We theoretically predict that the latter performs better, and our experiments confirm this prediction.
OptimAI: Optimization from Natural Language Using LLM-Powered AI Agents
Apr 23, 2025



Optimization plays a vital role in scientific research and practical applications, but formulating a concrete optimization problem described in natural language into a mathematical form and selecting a suitable solver to solve the problem requires substantial domain expertise. We introduce \textbf{OptimAI}, a framework for solving \underline{Optim}ization problems described in natural language by leveraging LLM-powered \underline{AI} agents, achieving superior performance over current state-of-the-art methods. Our framework is built upon four key roles: (1) a \emph{formulator} that translates natural language problem descriptions into precise mathematical formulations; (2) a \emph{planner} that constructs a high-level solution strategy prior to execution; and (3) a \emph{coder} and a \emph{code critic} capable of interacting with the environment and reflecting on outcomes to refine future actions. Ablation studies confirm that all roles are essential; removing the planner or code critic results in $5.8\times$ and $3.1\times$ drops in productivity, respectively. Furthermore, we introduce UCB-based debug scheduling to dynamically switch between alternative plans, yielding an additional $3.3\times$ productivity gain. Our design emphasizes multi-agent collaboration, allowing us to conveniently explore the synergistic effect of combining diverse models within a unified system. Our approach attains 88.1\% accuracy on the NLP4LP dataset and 71.2\% on the Optibench (non-linear w/o table) subset, reducing error rates by 58\% and 50\% respectively over prior best results.